🏡 California Housing 집값 예측
💡프로젝트 중점사항
- task : 캘리포니아 집값 예측하기
- 여러가지 머신러닝 선형회귀 알고리즘 활용
- scikit-learn 데이터 활용하기
💻 기술스택
- Python
- sklearn, pandas, numpy, matplotlib
- google colab
1. 데이터 및 라이브러리 불러오기
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns- 배열과 표를 사용하기 위해 numpy와 pandas를 불러옵니다.
- EDA를 편리하게 하기 위해 시각화 라이브러리인 matplotlib과 seaborn을 불러옵니다.
# California 데이터 불러오기
from sklearn.datasets import fetch_california_housing
X = fetch_california_housing(as_frame = True)['data']
y = fetch_california_housing(as_frame = True)['target']
# as_frame = True : 데이터프레임 형식으로 바꾸어주는 코드(디폴트값 : False)
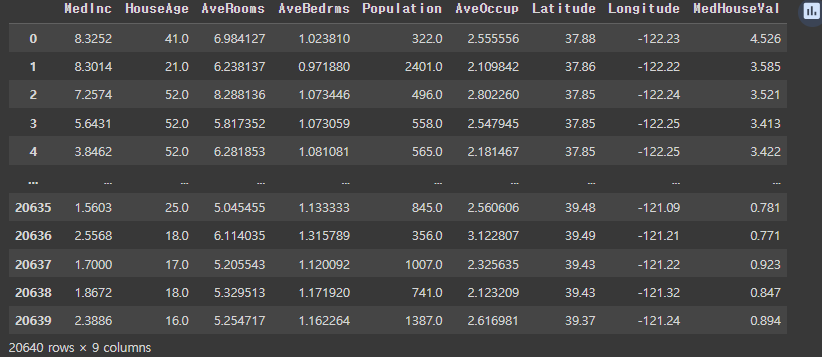
data = pd.concat([X, y], axis = 1)
display(data)- sklearn 라이브러리 안에 있는 데이터 셋인 'fetch_california_housing'을 불러옵니다.
- 변수 X와 y에 data값과 target값을 선언해주고, pandas의 concat()함수를 통해 열기준으로 붙여줍니다.
2. Data Preprocessing(데이터 전처리)
1) 결측치 확인
2) feature selection
1) 결측치 확인
data.info()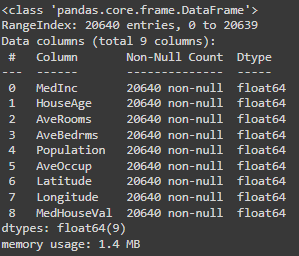
- 다행히(?) 딱 보았을 때 결측치는 없어보입니다.
- 하지만 ' ', '-', '/' 등의 결측치를 표시하는 값이 들어가 있을 수도 있으니 확인을 해야하지만 이 데이터셋의 Dtype을 확인하면 float64로 되어 있습니다. 이 말은 즉슨, 숫자 소수로 되어 있다는 뜻으로 해당 이상한 문자가 없다는 뜻입니다.
- 결론적으로 Dtype이 float64이면 해당 데이터셋에는 결측치가 없다고 봐도 무방합니다.
2) feature selection(특징 선택)
- 데이터분석에서 사용할 컬럼을 선택하는 과정인데 저는 모든 column을 사용할겁니다.
- feature selection은 작업자의 판단에 따라 진행하면 됩니다.
3. EDA(탐색적 데이터 분석)
1) feature distribute
2) target distribute
1) feature distribution
- 데이터셋의 각 컬럼의 분포를 이해하고 시각화 하는 과정입니다.
- 데이터의 특성이 어떻게 분포되어있는지 통계적으로 파악할 수 있습니다.
sns.histplot(data = data, x = "AveRooms")
plt.figure(figsize = (8, 6))
sns.boxplot(data = data.loc[:, ["MedInc", "HouseAge", "AveRooms", "AveBedrms",
"AveOccup", "Latitude", "Longitude", "MedHouseVal"]])
sns.boxplot(data = data.loc[:, ["AveRooms", "AveBedrms", "AveOccup"]])
plt.figure(figsize = (10, 6))
sns.heatmap(data.corr(),annot=True)- 여러 그래프들을 활용하여 각 column들의 관계를 파악하고, 분석에 활용할 column의 feature들을 확인합니다.
🔎 코드 정리
sns.histplot(data = data name, x or y ='column_name') -> 해당 컬럼에 대한 히스토그램(빈도분포) -> 데이터의 범위, 중심 경향, 이상치, 빈도 등을 파악 -------------------------------------------------------------------- sns.boxplot([column name]) -> 데이터의 분포와 이상치를 시각화하는 데 사용 -> 매개변수(선택) * boxplot은 생소해서 나중에 따로 다뤄봐야겠다. ``
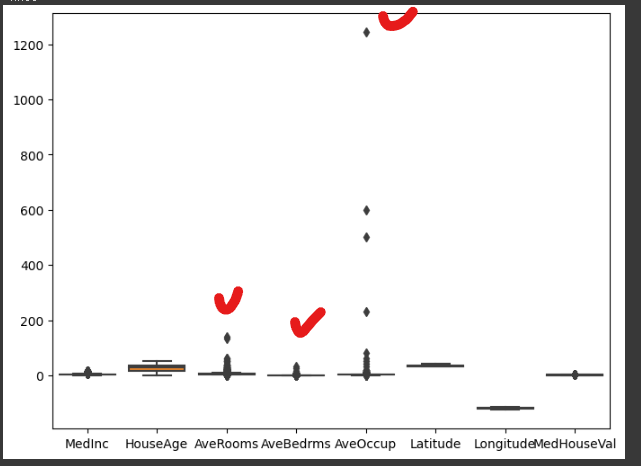
- AveRooms, AveBedrms, AveOccup가 다른 컬럼보다 이상치가 높으므로 따로 확인해봅시다.
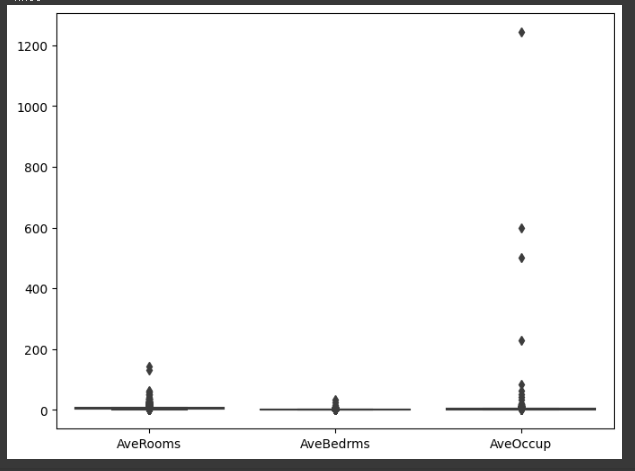
- AveRooms, AveOccup의 이상치가 현저히 높으므로 정제작업이 필요해보입니다.
data.loc[data.AveRooms > 100, :] #1914, 1979 row 제거
data.loc[data.AveOccup>200, :] # 3364, 13034, 16669, 19006 row 제거
# AveBedrms, Longitude column 제거 -> 다중공선성 제거
data = data.drop(index = [1914, 1979, 3364, 13034, 16669, 19006]) ##remove outlier
data = data.drop(columns = ['AveBedrms', 'Longitude']) ## remove collinearity(다중공선성)- AveRooms는 100 이상의 row를 제거하고, AveOccup는 200 이상의 row를 제거함으로 데이터를 조정합니다. 특별한 패턴없이 터무니없이 너무 큰 값들을 제거해주기 위함입니다.
- 다중공선성(coolinearity)를 제거하기 위해 AveBedrms, Longitude column을 제거해줍니다.
2) target distribution
sns.histplot(data=data, x = "MedHouseVal")
data.MedHouseVal.value_counts()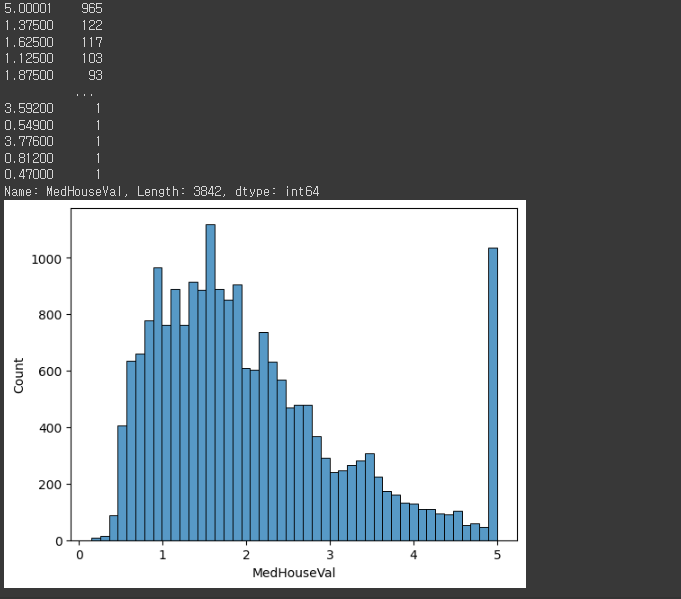
- target 값들의 분포를 hisplot를 통해 파악해보니, MedHouseval에서 5주변 값이 급격히 많아지고, 현저하게 많다는 것을 알 수 있다.
4. Training
1) train-test split
2) Standardization
3) Model training
4) Hyper-parameter tuning
1) train-test split
# 학습을 위한 training / test dataset 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=0xC0FFEE)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size = 0.25, random_state=0xC0FFEE)
# 6:2:2 = train : validation : test- 메인 data와 target data를 training과 test dataset으로 나누어줍니다.
- training과 test 데이터의 비율은 8:2로 설정해줍니다.
- 그리고 나눈 training dataset에서 0.25 비율로 validation dataset을 만들어줍니다.
- 결론적으로 dataset의 비율은 6:2:2 = train : test : validation입니다.
2) Standardization
feature scaling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
X_test = scaler.transform(X_test)- 데이터 전처리를 위한 표준화 작업인 feature scaling을 진행합니다.
- feature vector(X)에 대한 StandardScaling을 진행합니다.
3) Model training
📃학습을 위한 라이브러리 세팅
# 1. Linear Regression from sklearn.linear_model import LinearRegression # 2. Lasso from sklearn.linear_model import Lasso # 3. Ridge from sklearn.linear_model import Ridge # 4. XGBoost from xgboost.sklearn import XGBRegressor # 5. LightGBM from lightgbm.sklearn import LGBMRegressor # 5. LightGBM from sklearn.metrics import mean_squared_error
- 총 5가지의 회귀모델을 사용합니다.
- 평가지표는 MSE를 사용합니다.
## training
reg = LinearRegression()
reg2 = Lasso()
reg3 = Ridge()
reg4 = XGBRegressor()
reg5 = LGBMRegressor()
reg.fit(X_train, y_train)
reg2.fit(X_train, y_train)
reg3.fit(X_train, y_train)
reg4.fit(X_train, y_train)
reg5.fit(X_train, y_train)
pred_train = reg.predict(X_train)
pred_train2 = reg2.predict(X_train)
pred_train3 = reg3.predict(X_train)
pred_train4 = reg4.predict(X_train)
pred_train5 = reg5.predict(X_train)
pred_val = reg.predict(X_val)
pred_val2 = reg2.predict(X_val)
pred_val3 = reg3.predict(X_val)
pred_val4 = reg4.predict(X_val)
pred_val5 = reg5.predict(X_val)
mse_train = mean_squared_error(y_train, pred_train)
mse_val = mean_squared_error(y_val, pred_val)
mse_train2 = mean_squared_error(y_train, pred_train2)
mse_val2 = mean_squared_error(y_val, pred_val2)
mse_train3 = mean_squared_error(y_train, pred_train3)
mse_val3 = mean_squared_error(y_val, pred_val3)
mse_train4 = mean_squared_error(y_train, pred_train4)
mse_val4 = mean_squared_error(y_val, pred_val4)
mse_train5 = mean_squared_error(y_train, pred_train5)
mse_val5 = mean_squared_error(y_val, pred_val5)
print("l. Linear Regression,\t train/val = %.4f, %.4f" % (mse_train, mse_val))
print("2. Lasso,\t\t train/val = %.4f, %.4f" % (mse_train2, mse_val2))
print("3. Ridge,\t\t train/val = %.4f, %.4f" % (mse_train3, mse_val3))
print("4. XGBoost,\t\t train/val = %.4f, %.4f" % (mse_train4, mse_val4))
print("5. LightGBM,\t\t train/val = %.4f, %.4f" % (mse_train5, mse_val5))- 각 모델에 대해 training 데이터와 validation 데이터를 학습시켜주고, 예측값을 만들어줍니다.
- target data(y)의 training, validation data와 학습시킨 X의 training, validation data(pred_train, pred_val)를 MSE 평가를 해줍니다.
- 학습데이터가 학습을 잘 했는지, 검증데이터로 결과를 냈을 때 학습데이터와 큰 오차가 없는지 확인하여 후에 파라미터를 튜닝해줍니다.
결과
l. Linear Regression, train/val = 0.5336, 0.5241 2. Lasso, train/val = 1.3490, 1.2857 3. Ridge, train/val = 0.5336, 0.5241 4. XGBoost, train/val = 0.0603, 0.2247 5. LightGBM, train/val = 0.1474, 0.2167🔎 MSE(평균제곱 오차) : 실제 정답값과 예측값의 차이를 제곱한 뒤 평가하는 지표. 점수가 낮을수록 좋습니다.
- 정답값은 target value(y)이며, 예측값은 pred_train, pred_val입니다.
- validation data 중 LightGBM 모델이 가장 성능이 좋게 나왔습니다.
4) Hyper-parameter tuning
💡 튜닝 방법 몇 가지...
- Human Search
- Grid Search(Grid SearchCV) : 주어진 하이퍼파라미터의 조합을 모두 돌려보는 방식.
- Byesian Optimizataion(hyperopt, optuna, ...) : hyper-parameter를 최적화하는 베이지안 방식을 사용.
# GridSearchCV
from sklearn.model_selection import GridSearchCV
param_grid = {
"max_depth" : [3, 5, -1], # 3개
"learning_rate" : [0.1, 0.01], # 2개
"n_estimators" : [50, 100] # 2개
} # -> 3x3x2 = 12번을 수행
gcv = GridSearchCV(reg5, param_grid, scoring = 'neg_mean_squared_error', verbose=1)
gcv.fit(X_train, y_train)- 가장 모델 성능이 좋은 LightGBM을 튜닝해줍니다.
- GridSearchCV 방식으로 주어진 하이퍼파라미터의 조합을 모두 돌려보겠습니다. 하이퍼파라미터가 많으면 많을 수록 실행 시간은 오래걸립니다. 그러니 적당하게 튜닝을하여 돌려주는 것이 좋습니다.
- 하이퍼파라미터 튜닝을 한 후, 튜닝한 모델을 다시 학습시켜줍니다.
5) Test
# prediction!
result5 = reg5.predict(X_test)- LightGBM 모델의 test 데이터의 예측값을 구해줍니다.
print("---------- LightGBM ---------")
print('MSE in training: %.4f' % mean_squared_error(y_test, result5))
-----------------------------------------------------------------
---------- LightGBM ---------
MSE in training: 0.2151- MSE를 다시 구해보면 이전보다 약간 성능이 좋아진 것을 알 수 있습니다.
💡 시사점
- 여러 회귀모델 중 가장 많이 쓰이고 성능이 좋은 편에 속하는 LightGBM이 역시 성능이 좋게 나왔다.
- 미니 프로젝트를 하다보니 EDA과정과 전처리 과정이 정말 중요하다는 것을 깨달았다.
- 코드만 잘 짠다고 해서 될 것이 아니라 데이터를 잘 다루고, 의미있는 해석을 잘해야되는 것 같다.
- 사실 아직 많이 모르겠다. 이제 어느정도 프로세스 느낌만 알 거 같은 상태이다. 계속해서 미니 프로젝트와 공부를 하며 실력을 키워야겠다.
