
Redis 도입 전
기존 게시글 좋아요 API는 RDB(관계형 데이터베이스)에 대한 직접적인 I/O 작업을 통해 좋아요 상태를 토글하는 방식으로 구현되어 있었습니다.
기존 좋아요 API 로직
public void likeArticle(Long articleId, Long userId) {
Article article = articleRepository.find(articleId)
.orElseThrow(() -> new EntityNotFoundException("Article not found"));
boolean exists = articleLikeRepository.existsByArticleIdAndUserId(articleId, userId);
if (exists) {
articleLikeRepository.deleteByArticleIdAndUserId(articleId, userId);
article.unlike();
} else {
ArticleLike like = ArticleLike.create(articleId, userId);
articleLikeRepository.save(like);
article.like();
}
}이 로직은 좋아요의 존재 여부를 확인하고, 존재하면 삭제, 없으면 새로 생성하여 즉시 RDB에 저장합니다. 이러한 방식은 락 경합 및 동시성 이슈 발생 가능성이 높다고 판단했습니다.
기존 로직의 문제점:레이스 컨디션
@Entity
@Table(
name = "article_likes",
uniqueConstraints = @UniqueConstraint(
name = "uk_article_like_article_user",
columnNames = {"article_id", "user_id"}
)
)
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ArticleLikeDB에 UNIQUE(article_id, user_id) 제약 조건이 설정되어 있더라도, 동시에 두 요청이 들어올 경우 다음과 같은 레이스 컨디션이 발생할 수 있을 것 같았습니다.
- A, B 두 스레드가 거의 같은 순간에 "해당 좋아요가 존재하지 않는다"고 판단하여 둘 다 삽입 로직을 실행한다면, 이 경우 둘 중 하나가 먼저 DB에 레코드를 넣고, 나머지는 제약 위반으로 예외가 발생하여 테스트에서 실패 케이스로 기록될 수 있습니다.
- 반대로 이미 좋아요가 있을 때, 동시에 두 스레드가 "존재한다"고 판단하여 둘 다 삭제를 시도할 경우, 하나는 "삭제 대상이 없음"으로 실패할 수 있습니다.
이러한 문제점을 확인하기 위해 K6 테스트 툴을 사용하여 성능을 측정했습니다.
(K6는 JMeter와 유사한 부하 테스트 툴로, 최근 테스트 진영에서 점유율이 증가하고 있어 선택하게 되었습니다.)
테스트 스크립트
export let options = {
scenarios: {
baseline: {
executor: 'constant-arrival-rate',
rate: 20,
timeUnit: '1s',
duration: '10m',
preAllocatedVUs: 30,
maxVUs: 100,
},
spike: {
executor: 'constant-arrival-rate',
rate: 100,
timeUnit: '1s',
duration: '1m',
startTime: '10m', // baseline 종료 시점
preAllocatedVUs: 100,
maxVUs: 200,
},
},
};로그인 인증 및 인가 과정은 제외한 핵심 테스트 구성 인자들입니다.
아래의 테스트들은 해당 스크립트를 통해 진행한 테스트입니다.
Redis 도입 전 성능 테스트 결과
k6 테스트
baseline test: 16:05 ~ 16:15
spike test: 16:15 ~ 16:16
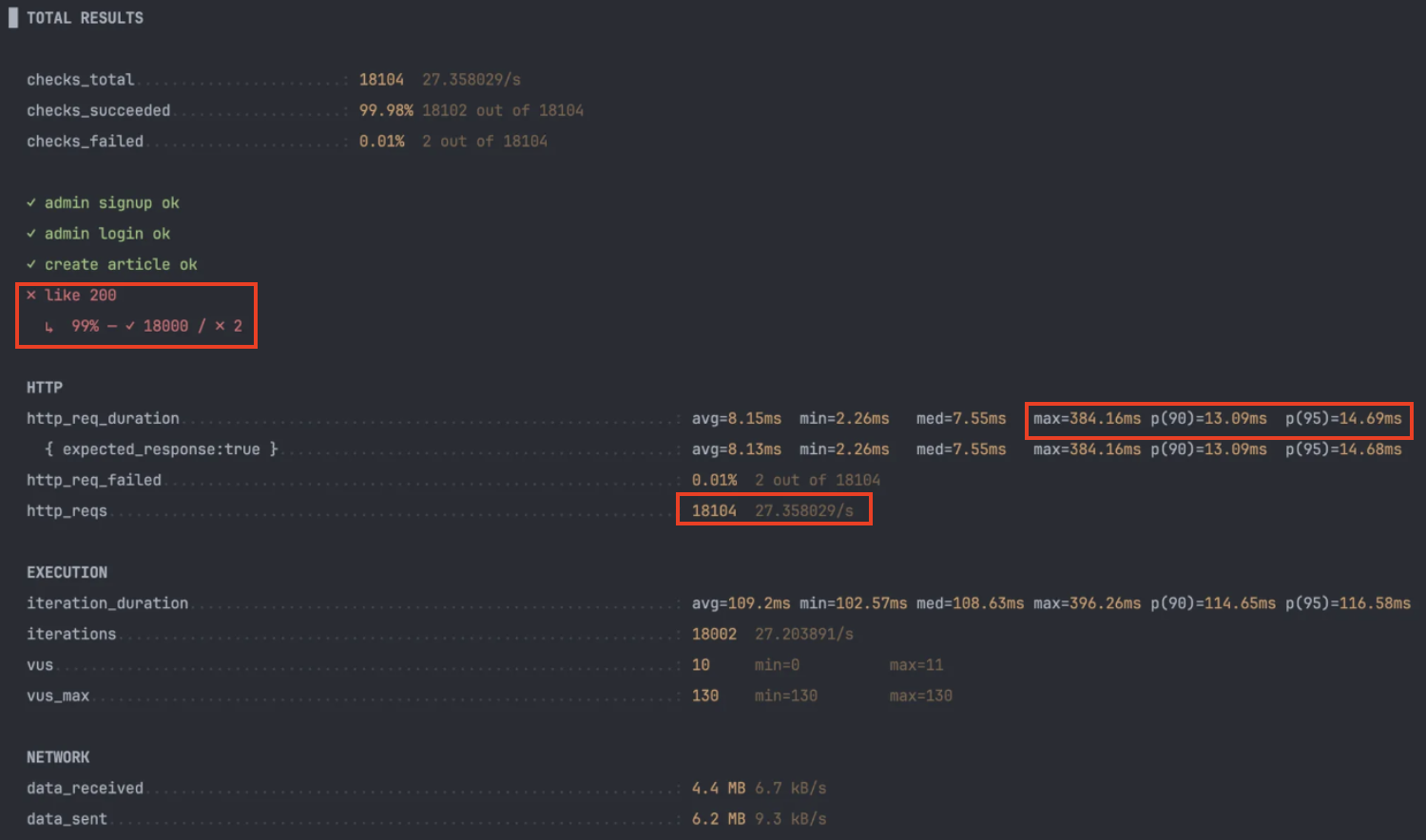
그리 크지 않은 부하의 스파이크 테스트임에도 불구하고 0.01%의 동시성 이슈가 발생하여 실패했습니다.
- Throughput: 27.3 req/s
- 최대 지연: 384ms (DB 직행으로 인한 I/O 또는 락 대기 타임이 튀는 구간이 있었을 것으로 예상됩니다.)
- 에러(0.01%) 동시성 토글 충돌이 남아있어 캐시 계층으로 제거가 필요하다고 판단했습니다.
- p(95): 14.69ms
스프링 서버 모니터링
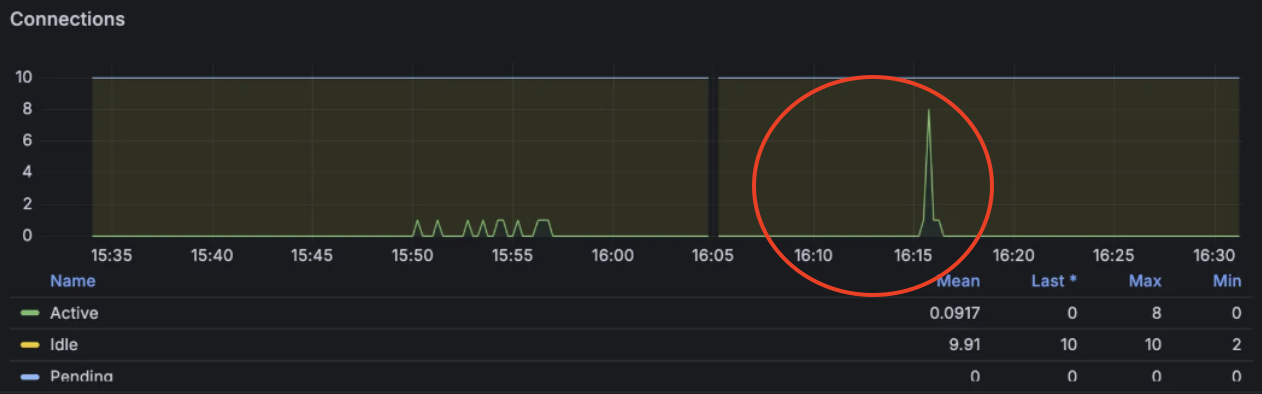
- HikariCP 풀 사이즈(10) 대비 여유가 있었으나, 스파이크 발생 시 순간적으로 8개의 커넥션이 사용되었습니다.
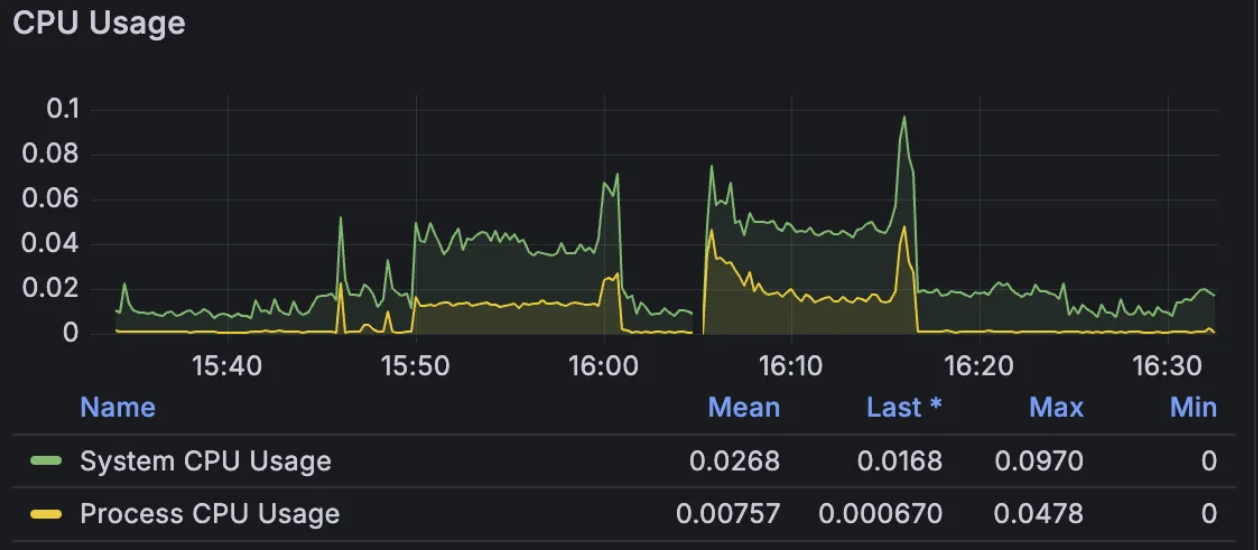
- 프로세스 평균 CPU 사용률은 0.75%, 피크 시 4.78%를 기록했습니다. 부하 순간에도 CPU는 여유가 있었던 것으로 추정됩니다.
MySQL 모니터링
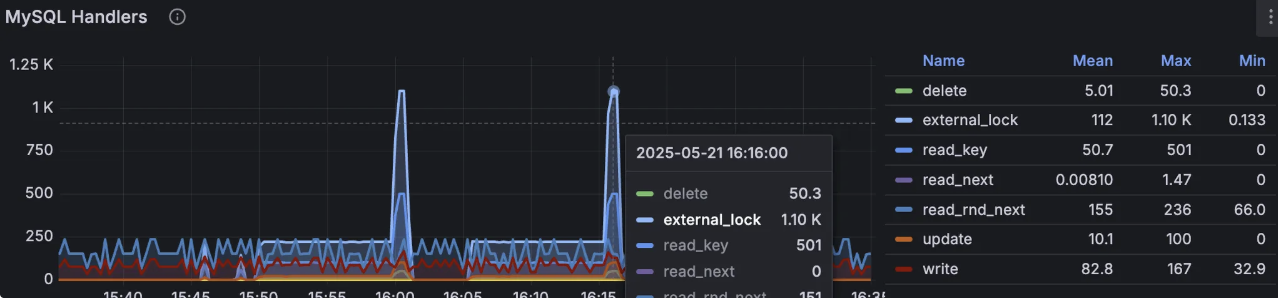
- External_lock Handlers 지표에서 락 대기 및 경합 발생량이 많아 동시성 취약점이 확인되었습니다.
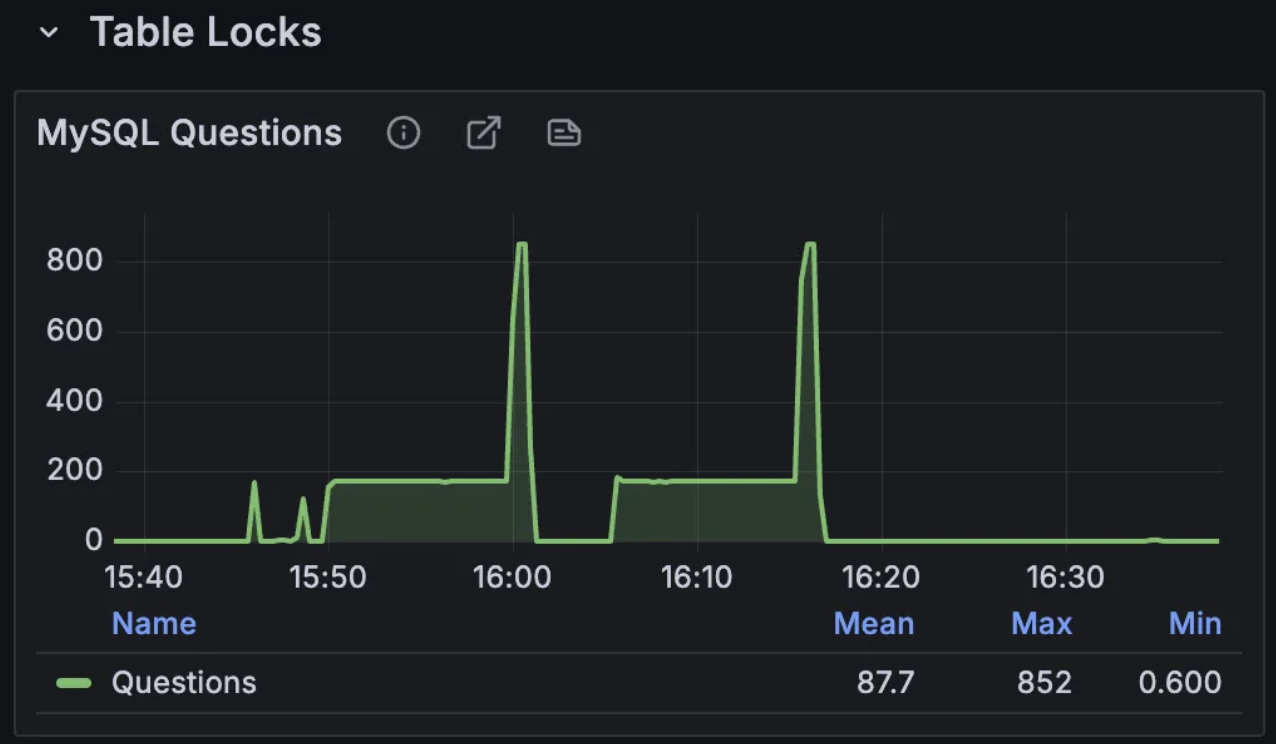
- MySQL Questions 지표는 안정 상태에서 180/s, 스파이크 시 850/s를 기록했습니다.
Redis 도입 후
위에서 확인된 동시성 문제와 RDB 부하를 개선하기 위해 Spring Boot와 RDB 사이에 Redis NoSQL 서버를 도입하기로 결정했습니다.
기존에도 Spring Redis를 사용하고 있었기에, 동일한 프레임워크를 채택하는 것이 더욱 유용하다고 판단했습니다.
좋아요 개수를 레디스에서 따로 뽑아 게시글 상세조회 등 API에 게시글 객체와 더해 반환하도록 수정하였습니다.
따라서 Article 도메인에서 likeCount 필드를 제거하였습니다.
public ArticleDetailResponse find(Long id) {
Article article = articleQueryService.find(id);
long likeCount = articleLikeService.getLikeCount(id);
return ArticleDetailResponse.from(article, likeCount);
}
}이후 좋아요를 각 게시글 조회시마다 게시글 ID를 통해 redis에서 따로 조회하여 반환하도록 수정하였습니다.
Redis 도입 후 좋아요 API 로직
public void likeArticle(Long articleId, Long userId) {
articleRepository.find(articleId)
.orElseThrow(() -> new EntityNotFoundException("Article not found"));
String key = KEY_PREFIX + articleId;
BoundSetOperations<String, String> ops = redisTemplate.boundSetOps(key);
boolean added = ops.add(userId.toString()) == 1;
if (!added) {
ops.remove(userId.toString());
}
likeChangeQueue.enqueue(new LikeChange(articleId, userId, added));
}
public long getLikeCount(Long articleId) {
String key = KEY_PREFIX + articleId;
return redisTemplate.opsForSet().size(key);
}즉, 이제 좋아요 API 호출시 RDB에 직접 쓰기 작업을 하지 않고, redis 에 적재한 후, 해당 좋아요 발생 이벤트에 대해 likeChangeQueue 에 저장한 후, 스프링 스케줄러를 통해 정해진 시간마다 db에 batch 쓰기 작업을 진행합니다.
@Component
public class LikeChangeQueue {
private final BlockingQueue<LikeChange> queue = new LinkedBlockingQueue<>();
public void enqueue(LikeChange likeChange) {
queue.put(likeChange);
}
public List<LikeChange> drain() {
List<LikeChange> list = new ArrayList<>();
queue.drainTo(list);
return list;
}
}LinkedBlockingQueue는 내부적으로 스레드 안전하게 동작하며, put()과 take() 메서드를 통해 큐가 가득 차거나 비었을 때 자동으로 대기(Blocking)할 수 있어 producer-consumer 패턴 구현에 효과적입니다.
LinkedBlockingQueue#drainTo(Collection c) 는 큐에 현재 들어있는 요소들을 가능한 만큼 꺼내서(c로) 옮기고, 큐에서는 제거합니다. 스냅샷처럼 현 시점에서의 데이터를 모두 읽고 비우는 메서드입니다.
또한, 락을 잡아서 일괄적으로 처리하기 때문에 poll()을 반복하는 것 보다 락 경합이 줄어들어 효율적이라고 합니다.
현재 인메모리 구조로써, 서버가 내려가면 날라가기 때문에 Redis Stream이나 Kafka 메세지 큐를 추후 추가 예정입니다.
@Component
@RequiredArgsConstructor
public class ArticleLikeFlushJob {
private final LikeChangeQueue likeChangeQueue;
private final ArticleLikeRepository articleLikeRepository;
@Scheduled(fixedDelayString = "${like.flush.interval:60000}")
@Transactional
public void flush() {
for (LikeChange lc : likeChangeQueue.drain()) {
if (lc.added()) {
articleLikeRepository.insertIgnore(lc.articleId(), lc.userId());
} else {
articleLikeRepository.deleteByArticleIdAndUserId(lc.articleId(), lc.userId());
}
}
}
}위 스케줄러에 정해진 시간마다 rdb로 flush() 작업 진행
(25.10.23) 내용 보완
위 flush() 메서드는 하나의 트랜잭션에서 다수의 ChangeEvent에 대해 처리하기 때문에, 하나의 이벤트 처리중 장애가 발생하면 트랜잭션이 롤백되어 다른 이벤트도 유실되는 문제가 발생할 것 같습니다.
따라서 아래처럼 많은 이벤트를 나눠서 처리한다면, 각각의 트랜잭션이 짧아질 것고,
List<LikeChange> batch = likeChangeQueue.drain();
for (List<LikeChange> chunk : Lists.partition(batch, 1000)) {
// 1000건씩 나눠서 처리, 해당 메서드 구현 시 트랜잭션을 새로 걸어야 함
processChunk(chunk);
}결국 기존의 HTTP → RDB 구조를 HTTP → Cache → RDB 로 변경함으로써 얻는 이점은 다음과 같습니다.
- 쓰기 지연(Write-behind) 을 통해 RDB에 반영하기 전에 중복된 이벤트를 정제할 수 있다.
→ 동일 유저의 빠른 연속 요청(좋아요/취소 반복)도 최종 상태만 반영되어 DB 부하를 줄인다. - 싱글 스레드 기반의 Redis 구조를 활용하여, 데이터에 대한 동시성 이슈를 자연스럽게 해결할 수 있다.
→ 별도의 락(lock) 없이도 일관성이 유지된다.
이 중 1번을 만족시키기 위해,
flush() 실행 전 HashMap 자료구조를 사용하여 최종 상태만 남기는 방식으로 처리할 수 있습니다.
Map<Pair<Long, Long>, LikeChange> latest = new HashMap<>();
for (LikeChange lc : likeChangeQueue.drain()) {
latest.put(Pair.of(lc.articleId(), lc.userId()), lc); // 동일 (articleId, userId) 키는 마지막 이벤트로 덮어씀
}이렇게 하면 (articleId, userId) 조합별로 마지막 이벤트만 남기므로,
좋아요 → 취소 → 다시 좋아요 같은 연속 이벤트가 들어와도 최종 상태만 RDB에 반영됩니다.
향후 Redis Stream 또는 Kafka로 LikeChange 이벤트를 발행하도록 확장할 예정이며, 소비자는 동일한 flush 로직을 수행하여 분산 환경에서도 데이터 일관성과 내구성을 보장할 계획입니다
Redis 도입 후 성능 테스트 결과
k6
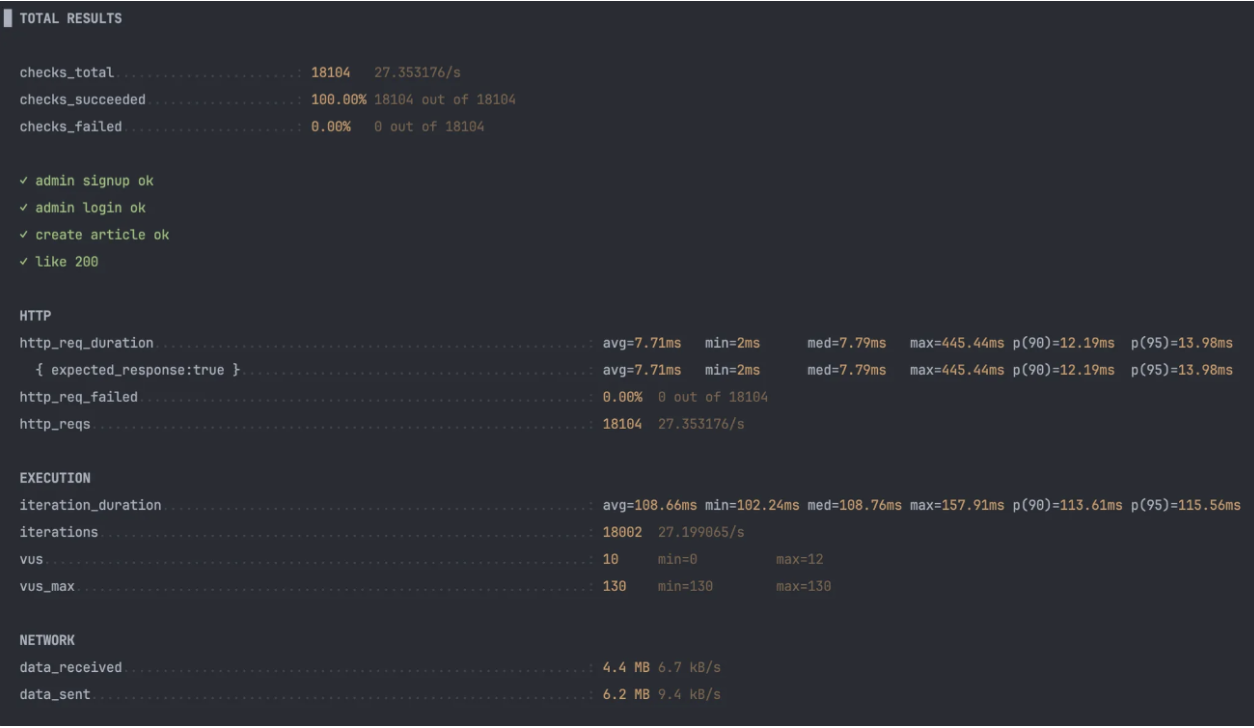
| 지표 | Redis 도입 전 | Redis 도입 후 | 변화 |
|---|---|---|---|
| 최대 지연 (max latency) | 384ms | 445.44ms | 약간 증가 |
| p(95) | 14.69ms | 13.98ms | 소폭 개선 |
| 처리량 (http reqs/s) | 27.35/s | 27.35/s | 동일 |
| 에러율 | 0.1% | 0% | 완전 해소 |
- 지연시간이 다소 증가한 이유는 Redis를 경유하며 발생한
네트워크 비용과 직렬화/역직렬화 과정에서 비용이 추가된 영향으로 추정됩니다. 하지만 상위 95%의 응답속도는 오히려 개선되었습니다. - 에러율이 0%로 개선된 것은 Redis의 싱글스레드의 원자적 연산 덕분에 DB 레벨의 동시성 충돌이 제거된 결과로 해석됩니다.
스프링 서버 모니터링
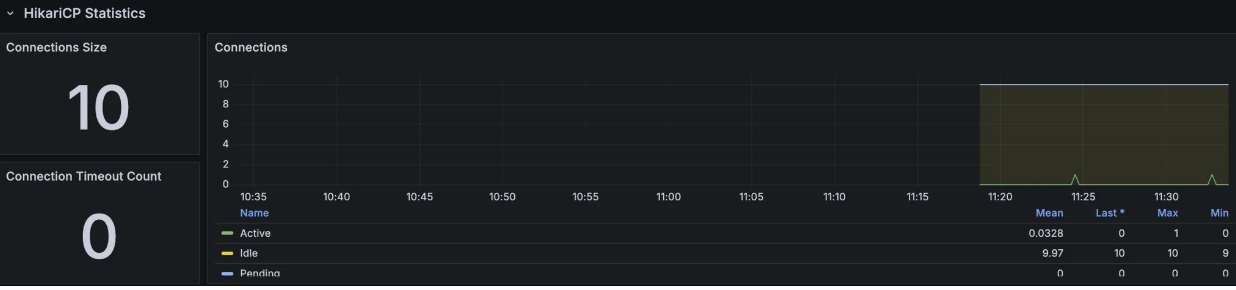
HikariCP Connection Pool
- 풀 사이즈: 10
- 커넥션 타임아웃: 0
- 스파이크 시에도 Active/Idle 수치가 거의 변동 없음
좋아요 API가 더 이상 DB에 직접 쓰기작업을 진행하지 않기 때문입니다. 대부분의 요청이 Redis 레벨에서 처리되어, DB 커넥션 풀에 부하가 걸리지 않게 되었습니다.
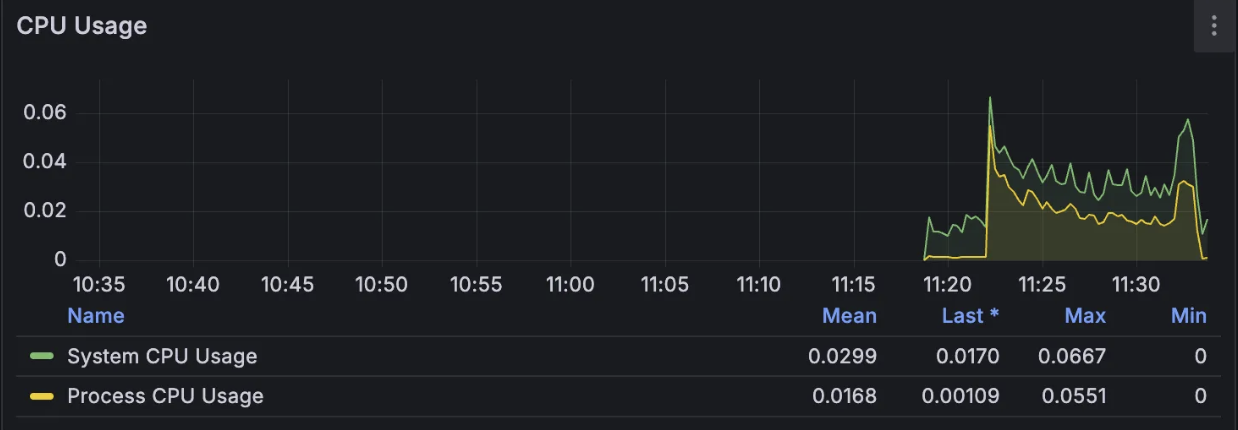
CPU Usage
- 평균 CPU: 1.68%
- 피크 시 CPU: 6.87%
- 이전 대비 약간 증가
Redis 연동과 직렬화과정 그리고 BlockingQueue의 enqueue 등 추가 로직으로 인해 CPU 부하를 미세하게 증가시켰습니다. 하지만 전체 부하가 7% 미만이므로 충분히 안정적인 상황인 것 같습니다.
MySQL 모니터링
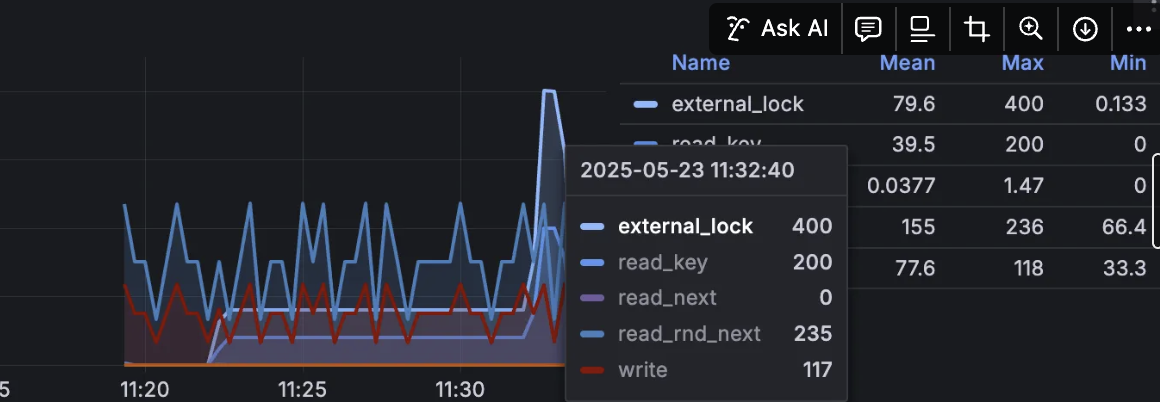
External_lock Handlers
- 피크 시 1100 -> 400(약 63% 감소)
이전에는 각 요청이 직접 insert/delete를 수행하며 테이블 락에 대하여 경쟁하는 상황이였지만, Redis 도입 후에 실시간 DB write가 사라지고 스케줄러를 통해 write 작업을 진행하기 때문입니다.
즉, DB 접근 횟수가 줄어들어 락이 짧게 유지되어 락 경합이 해소되었다고 판단됩니다.
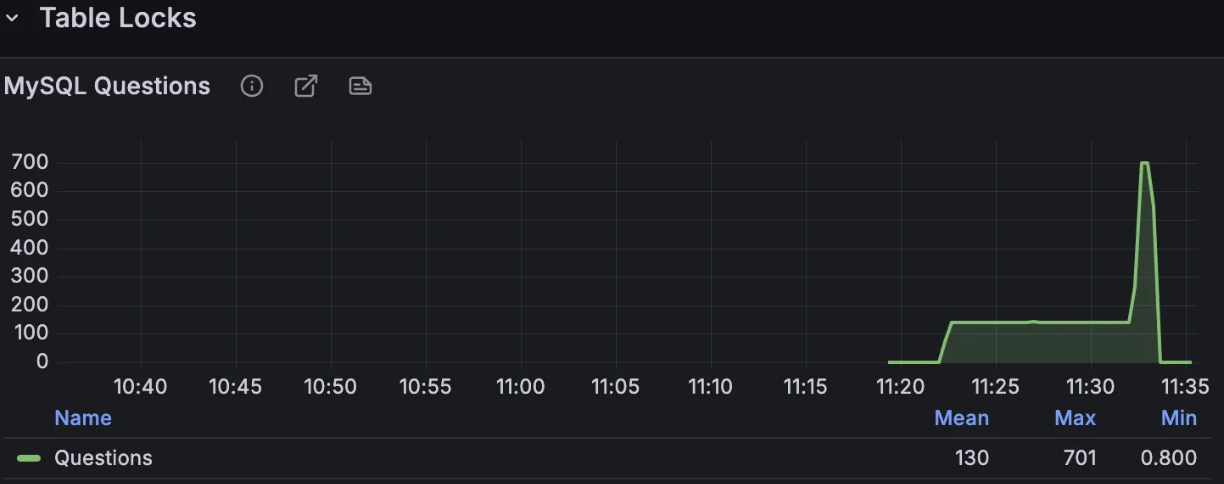
MySQL Questions
- 안정 구간: 180/s -> 140/s
- 스파이크 구간: 850/s -> 700/s
Redis에서 좋아요 상태를 캐시하고 실제 DB 반영은 배치 타이밍에만 일어나기 때문에 트랜잭션 및 질의 횟수가 자연스럽게 줄어든 결과입니다.
결론
Redis 도입을 통해 좋아요 API의 동시성 문제가 성공적으로 해결할 수 있었고, RDB의 락 경합 및 부하가 상당 부분 완화되었음을 확인할 수 있었습니다. 서비스의 안정성과 성능 향상에 기여할 수 있는 아키텍쳐를 구성하였습니다.
현재 인메모리에 좋아요 이벤트를 저장하고 있기 때문에, 이후에는 비동기 메세징 큐를 도입하여 레디스 서버의 유실 방지 및 스프링 이벤트 구조를 도입할 예정입니다
