기존 아키텍처 구조
현재 프로젝트는 아래와 같은 아키텍처로 구성된 상태입니다.
Spring Boot ↔ Redis (SET 구조) ↔ MySQL
사용자가 게시글 상세 페이지를 조회하면, 기본적인 게시글 정보(제목, 내용 등)와 함께 좋아요 수도 함께 반환됩니다. 이때 좋아요 수는 실시간성과 성능을 고려하여 RDB가 아닌 Redis의 Set 자료구조를 활용해 계산하고 있습니다.
// Redis SET size를 통해 좋아요 개수 계산
public long getLikeCount(Long articleId) {
return redisTemplate.opsForSet().size("article:likes:" + articleId);
}이 구조를 통해 MySQL의 부하를 줄이고 동시성 문제도 자연스럽게 해결했지만, 다음과 같은 두 가지 문제점이 발생하였습니다.
문제 1 – Redis 서버 재부팅 시 좋아요 수 0으로 조회되는 문제
Redis는 메모리 기반 저장소이기 때문에 서버가 다운되거나 재부팅되면 기존의 좋아요 정보가 모두 날아가버릴 수 있습니다. 이 경우, RDB에는 분명히 좋아요 정보가 남아 있음에도 불구하고 Redis에는 해당 키가 존재하지 않기 때문에 좋아요 수가 0으로 반환됩니다.
해결 방안 – Redis Warm-up
이 문제를 해결하기 위해, 애플리케이션 시작 시점에 RDB의 데이터를 Redis에 다시 적재하는 Warm-up 로직을 구현했습니다.
- 서버 시작 → Redis 좋아요 키 존재 여부 확인
- 키가 없다면 Kafka에서 과거 메시지 읽기
- Redis에 재적재이를 통해 Redis 유실 혹은 서버가 다운 됐을 경우에도 빠른 복구를 기대할 수 있습니다.
문제 2 – 스케줄러 기반 RDB 동기화 시 정합성 이슈
초기에는 좋아요 API가 호출되면 Redis에만 먼저 반영하고, 일정 주기로 동작하는 Spring Scheduler가 Redis 데이터를 RDB에 배치 저장하는 구조로 구현되어 있었습니다.
하지만 이 경우 다음과 같은 문제가 발생합니다
- Redis: 좋아요 수 10개
- RDB: 좋아요 수 9개 (아직 반영되지 않음)
- 이 때 Redis 서버 다운 → 좋아요 1개 정보 유실
즉, 스케줄러에 지정한 시간에 따라 Redis → RDB write 사이의 시간차로 인해 데이터 정합성이 깨질 수 있는 구조라고 판단하였습니다.
해결 방안 – Kafka 메시징 큐 기반 아키텍처로 개선
이를 해결하기 위해 Kafka와 같은 메시징 큐를 도입하게 된다면, 좋아요 이벤트 발생 시점에 LikeChange 객체를 Kafka로 발행하고, Consumer에서 해당 데이터를 비동기로 RDB에 적재할 수 있을 것 같았습니다.
1. Redis에 좋아요 상태 반영
2. Kafka로 이벤트 발행 (트랜잭션 커밋 이후)
3. Consumer가 Kafka 메시지를 읽고 RDB에 저장문제1에서 어플리케이션 재부팅(레디스 서버 유실시)을 하면 RDB의 데이터를 redis 서버로 적재하는 warm-up 과정을 진행하게 되는데, 이때 카프카의 특정 컨슈머에 해당 역할을 부여할 수 있을 것입니다.
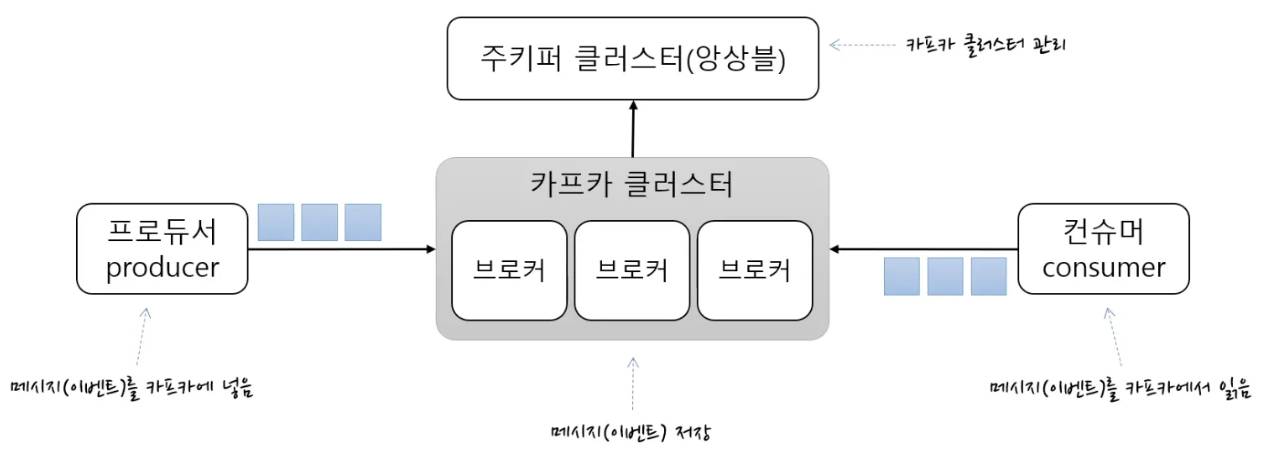
또한 이전에 간단하게 MSA를 경험하며 카프카를 사용해본 적이 있는데, 이때는 주키퍼를 사용해서 카프카 클러스터를 관리해야하는 구조였습니다.
하지만 KRaft라는 새로운 협의 프로토콜이 등장하게 되고, 이전에 주키퍼를 통해 카프카 브로커의 메타데이터를 관리하는 의존성을 제거할 수 있기에, 사용해보면 좋겠다는 생각이 들어 카프카 메세징 큐를 채택하게 되었습니다
KRaft는 Apache Kafka의 새로운 협의 프로토콜로, 주키퍼 없이 카프카 자체적으로 메타데이터 관리를 가능하게 합니다. 카프카 2.8 버전에서 처음 소개되었고, 3.3 버전에서 프로덕션 레벨 릴리스가 되었습니다. 카프카 3.6 버전까지는 주키퍼 모드와 KRaft 모드를 모두 지원하며, 4.0 버전부터는 KRaft 모드로만 사용 가능합니다
또한 발행에 실패하거나 Consumer가 실패할 경우를 대비하여 Outbox 패턴을 도입하여 이벤트 객체를 DB에 먼저 저장하고, Kafka 발행 후 상태를 갱신하는 구조를 적용한다면 더욱 안정적으로 서버 운영을 기대할 수 있습니다.
주키퍼 모드 vs KRaft 모드의 차이점은 아래 링크에서 자세히 확인할 수 있습니다.
Apache Kafka의 새로운 협의 프로토콜인 KRaft에 대해(1)
이번글에서는 앞으로 성능과 데이터 정합성을 고려한 설계를 고민하고 작성하였습니다.
다음 글에서는 카프카를 도입하여 겪었던 에러사항들과 도입 후 개선된점들을 모니터링을 통하여 정량적인 데이터를 분석해보겠습니다.
