
kafka를 도입한 후 부하 테스트를 진행하며 발생했던 현상들을 정리하였습니다.
0️⃣ 테스트셋
| 항목 | 내용 |
|---|---|
| Hardware / OS | MacBook Pro 14-inch (2021) · Apple M1 Pro · 16GB RAM · macOS Tahoe 26.0.1 |
| Environment | Localhost (Docker Compose: MySQL 8.0 · Redis latest · Kafka latest) |
| Spring Boot | 3.3.4 (Gradle, OpenJDK 21) |
| Tool | k6 |
| Spike Test | 5분간 초당 500명 요청 (VU 500명) |
| Recovery Test | 1분간 초당 20명 요청 (VU 30 → 50명) |
| Thresholds | p(95)<300ms, p(99)<500ms, 실패율 <5% |
| Pre-step | 200명 회원가입 → 로그인 → 게시글 1건 생성 후 테스트 수행 |
1️⃣ DBCP 확장 - HTTP + Async 스레드 동시 접근 문제
문제 인식
현재 좋아요 API는 단순한 기능이지만 내부적으로 다음 과정을 거칩니다.

즉, 하나의 요청에서 HTTP 요청 스레드와 비동기 스레드가 모두 DB에 접근합니다.
현재 HikariCP와 Executor 설정값은 다음과 같습니다.
// HikariCP 기본값
spring.datasource.hikari.minimumIdle=5
spring.datasource.hikari.connectionTimeout=10000
spring.datasource.hikari.maximumPoolSize=10
//비동기 스레드 풀 설정
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(10);HikariCP와 Executor의 동작 방식에는 약간의 차이가 있는데 다음 포스팅에 정리하겠습니다.
10(Async) + n(HTTP) + m(KafkaConsumer)
→ 동시 DB 점유 →connections.pending급상승

HikariCP 커넥션이 피크를 칠때, 커넥션 고갈로 인해 대기중인 스레드가 발생하는것을 확인하였습니다.
결과적으로 HTTP 응답 p99이 1초 이상 지연되는 현상이 확인되었습니다.
행동
✅ DBCP 사이즈 변경
최대 풀 사이즈를 10->30으로 늘리고, 기본 유휴 스레드 값을 5->10으로 변경하였습니다.
spring:
datasource:
hikari:
maximum-pool-size: 30
minimum-idle: 10
pool-name: HikariPool-synapse✅ existsById() 쿼리 최적화 검토 및 개선 과정
-
엔티티 조회 → 존재 여부 확인 로직으로 변경
기존findById()사용 시 JPA 1차 캐시에 엔티티가 적재되며, 단순 존재 확인만 필요한 경우에도 불필요한 객체 생성이 발생했습니다.
이에 따라 반환 타입을Optional<Article> → boolean으로 단순화하기 위해
existsById()를 사용하도록 수정하였습니다. -
JPA existsById() 내부 쿼리 분석
Hibernate에서existsById()실행 시, 실제로는SELECT COUNT(*) FROM ... WHERE id = ?형태의 쿼리가 실행됩니다.
MySQL InnoDB 엔진은EXISTS대신COUNT(*)집계 쿼리를 사용하므로 모든 행을 스캔할 가능성이 있다는 점을 확인했습니다. -
Native Query 기반의 최적화 시도
EXISTS서브쿼리를 사용해 즉시 종료되는 형태로 개선하기 위해existsByIdFast()메서드를 추가하였습니다.@Query(value = "select exists(select 1 from article_like where article_id = :articleId and user_id = :userId)", nativeQuery = true)그러나 MySQL은
EXISTS의 결과를TINYINT(1)형태(0 또는 1)로 반환하기 때문에
JPA에서boolean으로 직접 매핑하는 과정에서
ClassCastException(Long cannot be cast to Boolean)예외가 발생했습니다. -
대안 검토 및 최종 결정
CASE WHEN EXISTS(...) THEN TRUE ELSE FALSE형태로 변환하거나 0/1을 직접 사용하는 방식으로 해결할 수 있었으나, 해당 ID 컬럼이 PK(유니크 인덱스) 이므로 InnoDB가 인덱스를 이용해 단일 행만 탐색하고 즉시 종료함을 확인했습니다.- 따라서 성능상 실질적인 이점이 미미하다고 판단하여, 기본 JPA 메서드인
existsById()를 유지하기로 결정하였습니다.
결과

- 활성 커넥션 수는 30 중 약 20 수준에서 안정화
- p95 응답 시간은 1.1s → 480ms로 감소
- HikariCP 대기 스레드 0
단, 풀을 키우는 것은 임시 방편일 뿐
비즈니스 로직 단의 커넥션 점유 최적화가 필요하다고 생각하였습니다.
2️⃣ DLT(Dead Letter Topic) 도입 - Kafka Retry Loop 문제
문제 인식
Kafka 비동기 전송 중 DataIntegrityViolationException이 반복 발생했습니다.
이는 Consumer가 이미 존재하는 Like 데이터를 다시 INSERT하면서 Unique Key 제약 조건에 위배된 상황이었습니다.
Kafka는 해당 예외를 재시도 가능한 오류로 간주해 같은 메시지를 무한히 재처리했고, 이로 인해 다음과 같은 문제가 발생했습니다.
1. Retry Loop로 인한 Lag 폭증
2. DBCP 커넥션 피크 증가 (HikariCP maximumPoolSize=30, Async Executor maxPoolSize=10)
이 현상은 k6 부하 테스트에서는 감지되지 않았지만,
Spring 서버 로그와 Grafana 메트릭을 통해 Kafka Lag이 지속적으로 누적됨을 확인했습니다.

행동
❌ Rollback 무효화 (실패)
처음에는 DataIntegrityViolationException 발생 시 트랜잭션 rollback을 막기 위해 아래처럼 설정했습니다.
@Transactional(noRollbackFor = DataIntegrityViolationException.class) 그러나 내부적으로 여전히 rollback이 수행되어 문제를 해결하지 못했습니다.
정확한 이유는 파악하지 못했지만, 제 생각은 다음과 같습니다.
“listen 메서드에 noRollbackFor을 걸어도,
실제 DB 예외가 카프카 리스너 내부 스레드에서 발생하기 때문에 rollback이 계속 일어난다
우선 이 코드는 @KafkaListener 내부 비동기 처리 메서드에 붙어있습니다.
@KafkaListener(topics = "like-change", containerFactory = "immediateListenerContainerFactory")
@Transactional(noRollbackFor = DataIntegrityViolationException.class)
public void listen(LikeChange likeChange) { ... }Kafka의 리스너 컨테이너는 내부적으로 KafkaMessageListenerContainer → ListenerInvoker → invokeListener() 체인을 통해 메시지를 처리합니다.
이 시점에서 Kafka 내부의 트랜잭션은 논리 트랜잭션이기 때문에 rollbackOnly=true 를 마킹하고, Kafka 내부 트랜잭션의 부모 트랜잭션(물리 트랜잭션)이 rollback 되는 것입니다.
물리/논리 트랜잭션 이해하기
⬆ 해당 글에서 이전에 정리했던 개념과 같은 상황인것 같습니다.
즉, @Transactional(noRollbackFor)은 현재 스레드의 트랜잭션 관리 범위에서 발생한 예외에만 적용됩니다.
Kafka Listener는 내부적으로 별도 트랜잭션 경계를 만들기 때문에 rollback 방지가 적용되지 않습니다.
✅ 임시 대응: DLT 적용
임시 방안으로 @RetryableTopic을 통해 5회 재시도 후 DLT(Dead Letter Topic) 으로 메시지를 버리도록 구성했습니다.
@RetryableTopic(attempts = "5", dltTopicSuffix = ".dlt")
@KafkaListener(topics = "like-change", groupId = "like-group")결과
- Consumer 무한 루프 해소
- Kafka Lag 감소
다만, DLT는 복구 불가능한 메시지 처리를 위한 설계 요소로
이처럼 도메인 정합성 문제를 “버리는 방식”으로 해결하는 것은 바람직하지 않았습니다.
이에 따라 도메인 레벨에서 멱등성을 보장하는 구조로 개선하였습니다.
3️⃣ DLT 제거 및 도메인 레벨 멱등성(Idempotency) 검증
문제 인식
DLT로 무한 루프는 해소되었으나,
근본적으로는 Like 데이터 중복 생성이라는 도메인 정합성 문제가 남아 있었습니다.
행동
✅ 사전 검증(Pre-check) 로직 추가
Kafka Consumer에서 Like를 DB에 저장하기 전,
이미 Redis에 저장된 Like 상태를 확인하여 멱등성을 보장하도록 수정했습니다.
//to-be
boolean added = redisTemplate.opsForSet().isMember(KEY_PREFIX + articleId, userId.toString());
if (likeChange.added()) {
if (added) {
log.debug("Skip duplicate like: articleId={}, userId={}", articleId, userId);
return;
}
articleLikeRepository.save(ArticleLike.create(articleId, userId));
} else {
if (!added) {
log.debug("Skip non-existing like deletion: articleId={}, userId={}", articleId, userId);
return;
}
articleLikeRepository.deleteByArticleIdAndUserId(articleId, userId);
}RDB 접근을 최소화하기 위해 Redis 기반 검증을 진행하였고,
멱등성이 보장된 이후 ArticleLike 객체를 생성함으로써, 기존 로직(생성 후 검증)보다 JVM의 힙 메모리 낭비를 줄였습니다.
결과
- 중복 INSERT 완전 차단
- Kafka Lag = 0 유지
- DB 커넥션 점유율 40% → 20%로 감소
- 목적성에 맞지 않는 DLT 제거
4️⃣ Async 스레드 포화 및 트랜잭션 분리
문제 인식
Kafka 프로듀서가 전송 성공 시, Outbox 테이블의 이벤트를 즉시 삭제하는 로직을 비동기(Async) 스레드에서 수행하고 있었습니다.
즉, Kafka 전송 성공 콜백 내부에서 다음 코드가 실행되었습니다.
future.whenComplete((result, excepion) -> {
if (excepion == null) {
outboxService.deleteById(outboxEvent.getId());
RecordMetadata meta = result.getRecordMetadata();
} else {
log.error("failed to send LikeChange event (articleId={} userId={}): {}",
event.articleId(), event.userId(), excepion.getMessage(), excepion);
}
});그러나 비동기 스레드 풀이 포화되며 다음 예외(RejectedExecutionException)가 발생했습니다.
Caused by: java.util.concurrent.RejectedExecutionException:
Task java.util.concurrent.FutureTask@5f831c19[Not completed, task = org.springframework.aop.interceptor.AsyncExecutionInterceptor$$Lambda/...]
rejected from ThreadPoolTaskExecutor[Running, pool size = 10, active threads = 1, queued tasks = 10, completed tasks = 9953]
이는 Kafka 전송 직후 Outbox 삭제 트랜잭션이 비동기적으로 몰리면서,
Executor 큐가 한계에 도달해 발생한 문제였습니다.
행동
✅ 비동기 스레드 풀을 확장하고, 큐 용량을 늘려 스레드 대기를 완화했습니다.
executor.setCorePoolSize(10);
executor.setMaxPoolSize(30);
executor.setQueueCapacity(200);결과
- Async 스레드 대기 해소
최종 결과
✅ k6 부하 테스트
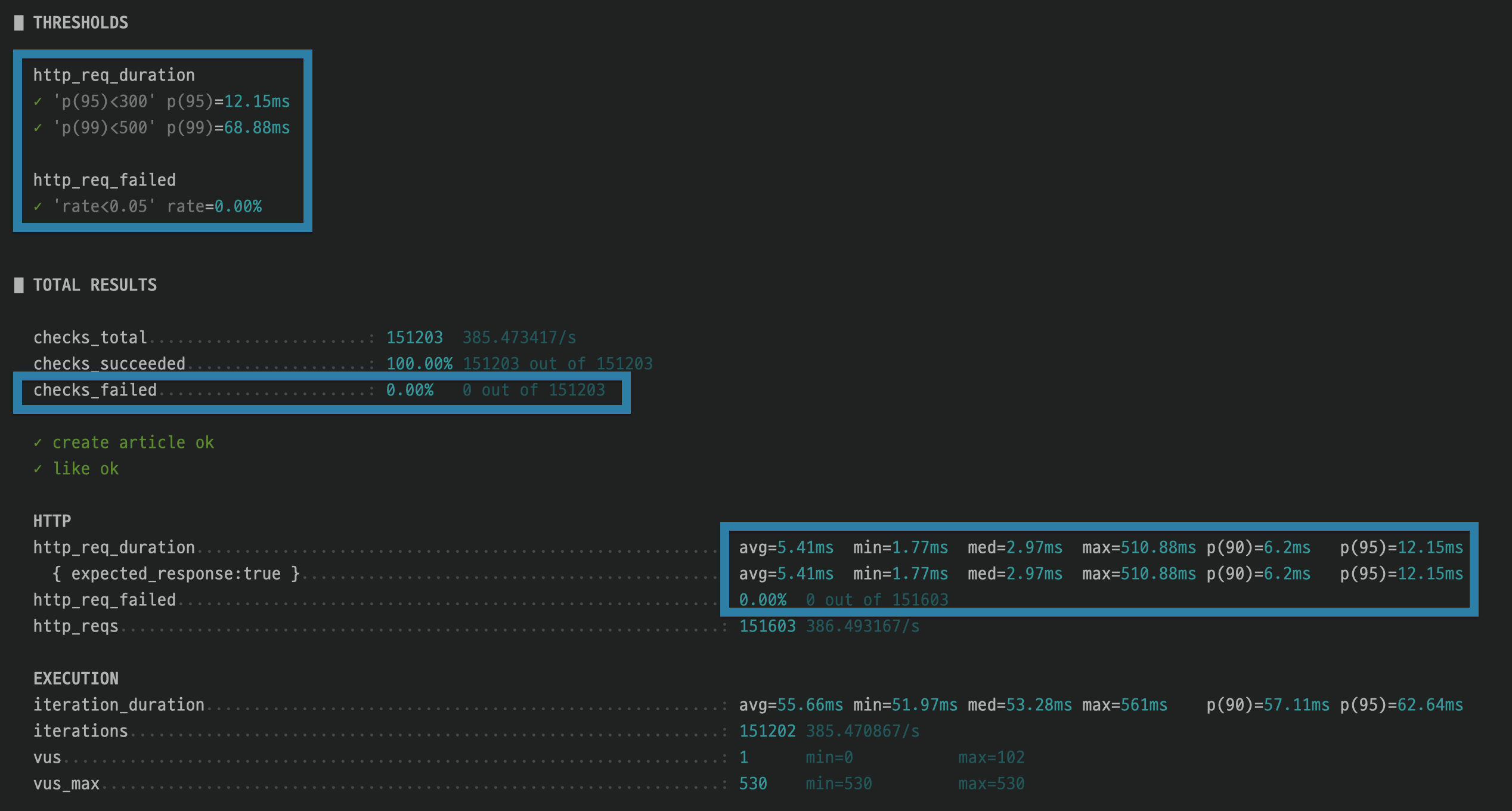
✅ 백로그 0 유지

✅ Grafana 지표
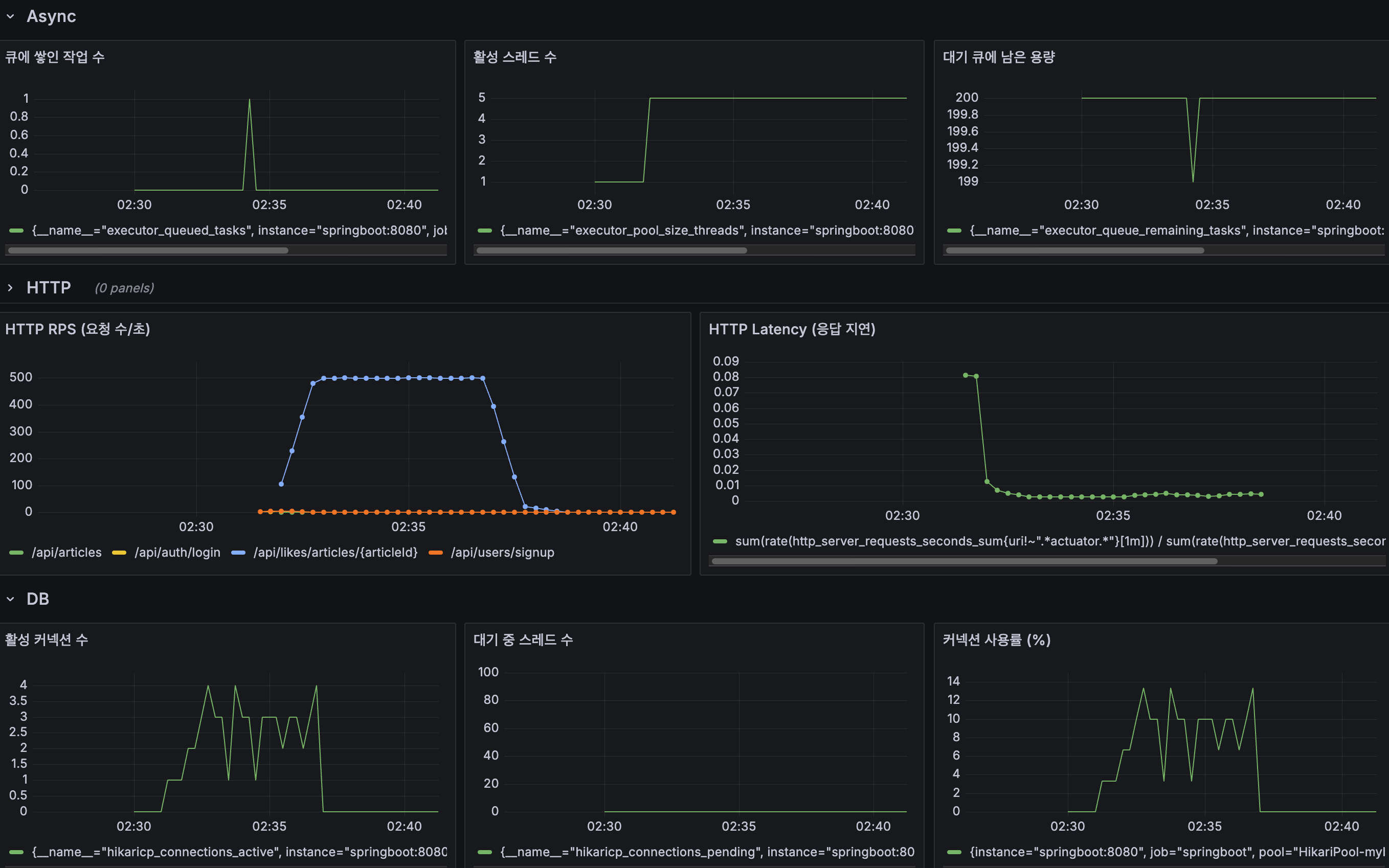
이후 작업
- Kafka Consumer 멀티 스레드 적용을 통한 병렬 처리 성능 향상
- 4️⃣번 과정 보강
- 프로듀서 Outbox 삭제 로직을 Hard Delete → Soft Delete로 변경하여 InnoDB의 락 경합을 줄이기(update, delete 쿼리 성능 파악)
