개요
Convolution Neural Network (CNN)은 이미지나 영상 데이터를 처리하는데 최적화된 neural network이다. 이 포스트에서는 기존 MLP와 차이점은 무엇인지, 이미지에서 CNN을 사용하는 이유는 무엇인지 알아볼 것이다.
1. Convolution in image
이미지에는 각 픽셀의 위치에 따른 색상 값이 정의되어 있다. RGB 컬러 이미지를 예로 들면, 가로와 세로의 좌표가 (28, 20)인 픽셀의 색상은 R, G, B 3개의 채널에 대응하는 각각의 색상값이 하나의 벡터로 결합되어 있다.
그러나 MLP 모델에서는 2차원 이상의 행렬을 한꺼번에 입력받는 것이 불가능하여 1차원의 벡터로 변환했는데, 이렇게 변환하면 이미지의 위치 정보가 소실되는 문제가 발생한다.
따라서 CNN에서는 이미지의 데이터를 1차원 벡터로 변형하지 않고 각 채널별 행렬과 이미지보다 크기가 작은 필터 또는 커널 (filter / kernel)이라는 행렬과 서로 convolution 연산을 수행한다. 이 필터를 이미지의 좌측 상단부터 우측 하단까지 일정한 픽셀 수만큼 이동 (stride)하면서 convolution 연산을 수행한다. Convolution 연산을 어떻게 수행하는지 아래 그림을 통해 살펴보자.
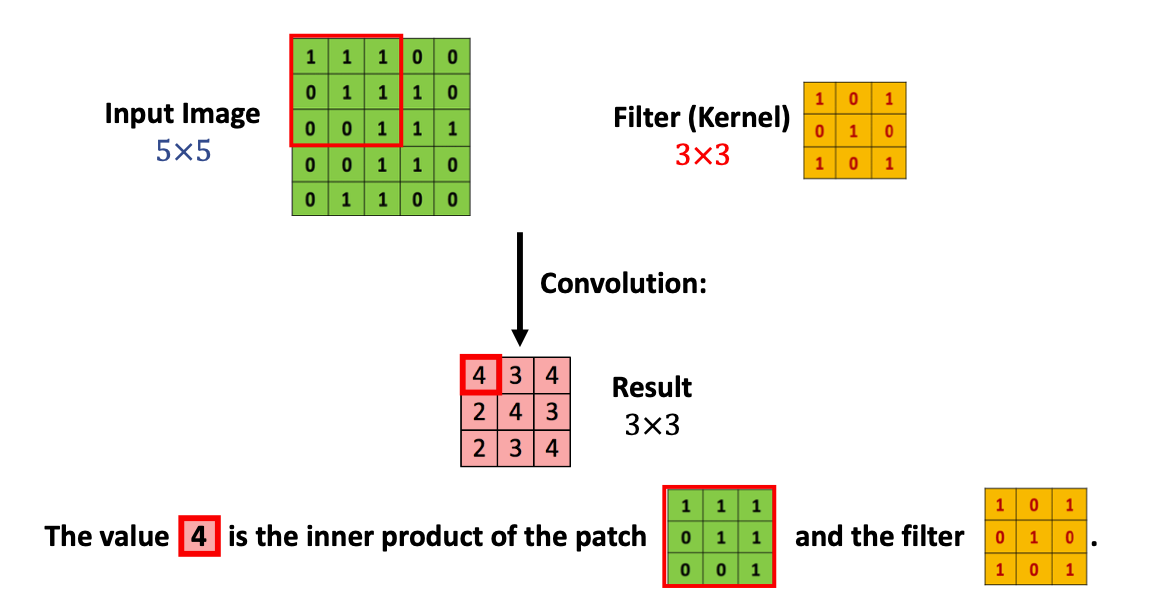 먼저 이미지의 좌측 상단부터 필터의 크기(3 3)만큼 행렬을 추출하여 필터와의 내적 (각 원소끼리의 곱의 합산)을 계산한다.
먼저 이미지의 좌측 상단부터 필터의 크기(3 3)만큼 행렬을 추출하여 필터와의 내적 (각 원소끼리의 곱의 합산)을 계산한다.
 출처: https://halfundecided.medium.com/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-cnn-convolutional-neural-networks-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-836869f88375
출처: https://halfundecided.medium.com/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-cnn-convolutional-neural-networks-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-836869f88375
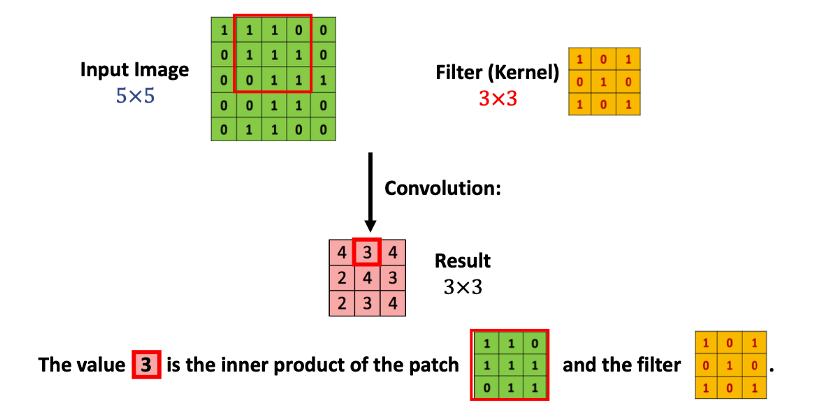
그런 다음 이미지의 좌측 상단에서 한 칸 오른쪽에 위치한 픽셀부터 필터의 크기만큼 행렬을 추출하여 다시 필터와의 내적을 계산한다. 이런식으로 반복하면 그림의 빨간색 3 3 행렬이 최종적으로 계산된다. 이 때 convolution 연산 과정에서의 입출력 데이터를 feature map이라고 하며, convolution할 입력 데이터를 input feature map, convolution된 출력 데이터를 output feature map이라 한다.
1) Padding
위 그림에서 원본 이미지 행렬과 output feature map의 크기를 비교해보자. output feature map의 크기가 원본 이미지에 비해 줄어들었다. 이 행렬에 대해 다시 convolution 연산을 수행하면 그 행렬의 크기는 원본 이미지보다 더 작게 줄어들 것이다.
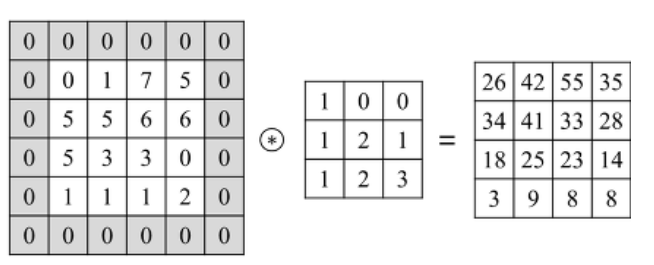
이렇게 convolution을 할 때마다 output feature map의 크기가 줄어드는 것을 방지하기 위해 아래 그림처럼 원본 이미지의 가장자리에 원소 0을 한줄로 둘러싼 뒤 convolution을 수행하면 원본 이미지와 크기가 동일해진다. 이러한 방식을 padding이라 부른다.
2) Stride
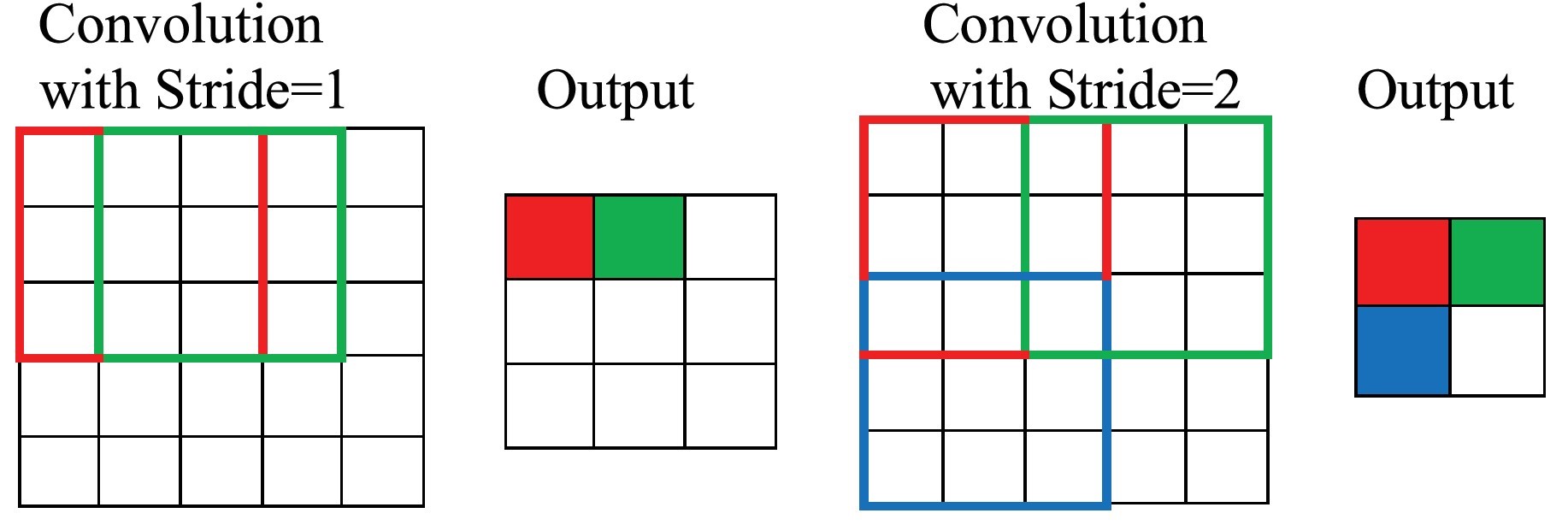
위 그림에서는 필터를 한 픽셀씩 움직이면서 convolution을 수행했다. 여기서 필터를 몇 픽셀씩 움직일지를 결정하는 것이 바로 stride이다. 아래 그림처럼 한 픽셀씩 움직이면 stride가 1이 되고, 두 픽셀씩 움직이면 stride가 2가 된다. stride를 크게 하면 feature map의 크기는 줄어들게 되지만 stride가 너무 크면 이미지 정보의 손실이 커지므로 적절한 크기의 stride를 사용해야 한다.
3) Pooling
Pooling 또한 feature map의 크기를 줄이는데 사용한다. 다만 stride와 달리 줄이는 방식에 차이가 있다. 아래 그림을 살펴보자.
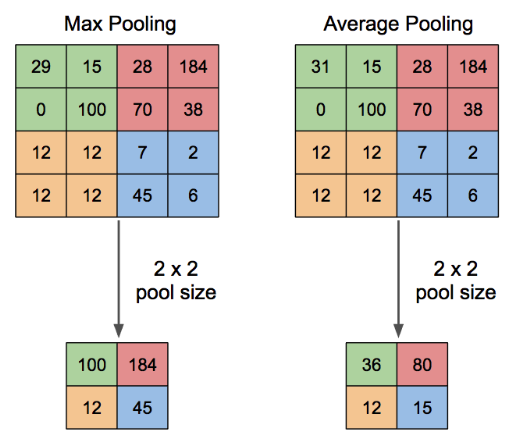 위 그림은 4 4의 feature map에서 2 2의 크기로 pooling을 적용하는 과정을 나타낸 것이다. 4 4의 feature map을 2 2 행렬 4개로 분할한 후, 각 행렬에서 원소의 최대값을 추출하는 과정을 max pooling, 평균값을 추출하는 과정을 average pooling 이라 한다.
위 그림은 4 4의 feature map에서 2 2의 크기로 pooling을 적용하는 과정을 나타낸 것이다. 4 4의 feature map을 2 2 행렬 4개로 분할한 후, 각 행렬에서 원소의 최대값을 추출하는 과정을 max pooling, 평균값을 추출하는 과정을 average pooling 이라 한다.
2. CNN model creation
이제 MNIST 데이터셋을 이용하여 CNN 모델을 학습하고 평가하는 과정을 살펴보자. MNIST 데이터셋을 DataLoader 클래스의 객체로 만드는 과정은 이전 포스트에서 설명했으니 이 과정은 생략하고, 여기서는 클래스를 이용하여 CNN 모델을 생성하는 과정을 알아보자.
class MyCNN(nn.Module):
"""Simple CNN model for classify MNIST."""
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, padding=1)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(
in_channels=64, out_channels=32, kernel_size=3, padding=1
)
self.avgpool = nn.AdaptiveAvgPool2d(4)
self.fc = nn.Linear(in_features=32 * 4 * 4, out_features=10)
def forward(self, x):
"""Forward propagation inherited from class `torch.nn.Module`."""
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.avgpool(x)
x = self.fc(x.flatten(1))
return x위 모델은 MNIST 이미지 하나를 입력받아 숫자 0~9에 대한 점수를 크기가 10인 벡터로 산출하는 모델이다. 모델의 입출력 결과는 이전 포스트에서 언급한 MLP 모델과 동일하나 내부 구조의 차이가 있다. 이 모델은 2개의 convolution layer와 1개의 average pooling layer, 1개의 linear layer가 있다.
PyTorch에서 convolution layer는 torch.nn.Conv2d 클래스를 사용한다. 클래스의 입력 변수를 살펴보자.
in_channels와 out_channels는 각각 입력 이미지의 채널 수와 출력된 feature map의 개수를 뜻한다. 여기서는 입력 이미지가 흑백인 MNIST이므로 in_channels의 값은 1이 되어야 한다. out_feature수는 64로 설정되어 있으므로 첫번째 convolution layer를 통과했을때 64개의 feature map이 만들어진다.
kernel_size는 convolution 연산을 수행하는 필터/커널의 크기를 뜻한다. 커널의 행렬 크기가 정사각형이면 숫자 하나만 써도 된다. 여기서는 kernel_size의 값이 3이므로 3 3 커널이 사용되었다.
padding은 1항에서 언급한 padding의 크기이다. 여기서는 padding의 값이 1이므로 이미지의 feature map의 가장자리에 한 줄로 원소 0의 값을 둘러싼다. padding의 값은 feature map의 가장자리를 몇 줄로 둘러쌀지를 결정하며, 입력 이미지의 크기를 유지하려면 이 값은 커널의 크기에서 1을 뺀 값의 절반으로 설정하면 된다.
첫번째 convolution에서 두번째 convolution layer로 넘어가기 전에 ReLU activation 함수를 적용한다. convolution 연산 또한 선형성을 유지하는 연산이므로 convolution만 반복해서는 모델의 비선형성을 얻을 수 없다. 따라서 두 convolution layer 사이에 비선형성을 추가하는 activation 함수를 추가했다.
두 번의 convolution layer를 통과한 feature map의 크기는 원본 이미지와 동일하지만 그 개수는 32개로 증가했다. 여기서 최종 결과를 출력하기 전 average pooling을 적용하여 feature map의 크기를 4 4로 축소하고 이를 1차원 벡터로 변형한 후 linear layer에 입력하여 크기가 10인 벡터를 얻게 된다. 이 때 적용되는 linear layer를 fully connected layer라 한다.
