개요
이전 포스트까지는 입력 변수 및 출력값이 각각 1개씩 있는 스칼라 데이터, 즉, 형태의 데이터를 학습하고 예측하는 과정을 알아봤다. 이제는 입력 데이터가 스칼라값이 아닌 이미지이고, 출력값은 이미지의 이름 (레이블)에 해당하는 모델을 만들어 이를 학습하는 과정을 알아보자.
1. Data structure
1) Input Image Data
이미지 파일은 크게 비트맵 그래픽 형식과 벡터 그래픽 형식으로 나뉘며, 압축 방식에 따라 JPEG, PNG, GIF 등 여러 종류의 형식이 있다. 딥러닝에서 다루는 이미지는 비트맵 그래픽 형식을 갖는 이미지로 한정하며, 비트맵 형식 이미지는 픽셀이라 불리는 아주 작은 점들이 모여 하나의 이미지를 만들어낸다.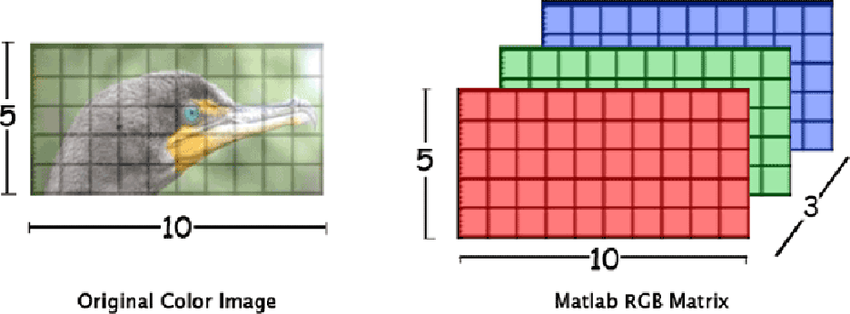 출처: https://www.researchgate.net/figure/Color-image-representation-and-RGB-matrix_fig15_282798184
출처: https://www.researchgate.net/figure/Color-image-representation-and-RGB-matrix_fig15_282798184
일반적인 컬러 이미지는 R (빨강), G (초록), B (파랑)의 색상값이 각 픽셀별로 정의된 각각의 행렬이 하나의 3차원 텐서로 결합된 구조를 갖고 있다. 한 픽셀의 색상값은 0에서 255사이의 값 중 하나를 가지며 3개의 행렬이 겹쳐있기 때문에 특정 위치의 색상값은 형태의 벡터로 나타낼 수 있다.
2) Output Label, Class
이미지를 분류하기 위해서는 각 이미지가 무엇인지, 이미지에 대응하는 이름이 있어야 한다. 이러한 이름을 레이블 (label) 또는 클래스 (class) 라고 부른다. 예를 들어, 아래의 CIFAR10 데이터셋을 분류한 결과에서 '비행기', '자동차' 등의 텍스트가 레이블에 해당한다. 딥러닝 모델을 이용한 이미지 분류는 이미지를 보고 그 이미지가 어떤 레이블에 해당하는지를 선택하는 것을 목표로 한다.  출처: https://gruuuuu.github.io/machine-learning/cifar10-cnn/
출처: https://gruuuuu.github.io/machine-learning/cifar10-cnn/
2. PyTorch DataLoader generation
PyTorch로 모델을 생성하기 이전에 필요한 작업이 하나 있다. 바로 전체 데이터셋을 저장하는 Dataset과 데이터 샘플을 추출하는 DataLoader 클래스를 정의하는 것이다. 두 클래스에서는 어떤 데이터를 학습에 사용하는지, 데이터 샘플을 추출할 때 옵션 등을 지정할 수 있다. 지금부터 데이터를 학습에 사용하는 방법과 데이터 샘플을 추출하는 방법을 알아보자.
1) Dataset
데이터셋 (dataset)이란 모델을 학습하거나 성능을 평가할 때 사용하는 모든 데이터들의 집합을 말한다. 이미지 분류에서는 이미지와 그에 맞는 레이블이 하나의 쌍으로 구성되어야 하는데, 이러한 한 쌍을 데이터 샘플 (data sample)이라 하고 모든 데이터 샘플이 모여 하나의 데이터셋이 된다.
(1) Datasets from PyTorch
PyTorch에서는 딥러닝 튜토리얼 용도로 torchvision.datasets 패키지에서 특정 데이터셋을 제공하고 있다. 이를 이용하면 데이터셋을 쉽게 구성할 수 있다. 예시로 MNIST 데이터셋을 만들어보자.
import torchvision
from torchvision import transforms
training_dataset =
torchvision.datasets.MNIST(
root="../data/MNIST",
train=True,
transform=transforms.ToTensor(),
download=True,
)
test_dataset =
torchvision.datasets.MNIST(
root="../data/MNIST",
train=False,
transform=transforms.ToTensor(),
download=True,
)MNIST 클래스를 사용하면 MNIST 데이터셋을 생성할 수 있다. 그러면 사용 가능한 옵션을 살펴보자.
root는 데이터셋을 저장하거나 이미 저장되어 있는 경로에 해당한다. 이 때, download 옵션을 True로 설정하면 해당 경로에 데이터셋이 존재하지 않으면 다운로드할 수 있다. 물론 데이터셋이 해당 경로에 이미 존재하면 다운로드 과정을 생략한다.
train 옵션은 training_dataset과 test_dataset에 대해 다르게 설정했다. 그래서 모델의 학습에 사용할 데이터셋과 성능 평가에 사용할 데이터셋을 따로 구분할 수 있다. 왜냐하면 모델이 좋은 성능을 보이기 위해서는 학습하지 않았던 데이터도 정확히 예측하거나 분류할 수 있어야 하기 때문이다.
transform 옵션에서는 이미지에 적용할 변환을 정의한다. PyTorch에서 다운받은 데이터셋의 이미지는 모두 PIL (Python Image Library) 객체로 저장되어 있다. 따라서 이를 모델이 입력받을 수 있는 텐서의 형태로 변환하는 과정이 필요한데, torchvision.transforms 패키지의 ToTensor 클래스가 이 과정을 수행한다. 이외에도 다양한 변환을 수행할 수 있는데, 여러 개의 변환을 수행하려면 Compose 클래스에 수행할 변환을 하나의 리스트로 묶어 이를 입력 변수로 만들면 된다.
데이터셋의 생성 옵션은 데이터셋 종류마다 약간씩 차이가 있으니, 각 데이터셋에서 사용 가능한 옵션은 torchvision의 Built-in Datasets 항목을 참고하기 바란다.
(2) Custom Dataset
PyTorch에서 기본으로 제공하는 데이터셋 이외에 사용자가 별도로 구축한 데이터셋을 사용하려면 torch.utils.data.DataLoader 클래스에서 사용 가능하도록 torch.utils.data.Dataset 클래스를 상속받는 객체를 만들어야 한다. 먼저 데이터셋 클래스를 만들어보자.
class ImageDataset(Dataset):
def __init__(self):
self.image_file_path = './data/images'
self.label_file_path = './data/labels'
self.image_file_list = sorted(os.listdir(self.image_file_path))
self.label_file_list = sorted(os.listdir(self.label_file_path))
self.transform = transforms.Compose(
[
transforms.Resize((224, 800)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
),
]
)
def __len__(self):
return len(self.image_file_list)
def __getitem__(self, index):
img = self.image_file_list(index)
img_tensor = self.transform(img)
label = self.label_file_list(index)
sample = {"image": img_tensor, "label": label}
return sample클래스를 만들 때 반드시 구현해야 하는 메소드 3개가 있는데, 바로 __init__, __len__, __getitem__ 이다. 이 메소드는 Python에서 기본으로 제공하는 특수한 메소드로, 매직 메소드 (magic method)라 불린다. 각 메소드가 어떤 역할을 하는지는 따로 검색하도록 하고, 여기서는 메소드 내부에서 어떤 작업을 수행하는지 알아보자.
우선 __init__ 메소드에서는 이미지와 레이블이 저장된 폴더 경로를 지정하여 디렉토리 내 모든 파일 이름을 리스트로 저장한다. 그리고 각 이미지에 Resize, Normalize, ToTensor 변환을 적용한다.
__len__ 메소드에서는 디렉토리에 저장된 이미지 또는 레이블 개수를 반환한다. 이미지와 레이블 개수는 서로 동일하니 어느 것을 호출해도 무방하다.
__getitem__ 메소드에서는 변환된 이미지와 그에 상응하는 레이블을 한 쌍의 딕셔너리 형태로 반환한다. 이는 DataLoader 클래스의 객체를 반복적으로 호출할 때 사용된다.
2) DataLoader
torch.utils.data.DataLoader 클래스는 데이터셋에서 데이터 샘플을 하나씩 호출할 수 있도록 하는 반복 가능한 클래스다. DataLoader 클래스는 앞서 만들었던 Dataset 클래스의 객체를 입력 인자로 사용하고, 그 외에 여러 옵션들이 있다. 각 옵션들에 대해 알아보자.
train_dataloader =
DataLoader(
training_dataset, batch_size=1000, shuffle=True,
num_workers=16, pin_memory=True
)
test_dataloader =
DataLoader(
test_dataset, batch_size=100, shuffle=True,
num_workers=16, pin_memory=True
)batch_size는 하나의 batch에 포함될 데이터 샘플의 개수를 지정한다.
shuffle은 1회 학습 시 데이터 샘플의 순서를 무작위로 변경할 때 사용한다. shuffle을 사용하지 않고 순차적으로 모델 학습을 진행하면 모델이 데이터 샘플의 순서까지 학습할 수 있다. 그러면 모델 성능 평가 시 해당 데이터셋에 대한 분류를 정확하게 하지 못할 가능성이 커지기 때문에, shuffle 옵션을 True로 설정하여 데이터 샘플을 무작위로 추출하여 학습하는 것이 좋다.
num_workers 옵션은 DataLoader에서 데이터 샘플을 추출할 때 멀티프로세싱을 사용하여 작업 속도를 높일 때 필요하다. num_workers의 값은 프로세스 개수로, CPU의 프로세스 개수 이내로 지정한다.
pin_memory 는 GPU로 모델 학습 시 데이터 샘플을 GPU의 메모리 공간으로 전송할 때 전송 속도를 높일 수 있는 옵션이다. GPU로 학습할 때 사용하는 것이 좋다.
이외에도 sampler와 collate_fn 옵션으로 데이터 샘플을 추출하는 방식과 추출한 데이터 샘플을 하나의 batch에 결합하는 방법을 사용자가 직접 구현할 수 있다. DataLoader에는 여기서 설명한 옵션 외에 다른 옵션들도 있으니 기타 옵션에 대한 상세 설명은 PyTorch 공식 홈페이지를 참고하기 바란다.
3. MNIST Classification with MLP
이제 MNIST 데이터셋을 이용해 MLP 모델을 학습하고 그 성능을 테스트하는 과정을 구현해보자. MNIST는 0~9까지의 숫자에 대한 사람의 손글씨 이미지를 모은 데이터셋으로, 이미지 크기는 모두 28 28 픽셀인 흑백 이미지다.
1) MLP model creation
2절에서 PyTorch의 torchvision.datasets 패키지에서 제공하는 데이터셋으로 클래스를 생성하고 이를 DataLoader의 객체로 만드는 과정을 알아봤다. 이제 MLP 모델을 만드는 과정을 살펴보자.
model =
nn.Sequential(
nn.Linear(in_features=1 * 28 * 28, out_features=100),
nn.SiLU(),
nn.Linear(in_features=100, out_features=10)
).to(device)MLP 모델의 입력 데이터는 1차원 벡터여야 한다. 하지만 이미지는 3차원 텐서이므로 이를 1차원 벡터로 변환해야 하는데, 이를 위해 이미지의 가로, 세로, 채널 수를 모두 곱한 1차원 벡터로 변환한다. MNIST는 이미지 크기가 28 28이고 흑백 이미지이므로 채널 수는 1인데, 이를 사전에 모르고 있으면 어떻게 변환할 수 있을까? 그러면 다음과 같이 모델을 생성하기 이전에 이미지 크기 및 채널 수를 알 수 있다.
>> sample_image, sample_label = next(iter(train_dataloader))
>> sample_image.shape
(100, 1, 28, 28)DataLoader에서 정의한 학습 데이터셋에서 Python 빌트인 함수인 iter와 next를 호출하면 임의로 1개의 데이터 샘플을 추출하여 그 정보를 알 수 있다. 샘플 이미지의 shape 속성을 호출하면 (batch_size, channels, height, width) 형태로 튜플이 반환된다.
본 예시에서 생성한 MLP 모델은 MNIST 이미지를 입력받아 그 이미지가 0~9 중 어느 숫자에 해당하는지를 판별하므로 최종 출력 데이터는 길이가 10인 벡터여야 한다. 이 벡터는 숫자 0에서 9에 대한 각각의 점수 값을 나타내며, 그 중에 가장 높은 값 하나가 모델이 판별한 숫자에 해당한다. 그래서 마지막 linear layer의 out_features 값은 10이 되어야 한다.
그 다음에 모델이 판별한 숫자가 실제 이미지에 대응하는 숫자와 일치하는지를 확인하여 모델이 숫자를 정확하게 맞추도록 하는 것을 목표로 하고 있다.
2) Model training & evaluation
(1) Loss function in Classification
Regression에서는 loss function으로 L1 loss 또는 L2 loss를 주로 사용했다. 그러나 Classification에서는 엔트로피 (entropy)를 기반으로 하는 loss function을 사용한다.
Entropy란 정보 이론에서 어떤 상태에서의 불확실성을 나타내는 척도를 말한다. 예를 들어, 사건 가 발생할 확률이 높으면 에 대한 엔트로피는 작고, 반대로 발생할 확률이 낮으면 엔트로피가 크다고 할 수 있다.
이제 본 예시에 엔트로피를 적용해보자. 만약 모델이 MNIST 데이터셋 중 하나의 이미지에 숫자 0~9로 각각 판단할 확률을 계산했다면, 이들을 각 숫자에 대한 엔트로피 값으로 정량화할 수 있다. 이 때, 어떤 숫자로 판단할 확률이 높으면 엔트로피는 낮아지고, 해당 숫자로 판단할 확률이 낮으면 엔트로피는 커지기 때문에 classification에서 엔트로피를 loss 값으로 사용할 수 있다. 그러면 엔트로피를 계산하는 과정을 구체적으로 살펴보자.
(2) Logits and Softmax
본 예시를 간소화하여 숫자 0~9까지 10개의 숫자 대신에 0~2까지 3개의 숫자만 분류한다고 가정하자. 이 때 모델이 계산한 벡터를 라고 하면 의 형태가 되며, 원소 는 숫자 0, 1, 2에 대한 점수에 해당한다. 이 때 해당 점수 값을 logit 함수의 값이라고 할 수 있다.
logit 함수의 값은 에서 사이의 값을 가질 수 있기 때문에 이 값들이 확률분포를 따르도록 하려면 softmax 함수를 사용해야 한다. Softmax 함수는 각 logit 값에 지수함수를 취한 뒤, 그 값들의 총합으로 나눈 값이다. 수식으로 나타내면 다음과 같다.
즉, 예시에서 의 원소에 softmax 함수를 적용하면 다음과 같이 계산할 수 있다.
Softmax 함수는 두가지 특징이 있다. 먼저, 각 logit 값에 지수함수를 취했기 때문에 이 값은 항상 양수가 된다. 그리고 그 값을 모든 logit 값에 지수함수를 취한 값의 총합으로 나누었기 때문에 그 결과값은 항상 0에서 1사이의 값을 가진다. 따라서 softmax 함수의 결과값은 0에서 1사이의 확률분포를 따른다고 할 수 있다.
(3) One-hot Encoding
이제 각 클래스에 대한 모델의 엔트로피를 계산해보자. 모델이 계산한 각 클래스에 대한 확률분포는 softmax 함수를 이용해 계산했다. 그러면 이 결과를 실제 레이블에 대한 확률분포와 비교하는 과정이 필요하다.
그런데 실제 레이블은 텍스트로 저장되어 있기 때문에 이를 각 클래스에 대한 확률분포로 변환해야 한다. 이는 one-hot encoding을 사용하여 변환할 수 있다. One-hot encoding이란 모든 클래스에 대해 참인 클래스의 원소값만 1이고 나머지 클래스에 대한 원소값은 모두 0인 벡터로 변환하는 방법을 말한다.
2.2).(2)절의 예시에서 레이블 0, 1, 2에 대해 각각 one-hot encoding을 적용하면 인 벡터로 변환된다. 즉, 레이블 1에 대해 클래스 1로 판단할 확률은 1이고 나머지 클래스 0과 2로 판단할 확률은 0인 확률분포로 생각할 수 있다.
(4) Cross Entropy Loss Function
그러면 실제 레이블에 대한 모델이 계산한 확률분포의 엔트로피를 계산해보자. 이 때 엔트로피는 다음과 같이 계산할 수 있다.
여기서 는 실제 레이블, 는 모델이 계산한 클래스 로 판단할 확률이다. 예를 들어, (2)절의 이고 실제 레이블이 1일 때 엔트로피 은 다음과 같이 구한다.
이 때의 엔트로피 값을 cross entropy (교차 엔트로피)라고 하며, 이 cross entropy는 classification에서의 loss 값으로 사용된다.
3) Implementation in PyTorch
이제 PyTorch로 위 과정들을 모두 구현해보자. 이를 위해 loss function은 cross-entropy loss function을 사용하고, 모델의 매개변수 optimizer는 learning rate가 0.001인 Adam을 사용했다. 그리고 1 epoch 당 학습과 성능 평가를 반복하여 학습이 제대로 되고 있는지, 모델의 성능은 점점 개선되는지를 확인한다.
optimizer = Adam(model.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
num_epochs = 200
for epoch in range(num_epochs):
# Start model training
model.train()
for image, label in train_dataloader:
image, label = image.to(device), label.to(device)
pred = model(image.flatten(1))
loss = loss_fn(pred, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Loss: {loss:.3f}, Epoch: {epoch + 1} / {num_epochs}")
# Test the model for every epoch
model.eval()
with torch.no_grad():
correct, total = 0, 0
for image, label in test_dataloader:
image, label = image.to(device), label.to(device)
pred = model(image.flatten(1))
pred_label = torch.max(pred, 1)[1]
total += len(label)
correct += (pred_label == label).sum().item()
print(f"Test Accuracy: {100 * correct / total}%")>>> Loss: 1.708, Epoch: 1 / 200
Test Accuracy: 72.58%
Loss: 1.005, Epoch: 2 / 200
Test Accuracy: 82.82%
Loss: 0.633, Epoch: 3 / 200
Test Accuracy: 85.91%
Loss: 0.483, Epoch: 4 / 200
Test Accuracy: 88.24%
...
Loss: 0.012, Epoch: 199 / 200
Test Accuracy: 97.55%
Loss: 0.015, Epoch: 200 / 200
Test Accuracy: 97.53%1)절에서 언급했듯이 MLP 모델의 입력 데이터는 1차원 벡터가 되어야 한다. 따라서 forward propagation을 수행할 때 이미지를 1차원 벡터로 변환해야 하는데, 이를 위해 flatten(1) 메소드를 호출하여 1차원 벡터로 변환한다.
그런데 위 코드에서는 생략된 과정이 있다. 바로 모델이 계산한 logit 값을 softmax 함수를 적용하여 확률분포로 변환하는 과정과 실제 레이블에 one-hot encoding을 적용하는 과정이다. 그럼에도 불구하고 loss 값을 문제없이 계산하는 것을 확인할 수 있는데, 그 이유는 무엇일까?
PyTorch에서 정의된 cross-entropy loss function은 torch.nn.CrossEntropyLoss 클래스 또는 torch.nn.functional.cross_entropy 함수다. 그런데 이 함수에는 softmax를 취해 엔트로피를 계산하는 과정이 포함되어 있다. 즉, softmax 변환 후 로그함수를 취하는 Log-softmax (torch.nn.LogSoftmax)와 그 값에 클래스 확률을 곱해 음의 값을 취하는 negative log-likelihood (torch.nn.NLLLoss)가 결합된 함수다. 따라서 PyTorch의 cross-entropy loss를 계산할 때는 모델의 logit에 softmax 변환을 적용한 값이 아닌 logit값 자체를 함수의 입력값으로 사용해야 한다.
