
| 작성 배경
현재 졸업 프로젝트에서 "믿어방"이라는 서비스를 기획하고 개발하는 중에 있다.

서비스 "믿어방"을 간략히 소개하자면,
부동산 관련 배경 지식이 부족한 사회초년생들을 위한 '부동산 문서 분석&해설 서비스'이다.
여러 기능이 있지만, 핵심 기능 중 하나는 [독소 조항 판별] 기능인데,
주택임대차계약서를 촬영하면, 계약 내용(특히 특약 사항)을 분석해 해당 조항이 독소 조항인지, 나에게 불리한 조항인지 아닌지 판별해 알려준다.
그리고 이 독소 조항 case 검출을 구현하려면 한국어 유사 문장 판별 기술이 필요하다.
한국어 문장 사이 유사도를 검사하기 위해 1) konlpy 라이브러리와,2) tf-idf의 원리를 이용해 기능을 구현한 과정을 정리하고자 한다!
+
또한 부동산 문서 특성 상, 촬영된 사진에 개인정보가 포함되어있을 확률이 높다.
Client-side에서 이미지에 개인정보가 있는지 판단한 후, 그 부분을 마스킹 처리해 서버에 보내는 기술도 필요해 구현하였다.
(이 부분은 번외로 짧게 작성하고자 한다.)
| 목차
- 자연어 처리란?
- 한국어 자연어 처리가 어려운 이유
- 한국어 자연어 처리 기본 개념
- 임베딩
- 문장 유사도 계산법
- 한국어 문장 유사도 계산하기
- 형태소 분석 추가하기
- 형태소 분석기 비교 분석
- 코드 보완
- TF-IDF 적용해 계산하기
- tf-idf 예제
- 코드 보완
- (번외) 이미지 속 개인정보 마스킹하기
- Tesseract.js
| 자연어 처리란?

우선, 자연어 처리란 뭘까?
구글 최상단에 뜨는 검색 결과는 다음과 같다.
NLP(Natural Language Processing, 자연어 처리)는 인공지능의 한 분야로서 머신러닝을 사용하여 텍스트와 데이터를 처리하고 해석합니다. 자연어 인식 및 자연어 생성이 NLP의 유형입니다.
머신 러닝이 핫하다보니, NLP(자연어 처리)라 하면 대부분 자연어를 다루는 인공지능의 의미로써 많이 사용하는 것 같다.
하지만 실제론 이보다 더 넓은 의미로써도 해석 가능한데,
우리가 일상적으로 사용하는 언어(자연어)는 컴퓨터가 바로 이해할 수 없다. 이를 컴퓨터가 이해할 수 있는 방식으로 처리하는 과정을 ‘자연어 처리’ 기술이라고 한다.
라고도 이해 할 수 있다.
내가 이 포스팅에서 말하는 '자연어 처리'란 후자의 경우이다!
🙄 왜 ‘한국어’의 자연어처리(NLP)는 유독 어려울까?

개발을 위해 자료 조사 하면서 느낀 것은
'영어 자연어 처리는 자료가 이렇게 많은데, 왜 유독 한국어 자연어 처리는 레퍼런스가 한개도 없지?' 였다.
이는 나라별로 언어가 가지고 있는 특징이 다르기 때문이다.
특히 우리 한국어는 어간에 접사가 붙고, 의미적 기능과 문법적 기능을 하는 부분이 한 단어에 함께 쓰이는 '교착어'의 형태를 띄고 있다.
'교착어'인 한국어가 자연어 처리에 어려운 이유는 다음과 같은 예시를 보면 바로 이해 할 수 있다.

1. 접사가 붙으면 의미가 바뀐다!
예를 들어, ‘고양이’라는 명사에 접사를 붙여 문장을 만들어 보자.
‘고양이(어간)’ + ‘를(접사)’일 때는 ‘고양이’가목적어가 되지만,
‘고양이(어간)’ + ‘가(접사)’일 때는 ‘고양이’가 주어가 되어 같은 언어가 쓰이더라도 문장 내에서의 문법적 기능이 달라지는 걸 볼 수 있다.

2. 단어들의 순서가 너무 유연하다
나는 밥을 먹으러 간다.
밥을 먹으러 나는 간다.
나는 간다, 밥을 먹으러.
위 처럼 단어의 순서를 바꾸어도 의미는 바뀌지 않는다.
어순이 제각각이지만 의미는 동일한 문장인데, 컴퓨터 입장에선 이 문장들을 동일한 정보로 처리하는 것이 매우 어렵다.

3. 띄어쓰기 규칙이 모호하다...
아버지가방에들어가신다 라는 문장은 어떻게 띄어 쓰냐에 따라 아버지가 가방에 들어갈수도, 방에 들어 갈 수도있다.
사람이야 앞 뒤 맥락을 보고 알맞게 해석 할 수 있지만,
만약 컴퓨터에게 띄어쓰기를 하지 않은 뭉텅이로 작성한 텍스트를 제공한다면, 컴퓨터는 이를 정확하게 구분해 해석하는 것이 어렵다.
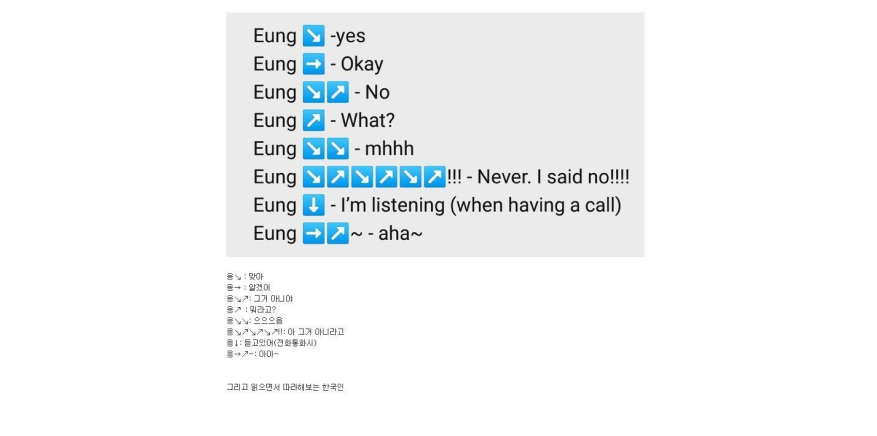
4. 평서문과 의문문의 생김새 차이가 적다.
점심 먹었어. (I had lunch.)
점심 먹었어? (Did you have lunch?)
영어에 비해 한국어는 평서문/의문문의 차이가 크지 않아 컴퓨터가 이해하기 어렵습니다.
위 처럼 마침표를 물음표로 바꾸기만 했는데 완전히 다른 뜻의 문장이 된다. 심지어 주어가 생략되었고 어순 변화도 없는데도 문법적으로 오류가 없는 문장이다.
...이러니 당연히 한국어는 컴퓨터가 숨겨진 맥락이나 의미를 파악하는데 더 까다로울 수밖에 없는 것이다 ㅠㅠ
| 한국어 자연어 처리의 기본 개념
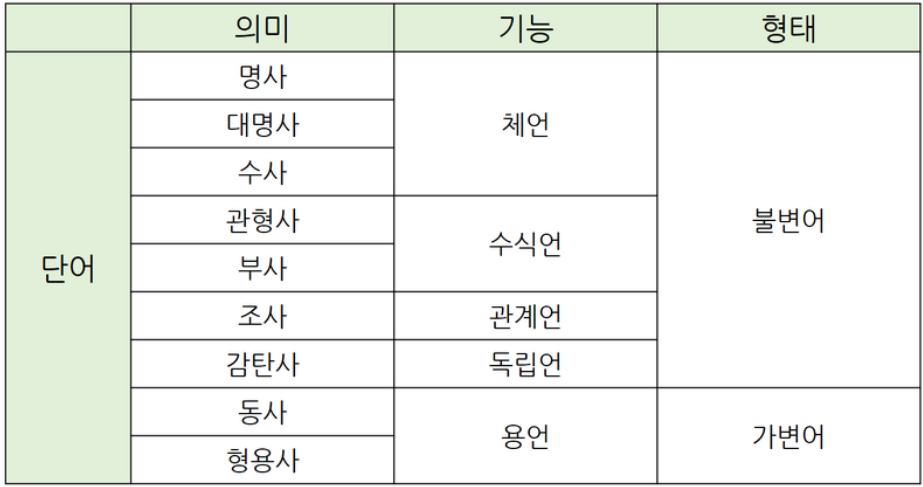
아무튼, 이 까다로운 한글 자연어 처리를 정복해보자!🧐
한국어 자연어 처리의 기본은 단어 추출에서 시작된다.
추출 된 단어를 통해 문장의 의미와 특징을 파악 할 수 있다.
그럼, 단어는 어떻게 추출 할까?
영어 경우엔 띄어쓰기를 기준으로 나누면 원하는 단어를 쉽게 추출 할 수 있다.
하지만 위에서도 말했듯,
한국어에선 단어의 기준이 명확하지 않다. 또 한 단어 안에 의미적 기능을 하는 부분과 문법적 기능을 하는 부분이 모두 들어있기에 띄어 쓰기를 기준으로 구분해 분석하는 것은 한계가 있을 것이다.
예를 들면 '먹다', '먹었다', '먹는다' 에서 '먹'이 의미를 뜻하고 나머지는 문법적인 기능을 하는 문자가 조합되어 있다.
한국어 자연어 처리에서는 이 의미적 기능을 하는 부분을 정확히 추출해 사용하는 것이 문장 분석에서 중요하다고 한다.
또 데이터의 양이나 원하는 자연어 처리의 목적에 따라 문법적인 기능을 하는 부분을 포함시키기도, 삭제하기도 한다.
결론 : 한국어 자연어 처리에서는 단어의 의미적 기능과 문법적인 기능을 구분하는 것이 중요하다.
👻 단어 임베딩이란?
정의 : 자연어 처리 분야에서 임베딩이란, 자연어를 기계가 이해할 수 있는 숫자의 나열인
벡터로 바꾸는 것입니다.
좀 더 풀어서 설명하자면...
말뭉치 내 각 단어에 일대일로 대응하는 실수 벡터의 집합, 혹은 이 벡터를 구하는 행위를 말한다. 주로 단어를 피처(feature)로 사용하는 자연어 처리 분야에서는 단어를 컴퓨터 친화적인 형태로 바꾸어 주는 임베딩 작업이 필수적이다.
단어나 문장 각각을 벡터로 변환해 벡터 공간(Vector space)으로 끼워넣는다는 의미에서 임베딩이라고 합니다.
👀 예시
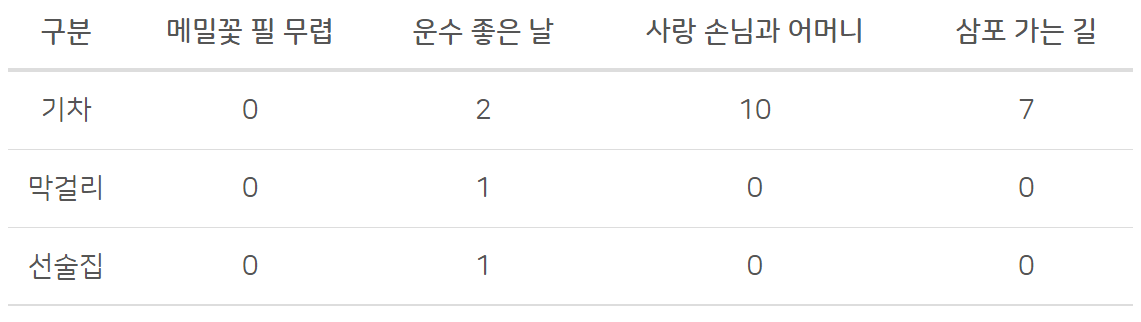
가장 간단한 형태의 임베딩은 위 처럼 단어의 출현 빈도를 기준으로 벡터로 변환하는 것이다.
각 소설에서 해당 단어가 몇 번 출현했는지 카운트 한 것이다.
이렇게, 자연어를 숫자 형태인 벡터로 바꿨으니, 이를 기반으로 "수학적 계산"이 가능해진다!
🙄문장의 유사도는 어떻게 계산할까
문장 유사도 계산법
두개의 문장이 있을 때, 이 두 문장이 얼마나 비슷한지 어떻게 판단할까?
보통 문장 간 유사도는 공통된 단어 혹은 의미를 기반으로 계산한다.
계산 방법에는 다음 3가지가 있다.
1) 자카드 지수
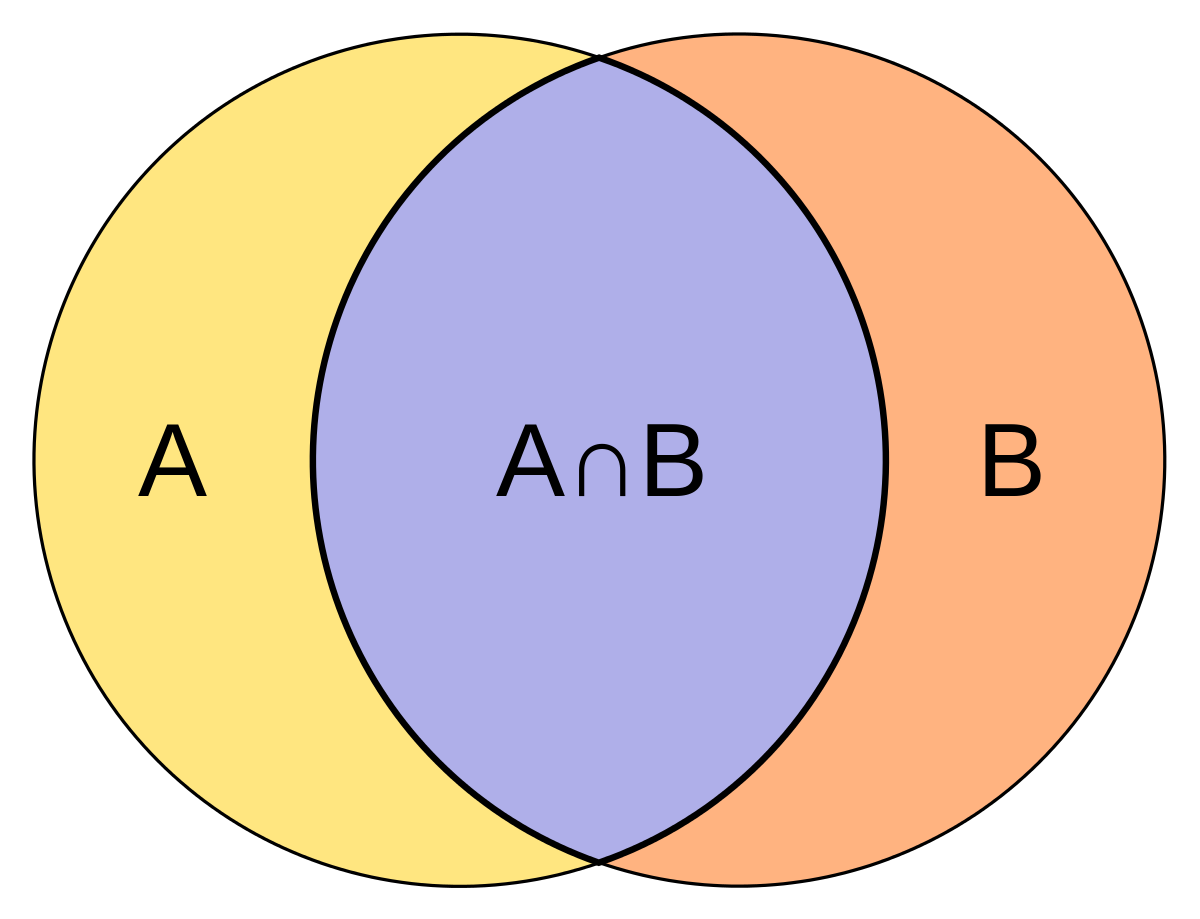
자카드(Jaccard) 지수는 문장 간에 공통된 단어의 비율로 문장 간 유사도를 정의하고 있다.
(유사도는 0~1 사이로 표현 된다.)
단순히 공통 단어 기준으로만 문장 유사도를 비교하기 때문에 의미적인 내용을 부여할 수 없어 한계가 크다.
하지만! 쉽고 간단하고 빠르게 계산 할 수 있다는 점이 장점이다.
2) 유클리디언 거리


피타고라스 원리를 이용해 점과 점 사이의 거리를 계산하는 매우 간단한 방식.
만약 차원이 3차원 이상이라면 같은 칼럼에 해당하는 벡터 요소 모두 위 처럼 여러번 계산하면 끝!
3) 코사인 유사도
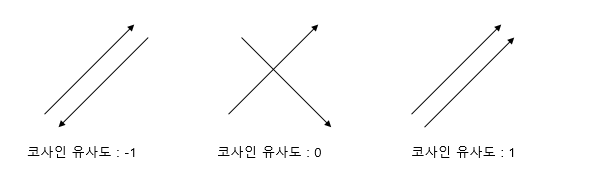
코사인 유사도는 문장 벡터 간의 각도를 기반으로 계산한다.
유클리디언 vs 코사인

거리가 아닌, 각도 기반이라는 것이 가장 큰 특징이다.
유클리디언 방식과 비교하면 바로 알 수 있다.
문장들을 벡터로 표현한 후, 이 벡터 사이의 각도가 작을 수록 비슷한 문장이라는 가정 하에 유사도를 계산하게 된다.
(참고 : 벡터의 크기 = 벡터의 길이 = 벡터의 norm = ||x|| )코사인 유사도는 벡터 간 내적을 사용해서 계산하게 된다.
ex) word2vec의 예시
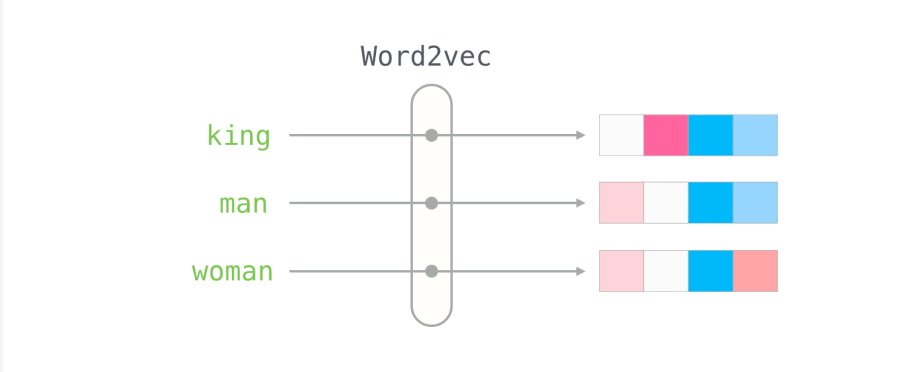
특히 유명한 임베딩 기법인 WORD2VEC에서 임베딩 벡터간 유사도를 계산하는데 그 기준이 바로 코사인 유사도다.
Mecab을 통해 형태소 분석을 한 뒤 이를 100차원으로 학습한다.
'희망'이라는 단어의 Word2Vec의 임베딩결과는 아래와 같다.
[-0.00209, -0.03918, 0.02419, ... 0.01715, -0.04975, -0.09300]위 수식은 100차원으로 임베딩하였으므로 모두 100개의 숫자(벡터)로 표현되었다.
단어를 벡터로 임베딩하면 단어 벡터들 사이의 유사도(Similarity)를 계산하는 일이 가능해진다.
결론
자연어처리는 대부분의 경우 코사인 유사도를 많이 사용하는데, 그 이유는 코사인 유사도는 고차원의 공간에서 벡터 간의 유사성을 잘 보존한다는 장점이 있기 때문이다.
단어, 문장, 문서를 임베딩하게 되면 벡터가 굉장히 길어진다. 즉 고차원의 공간에서 벡터가 존재하게 된다. 고차원에서는 앞선 유클리드 거리 보다는 각 벡터간의 각도를 사용하는 코사인 유사도가 더욱 잘 보존하므로, 기본적인 유사도는 코사인 유사도를 사용하는 것이다.
| 한국어 문장의 유사도 계산해보기
위에서 살펴본 기본 개념을 적용하여
아주 간단하고 단순하게 문장 사이의 유사도를 계산해보는 코드를 작성해보았다.
여러 개의 후보 문장 중, 타겟 문장과 가장 비슷한 문장이 무엇인지 알아내는 코드이다!
1. 전처리 : 토큰화 & 임베딩 과정 (후보 문장)

- vectorizer : 토큰화&벡터화 시키는 함수
- contents : 후보 문장들이다. 우리 프로젝트는 부동산 관련 서비스이므로, 주택임대차계약서의 특약으로 많이 쓰이는 문장 4가지를 넣어주었다.
단순하게 띄어쓰기 기준으로 토큰화 한 결과이다.
# 결과
['1일까지',
'1일에',
'2개월',
'계산해서',
'계약과',
'계약금은',
'계약을',
'달은',
'동시에',
'매월',
'별도로',
'부가가치세는',
'연체',
'월세',
'월세는',
'월세도',
'이상',
'임대인',
'임대인은',
'임대차',
'입금하고',
'입금하기로',
'입금한다',
'있다',
'잔금일로부터',
'통장으로',
'한다',
'해지할']사용한 함수를 설명해보자면,
sklearn의 "CountVectorizer"를 사용했다.
문장을 벡터화 하는 가장 단순한 방법으로, 단위 별로 등장 횟수를 카운팅해 수치 벡터화 해주는 함수이다.
텍스트 카운팅은 먼저 단어 사전 벡터를 만들고, 카운팅 할 문장을 확인하며 그 단어 사전의 횟수를 카운팅한다.
예를들어
[우리집, 고양이, 너무, 밥, 많이 , 먹어]
이러한 단어 사전 벡터가 존재한다면,
'우리집, 너무, 너무, 더러워'
라는 문장이 있을 때 이를
[1,0,2,0,0,0]
이라는 벡터로 표현 가능하다.
🚨 주의
( * 반복되는 단어는 카운팅에서 높은 횟수를 가지겠지만, 실질적으론 의미가 없는 데이터일 수 있다는 문제가 있다. 이 경우 높은 횟수로 등장한 단어의 가중치를 낮춤으로써 결과에의 영향력을 줄여 해결 할 수 있다. )

위 단어를 기준으로 벡터화 한 결과를 출력해봤다.
한 눈에 보기 좋게 배열로 만들고 행/열을 전치시켰다.
# 결과
array([[0, 0, 1, 0],
[0, 0, 1, 0],
[1, 0, 0, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 1, 0, 0],
[1, 0, 0, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 1, 1, 0],
[0, 0, 0, 1],
[0, 0, 0, 1],
[1, 0, 0, 0],
[1, 0, 0, 1],
[0, 0, 1, 0],
[0, 1, 0, 0],
[1, 0, 0, 0],
[0, 1, 0, 0],
[1, 0, 0, 0],
[1, 0, 0, 0],
[0, 1, 1, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[1, 0, 0, 0],
[0, 0, 1, 0],
[0, 2, 0, 0],
[0, 0, 1, 1],
[1, 0, 0, 0]])나의 경우 후보 문장이 4개였으므로 4개의 열로 표현되고 있다.
각 문장에서 해당 단어가 존재하면 1값을, 존재하지 않으면 0값을 가진다.
예를 들어
'1일까지'는 위 추출 결과에서 첫번째에 나타나고 있다.
그리고 '1일까지'라는 단어는 3번 째 문장에서만 등장하는데,
그러므로 1행 3열의 값이 1인 것을 알 수 있다!
2. 전처리 : 토큰화 & 임베딩 과정 (타켓 문장)

일단 난 타겟 문장으로 💙
"월세를 두 번 이상 연체 하면 방을 빼셔야 합니다."를 넣었고,
가장 가까운 문장 정답으로 후보 문장의 1번,
👍"2개월 이상 월세 연체 시 임대인은 임대차 계약을 해지할 수 있다.가 나오게 하는게 목표다!
🚨 정확도 판단을 위해 문장들에 중복적으로 들어간 "월세"라는 단어를 의도적으로 포함시켰다.
그리고 타겟 문장을 위에서 만든 vertorizer을 가지고 새 문장을 벡터화하면 다음과 같다.
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0]]) `3. 벡터 거리 구하기

그리고 문장 벡터들 사이의 거리를 구하면 끝이다!
- scipy 라이브러리 : 과학기술계산을 위한 Python 라이브러리, NumPy, Matplotlib, pandas, SymPy와 연계되어 있다.
- norm : 선형대수에서 벡터의 크기, 길이를 의미함
4. 결과
== Post 0 with dist=2.65 : 2개월 이상 월세 연체 시 임대인은 임대차 계약을 해지할 수 있다.
== Post 1 with dist=3.74 : 계약금은 계약과 동시에 임대인 통장으로 입금하고, 월세도 본 통장으로 매월 입금한다.
== Post 2 with dist=3.46 : 월세는 매월 1일에 입금하고, 첫 달은 잔금일로부터 1일까지 계산해서 입금하기로 한다.
== Post 3 with dist=2.45 : 월세 외 부가가치세는 별도로 한다.
===> Best 3 with dist=2.45 : 월세 외 부가가치세는 별도로 한다.😨 역시 내 의도대로 컴퓨터를 속이는데 성공했다!(?)
다른 문장들에도 공통적으로 포함되는 '월세'라는 단어 때문에 오답이었단 3번 문장과의 거리가 가깝게 나온 것 같다.
😨 왜 정답을 못 맞췄을까 ?
띄어쓰기를 기준으로 토큰화 하는 것엔 문장을 분석하는데 한계가 있다.
Ex) 같은 의미를 가진 단어 '감사합니다'와 '감사해요'를 다른 벡터로 계산하기 때문이다. '합니다'와 '해요'는 문법적 요소일 뿐이고, 중요한 것은 의미를 담은 '감사'라는 명사다.
그러므로 문장에서 이 '형태소'를 분석하는 것이 유사도 계산에 있어 중요하다.
음 그렇다면 형태소 분석은 어떻게 할까..?
| 형태소 분석을 추가하자
KoNLPy 형태소 분석

한글 형태소 분석에는 KoNLPy라는 형태소 분석을 해주는 파이썬 라이브러리를 가장 많이 사용하고있다.
여러 한국어 형태소 사전을 기반으로 한국어 단어를 추출해주고 있으며, [Mecab, 한나눔, 꼬꼬마, Komoran, Open Korean Text(트위터)] 등의 5종류의 형태소 사전을 제공하고 있다!
그리고 이 형태소 분석기에 따라 속도와 정확도에 차이가 있다.
형태소 분석기의 종류
어떤 형태소 분석기를 사용할지 결정하고자 Konlpy의 공식 문서를 살펴보았다.
형태소 분석기 별 속도
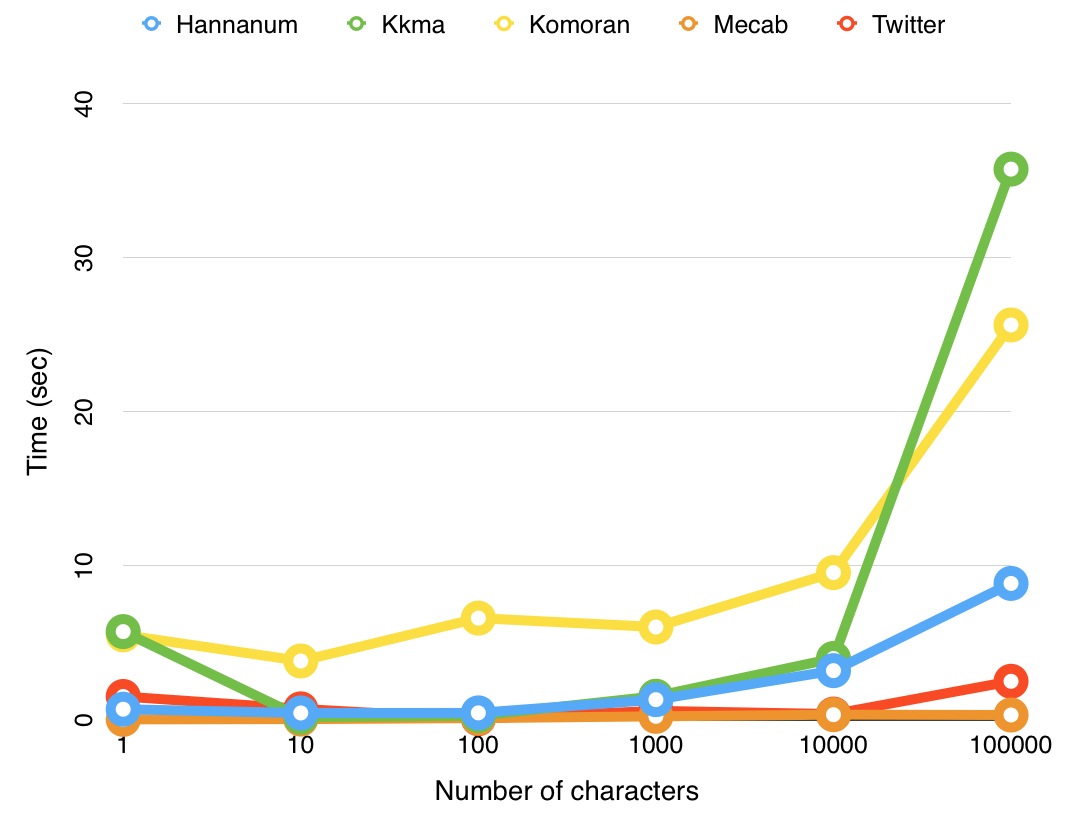
분석 속도는 위와 같았다.
- 꼬꼬마와 코모란은 character 양이 커질수록 처리에 소요되는 시간이 기하급수적으로 늘어남을 알 수 있었다.
- Mecab과 Twitter가 일관적으로 가장 빠른 속도를 보였다.
형태소 분석기 별 성능
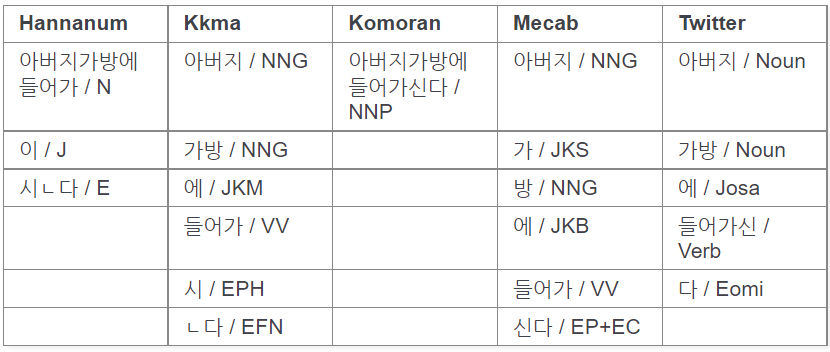
공식 문서에서는 띄어쓰기 알고리즘의 성능을 보여주고 있다.
만약 '아버지가방에들어가신다'라는 문장이 있다면
'아버지 + 가방에 + 들어가신다' 보단
'아버지가 + 방에 + 들어가진다'로 분석하는 것이 맞다.
🚨 이 부분에선 트위터를 제외한 분석기들은 모두 오답을 냈다.
하지만 띄어쓰기 오류의 경우 후보정 단계를 거쳐 해결하면 되니.... 어떻게든 극복 가능 할 것 같다(?)
(ex. 일단 우리는 한글 맞춤법 라이브러리 hanspell의 사용을 고려하고 있다.)
어떤 형태소 분석기를 사용할까?
형태소 분석기의 품질이나 속도야 이미 정말 좋지만,
나의 프로젝트에 잘 맞는 형태소 분석기가 무엇일지 고민해서 잘 선택하는게 중요했다.
고려한 점
- 나의 프로젝트는 서비스 되는 기능이므로
속도가 중요했다. 문서 하나 분석하는데 몇 분 넘게 걸린다면 유저 입장에선 매우 답답할 것이다.- 우리 서비스는 부동산 관련 문서를 분석하므로, 부동산 용어, 또는 지명, 건물명, 사람 이름 같은 고유 명사를 잘 분석하는
정확도도 중요하다.
🚨 위 5개의 분석기 중 속도가 가장 빨랐던 Mecab은 윈도우 지원이 되지 않아 아쉽게도 고려 대상에서 제외됐다. (우리 팀원들이 모두 윈도우를 사용한다는 점에서 개발 편의 상 어쩔 수 없었다 ㅠ)
그리하여, 나머지 중 레퍼런스가 많고 검색 결과가 많았던 형태소 분석기 3가지인 코모란(Komoran), 꼬꼬마(Kkma), Okt(Open korean text / Twitter)의 형태소 추출 성능과 속도를 비교해보고자 했다.
- 꼬꼬마 : 꼬꼬마는 서울대학교 IDS(intelligent Data Systems) 연구실에서 개발하였다고 하고, 성능이 아주 좋기로 유명하다.
- 코모란 : Shineware에서 개발하였고, Pure Java. 100% Java로만 구현되었다는 것이 특징. 자바가 있는 환경이면 어디서든 사용 가능하다고 한다.
- okt : 트위터에서 만든 오픈소스 한국어 처리기를 이어 진행되고 있는 프로젝트. 특이한 점이, 트위터에선 okt를 '형태소 분석기'가 아닌 '형태소 처리기'라고 소개하고 있다. 정교하게 형태소 분석을 하지 않아 빠른 속도를 내 프로젝트에 적합하게 만든 목적이 있기 때문이다.
(그리고 편의를 위해 okt는 이제부터 트위터 라고 설명하겠다.)
| konlpy 형태소 분석기 비교하기
pos-tagging은 문장 속 모든 품사를 분석하는 '품사 태깅'을 뜻한다.
보통 이 품사 태깅의 과정에서 시간을 가장 오래 사용한다고 볼 수 있다.
그래서 이 pos 함수 (형태소 - 품사 매핑)의 속도를 측정하여 형태소 분석기의 속도를 판단하고자 한다.
이를 위해 리뷰 데이터 2만개를 읽어왔고, 3개의 형태소 분석기의 pos 메소드를 실행했다.
1. 코랩 환경 초기 세팅

konlpy 라이브러리는 python 버전, java 버전, jpype 버전 등 맞춰야하는 것이 많은 만큼 로컬에서 실행시키는 것이 까다롭다.
그래서 난 코랩에서 개발을 진행했다. (코랩 짱!)
위와 같이 설치해주면된다.
위 코드에서 환경변수 path는 자기 로컬 상태에 맞게 바꿔서 쓰면 된다.
2. 리뷰 데이터 불러오기 & 속도 측정 방법

2만개 정도의 리뷰 데이터를 모아둔 깃허브에서 한글 데이터를 불러와 사용했다. 리뷰 데이터 출처
형태소 분석 속도는 time의 time() 함수를 사용했다.
start_time에 코드 시작의 시간을 저장하고,
여기서 끝난 시점의 시간을 빼면, 총 소요 시간을 구할 수 있는 매우 간단한 코드이다.
리뷰 데이터 읽어오기
시작!
리뷰 데이터 사이즈는 20000
읽어오는데 걸린 시간은 0.7001774311065674 초
디자인을 배우는 학생으로, 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산업이 부러웠는데. 사실 우리나라에서도 그 어려운시절에 끝까지 열정을 지킨 노라노 같은 전통이있어 저와 같은 사람들이 꿈을 꾸고 이뤄나갈 수 있다는 것에 감사합니다.위 처럼 리뷰 데이터를 불러오는데 걸린 시간은 0.7초 정도다.
이제 형태소 분석기를 사용해 데이터를 분석해보자!
1. 꼬꼬마 속도

결과
[('디자인', 'NNG'), ('을', 'JKO'),...., ('ㅂ니다', 'EFN'), ('.', 'SF')]
꼬꼬마 속도 445.2370822429657꼬꼬마는 445초가 소요됐다.
공식 문서에서 나온대로 굉장히 오래 걸린 편이다.
2. 코모란 속도

결과
[('디자인', 'NNG'), ('을', 'JKO'),...('ㅂ니다', 'EF'), ('.', 'SF')]
코모란 속도 30.89557957649231
30초가 소요됐다. 공식 문서와 다르게 꽤나 빠른 속도를 보여줬다😮.
3. Okt (Twitter) 속도

결과
[('디자인', 'Noun'), ('을', 'Josa'),... ('감사합니다', 'Verb'), ('.', 'Punctuation')]
okt 속도 93.3365349769592393초 정도 걸렸다. 나쁘지 않지만 코모란 보다는 느리게 나왔다.
속도에 대한 분석

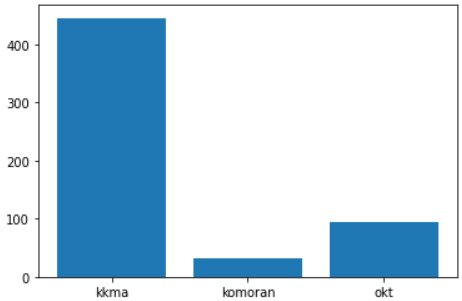
3가지 형태소 분석기의 속도를 보기 좋게 막대 그래프로 표현해보았다.
komoran > okt > kkma 순으로 속도가 빠름을 알 수 있었다.
하지만 빠른 속도만을 가지고 판단하기엔 부족함이 있을 것 같아, 형태소 분석 결과도 살펴보았다.
| 형태소 분석 품질 결과
형태소 분석 결과에서 중요한 차이를 발견할 수 있었다!
1. 꼬꼬마 형태소 분석
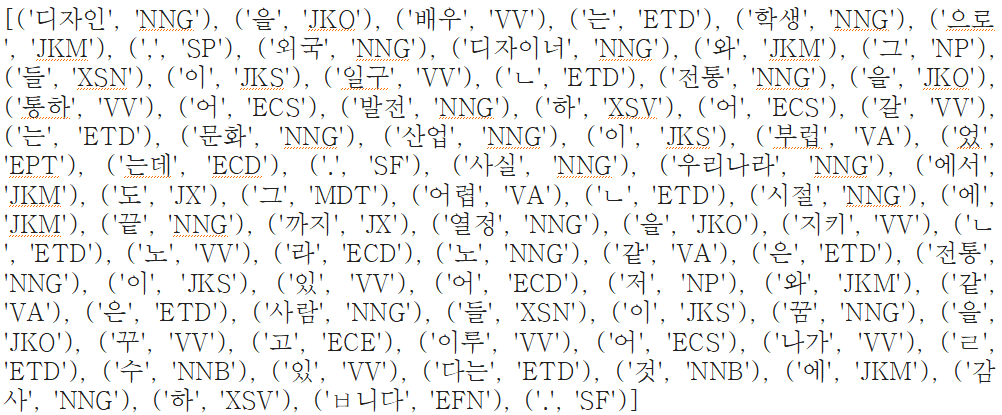
꼬꼬마는 기본적으로 품사를 정~말 디테일하게 분석한다.
이 정도 퀄리티라면 정말 디테일한 성능을 내야하는 서비스에 적용하면 효과적일 것 같다.
예를 들면 챗봇 같이 품사 조합을 구별하고 앞뒤 맥락 파악까지 해야하는 서비스 등 말이다.
2. 코모란 형태소 분석

코모란도 꼬꼬마와 분석 결과가 유사했다.
아무래도 꼬꼬마랑 비슷한 품사체계를 사용하고 있는게 아닐까 싶다.
3. Okt 트위터 형태소 분석

트위터는 분석 결과가 약간 달랐다.
꼬꼬모, 코모란과 달리 형태소를 잘게 자르지 않았다.
공백 기준으로 한 토큰이 같은 명사 사전에 존재한다면 전체를 명사 하나로 뽑는 것 같다.
💯 빨간 색으로 표시해 둔 부분이 형태소 분석기 별로 다르게 분석한 부분이다.
-
꼬꼬마와 코모란은 '일군'이라는 단어를 '일구 + ㄴ'으로 추출했다.
임베딩 수행에서 'ㄴ'은 반영되지 않을 확률이 높다. -
또 꼬꼬마와 코모란의 경우 '노라노'와 같은 고유명사를
꼬꼬마의 경우'노'+'라'+'노'로,
코모란의 경우'노라' + '노'로 분석해버렸지만,
트위터만 '노라노' 그대로 보존하는데 성공했다.
공식 문서에 따르면 품사 태깅의 퀄리티는
kkma > komoran > okt
라고 하는데, 실험 결과 얼추 비슷하게 나온 것 같다.
🚨 하지만 품사 태깅의 퀄리티가 좋다고 무조건 내 프로젝트에 적절하다고 판단 할 수는 없었다.
너무 정교한 형태소 분석은 오히려 내 프로젝트에 독이 될 수 있다...
너무 잘게자르면 벡터 계산량이 증가해 처리에 소요되는 시간이 기하급수적으로 늘어나고 임베딩 퀄리티가 떨어질 수 있다.
그래서 속도가 중요한 서비스 개발 프로젝트에선 대부분 명사, 부사, 동사 정도만 사용하게 된다.
어느 정도로 품사를 분석하는 것이 내 서비스에 맞는지 많이 고민해보았는데,,,

Okt(트위터)는 적당히 좋은 속도를 가졌으며 고유명사 분석을 잘했고, 띄어쓰기 오류에서도 형태소 분석을 잘 했기 때문에 우리 프로젝트에는 Okt(트위터)가 가장 적절하다고 판단했다.!
2. 형태소 추출 후 벡터 거리 계산
아무튼, 이번엔 Okt 트위터를 사용해 좀 더 한글의 특성을 살려서 토큰화 해보자.
1. 형태소 기준으로 토큰화

morphs() 함수 : 품사명을 제외하고 형태소 결과만 리턴
# 결과
[['2','개월','이상','월세','연체',
'시','임대','인','은','임대차','계약','을','해지', '할', '수', '있다','.'],
['계약금', '은', '계약', '과', '동시','에', '임대', '인', '통장', '으로', '입금', '하고', ',', '월세', '도', '본', '통장', '으로', '매월', '입금', '한다', '.'],
['월세', '는', '매월', '1일', '에', '입금', '하고', ',', '첫', '달', '은', '잔금', '일로', '부터', '1일', '까지', '계산', '해서', '입금', '하기로', '한다', '.'],
['월세', '외', '부가가치세', '는', '별도', '로', '한다', '.']]2. 토큰을 한 문장으로 붙이기

결과
[' 2 개월 이상 월세 연체 시 임대 인 은 임대차 계약 을 해지 할 수 있다 .',
' 계약금 은 계약 과 동시 에 임대 인 통장 으로 입금 하고 , 월세 도 본 통장 으로 매월 입금 한다 .',
' 월세 는 매월 1일 에 입금 하고 , 첫 달 은 잔금 일로 부터 1일 까지 계산 해서 입금 하기로 한다 .',
' 월세 외 부가가치세 는 별도 로 한다 .']3. 벡터화 (후보 문장)

# 결과
array([[0, 0, 2, 0],
[1, 0, 0, 0],
[0, 0, 1, 0],
[1, 1, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 1, 1, 0],
[0, 0, 0, 1],
[0, 0, 0, 1],
[0, 0, 1, 0],
[1, 0, 0, 0],
[1, 1, 1, 1],
[0, 2, 0, 0],
[1, 0, 0, 0],
[0, 0, 1, 0],
[1, 1, 0, 0],
[1, 0, 0, 0],
[0, 2, 2, 0],
[1, 0, 0, 0],
[0, 0, 1, 0],
[0, 2, 0, 0],
[0, 1, 1, 0],
[0, 0, 1, 0],
[0, 1, 1, 1],
[0, 0, 1, 0],
[1, 0, 0, 0]])
4. 형태소 기준으로 토큰화 (타겟 문장)

5. 벡터화 (타겟 문장)

# 결과
[' 월세 를 두 번 이상 연체 하면 방 을 빼셔야 합니다 .']
# 결과
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0]])
6. 문장 사이 거리 계산

결과
== Post 0 with dist=2.45 : 2개월 이상 월세 연체 시 임대인은 임대차 계약을 해지할 수 있다.
== Post 1 with dist=4.58 : 계약금은 계약과 동시에 임대인 통장으로 입금하고, 월세도 본 통장으로 매월 입금한다.
== Post 2 with dist=4.47 : 월세는 매월 1일에 입금하고, 첫 달은 잔금일로부터 1일까지 계산해서 입금하기로 한다.
== Post 3 with dist=2.24 : 월세 외 부가가치세는 별도로 한다.
== Best 3 with dist=2.24 : 월세 외 부가가치세는 별도로 한다.이번에도 역시 정답을 맞추진 못했지만,
오답인 문장과의 거리가 더 멀어졌음을 알 수 있다. 🤩
🧐 어떻게 더 개선할까?
다른 문장에서도 공통적으로 가지고 있는 단어의 가중치를 낮출 필요가 있어보인다.
어떻게 하면 중요하지 않는 단어의 가중치를 낮출 수 있을까?
이를 위해 통계적 계산 방식을 적용하고자 했다.
| TF-IDF를 적용해보자
타겟 문장에서 중요하게 계산해야하는 단어는 '월세'보다는 '연체'다.
다른 문장에 공통적으로 많이 쓰이는 단어는 계산 할 때 가중치를 낮출 필요가 있다.
보통 이럴 때 사용하는 것이 TF-IDF이다.

TF-IDF(Term Frequency - Inverse Document Frequency)는 정보 검색과 텍스트 마이닝에서 이용하는 가중치로, 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치
문서의 핵심어를 추출하거나, 검색 엔진에서 검색 결과의 순위를 결정하거나, 문서들 사이의 비슷한 정도를 구하는 등의 용도로 사용
- tf (term frequency) idf (inverse document frequency)
텍스트 마이닝에서 사용하는 일종의 단어별로 부과하는 가중치- tf(term frequency) : 단어 빈도
특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값으로, 이 값이 높을수록 문서에서 중요하다고 생각할 수 있다.- idf(inverse document frequency) : 역문서 빈도
문서 군의 성격에 따라 중요 단어 여부 결정
단어 자체가 문서군 내에서 자주 사용되는 경우, 이것은 그 단어가 흔하게 등장한다는 것을 의미한다. 이것을 DF(문서 빈도, document frequency)라고 하며, 이 값의 역수를 IDF(역문서빈도)라고 함
(TF-IDF는 TF와 IDF를 곱한 값을 의미)
조금 더 풀어 설명하자면, 해당 단위(문장) 안에서는 많이 등장하지만, 다른 문서들까지 전체에서는 적게 사용될수록, 분별력 있는 특징이란 것입니다.
TF-IDF 예제 함수

이해를 돕고자 간단한 함수를 만들어 보았다.
- t : 분석하고자 하는 타겟 단어
- d : t가 포함된 문서
- D : 문서들의 집합

문서 d 에서 단어 t가 가지는 가중치를 계산하고자 tf와 idf를 계산해내는 원리이다.
# 결과
(1.0, 0.0)
(0.6666666666666666, 0.4054651081081644)
(0.3333333333333333, 0.0)
(0.3333333333333333, 0.4054651081081644)
(0.3333333333333333, 1.0986122886681098)| TF-IDF 적용하여 코드 수정
이제 TF-IDF의 원리를 적용해 코드를 보완해보자!

scikit-learn에서 TfidfVectorizer를 import해 사용했다.
위에서 사용했던 CountVectorizer는 단순히 각 텍스트에서 단어 출현 횟수를 카운팅한 벡터이지만, TfidfVectorizer는 TF-IDF 값을 사용해 벡터화하여 CountVectorizer의 단점을 보완한다.
1. 형태소 분리 & tf-idf 벡터화 (후보 문장)

위와 동일하게 진행하면 된다.
2. 형태소 분리 & tf-idf 벡터화 (타겟 문장)

# 결과
[' 월세 를 두 번 이상 연체 하면 방 을 빼셔 야합니다 .']
3. 벡터 거리 계산
4. 결과
== Post 0 with dist=0.95 : 2개월 이상 월세 연체 시 임대인은 임대차 계약을 ...있다.
== Post 1 with dist=1.38 : 계약금은 계약과 동시에 임대인 통장으로 입금하고, ...
== Post 2 with dist=1.38 : 월세는 매월 1일에 입금하고, 첫 달은 잔금일로부터 ...
== Post 3 with dist=1.33 : 월세 외 부가가치세는 별도로 한다.
Best post is 0, dist = 0.95
--> ['월세를 두 번 이상 연체 하면 방을 빼셔야합니다.']
----> 2개월 이상 월세 연체 시 임대인은 임대차 계약을 해지할 수 있다.드디어 내가 원했던 문장을 찾아내는데 성공했다👍
| TF-IDF 문장 유사도 검사 사이트💜
위 함수를 직접 사용해볼 수 있는 웹사이트를 구현했다.
아래 링크로 연결하면 사이트를 직접 사용 할 수 있다.
TF-IDF 한글 문장 유사도 검사해보기
(현재 aws 비용 문제로 서버를 잠시 내렸습니다...)
완성본

후보 문장을 여러개 작성하고, 타겟 문장을 1개 작성한 뒤, 검사를 진행 할 수 있다.
후보 문장 중, 타겟 문장과 가장 가까운 문장이 무엇인지 알려준다.
문장 벡터 사이 거리도 출력되고 있다.

후보 문장을 적고 한 페이지 넘기면 타겟 문장을 작성 할 수 있다.
원하던 퀄리티에 속도까지 나와줘서 너무 다행이다!
여기까지, TF-IDF를 이용한 한글 문장 유사도 계산은 끝!
+ 번외 | 🔐 사진 속 개인정보 마스킹하기
여기서 부턴 뽀너스 트랙~
우리 서비스 믿어방은 부동산 계약서와 문서 사진을 다루는데, 문서 사진 속에 개인정보가 포함 되어있을 수 있고, 만약 서버가 공격받게 된다면 개인정보 유출 등의 문제가 발생 할 수 있다고 판단했다.
이를 방지하고자 Client-Side (브라우저) 단계에서 사진 속 개인정보 유무를 검사하고, 만약 개인정보가 발견됐다면 이를 마스킹 처리한 후 Server-Side로 보내는 방식으로 사이트를 구현하고자 했다.
사진 속 텍스트를 추출하려면 OCR을 사용해야하는데, 우리 조가 만들고 있는 OCR 모델을 직접 돌리자니, 브라우저와 서버에서 같은 일을 두번이나 하는 꼴이 되고, 이 과정에서 시간이 많이 소요되어 유저 경험에 매우 좋지 않을 것이라 생각했다.
그래서 브라우저에서 js 형태로 사용 가능하며 패키지 사이즈가 가볍고 속도도 빠른 Tesseract.js를 사용하기로 결정했다.
Tesseract.js

Tesseract.js는 머신러닝 기반의 이미지(동영상) 텍스트 검출 라이브러리이다.
여러가지 언어를 추출 할 수 있는데, 한글에 대한 인식도는 80% 전후의 정확도를 보여주고 있다고 한다. 이미지나 영상에 한글만 있는 경우에는 정확도가 올라가지만, 숫자 혹은 영어 조합일 경우에는 폰트깨짐 현상이 발생하는 등의 성능 문제가 있긴 하다.
하지만 무엇보다도 브라우저 단계에서 쉽게 사용 가능하다는 점이 가장 큰 장점이다.🥲
또 tesseract.js는 CDN, Node.js를 지원하고 있다.
이런 친절한 라이브러리가 있다니,,, 프론트 담당인 나는 너무 기뻐서 눈물을 흘림
1) Tesseract.js 사용 코드
나는 CDN을 사용했다.
Tesseract 깃허브 에 들어가면 예시 코드도 볼 수 있다. (엄청 잘 정리되어있다.)
// CDN
<script src="https://unpkg.com/tesseract.js@2.1.4/dist/tesseract.min.js">
// 코드
<script type="module">
const { createWorker } = Tesseract;
var status = document.querySelector(".loading");
var progress = document.querySelector(".progress");
const worker = createWorker({
logger: (m) => {
console.log(m);
if (m.status === "recognizing text") {
status.innerHTML = "분석 중...";
progress.innerHTML = Math.floor(m.progress * 100) + "%";
if (m.progress === 1) {
status.innerHTML = "분석 완료✨";
progress.innerHTML = "";
}
} else {
status.innerHTML = "이미지 전송 중, 기다려주세요!!";
}
},
});
// 테서렉트에 file 전송하기
const recognize = async (file) => {
const {
data: { text },
} = await Tesseract.recognize(file, "kor", {
corePath:
"https://unpkg.com/tesseract.js-core@v2.0.0/tesseract-core.wasm.js",
logger: (m) => console.log(m),
});
console.log(text);
result = text;
};2) 개인 정보 추출 원리
OCR을 통해 추출 된 텍스트에 개인정보를 검출하기 위해 정규 표현식와 match() 함수를 사용했다.
/*개인정보 추출*/
const findInfomation = (data) => {
var phone = /\d{3}-\d{4}-\d{4}/;
var id =
/\d{2}([0]\d|[1][0-2])([0][1-9]|[1-2]\d|[3][0-1])[-]*[1-4]\d{6}/;
var result_phone = [];
var result_id = [];
data.words.map((word) => {
if (word.text.match(phone)) {
result_phone.push(word);
}
if (word.text.match(id)) {
result_id.push(word);
}
});
if (result_phone) {
console.log("폰 번호 : ", result_phone);
result_phone.map((res) => {
console.log("좌표는 : ", res.line.bbox);
var { x0, y0, x1, y1 } = res.line.bbox;
draw(x0, y0, x1, y1); // 마스킹 실행
});
}
if (result_id) {
console.log("주민등록번호 :", result_id);
result_id.map((res) => {
console.log("좌표는 : ", res.line.bbox);
var { x0, y0, x1, y1 } = res.line.bbox;
draw(x0, y0, x1, y1); // 마스킹 실행
});
}
};
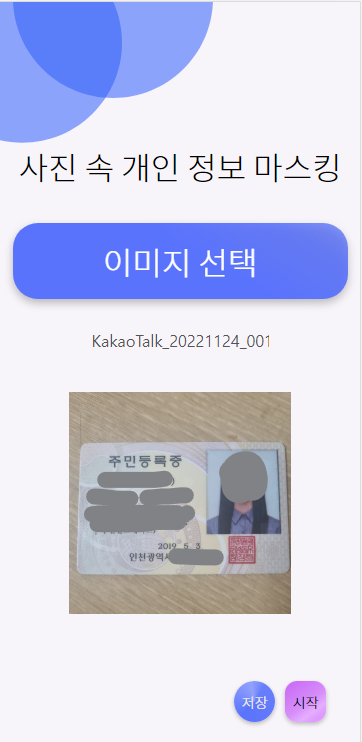
💜 사진 속 개인정보 마스킹 - 베타 버전
이미지를 업로드하면 개인정보가 노출된 부분을 마스킹 처리합니다.
사이트 링크 < 여기를 누르면 직접 체험해 볼 수 있다👍
사용해보기
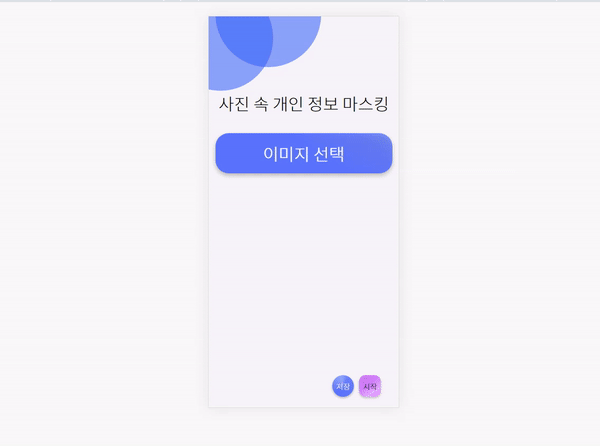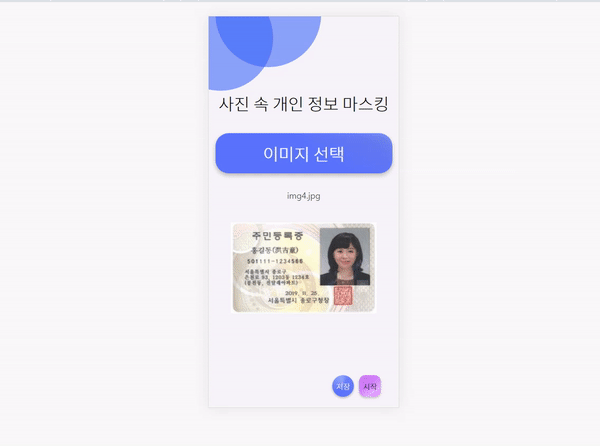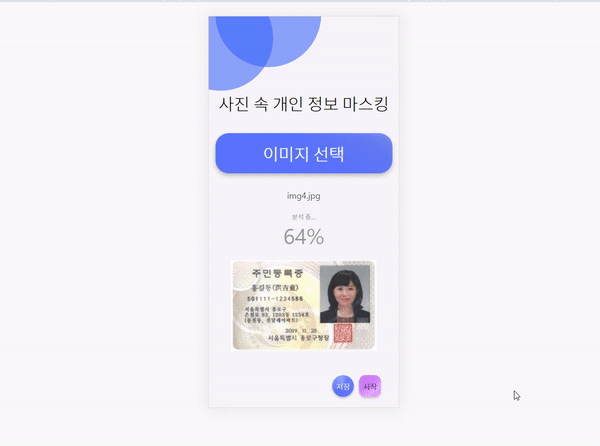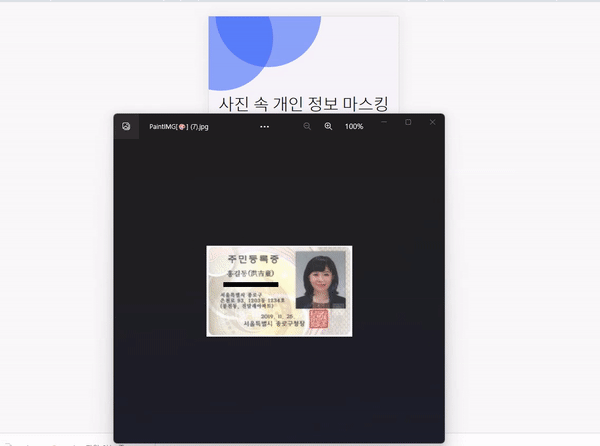
사이트는 위와 같이 생겼다.
(모바일, pc 모두 접속 가능)
1. 이미지 업로드
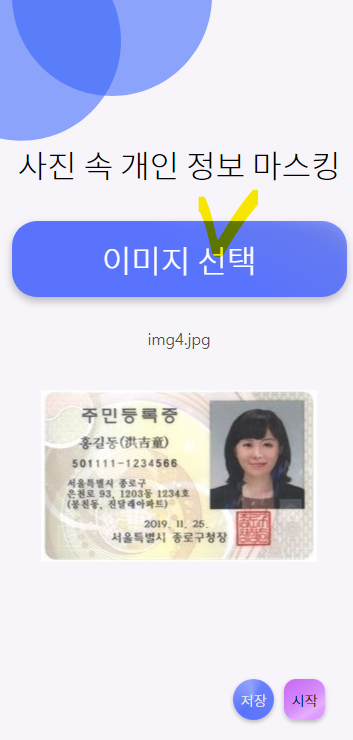
[이미지 선택] 버튼을 누르면 이미지를 업로드 할 수 있다.
개인정보가 포함된 테스트 이미지를 넣어보았다.
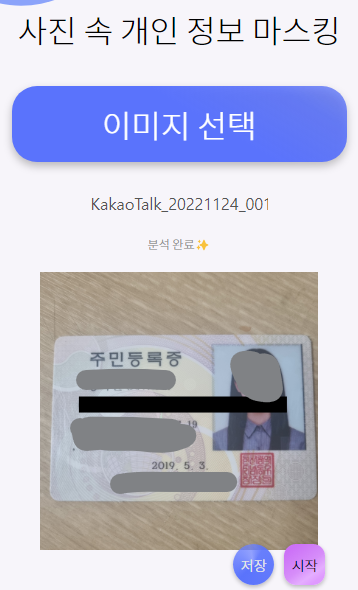
2. 분석
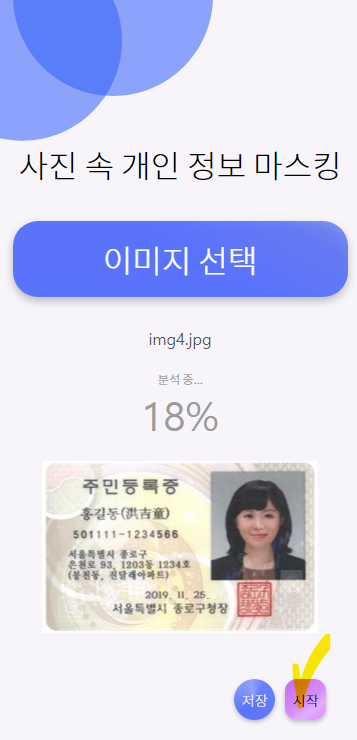
[시작] 버튼을 누르면 Tesseract를 이용해 텍스트를 추출하고, 추출된 텍스트 중 개인정보가 포함되어있다면 해당 부분을 마스킹 처리 해준다.
현재 베타 버전에선 주민등록번호와 전화번호를 마스킹 가능하다.
3. 결과
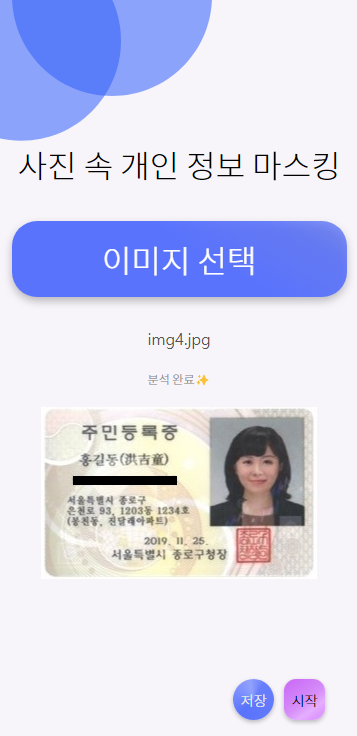
짠~ 아주 잘 가려준다 ㅠㅠ🥲🥲🥲👍
아하하 아 누가 만들었냐 진짜 대박이다
4. 저장
[저장] 버튼을 누르면 마스킹 처리된 사진을 저장 하는 것도 가능하다.
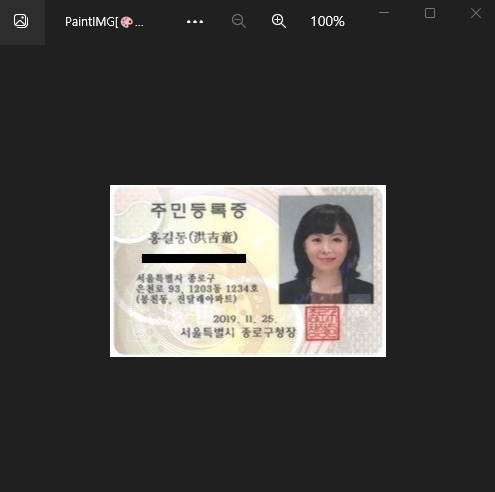
마스킹 된 버전으로 자주 잘 저장 되었다👍
5. 테스트
모든 사진이 잘 되는지 보기 위해, 내 민증 사진을 넣어보았다.
살짝 삐져나갔지만(?) 아무튼 잘 가려준다 !!
아직 베타 버전이라 성능이 완벽하지 않고... 오류도 많다^^;
그래도 완성한 것에 큰 의미가 있다고 생ㄱ각.....
앞으로 해결 할 것
- 이미지 사이즈가 클 수록 OCR 처리 속도가 증가함
- Tesseract의 분석 결과에 지나치게 의존적, OCR 결과에 대한 오류 보정 필요
- 이미지 여러 번 업로드 시 오류 발생
우리 프로젝트에 적용 가능할 정도로 수정 & 보완해나갈 계획이다!
오랜만에 혼자 개발을 했더니...

오랜만에 혼자 개발 하니까 어색하고~ 어려움이 많았다.
특히 내가 프론트/백 둘 다 개발한 것이 가장... 믿기지 않는다...얼떨떨
3일 동안 Flask, Django, Node.js 서버 만들고 DB 연동하고 프로토 디자인하고 React 개발하고 미쳣습니까 휴먼 ㅠㅠ >?? (살려줘
앞으로 서버 만들어주는 백엔드 팀원들에게 잘해줘야겠다
하하
-끝-
참고 자료 출처
한국어 자연어 처리 및 문장 유사도
형태소 분석기 별 noun 분석 속도 비교
Konlpy의 공식 문서
tf-idf 출처
자연어 처리 - 전처리
한글 자연어 처리 - 데이터셋
텍스트 유사도
tf-idf 파이썬
텍스트 유사도 분석
텍스트 유사도 분석2
텍스트 유사도 분석3
형태소 분석기 api 개발
konlpy 사용 시 jpype 에러
자바스크립트 canvas
사진, 영상에서 글씨 추출하기

6개의 댓글

와 정리도 잘 하시고 글도 잘 읽히고 잘봤습니다 하고 댓글 달아야지 하면서 마지막까지 읽었는데 혼자 하셨다구요...? 대단하시네용!!! 진짜 잘 읽고 갑니다!


Also you can check the best escort and call girl service in lucknow
아주 잘 읽었어요~