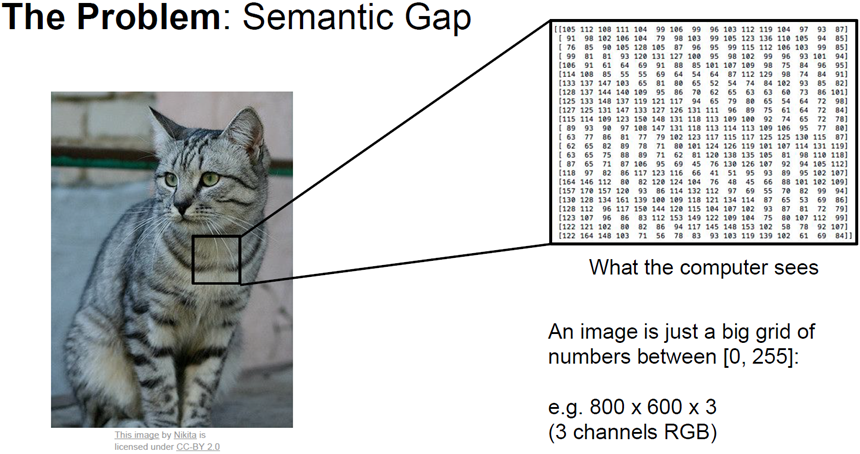
첫번째 문제로는 semantic Gap(의미론적인 차이)이다.
사실 고양이라는 레이블은 우리가 붙힌 의미상의 레이블이다.
컴퓨터에겐 아기 고양이로 보이는 것이 아닌, 아주 큰 격자 모양의 숫자집합으로 밖에 보이지 않을 것이다.
이미지 알고리즘에서 고려해야 될 점이 몇가지 있다.
- viewport variantion : 아주 미묘하게 구도가 바뀌어도, 픽셀 값들은 모조리 변하게 될 것이다.
- Illumination : 조명에따라 픽셀값들이 달라질 것이다.
- Deformation : 다양한 변형에 따라 픽셀값들이 달라질 것이다.
- Occlusion : 대상의 일부가 가려지는 이미지를 어떻게 인식할 것인가.
- Background Clutter : 대상이 배경화면과 유사하면 어떻게 인식할 것인가.
- Interclass variation : 다양한 모습들을 어떻게 인식할 것인가.
ex. 성인 고양이와 아기 고양이
알고리즘은 이런 다양성을 다룰 수 있어야 하지만, 어려운 문제이다.
우리의 뇌는 이런 것들을 잘하기 때문에 컴퓨터가 얼마나 어려워할지 망각하게 된다.
def classify_image(image):
# some code here
return class_labelimage classifier 위와 같은 간단한 방법이 함수가 있다.
# some code here에 구현될 코드는
find edges(가장자리들을 찾기) -> (Find corners)세점이 모이는 곳을 찾는 것이다.
하지만 이 방법은 잘 동작하지 않는다.
- 이런 알고리즘은 강인하지 못하다(robust하지못함).
- 다른 객체들을 인식해야 하면, 그 객체들에 대해서도 벼도로 만들어야 한다.
즉, 처음부터 다시 시작해야 한다(you need start all over again.)
이런 방법들은 확장성이 전혀 없는 방법이다.
위의 함수를 토대로 고려해야될점이 생겼다.
Data-Driven Approach(데이터 중심 접근)이라는 것을 고려해야된다.
-
Collect a dataset of images and labels.
인터넷에서 수집하는 것이 대표적인 방법이다.
eg. google image search - Use Machine Learning to train a classifier.
모은 데이터들을 학습시킨다. - Evaluate the classifier on new images.
이 방법은 Deep Learning 분야 뿐만 아니라 아주 일반적인 개념으로 널리 쓰인다.
위의 classify_image(image)와 다른 점은 함수가 2개로 나뉜다.
그 중 첫번재 classifier로 Nearest Neighbor이다.
[train]
def train(images, labels):
# Machine learning
# return model[predict]
def predict(model, test_images):
# use model to predict labels
return test_labels[train]은 우리가 하는 일은 아무것도 없으며, 단지 데이터와 레이블을 메모라이즈 해주면 된다.
[predict]는 새로운 이미지가 들어오면 기존 학습 데이터를 비교해서 가장 유사한 이미지로 레이블링을 예측한다.
maching learning에서 자주 쓰는 test용 데이터셋 CIFAR10을 NN에 적용시켜보자.

위 이미지중 오른쪽에 있는 이미지들을 주목하자.
이 중 맨 왼쪽에 있는 이미지들은 테스트 이미지들이고,
화살표 옆에 오른쪽의 이미지들은 Nearest neighbors. 즉, 유사하다고 여겨지는 이미지들이 나열된 것이다.
여기서 관건은 "어떤 비교함수를 사용할지"이고,
풀어서 말하자면 "이미지 쌍이 있을 때 어떻게 비교할 것인가?"이다.
그 중 가장 간단한 함수인 L1 distance를 사용해보자.
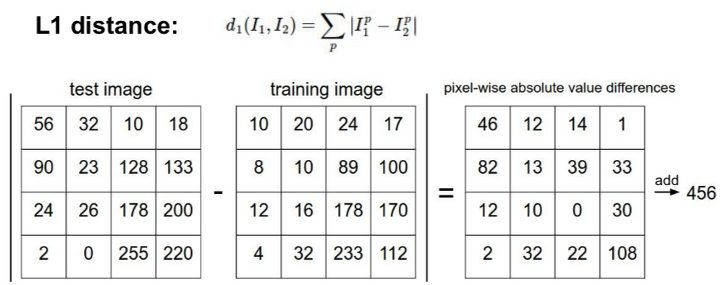
이미지를 pixel-wise로 비교한다.
이 함수를 사용해보며 알 수 있는 것은,
"두 이미지간에 차이를 어떻게 측정할 것인가?"에 대한 구체적인 방법을 제시한다.
맨 오른쪽은 최종적으로 456은 두 이미지간의 차이를 나타낸다.
NN을 식으로만 보면 감이 잡히지 않으니 decision regions를 이용하여 시각적으로 보면 밑에와 같다.
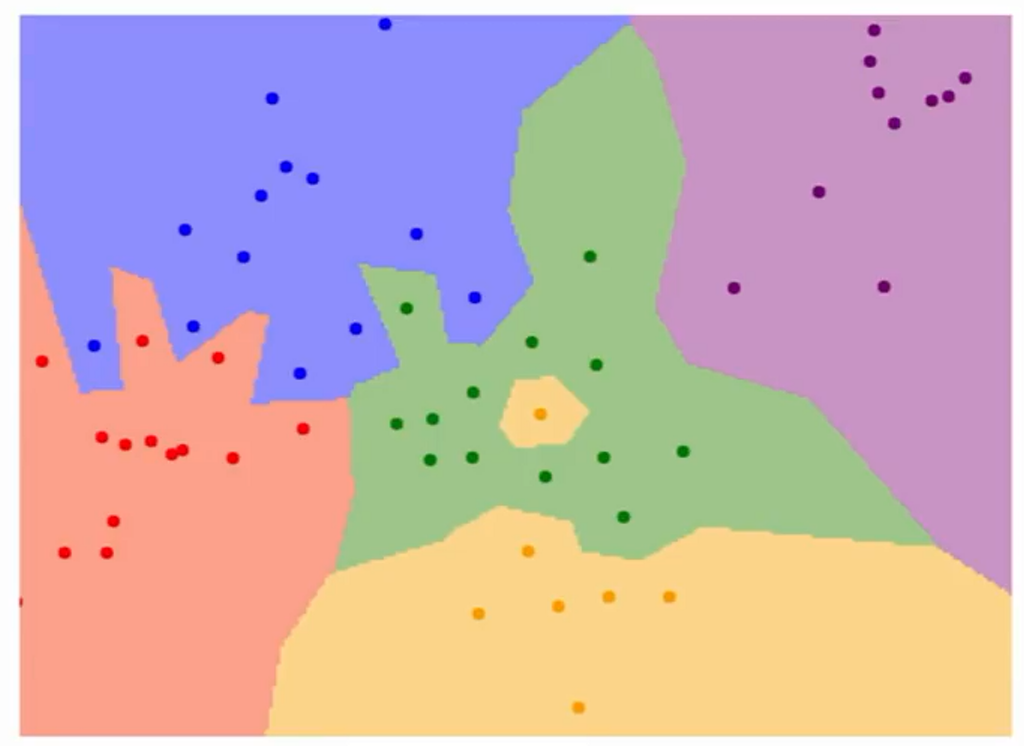
위의 이미지를 보면 레이블끼리의 구분을 색깔을 기준으로 경계를 나눈다.
초록색 영역 가운데 노란색 영역이라던지, 파란색 영역으로 초록색 영역이 비집고 들어가는 것을 볼 수 있다. 일명 noise(잡음)이라고 한다.
noise들을 없애기 위해 NN을 대신해서 고안한 알고리즘이 K-NN이다.
요약하자면, 가까운 이웃 k개가 이웃끼리 투표해서 가장 많은 득표수를 획득한 레이블로 예측하는 알고리즘이다.
NN은 k=1인 상태이다.
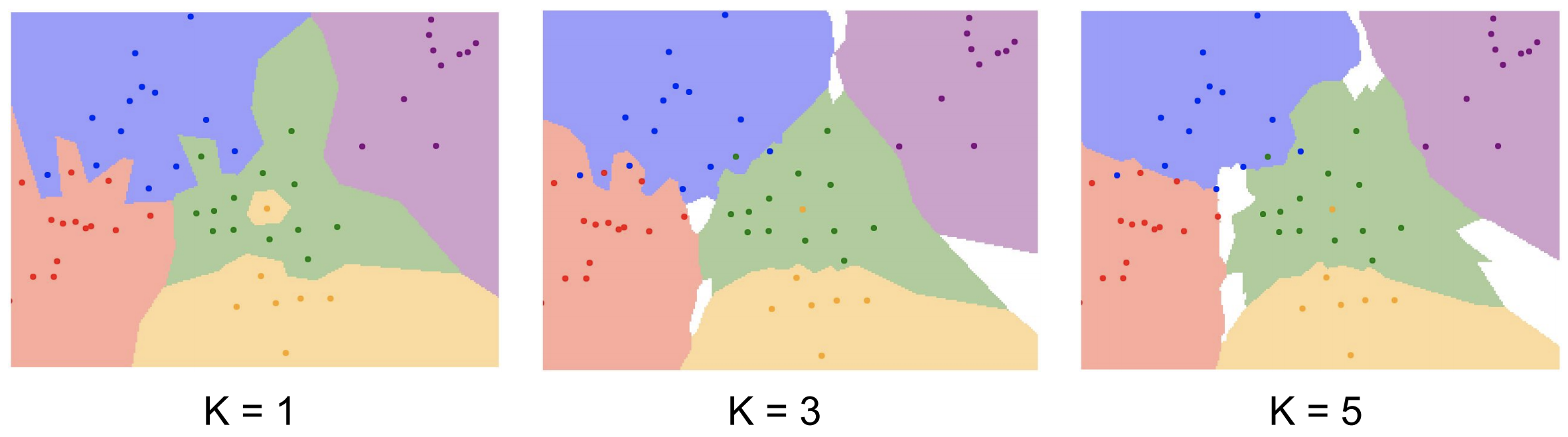
이제까지 보면 k-NN을 사용시 결정해야할 사항이 있다는 것을 살펴볼 수 있다.
"서로 다른 점들을 어떻게 비교할 것인가?"
- 첫번째는 위에 있는 L1(Manhattan) distance : 픽셀 간 차이 절대값의 합
기존 좌표계를 회전시키면 L1 distance가 변한다.
어떤 좌표시스템이냐에 따라 많은 영향을 받는다. - 두번째는 L2(Euclidean) distance : 제곱합의 제곱근
좌표계와 아무런 연관이 없다.
특정 벡터의 요소들이 개별적인 의미를 가지고 있다면 L1이 좀더 어울리며(eg. 키, 몸무게),
특정 벡터가 Generic vector(일반적인)이고, 요소들 간에 실질적인 의미를 잘 모르겠는 경우 L2가 좀더 어울린다.
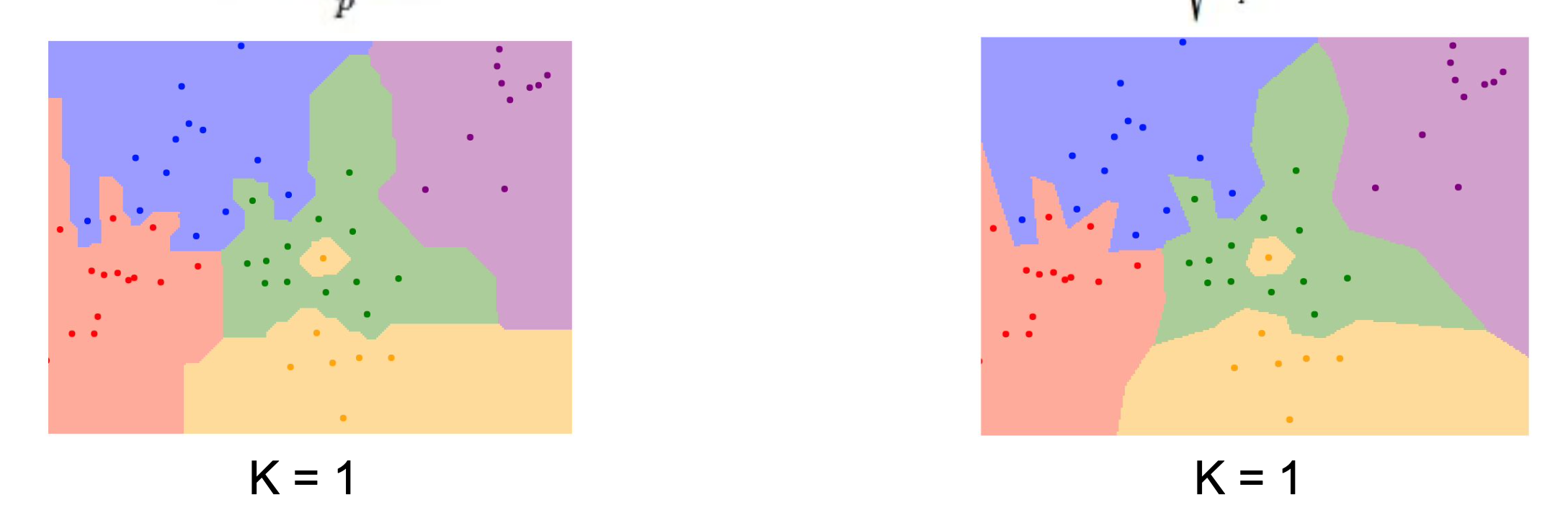
왼쪽은 L1, 오른쪽은 L2이다.
두 이미지에서 색깔 별로 경계가 나눠져있는 것을 decision boundary(결정경계)라고 한다.
L2의 경계가 L1의 경계보다 조금 더 부드러운 것을 볼 수 있다.
L2는 특정 요소가 없는 일반적인 벡터로 이루어져있기 때문에 경계가 부드러운 것이다.
k-NN을 demo 해볼수 있는 사이트가 있다. 밑에 링크를 달아 놓겠다.
demo
Hyperparameters
HyperParameter는 내 문제에 꼭 필요한 방법을 찾는 것이다.
이번 포스팅에서는 최선의 K, 그리고 최선의 distance을 찾는 것이 hyperparameter이다. HyperParameter를 찾는 방법은 다양한 HyperParameter값을 시도해보고 가장 좋은 값을 찾는다.
다양한 방법에는 여러가지 아이디어가 있는데, 그 중 4가지를 소개하겠다.
Idea 1
"Choose hyperparameters that work best on the data."

이 방법은 최악이라고 소개한다. 왜냐하면 학습데이터의 정확도와 성능을 최대화하는 것은 의미가 없기 때문이다(학습데이터에만 신경을 쓴다는 의미이다). 우리가 학습시킨 분류기가 한번도 보지 못한 데이터를 얼마나 잘 예측하는지가 중요하다.
Idea 2
2번째는 data를 train과 test로 나누는 방법이다.

학습시킨 모델들 중 테스트 데이터에 가장 잘맞는 모델을 선택한다면, 그저 "테스트 셋에서만" 잘 동작하는 hyperparameter를 고른 걸 수도 있다.
이렇게 되면 더이상 test에서의 성능은 한번도 보지 못한 dataset에서의 성능을 대표할 수는 없다.
Idea 3
3번째는 data를 train과 validation(검증), test로 나누는 것이다.

다양한 hyperparameter를 train에 학습시키고, 가장 성과가 좋았던 Hyperparameter로 validation(검증)을 한다. 최종적으로 개발과 디버깅을 마친 후, validation에서 가장 좋았던 classifier로 test데이터에서 "오로지 한번만" 수행한다.
앞선 2개의 아이디어 보다 훨 나은 방법이다. 하지만 3번째 아이디를 좀더 발전 시켜보도록 하겠다.
Idea 4 : Cross-validation
4번째는 3번째와 train, validation, test를 나누는 것은 동일하지만 train을 좀더 여러 구간(fold)으로 쪼개어 돌아가며 학습을 시켜본다. 이를 Cross-validation이라고 한다.
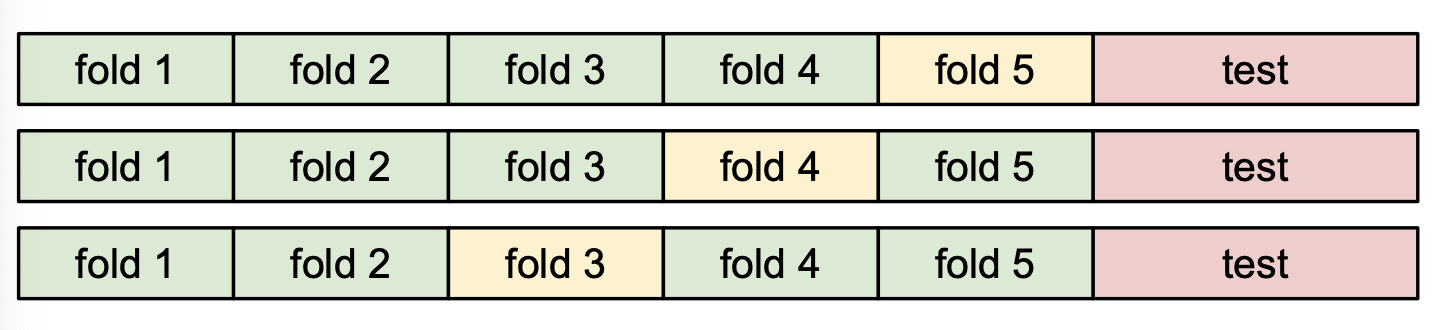
이는 마치 수능 보기 전 모의고사와 같다(아.... 수능...모의고사...^_^...).
노란색으로 질해진 부분이 최종 모의고사, 앞선 초록색 fold들은 이전 모의고사들이다. test는 수능이라고 생각하면 된다.
작은 데이터셋에서는 사용하지만, 딥러닝에선 잘 사용하지 않는다.
[train과 validation의 차이]
- train은 label(정답)이 보이지만, validation은 볼 수 없다.
- validation은 알고리즘이 잘 동작하는지 확인 용도로 쓰인다.
위와 같이 이미지에 대해서 배웠다. 하지만 결론이란 것이 있다.
k-NN은 이미지에선 절대 쓰이지 않는다....^_^....
- 너무 느리다.
- 앞에서 소개한 Distance(거리측정)가 이미지간의 거리를 측정하는데 적절하지 않다.

- Curse of dimensionality(차원의 저주) : 차원이 증가함에 따라 빈공간이 생기는 현상을 말한다. 빈공간이 생겼다는 것은 컴퓨터 상으로 0으로 채워졌다는 뜻이며, 정보가 적으니 모델의 성능이 떨어진다.
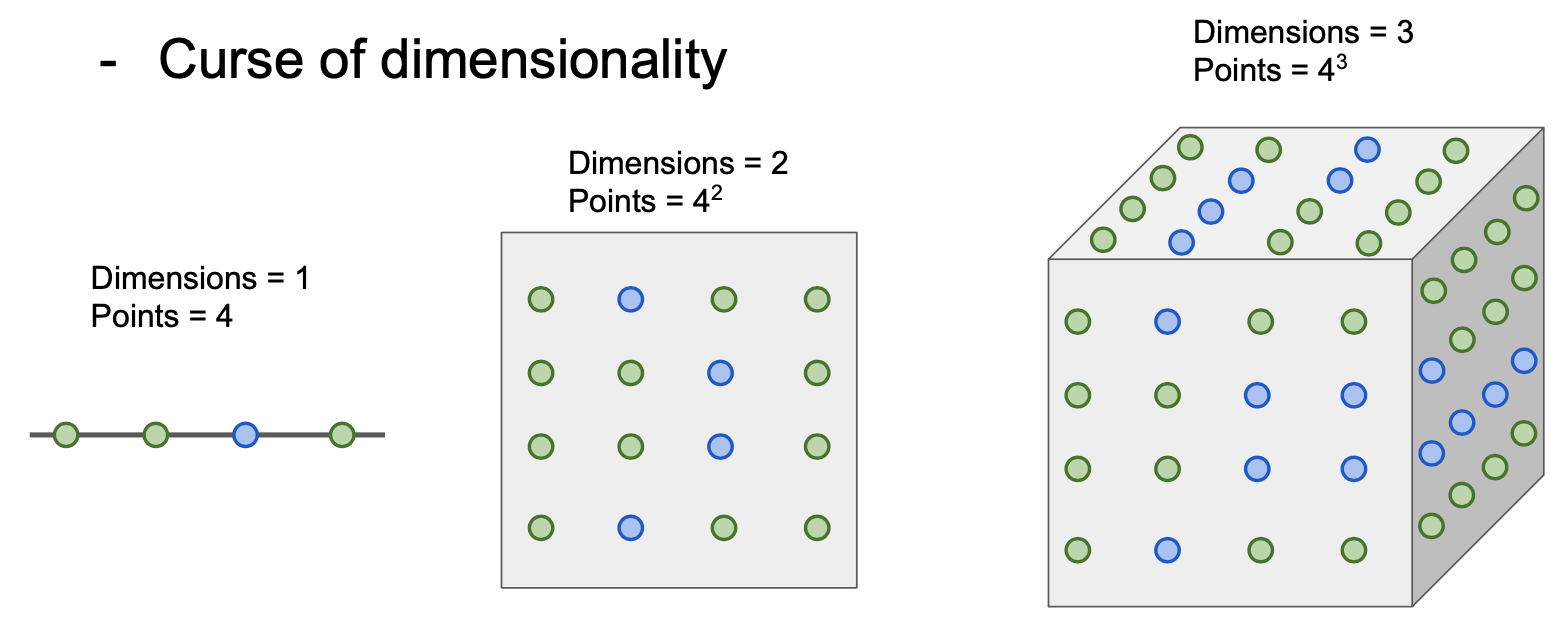
위의 내용을 토대로 요약해보자면....
- K-NN은 실제로는 성능이 좋지 않으며 더더욱 이미지 데이터들에서는 사용하지 않는다.
