DeepML
1.Deep ML. Image Classification - kNN

"The job of computer is to look at the picture and assign it one of these fixed category labels." 인간은 이미지를 보고 어떤 카테고리에 속할 지 바로 고를 수 있다. 이러한 일을 컴퓨터에
2.Deep ML. Image Classification - Linear Classification
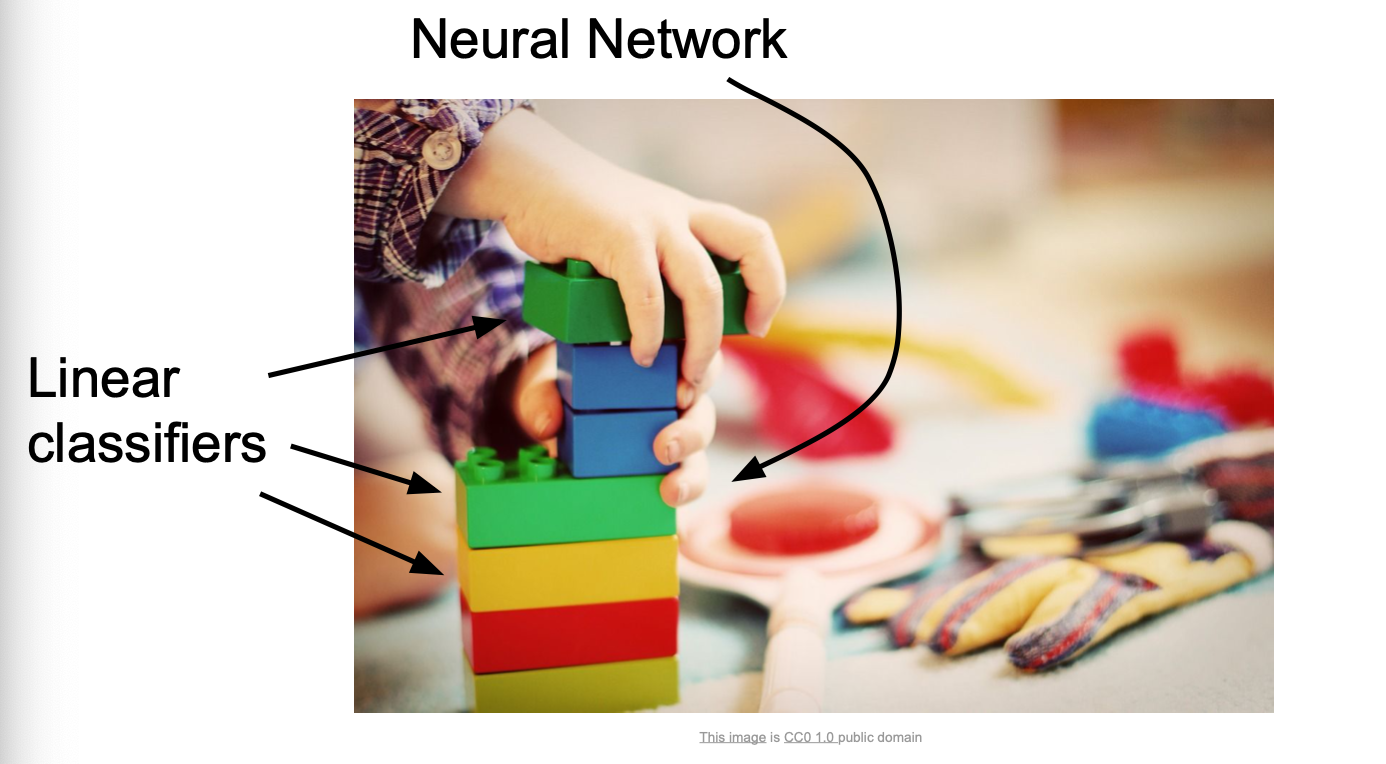
Linear Classification은 NN(Neural Networks)과 CNN(Convolutional Networks)에 기반 알고리즘이다.위 그림과 같이 NN을 Linear classifier라는 블럭을 쌓아올린 레고와 같다고 여기면 된다.위 사진들은 CNN
3.Deep ML. Loss Functions (손실함수)

지난 포스팅에서 Linear Classifier는 parametric classifier의 일종이며, parametric classifier 라는 것은 training data의 정보가 파라미터인 '행렬 W'로 요약된다는 것을 뜻하고, W가 학습되는 것이라 배웠다.
4.Deep ML. Regularization 정규화, softmax Classifier( loss function )
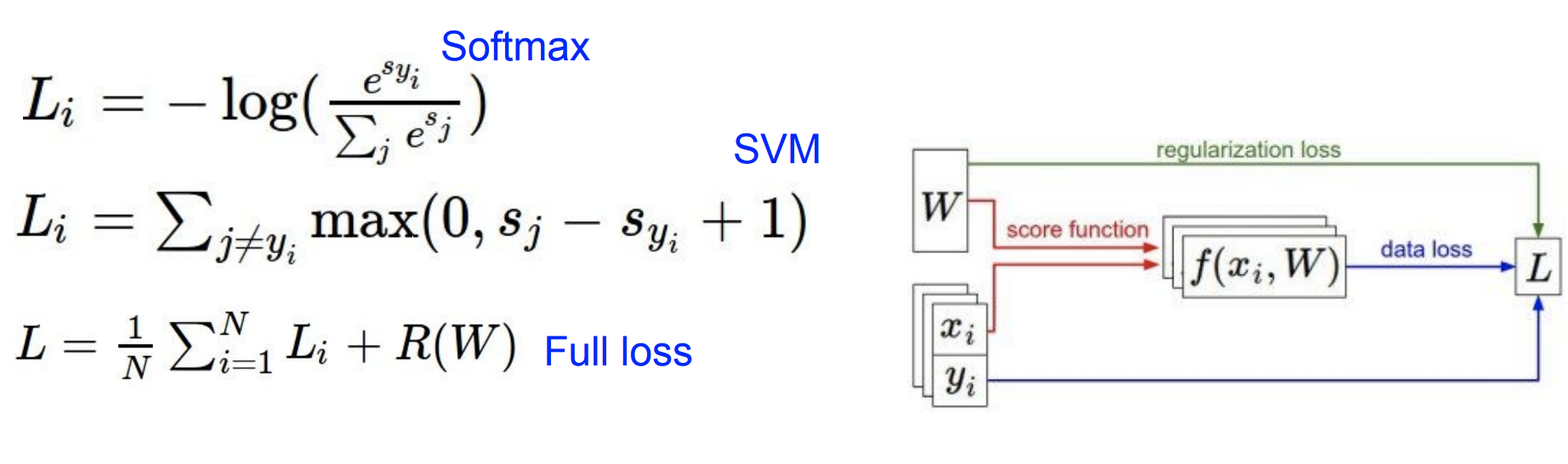
앞선 포스팅에서 Model의 복잡함을 좀 더 단순한 W를 선택하도록 도와주는 역할을 하는 것이 Regularization(정규화)이라고 말했다. 일반적인 Loss Function에서는 2가지 항을 가지게 된다. data loss regularization loss h
5.Deep ML. Optimization

이번 포스팅에서는 이전 포스팅의 내용을 이어서 최적의 $W$를 찾는 Optimization에 대해 소개해보겠다. 비유를 통해 설명해보겠다. 아래처럼 산과 계곡을 걸어 내려가본다고 생각해보자.여기서 산과 계곡이 $W$이며, 인간이 있는 높이는 Loss이다. Loss는 $
6.DeepML. Neural Network - 1
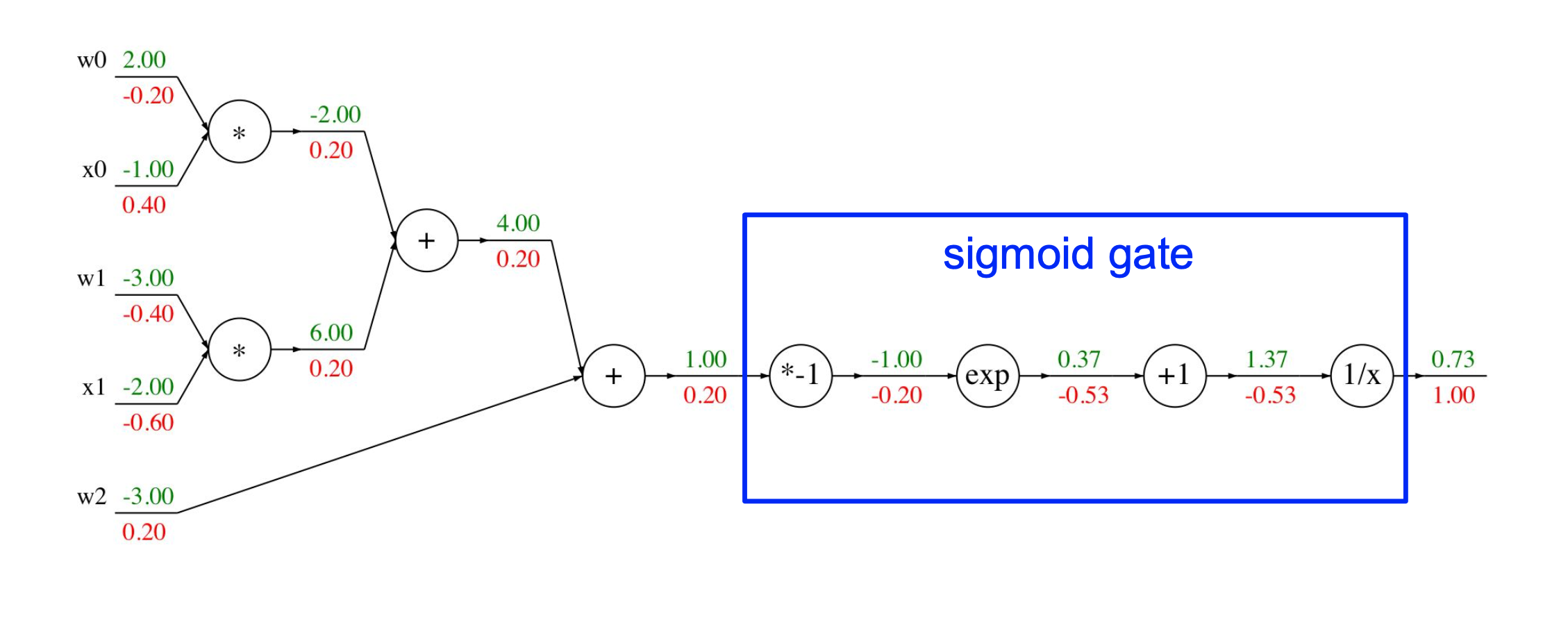
scores function $s = f(x; W) = Wx$ $s$는 score vector(output)이며 $x$는 input이다. SVM loss $Li = \sum{j \ne yi} \text{max}(0, sj - s{yi} + 1)$ data loss
7.DeepML. Neural Network - 2
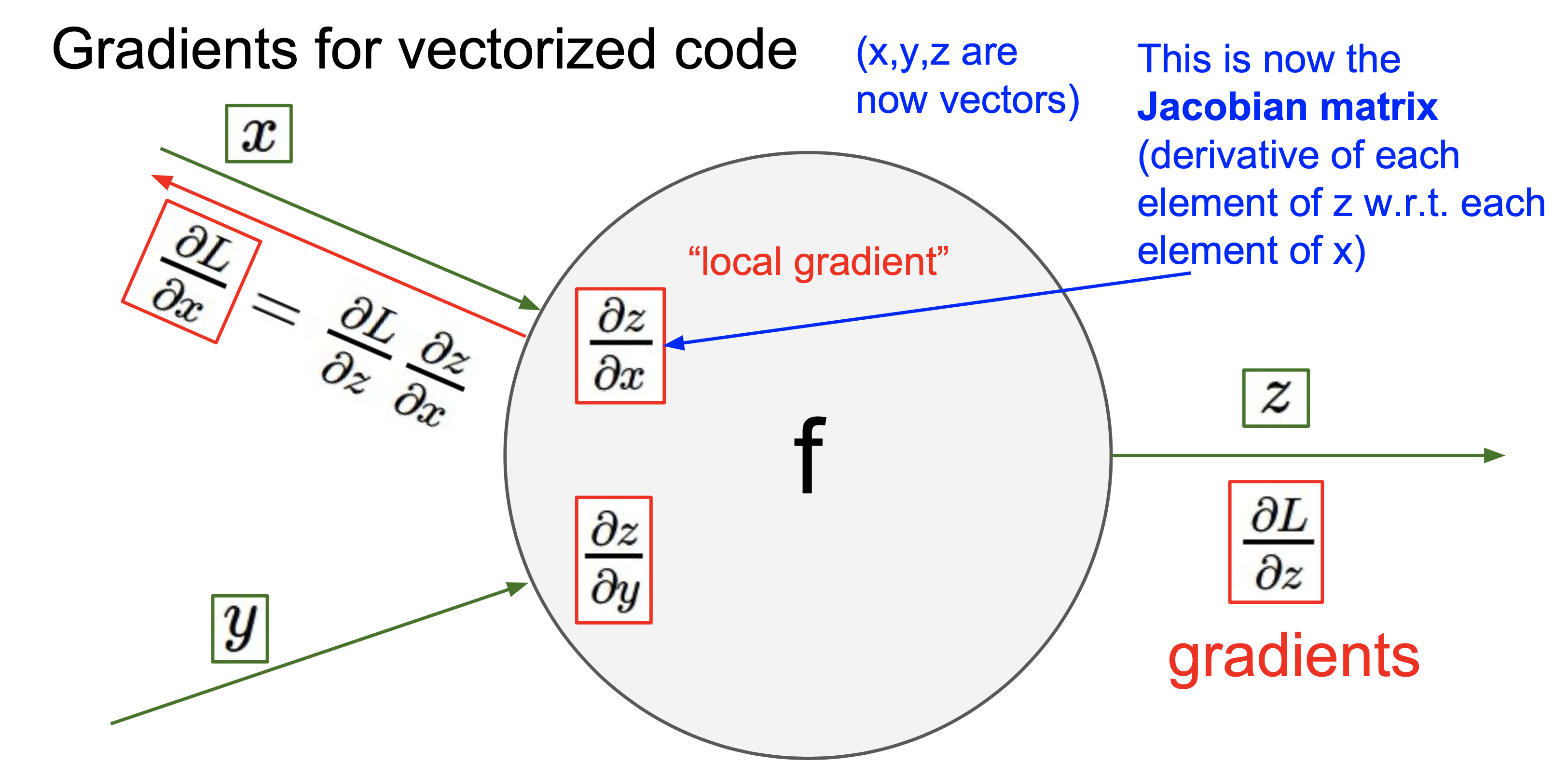
위는 벡터인 경우 연산을 대략적으로 그린 그림이다.위와 같은 연산이 있다고 생각해보자.여기서 Jacobian matrix는 $\\partial f \\over \\partial x$이다.이때 Jacobian matrix의 사이즈는 4096x4096 이다. 이때 Jaco
8.DeepML. Convolutional Neural Networks
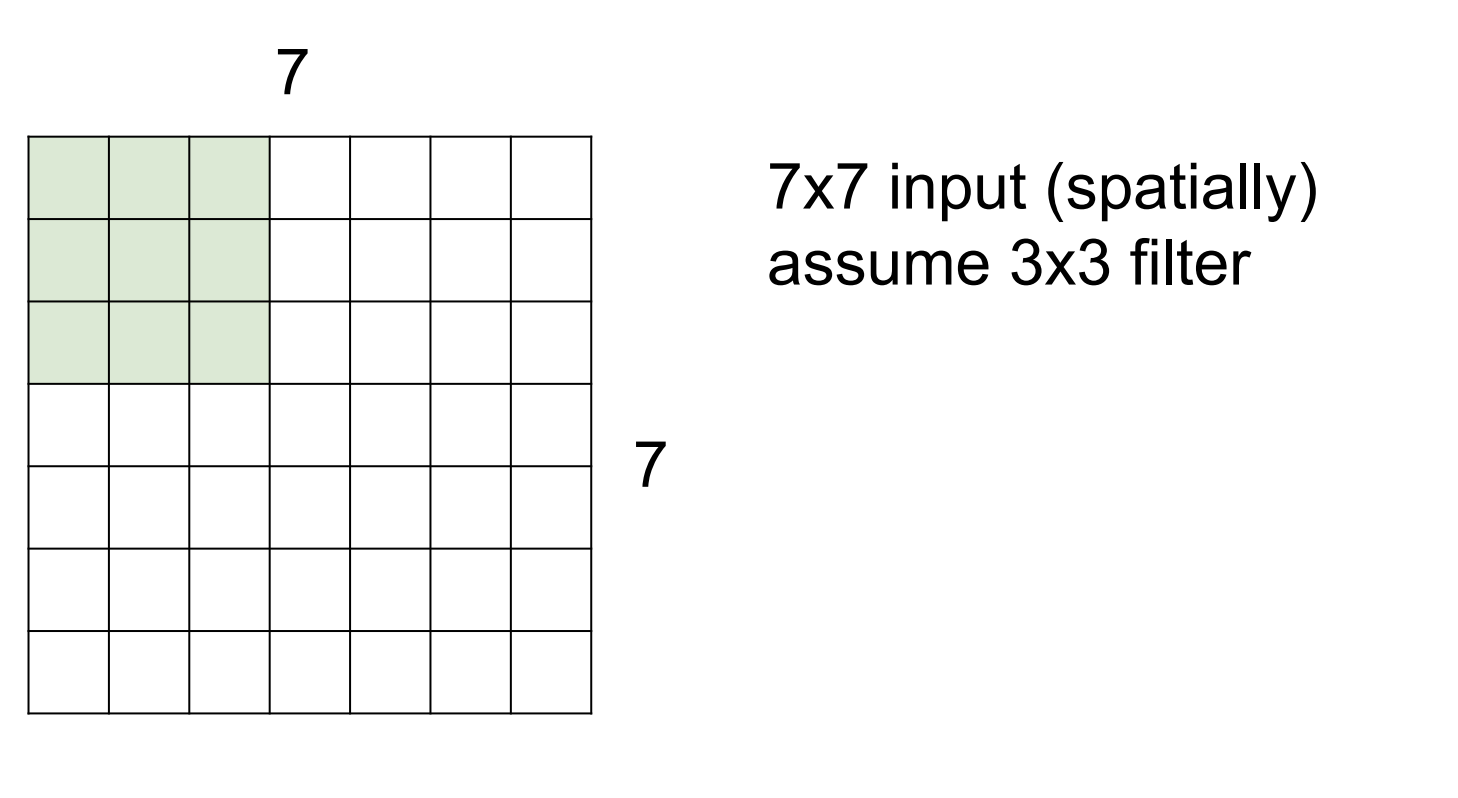
Fully Connected Layer Convolutional Layer filter는 가중치 역할을 한다. 아래와 같은 연산을 행
9.DeepML. Training Neural Networks
[목차] Activation Functions Data Preprocessing Weight Initialization Batch Normalization Babysitting the Learning Process Hyperparameter Optimization A