scikit-learn에서 사용할 알고리즘을 어떻게 분류해놨는지 밑에 링크를 통해 볼 수 있다.
choosing right algorithm
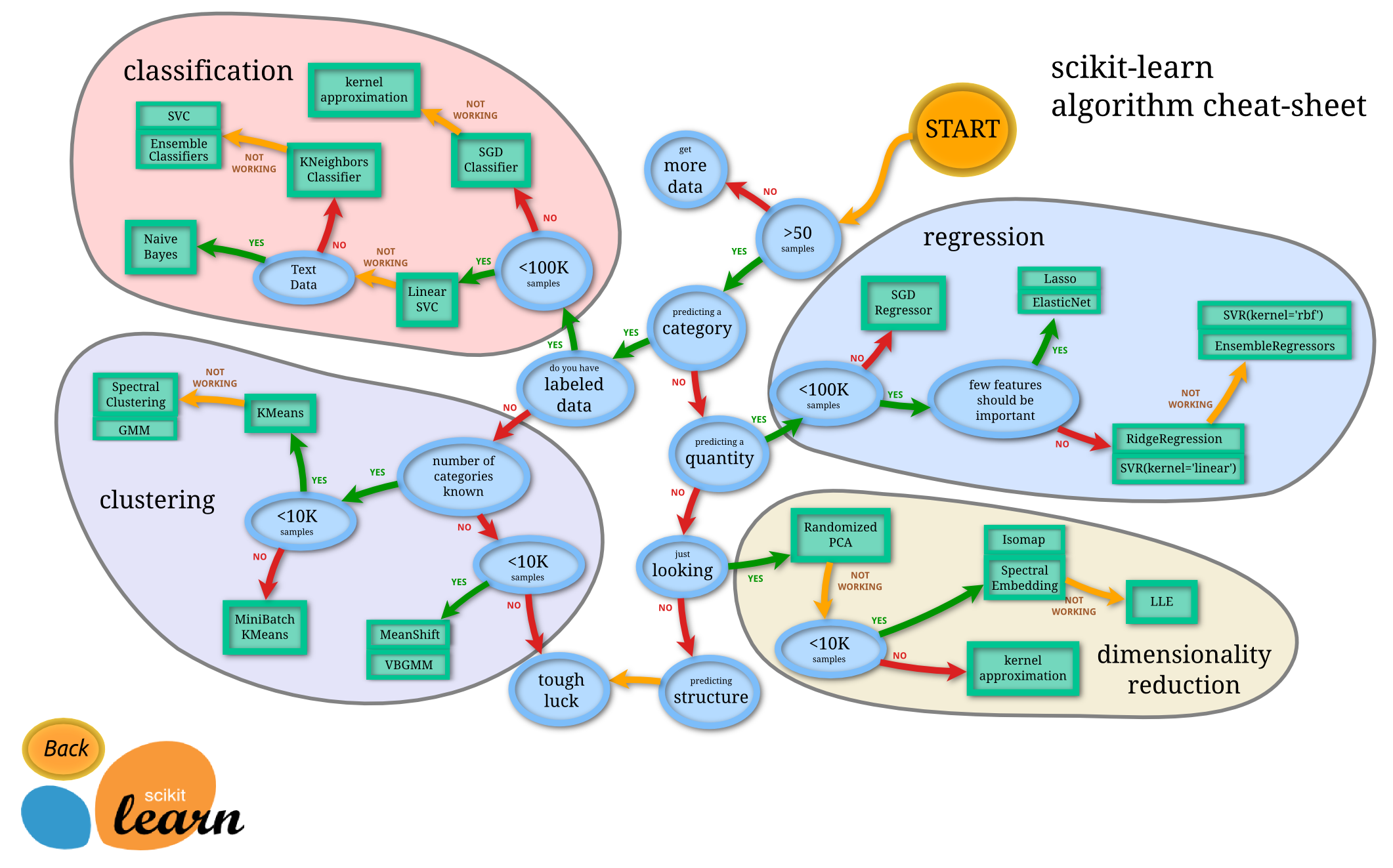
출처 : scikit-learn 공식 홈페이지
scikit-learn에서는 알고리즘을 크게 3가지 기준으로 나누었다.
- 데이터 량
- 라벨의 유무(정답의 유무)
- 데이터의 종류 ( 수치형 데이터(quantity), 범주형 데이터(category) 등등 )
분류 기준은 새로운 기술이 나오면 시시각각 바뀔 것이다.
scikit-learn package 설치 명령어이다.
!pip install scikit-learn
#!conda install scikit-learnscikit learn을 설치했으면 모듈을 import 한 뒤 버전을 확인해보자. 참고로, scikit-learn은 설치명과 import할 때 이름이 다르다. import 할 때는 sklearn이라고 써야한다.
import sklearn
print(sklearn.__version__)scikit-learn에서 중요한 메소드들이 몇개 있다.
train_test_split(): train데이터와 test데이터를 나눠주는model_selection객체 안의 메소드.transformer(): ETL(Extract Transform Load)부분에서 사용하는 메소드.fit(),predict(): 모델의 훈련과 예측을 담당하는Estimator객체에서 사용하는 메소드들,Pipeline(): 모델의 훈련과 예측이 끝나면 이 2가지 작업을 묶어 검증을 수행하는 메소드
다음 포스트 부터 차차 배워보도록 하자.
