머신러닝 알고리즘 종류는 대표적으로 3가지로 나눌 수 있다.
- Supervised Learning(지도 학습)
- Unsupervised Learning(비지도 학습)
- Reinforcement Learning(강화 학습)
참고사이트
문제들에 적합한 알고리즘 정리한 알고리즘 cheatsheet에 대한 내용을 위에 링크로 걸어두었다.
밑에는 내가 찾은 cheatsheet다.
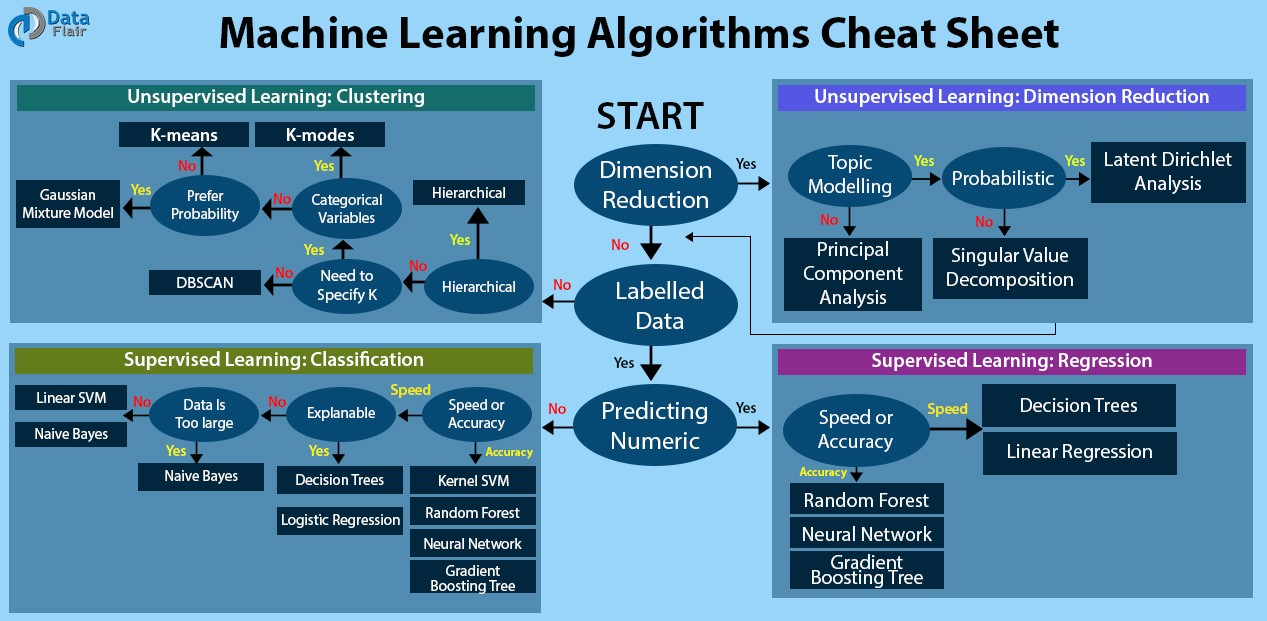
출처
위의 sheet를 보면 어느 문제에는 어떠한 알고리즘이 적합한지 확인이 가능하다.
예를 들어 보자면,
- If you want to perform dimension reduction then use principal component analysis.
(차원 축소를 수행하고 싶으면 주성분 분석을 사용한다.) - If you need a numeric prediction quickly, use decision trees or logistic regression.
(신속한 수치 예측이 필요하면 의사결정 트리 또는 로지스틱 회귀를 사용한다.) - If you need a hierarchical result, use hierarchical clustering.
(계층적 결과가 필요하면 계층적 클러스터링을 사용한다.)
Supervised Learning(지도 학습)
지도 학습은 사례들을(examples) 기반으로 예측을 수행한다.
(eg. 과거 매출데이터 -> 미래 매출데이터)
- Classification(분류) : 데이터로 범주형(categorical) 변수를 예측하기 위해 사용한다. 레이블(label) 또는 지표(indicator)가 2개인 경우 '이진 분류(binary classification)'이라 하고, 3개 이상인 경우는 '다중 클래스 분류(multi-class classification)'라고 한다.
(eg. 강아지, 고양이, 비행기 분류...) - Regression(회귀) : 연속적인 값을 예측할 때 사용한다.
(eg. 주택가격....^^ㅋ) - Forecasting(예측) : 과거 혹은 현재 데이터를 기반으로 미래를 예측할때 사용한다. 예측은 동향(trends)을 분석하기 위해 가장 많이 사용되며, 예를 들어보자면 올해와 전년도 매출을 기반으로 내년도 매출을 추산하는 작업 등에 쓰인다.
Unsupervised learning(비지도학습)
비지도 학습을 수행할 시 기계는 미분류 데이터만을 받는다.
- 클러스터링(Clustering) : 특정 기준에 따라 유사한 데이터 사례들을 세트별로 그룹화한다. 즉, 전체 데이터 세트를 여러 그룹으로 분류하기 위해 사용된다.
(eg. 뉴스 그룹) - 차원 축소(Dimension Reduction): 고려 중인 변수(feature)의 개수를 줄이는 작업을 할때 사용한다. 많은 application에서 raw data(원시 데이터: 있는 그대로의 데이터)는 아주 높은 차원의 특징을 지닌다. 이 작업을 통해 일부 특징들은 중복되거나 아무 관련이 없을 수 있으며, 따라서 차원수(dimensionality)를 줄이면 진정으로 필요한 변수들은 어떠한 것들이 있는 도출할 수 있다.
[지도 학습과 비지도 학습의 차이]
보통 라벨(label: 정답)의 존재 유무에 따라 머신러닝을 지도학습과 비지도학습으로 나눕니다.
보통 라벨(label: 정답)의 존재 유무에 따라 머신러닝을 지도학습과 비지도학습으로 나눕니다.
Reinforcement Learning(강화 학습)
강화학습은 지도학습, 비지도학습과는 다른 종류의 알고리즘이다.
학습하는 시스템(행위자)을 '에이전트'라고 하고, 환경을 관찰해서 에이전트가 스스로 행동하게 하며, 그 결과로 모델은 보상을 받는다. 이 보상을 최대화 하도록 학습한다.
요약하자면, 어떤 액션을 취해야 할지 보다는 최고의 보상을 도출하는 액션을 발견하기 위해 서로 다른 시나리오를 시도한다고 이해하면 된다.
강화학습에서 쓰이는 기본 용어들은 아래와 같다.
- Agent(에이전트): 학습 주체, 행위자 (혹은 actor, controller)
- Environment(환경): 에이전트에게 주어진 환경, 상황, 조건
- Action(행동): 환경으로부터 주어진 정보를 바탕으로 에이전트가 판단한 행동
- Reward(보상): 행동에 대한 보상을 머신러닝 엔지니어가 설계
다음은 강화학습 알고리즘의 대표적인 종류는 아래와 같다.
- Monte Carlo methods
- Q-Learning
- Policy Gradient methods
위의 3가지 대표적인 알고리즘 기법들을 살펴보면서 알고리즘 선택 시 고려해야할 상황을 정리해보자.
- 정확성
- 학습시간
- 사용 편의성
데이터 세트가 제공되었을 때 가장 먼저 고려해야 할 것은 '어떤 결과가 나올 것인지에 상관없이 어떻게 결과를 얻을 것인가'이다.
