그동안 주로 배워온 딥러닝 모델들이 주로 수행하는 작업들은 정답 데이터를 통해 X가 무엇인지 분류하는 방법을 배우게 하는 지도학습(Supervised Learning)이였다.
그러나 명확한 정답 데이터가 라벨(label)로 달려있지 않은 수많은 데이터들을 다룰땐 비지도학습(Unsupervised Learning)을 한다.
비지도학습은 주어진 데이터가 어떻게 구성되어 있는지 스스로 알아내며, 아무도 정답을 알려주지 않은 채 오로지 데이터셋의 특징(feature) 및 패턴을 기반으로 모델 스스로가 판단한다.
지도학습의 대표적인 예로 분류(classification) 문제가 있다.
비지도학습의 대표적인 예시로는 군집화(클러스터링, clustering) 가 있지만, 비지도학습이라는 용어는 정답이 없는 데이터를 이용한 학습 전체를 포괄하는 용어이다.
클러스터링 외에도 차원 축소(dimensionality reduction) 및 이를 이용한 데이터 시각화, 생성 모델(generative model) 등 포괄하는 개념이다.
이번 포스팅에서는 클러스터링의 대표적인 알고리즘인
- K-means, DBSCAN
- 차원 축소 : PCA(Principal Component Analysis), T-SNE
에 대해 알아보자.
클러스터링
K-means
군집화(클러스터링)이란 그렇게 명확한 분류 기준이 없는 상황에서도 데이터들을 분석하여 가까운(또는 유사한) 것들끼리 묶어 주는 작업이다. 명확한 분류 기준이 없다면 무엇을 기준으로 묶어낼 수 있냐에 물음이 생긴다.
가장 간단한 방법은 임의로 k개의 그룹으로 묶어보는 것이다. 다만, 아무렇게나 묶는 것이 아니라 k개의 기준점을 중심으로 가장 가까운 데이터들을 뭉쳐 보는 것이다. K-means 알고리즘은 k 값이 주어져 있을 때, 주어진 데이터들을 k 개의 클러스터로 묶는 알고리즘이다.
데이터 생성
%matplotlib inline
from sklearn.datasets import make_blobs
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
# 중심점(center point)이 5개인 100개의 점 데이터를 무작위로 생성
points, labels = make_blobs(n_samples=100, centers=5, n_features=2, random_state=77)
print(points.shape, points[:10]) # 점의 좌표 10개 출력
print(labels.shape, labels[:10]) # 점들이 각각 대응하는 중심점(label) 값 scikit-learn의 make_blob()을 활용하여 중심점(center point)이 5개인 무작위의 점 데이터 100개를 생성한다. 임의로 지정한 k개의 중심점이 새로운 label 역할을 하는 것이 K-means 의 아이디어이다.
생성한 데이터에 K-means 알고리즘 적용
K-mean의 순서는 다음과 같다.
[1] 원하는 클러스터의 수(K)를 설정한다.
[2] 무작위로 클러스터의 수와 같은 K개의 중심점(centroid)을 선정한다. 이들은 각각의 클러스터를 대표한다.
[3] 나머지 점들과 모든 중심점 간의 유클리드 거리를 계산한 후, 가장 가까운 거리를 가지는 중심점의 클러스터에 속하도록 한다.
[4] 각 K개의 클러스터의 중심점을 재조정 후, 특정 클러스터에 속하는 모든 점들의 평균값이 해당 클러스터 다음 iteration의 중심점이 된다.(이 중심점은 실제로 존재하는 데이터가 아니어도 상관없다.)
[5] 재조정된 중심점을 바탕으로 모든 점들과 새로 조정된 중심점 간의 유클리드 거리를 다시 계산한 후, 가장 가까운 거리를 가지는 클러스터에 해당 점을 재배정한다.
[6][4]번과 [5]번을 반복 수행한다. 반복의 횟수는 사용자가 적절히 조절하면 되고, 특정 iteration 이상이 되면 수렴(중심점이 더 이상 바뀌지 않음)하게 된다.
Kmean를 쓰고 싶으면 sklearn.cluster안에 KMeans쓰면 된다.
from sklearn.cluster import KMeans
# 클러스터의 수(K)가 5인 K-means 알고리즘을 적용
kmeans_cluster = KMeans(n_clusters=5)
# 3. ~ 6. 과정. points에 대하여 K가 5일 때의 K-means iteration을 수행
kmeans_cluster.fit(points)
print(type(kmeans_cluster.labels_))
print(np.shape(kmeans_cluster.labels_))
print(np.unique(kmeans_cluster.labels_))
------------------------------------------------
<class 'numpy.ndarray'>
(100,)
[0 1 2 3 4]KMeans의 결과를 시각화 하면 아래와 같다.
# n 번째 클러스터 데이터 색깔
color_dict = {0: 'red', 1: 'blue', 2:'green', 3:'brown', 4:'indigo'}
# 점 데이터를 X-Y grid에 시각화
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# K-means clustering의 결과대로 색깔별로 구분하여 점에 색칠한 후 도식
for cluster in range(5):
# 전체 무작위 점 데이터에서 K-means 알고리즘에 의해 군집화된 sub data를 분리
cluster_sub_points = points[kmeans_cluster.labels_ == cluster]
# 해당 sub data를 plot화 한다.
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
# 라벨, 점 데이터 그리기
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()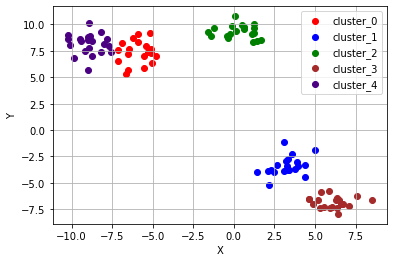
위 그림에서 확인할 수 있듯이 K-means 알고리즘은 군집의 수만 주어진다면, 데이터의 군집화를 매우 잘 수행한다. 하지만, K-means 알고리즘이 항상 만능인 것은 아니며, 주어진 데이터의 분포에 따라 의도하지 않은 결과를 초래할 수 있다.
K-means 알고리즘이 잘 동작하지 않는 예시들
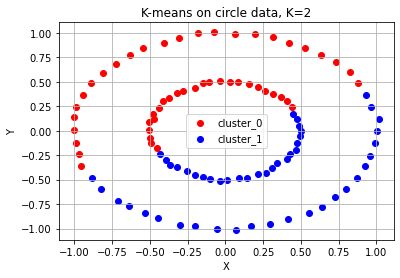
첫 번째, 원형으로 분포되어 있는 데이터 같은 경우는 '가운데 작은 원'과 '바깥쪽 큰 원' 두 개의 군집으로 분류하기를 원했을 테지만, 반으로 나뉘었다.
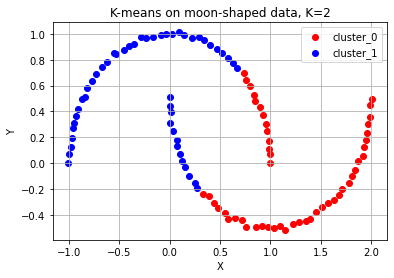
두 번째, 초승달 모양의 데이터도 두 개의 달 형태를 분리해서 군집화하지 않고, 이 역시 y축에 대하여 칼로 자른 형태의 느낌으로 두 개로 군집이 나뉘었다.
세번째, 3개의 대각선 방향으로 나열되어 있는 데이터들도 군집을 이루지 않는다.
- 군집의 개수(K 값)를 미리 지정해야 하기 때문에 이를 알거나 예측하기 어려운 경우에는 사용하기 어렵다.
- 유클리드 거리가 가까운 데이터끼리 군집이 형성되기 때문에 데이터의 분포에 따라 유클리드 거리가 멀면서 밀접하게 연관되어 있는 데이터들의 군집화를 성공적으로 수행하지 못할 수 있다.
위의 경우처럼 군집의 개수(K)를 명시하지 않으면서, 밀도 기반으로 군집을 예측하는 방법이 있다. 밑에서 소개할 DBSCAN 알고리즘이다.
DBSCAN
DBSCAN(Density Based Spatial Clustering of Applications with Noise) 알고리즘은 가장 널리 알려진 밀도(density) 기반의 군집 알고리즘이며, K-means을 사용하여 어려웠던 문제들을 해결한다.
DBSCAN 알고리즘의 가장 큰 특징 중 하나는 군집의 개수(K)를 지정할 필요가 없다.
알고리즘에 대해 자세히 알고 싶다면 아래 링크를 클릭하면 된다.
DBSCAN가 밀도 알고리즘인 이유는 클러스터가 최초의 임의의 점 하나로부터 점점 퍼져나가는데 그 기준이 바로 일정 반경 안의 데이터의 개수, 즉 데이터의 밀도이다.
DBSCAN 알고리즘의 동작
DBSCAN을 이해하는 데 필요한 변수와 용어를 정리해보자.
- epsilon: 클러스터의 반경
- minPts: 클러스터를 이루는 개체의 최솟값
- core point: 반경 epsilon 내에 minPts 개 이상의 점이 존재하는 중심점
- border point: 군집의 중심이 되지는 못하지만, 군집에 속하는 점
- noise point: 군집에 포함되지 못하는 점
K-means에서 K 값을 지정해야 했다면,
DBSCAN에서는 epsilon과 minPts 값을 미리 지정해 주어야 한다.
[1] 임의의 점 p를 설정하고, p를 포함하여 주어진 클러스터의 반경(elipson) 안에 포함되어 있는 점들의 개수를 센다.
[2] 만일 해당 원에 minPts 개 이상의 점이 포함되어 있으면,
해당 점 p를 core point로 간주하고 원에 포함된 점들을 하나의 클러스터로 묶는다.
[3] 해당 원에 minPts 개 미만의 점이 포함되어 있으면, 일단 pass
[4] 모든 점에 대하여 돌아가면서 [1]~[3] 번의 과정을 반복하는데, 만일 새로운 점 p'가 core point가 되고 이 점이 기존의 클러스터(p를 core point로 하는)에 속한다면, 두 개의 클러스터는 연결되어 있다고 하며 하나의 클러스터로 묶어준다.
[5] 모든 점에 대하여 클러스터링 과정을 끝냈는데, 어떤 점을 중심으로 하더라도 클러스터에 속하지 못하는 점이 있으면 이를noise point로 간주한다. 또한, 특정 군집에는 속하지만 core point가 아닌 점들을border point라고 한다.
DBSCAN 알고리즘을 적용해보기
scikit-learn의 DBSCAN을 사용해서 알고리즘을 사용해보자.
[원형]
# DBSCAN으로 circle, moon, diagonal shaped data를 군집화한 결과
from sklearn.cluster import DBSCAN
fig = plt.figure()
ax= fig.add_subplot(1, 1, 1)
# n 번째 클러스터 데이터를 어떤 색으로 도식할지 결정
color_dict = {0: 'red', 1: 'blue', 2: 'green', 3:'brown',4:'purple'}
# 원형 분포 데이터 plot
# [2]와 [3] 과정에서 사용할 epsilon, minPts 값을 설정
epsilon, minPts = 0.2, 3
# 위에서 생성한 원형 분포 데이터에 DBSCAN setting
circle_dbscan = DBSCAN(eps=epsilon, min_samples=minPts)
# [3] ~ [5] 과정을 반복
circle_dbscan.fit(circle_points)
#[3] ~[5] 과정의 반복으로 클러스터의 수 도출
n_cluster = max(circle_dbscan.labels_)+1
print(f'# of cluster: {n_cluster}')
print(f'DBSCAN Y-hat: {circle_dbscan.labels_}')
# DBSCAN 알고리즘의 수행결과로 도출된 클러스터의 수를 기반으로 색깔별로 구분하여 점에 색칠한 후 도식
for cluster in range(n_cluster):
cluster_sub_points = circle_points[circle_dbscan.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('DBSCAN on circle data')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()
--------------------------------------------------------------------
# of cluster: 2
DBSCAN Y-hat: [0 0 0 0 1 1 1 1 0 0 1 0 1 1 1 1 1 1 1 0 1 0 1 0 0 1 1 0 0 0 1 0 0 1 1 1 1
1 1 0 1 0 1 0 0 0 0 0 0 1 1 0 1 1 0 0 0 0 1 1 0 1 1 0 1 0 0 0 0 0 1 1 1 0
1 0 1 1 1 0 0 1 0 1 1 0 1 1 0 0 0 0 1 1 1 0 0 0 1 0]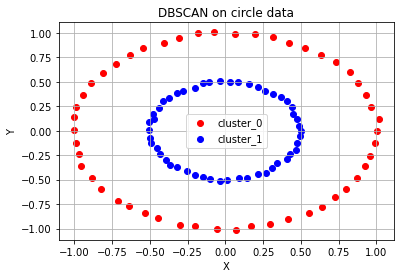
[초승달?]
# 달 모양 분포 데이터 plot
fig = plt.figure()
ax= fig.add_subplot(1, 1, 1)
# n 번째 클러스터 데이터를 어떤 색으로 도식할 지 결정
color_dict = {0: 'red', 1: 'blue', 2: 'green', 3:'brown',4:'purple'}
epsilon, minPts = 0.4, 3
moon_dbscan = DBSCAN(eps=epsilon, min_samples=minPts)
moon_dbscan.fit(moon_points)
n_cluster = max(moon_dbscan.labels_)+1
print(f'# of cluster: {n_cluster}')
print(f'DBSCAN Y-hat: {moon_dbscan.labels_}')
for cluster in range(n_cluster):
cluster_sub_points = moon_points[moon_dbscan.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('DBSCAN on moon data')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()
--------------------------------------------------------------------
# of cluster: 2
DBSCAN Y-hat: [0 1 1 1 1 0 0 0 0 0 0 1 0 0 1 0 0 0 1 1 1 0 0 1 1 1 1 1 0 1 0 1 0 0 0 0 1
1 1 1 1 0 0 1 0 1 1 0 1 1 1 1 0 0 0 0 0 1 1 1 0 0 1 1 1 0 0 1 1 0 1 0 0 1
1 1 0 0 0 1 0 1 1 0 0 0 0 1 0 1 1 0 1 1 0 0 0 0 1 1]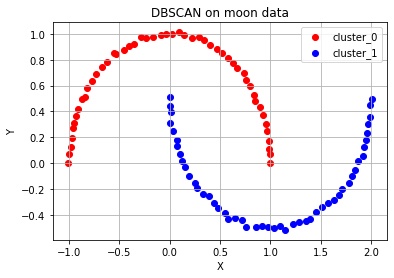
[대각선]
# 대각선 모양 분포 데이터 plot
fig = plt.figure()
ax= fig.add_subplot(1, 1, 1)
# n 번째 클러스터 데이터를 어떤 색으로 도식할 지 결정
color_dict = {0: 'red', 1: 'blue', 2: 'green', 3:'brown',4:'purple'}
epsilon, minPts = 0.7, 3
diag_dbscan = DBSCAN(eps=epsilon, min_samples=minPts)
diag_dbscan.fit(diag_points)
n_cluster = max(diag_dbscan.labels_)+1
print(f'# of cluster: {n_cluster}')
print(f'DBSCAN Y-hat: {diag_dbscan.labels_}')
for cluster in range(n_cluster):
cluster_sub_points = diag_points[diag_dbscan.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('DBSCAN on diagonal shaped data')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()
--------------------------------------------------------------------
# of cluster: 3
DBSCAN Y-hat: [ 0 1 1 0 0 2 2 0 1 2 2 2 0 2 0 1 2 2 2 1 1 1 1 1
2 2 0 1 0 2 1 0 2 1 2 0 0 0 0 0 1 0 1 0 0 2 1 1
0 2 1 1 2 1 0 2 -1 2 0 0 2 0 0 1 0 1 1 2 2 2 -1 0
2 0 0 0 1 2 2 -1 2 2 1 2 0 0 2 1 1 2 1 1 2 0 -1 1
0 0 0 1]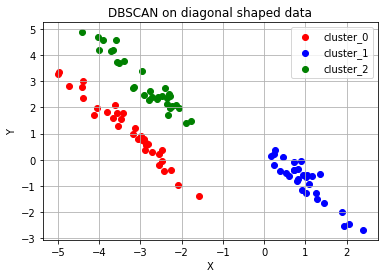
DBSCAN Y-hat 결과가 -1인 경우는 어느 군집에도 포함되지 못한 noise point 이다.
위와 같이 보면 군집화도 훌륭하게 해줄뿐더러 K-means에 비해 사용성도 훨씬 유연하다.
하지만 이 알고리즘에도 단점은 분명 존재한다.
DBSCAN 알고리즘과 K-means 알고리즘의 소요 시간 비교
import time
n_samples= [100, 500, 1000, 2000, 5000, 7500, 10000, 20000, 30000, 40000, 50000]
kmeans_time = []
dbscan_time = []
x = []
for n_sample in n_samples:
# 원형의 분포를 가지는 데이터 생성
dummy_circle, dummy_labels = make_circles(n_samples=n_sample, \
factor=0.5, \
noise=0.01)
# K-means 시간 측정
kmeans_start = time.time()
circle_kmeans = KMeans(n_clusters=2)
circle_kmeans.fit(dummy_circle)
kmeans_end = time.time()
# DBSCAN 시간 측정
dbscan_start = time.time()
epsilon, minPts = 0.2, 3
circle_dbscan = DBSCAN(eps=epsilon, min_samples=minPts)
circle_dbscan.fit(dummy_circle)
dbscan_end = time.time()
x.append(n_sample)
kmeans_time.append(kmeans_end-kmeans_start)
dbscan_time.append(dbscan_end-dbscan_start)
print("# of samples: {} / Elapsed time of K-means: {:.5f}s / DBSCAN: {:.5f}s".format(n_sample, kmeans_end-kmeans_start, dbscan_end-dbscan_start))
# K-means와 DBSCAN의 소요 시간 그래프화
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.scatter(x, kmeans_time, c='red', marker='x', label='K-means elapsed time')
ax.scatter(x, dbscan_time, c='green', label='DBSCAN elapsed time')
ax.set_xlabel('# of samples')
ax.set_ylabel('time(s)')
ax.legend()
ax.grid()
--------------------------------------------------------------------
# of samples: 100 / Elapsed time of K-means: 0.01534s / DBSCAN: 0.00129s
# of samples: 500 / Elapsed time of K-means: 0.02075s / DBSCAN: 0.00385s
# of samples: 1000 / Elapsed time of K-means: 0.02149s / DBSCAN: 0.00621s
# of samples: 2000 / Elapsed time of K-means: 0.01923s / DBSCAN: 0.01484s
# of samples: 5000 / Elapsed time of K-means: 0.42578s / DBSCAN: 0.07746s
# of samples: 7500 / Elapsed time of K-means: 0.69820s / DBSCAN: 0.08836s
# of samples: 10000 / Elapsed time of K-means: 0.62464s / DBSCAN: 0.16907s
# of samples: 20000 / Elapsed time of K-means: 0.59837s / DBSCAN: 0.47543s
# of samples: 30000 / Elapsed time of K-means: 0.66303s / DBSCAN: 0.83965s
# of samples: 40000 / Elapsed time of K-means: 0.64089s / DBSCAN: 1.44829s
# of samples: 50000 / Elapsed time of K-means: 0.80281s / DBSCAN: 2.19107s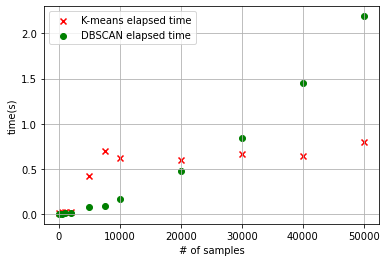
데이터의 수가 적을 때는 K-means 알고리즘의 수행 시간이 DBSCAN에 비해 더 길었으나, 군집화할 데이터의 수가 많아질수록 DBSCAN의 알고리즘 수행 시간이 급격하게 늘어나게 된다.
차원 축소
PCA
비지도학습의 대표적인 방법 중 하나로 주성분분석(PCA)이라는 차원 축소(Dimensionality reduction) 알고리즘이 있다.
PCA에 대해 알기전에 수학적인 용어를 몇개 알아야한다.
- PCA는 데이터 분포의 주성분을 찾아주는 방법이다. 여기서 주성분이라는 의미는 데이터의 분산이 가장 큰 방향벡터를 의미해요.
- PCA는 데이터들의 분산을 최대로 보존하면서, 서로 직교(orthogonal)하는 기저(basis, 분산이 큰 방향벡터의 축)들을 찾아 고차원 공간을 저차원 공간으로 사영(projection)한다.
- 또한 PCA에서는 기존 feature 중 중요한 것을 선택하는 방식이 아닌,
기존의 feature를 선형 결합(linear combination)하는 방식을 사용하고 있다.
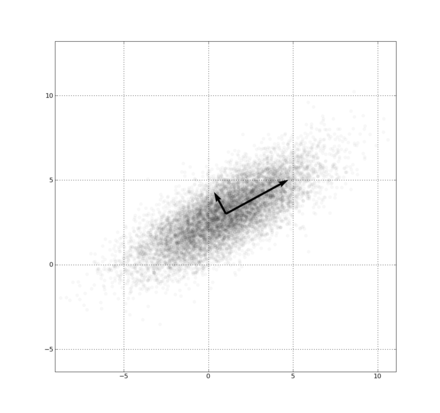
출처 : 위키피디아
위 그림과 같이 타원형 분포로 되어있는 데이터들이 있을 때, 차원의 수는 줄이면서 데이터 분포의 분산을 최대한 유지하기 위해 가장 분산이 긴 축을 첫 기저로 잡고, 그 기저에 직교하는 축 중 가장 분산이 큰 값을 다음 기저로 잡는다.
이 과정을 반복하게 되면 차원의 수를 최대로 줄이면서 데이터 분포의 분산을 그대로 유지할 수 있으며, 이것을 차원 축소라고 한다. 즉, 여러 개의 차원으로 구성된 데이터들을 2개의 차원으로 축소해도 정보의 손실을 최소화하여 데이터의 분포를 충분히 표현할 수 있다는 뜻이다.
차원 축소의 핵심 개념으로 사영(projection)이라는 용어가 등장한다.
ratsgo's님의 블로그 - 사영
X-Y-Z 좌표축상에 존재하는 데이터를 X-Y, Y-Z 좌표축에 사영(projection) 했다는 것은 각각 Z, X 좌표축을 무시했다는 뜻이 된다.
PCA는 차원축소 시 주어진 좌표축 방향이 아니라, 가장 분산이 길게 나오는 기저(basis) 방향을 찾아서 그 방향의 기저만 남기고, 덜 중요한 기저 방향을 삭제하는 방식으로 진행된다. 이렇게 찾은 가장 중요한 기저를 주성분(Principal Component) 방향, 또는 pc축이라 한다.
# 예제: 유방암 데이터셋
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer=load_breast_cancer()
# y=0(Malignant:악성 종양), y=1(Benign:양성 종양)
cancer_X, cancer_y= cancer.data, cancer['target']
train_X, test_X, train_y, test_y = train_test_split(cancer_X, cancer_y, test_size=0.1, random_state=10)
print("전체 검사자 수: {}".format(len(cancer_X)))
print("Train 에 사용되는 검사자 수: {}".format(len(train_X)))
print("Test 에 사용되는 검사자 수: {}".format(len(test_X)))
cancer_df = pd.DataFrame(cancer_X, columns=cancer['feature_names'])
cancer_df.head()
--------------------------------------------------------------------
전체 검사자 수: 569
Train dataset에 사용되는 검사자 수: 512
Test dataset에 사용되는 검사자 수: 57
mean radius mean texture mean perimeter mean area mean smoothness mean compactness mean concavity mean concave points mean symmetry mean fractal dimension radius error texture error perimeter error area error smoothness error compactness error concavity error concave points error symmetry error fractal dimension error worst radius worst texture worst perimeter worst area worst smoothness worst compactness worst concavity worst concave points worst symmetry worst fractal dimension
0 17.99 10.38 122.80 1001.0 0.11840 0.27760 0.3001 0.14710 0.2419 0.07871 1.0950 0.9053 8.589 153.40 0.006399 0.04904 0.05373 0.01587 0.03003 0.006193 25.38 17.33 184.60 2019.0 0.1622 0.6656 0.7119 0.2654 0.4601 0.11890
1 20.57 17.77 132.90 1326.0 0.08474 0.07864 0.0869 0.07017 0.1812 0.05667 0.5435 0.7339 3.398 74.08 0.005225 0.01308 0.01860 0.01340 0.01389 0.003532 24.99 23.41 158.80 1956.0 0.1238 0.1866 0.2416 0.1860 0.2750 0.08902
2 19.69 21.25 130.00 1203.0 0.10960 0.15990 0.1974 0.12790 0.2069 0.05999 0.7456 0.7869 4.585 94.03 0.006150 0.04006 0.03832 0.02058 0.02250 0.004571 23.57 25.53 152.50 1709.0 0.1444 0.4245 0.4504 0.2430 0.3613 0.08758
3 11.42 20.38 77.58 386.1 0.14250 0.28390 0.2414 0.10520 0.2597 0.09744 0.4956 1.1560 3.445 27.23 0.009110 0.07458 0.05661 0.01867 0.05963 0.009208 14.91 26.50 98.87 567.7 0.2098 0.8663 0.6869 0.2575 0.6638 0.17300
4 20.29 14.34 135.10 1297.0 0.10030 0.13280 0.1980 0.10430 0.1809 0.05883 0.7572 0.7813 5.438 94.44 0.011490 0.02461 0.05688 0.01885 0.01756 0.005115 22.54 16.67 152.20 1575.0 0.1374 0.2050 0.4000 0.1625 0.2364 0.07678(아... 결과가 너무 밀렸다....ㅎ...)
유방암 데이터셋에 PCA 알고리즘 적용 예제
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn import svm
from sklearn.metrics import accuracy_score
from collections import Counter
color_dict = {0: 'red', 1: 'blue', 2:'red', 3:'blue'}
target_dict = {0: 'malignant_train', 1: 'benign_train', 2: 'malignant_test', 3:'benign_test'}
#Train data에 PCA 알고리즘 적용
# 불러온 데이터에 대한 정규화 -> 각 column의 range of value가 전부 다르기 때문에 정규화를 진행해 주어야 합니다.
train_X_ = StandardScaler().fit_transform(train_X)
train_df = pd.DataFrame(train_X_, columns=cancer['feature_names'])
# 주성분의 수를 2개, 즉 기저가 되는 방향벡터를 2개로 하는 PCA 알고리즘 수행
pca = PCA(n_components=2)
pc = pca.fit_transform(train_df)StandScaler().fit_transform() 과정을 수행하는 이유는 각 열마다의 값의 범위가 전부 다르기 때문에 같은 범위로 맞춰주기 위해서다.
Test data에도 PCA 알고리즘을 적용한다. train과 똑같이 StandScaler().fit_transform() 과정을 수행해서 정규화를 해준다.
test_X_ = StandardScaler().fit_transform(test_X)
test_df = pd.DataFrame(test_X_, columns=cancer['feature_names'])
pca_test = PCA(n_components=2)
pc_test = pca_test.fit_transform(test_df)여기서는 SVM classifier을 써서 훈련시켜준다.
# 훈련한 classifier의 decision boundary를 그리는 함수
def plot_decision_boundary(X, clf, ax):
h = .02 # step size in the mesh
# create a mesh to plot in
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contour(xx, yy, Z, cmap='Blues')
# PCA를 적용한 train data의 classifier 훈련
# classfier로 Support Vector Machine(SVM) 사용
clf = svm.SVC(kernel = 'rbf', gamma=0.5, C=0.8) # 여기서는 classifier로 SVM을 사용한다는 정도만 알아둡시다!
clf.fit(pc, train_y) # train data로 classifier 훈련
# PCA를 적용하지 않은 original data의 SVM 훈련
clf_orig = svm.SVC(kernel = 'rbf', gamma=0.5, C=0.8)
clf_orig.fit(train_df, train_y)# 캔버스 도식
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# malignant와 benign의 SVM decision boundary 그리기
plot_decision_boundary(pc, clf, ax)
#Train data 도식
for cluster in range(2):
sub_cancer_points = pc[train_y == cluster]
ax.scatter(sub_cancer_points[:, 0], sub_cancer_points[:, 1], edgecolor=color_dict[cluster], c='none', label=target_dict[cluster])
#Test data 도식
for cluster in range(2):
sub_cancer_points = pc_test[test_y == cluster]
ax.scatter(sub_cancer_points[:, 0], sub_cancer_points[:, 1], marker= 'x', c=color_dict[cluster+2], label=target_dict[cluster+2])
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_title('PCA-Breast cancer dataset')
ax.legend()
ax.grid()
# Scoring
pca_test_accuracy_dict = Counter(clf.predict(pc_test) == test_y)
orig_test_accuracy_dict = Counter(clf_orig.predict(test_df) == test_y)
print("PCA 분석을 사용한 Test dataset accuracy: {}명/{}명 => {:.3f}".format(pca_test_accuracy_dict[True], sum(pca_test_accuracy_dict.values()), clf.score(pc_test, test_y)))
print("PCA를 적용하지 않은 Test dataset accuracy: {}명/{}명 => {:.3f}".format(orig_test_accuracy_dict[True], sum(orig_test_accuracy_dict.values()), clf_orig.score(test_df, test_y)))
--------------------------------------------------------------------
PCA 분석을 사용한 Test dataset accuracy: 54명/57명 => 0.947
PCA를 적용하지 않은 Test dataset accuracy: 43명/57명 => 0.754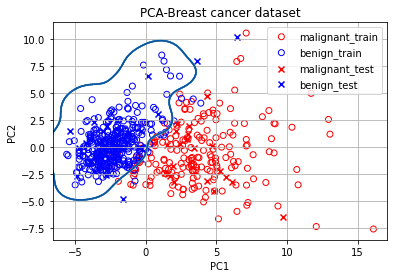
모든 feature를 이용한 방식의 정확도가 더 낮은 이유는 제공된 30개의 feature 중 종양의 악성/양성과 관련 없는 것이 존재해서 해당 feature가 오히려 분류를 방해했기 때문이며, 2개의 주성분 feature 만으로 분류한 PCA classifier의 정확도가 30개의 feature를 모두 사용한 original classifier보다 훨씬 높은 분류 정확도를 보여준다.
즉, feature의 수가 적더라도 악성/양성과 관련이 깊은 중요한 feature만을 이용한 분류의 정확도가 훨씬 더 높을 수 있다는 뜻이다.
T-SNE
이번에는 시각화에 많이 쓰이는 T-SNE(T-Stochastic Neighbor Embedding)알고리즘을 알아보자. 기존 차원의 공간에서 가까운 점들은, 차원축소된 공간에서도 여전히 가깝게 유지되는 것을 목표로 하는 알고리즘이다.
scikit-learn T-SNE
사이킷런(scikit-learn)에서 MNIST 데이터 불러오기
sklearn.datasets의 fetch_openml 함수를 사용하여 MNIST 데이터를 가져오자.
from sklearn.datasets import fetch_openml
# 784 pixel로 이뤄진 mnist 이미지 데이터 호출
mnist = fetch_openml("mnist_784",version=1)
X = mnist.data / 255.0
y = mnist.target
print("X shape: ",X.shape)
print("Y shape: ",y.shape)
-----------------------------------------------------------------
X shape: (70000, 784)
Y shape: (70000,)n_image = X.shape[0]
n_image_pixel = X.shape[1]
# 픽셀정보가 있는 칼럼의 이름을 담은 목록
pixel_columns = [ f"pixel{i}" for i in range(1, n_image_pixel + 1) ]
len(pixel_columns)
# pixel_columns[:20]
-----------------------------------------------------------------
784pandas를 이용하여 데이터를 살펴보자.
import pandas as pd
df = pd.DataFrame(X,columns=pixel_columns)
df['y'] = y
# 숫자 라벨을 스트링으로 만드는 함수를 파이썬 람다 문법으로 전체 데이터에 적용
df['label'] = df['y'].apply(lambda i: str(i))
X, y = None, None
df.head()
-----------------------------------------------------------------
pixel1 pixel2 pixel3 pixel4 pixel5 pixel6 pixel7 pixel8 pixel9 pixel10 ... pixel777 pixel778 pixel779 pixel780 pixel781 pixel782 pixel783 pixel784 y label
0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 5 5
1 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0
2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 4 4
3 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1 1
4 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 9 97만 개의 이미지 데이터 중 1만 개를 랜덤샘플링해보자.
import numpy as np
# 결과가 재생산 가능하도록 랜덤 시드를 지정
np.random.seed(30)
# 이미지 데이터의 순서를 랜덤으로 뒤바꾼(permutation) 배열을 저장
rndperm = np.random.permutation(n_image)
# 랜덤으로 섞은 이미지 중 10,000개를 뽑고, df_subset에 저장
n_image_sample = 10000
random_idx = rndperm[:n_image_sample]
df_subset = df.loc[rndperm[:n_image_sample],:].copy()
df_subset.shape
-----------------------------------------------------------------
(10000, 786)matplotlib를 이용해서 시각화해보자.
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
plt.gray()
fig = plt.figure( figsize=(10,6) )
n_img_sample = 15
width,height = 28,28
# 15개 샘플을 시각화
for i in range(0,n_img_sample):
row = df_subset.iloc[i]
ax = fig.add_subplot(3,5,i+1, title=f"Digit: {row['label']}")
ax.matshow(row[pixel_columns]
.values.reshape((width,height))
.astype(float))
plt.show()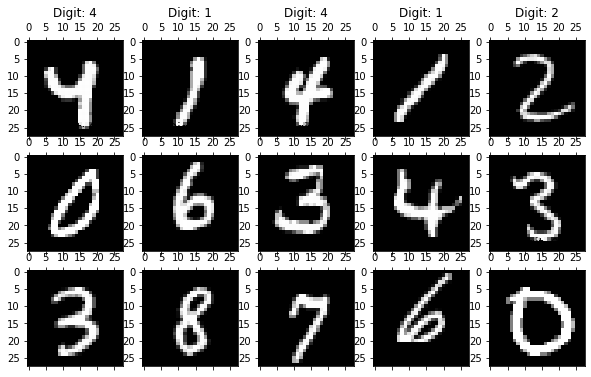
그럼 이제 PCA와 T-SNE를 비교해보자.
- T-SNE는 기존 차원의 공간에서 가까운 점들은, 차원축소된 공간에서도 여전히 가깝게 유지되는 것을 목표이다.
PCA와 구분되는 T-SNE의 뚜렷한 특징이다.
- T-SNE의 두 차원은 물리적 의미를 가지지 않는다. T-SNE는 정보 손실량에 주목하지 않으며, 그 결과 저차원 축이 아무런 물리적 의미를 가지지 못하며, 오직 시각화에만 유리할 뿐입니다.
- PCA는 정보 손실을 최소화하려는 관점을 가지고 있으므로, 그 결과 추출된 PC축은 주성분이라는 물리적 의미를 유지하고 있으며, 공분산을 통해 원본 데이터를 일정 부분 복원할 수 있는 가능성이 있다.
정리
| K-means | DBSCAN | PCA | T-SNE | |
|---|---|---|---|---|
| 장점 | 군집의 수(K)가 주어졌을 때 빠른 시간에 유클리드 거리 기반으로 군집화를 수행. | 밀도기반의 군집화 알고리즘으로 outlier에 강하다. | 데이터 분포의 분산을 최대한 유지한 채로 feature의 차원을 줄이는 차원 축소 알고리즘 | 차원축소 전후의 데이터의 상대적 거리를 유지하므로 시각화 결과가 가장 좋다. |
| 알고리즘이 단순하며 이해하기 쉬움 | K-means와는 달리 초기 중심점 및 군집의 수인 K값을 설정할 필요가 없다. | 상관관계가 적은 feature를 최대한 배제하고 분산이 최대가 되는 서로 직교(orthogonal)하는 기저(basis)들을 기준으로 데이터들을 나타내기 때문에 raw data를 사용하는 것보다 정확하고 간결하게 데이터를 표현할 수 있다. | ||
| feature수가 줄어들어 연삭속도가 빨라진다. | ||||
| 단점 | 초기 중심점이 어떻게 주어지느냐에 따라 결과값이 달라진다. | 데이터수가 많아 질수록 Kmeans알고리즘에 비해 오랜시간이 소여된다. | PCA는 단순히 변환된 축이 최대 분산 방향과 정렬되도록 좌표회전을 수행하는 것이 때문에 최대분산방향이 feature의 구분을 좋게 한다는 보장이 없다. | 차원축소 과정에서 좌표축의 물리적 의미를 무시하므로 시각화 이외의 다른 용도로는 사용하기가 어렵다 |
| 전체 거리 평균값에 영향을 주어 outlier에 민감하다 | 군집의 수는 미리 알려줄 필요가 없지만, epsilon 및 minPts등 초기에 설정해 줘야하는 변수가 존재한다 |
