
우리는 "선착순" 이란 키워드를 일상 생활에서 많이 볼 수 있다.
은행에서 번호표를 뽑는다던지, 공연이나 기차표 티켓팅을 위한 대기열을 기다리는 등 선착순으로 작업이 진행되도록 의도하는 자료구조를 Queue라고 한다.
큐(Queue)는 선입선출(FIFO) 순서로 데이터를 저장하는 자료구조이다.
데이터를 추가하는 enqueue와 데이터를 추출하는 dequeue모두 O(1) 의 낮은 비용으로 연산이 가능하며, CPU의 프로세스 스케줄링, 윕서버의 요청 처리, 너비우선탐색(BFS) 등에 주로 사용된다.
Queue의 특징
1. 선입선출(FIFO)
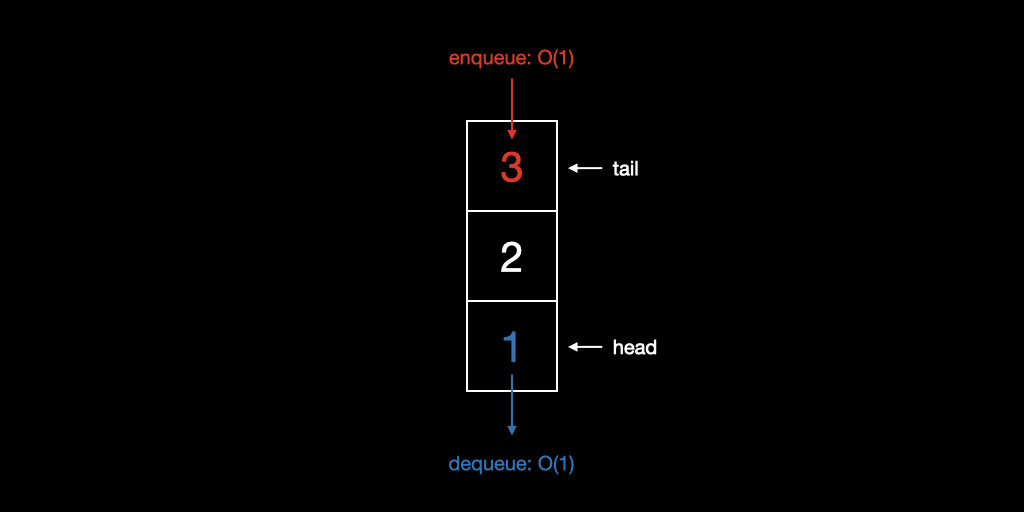
큐는 시간 순서상 먼저 들어간 데이터가 먼저 나오는 선입선출 FIFO(First In First Out) 형식으로 데이터를 저장한다.
- Front: 첫 번째 요소가 저장되어있는 위치
- Rear: 마지막 요소가 저장되어있는 위치
Linked List의 Head/Tail과 유사하게 큐는 Front/Rear의 포인터를 관리해 enqueue, dequeue의 효율성을 개선했다.
2. enqueue & dequeue
데이터를 추가하는 것을 enqueue라고 하며, 반대로 데이터를 추출하는 것을 dequeue라고 한다. 배열에서 사용되는 삽입(insert), 삭제(delete)와는 의미가 좀 다르다.
큐는 선입선출 구조이기 때문에 맨 뒤에 데이터를 추가하는 enqueue와 맨 앞의 데이터를 추출하는 dequeue가 가능하며, 두 연산 모두 O(1) 비용이 소요된다.
큐의 크기에 따라 불리는 상태명이 다른데 아래와 같다.
- Overflow: 큐가 가득 차 더이상 데이터를 넣을 수 없는 상태
- Underflow: 큐가 비어있어 더이상 꺼낼 데이터가 없는 상태
Queue의 구현 방식
Array-based
enqueue와 dequeue 과정에서 배열에 사용되지 않는 메모리 공간이 생긴다. 메모리의 낭비를 줄이기 위해서 주로 원형 큐 만들 때 Array-based로 구현한다.
Array를 기반하기 때문에 고정된 크기의 한계가 동반하게 되는데 큐의 resizing을 고려하면 enqueue는 Amortized O(1) 의 비용이, dequeue는 O(1) 비용이 소요된다.
List-based
Linked List를 사용해서 큐를 만들었기 때문에 불필요한 메모리 낭비가 없다. 시간복잡도 역시 enqueue와 dequeue 모두 O(1) 의 비용이 소요된다.
Queue의 종류 및 유형
선형 큐(Linear Queue)
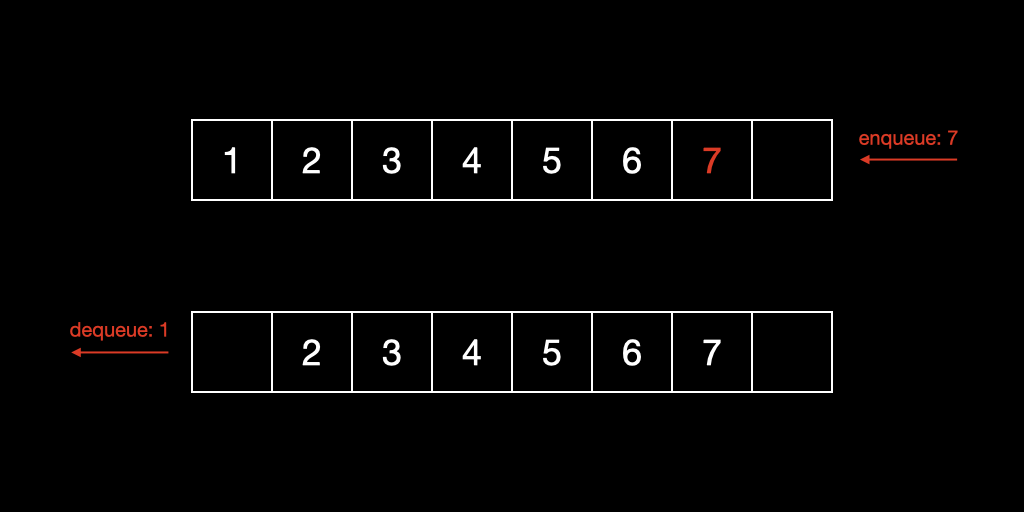
가장 기본적 형태의 Array-based 큐이다. Enqueue 연산을 통해서 배열의 가장 뒤에 데이터를 추가하고, Dequeue 연산을 통해서 배열의 가장 앞의 데이터를 추출한다. 고정된 크기인 배열의 특징상 enqueue를 위한 여유 공간을 고려해 배열을 생성해야 하며, 반복적인 dequeue로 배열 앞부분이 빈 공간이 되어 메모리 낭비가 발생한다.
원형 큐(Circular Queue)
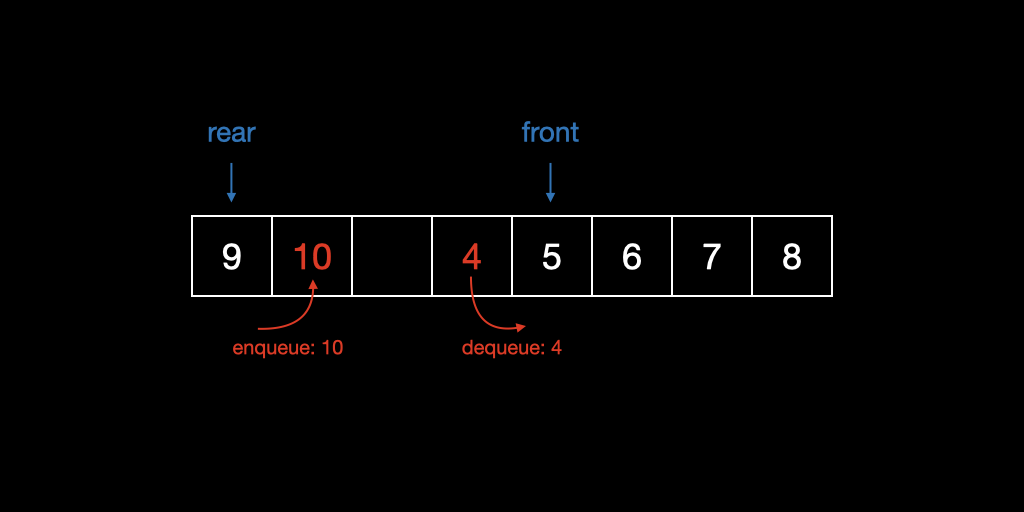
선형 큐에서 메모리 효율을 개선한 큐라고 할 수 있다. Front 인덱스와 Rear 인덱스를 저장해서 고정된 용량(capacity)의 배열에서 크기(size)를 효율적으로 관리한다. 하지만 선형 큐와 마찬가지로 할당된 용량을 초과하는 enqueue가 발생하면 resizing이 발생하기 때문에 enqueue에 Amortized O(1) 의 비용이 소요된다.
우선순위 큐(Priority Queue)
우선순위 큐는 데이터가 들어온 시간 순서가 아닌 데이터의 우선순위에 따라 정렬한다는 점에서 좀 다른 유형의 큐이다. Enqueue시 데이터가 rear에 저장되는것이 아닌 정의된 순위에 따라 저장되게 되며, 마찬가지로 dequeue시 front가 아닌 정의된 순위에 따라 추출된다. 따라서 enqueue, dequeue 연산시 더 높은 비용이 들지만 완전 이진 트리(Complete Binary Tree) 구조로 구현하면 O(logN) 의 비용으로 연산이 가능하다.
덱(Dequeue)
Dequeue(Double-ended queue)는 이름에서도 알 수 있듯이 Front/Rear 양 쪽에서 enqueue와 dequeue가 가능하다. 따라서 queue의 대표적인 특징인 FIFO가 성립하지 않을 수도 있다.
요약
| Operation | Worst Case |
|---|---|
| enqueue | O(1) |
| dequeue | O(1) |
| peek | O(1) |
장점
- 빠른 연산: 크기에 상관 없이 모든 연산에서 O(1) 의 비용이 소요된다.
단점
- 딱히 없음
Reference
