1. Model
-1. Model이란
- 핵심 특성을 담은 모형을 통해 실체를 설명하기 위한 것
-2. DataModel
- 어떤 데이터에 대한 개념적, 형식적 표현
- tabel형태로 이루어져 있음
- key를 이용하여 reference
- 구조(structure) + 연산(operation) + 제약 조건(constraint)
-> model설명 O
-3, 구조, 연산, 제약 조건
-
- 구조(structure)
- tabel형태의 schema + instance
- 현실 세계 -> 개념 세계로 추상화했을 때 어떤 요소로 이루어져 있는지를 표현한 구조
- 데이터를 어떤 모습으로 저장할 것인지 표현
- 구조에 따라 연산, 제약 조건이 변함
-
- 연산(operation)
- 구조를 운용하기 위한 연산
- instance에 부여, 적용 ( not schema)
- DB로부터 데이터를 추출, 삽입, 갱신하기 위한 연산
- ex) insert select delete update -> relational data model의 연산
-
- 제약 조건(constraint)
- DB가 지켜야 하는 제약조건
- key로만 상대방의 data 를 access/reference 할 수 있음
- schema는 구조, 제약 조건 / instance는 연산
-4. Conceptual Data Models
- Conceptual Data Model을 통해 Database Schema표현
- 상위적인 data 설명 model
- 데이터를 높은 수준이나 의미적 수준으로 표현하는 데이터 모델
- ex) '학생' data 표현 -> '학생' tabel의 구성 요소인 '나이' , '주소' 등을 정함
= schema의 이름에 따라 attributes를 정함
-5. Physical Data Models
- 데이터를 낮은 수준이나 물리적 수준으로 표현하는 데이터 모델
- 데이터가 디스크에 저장될 때 저장/구현 수준에서의 실질적인 데이터 모델
- ex) '학생' data에서 '나이' -> 4bytes정수, 여기서 B-Tree Index구축 -> 나중에 해당 Index를 reference해서 빠르게 찾을 수 있게함
2. 스키마와 인스턴스
-1. Schema
- DB는 schema에 따라 data를 저장함
- schema 덕분에 DB의 구조(structure)와 bytes수 도 정해짐 (+ 구조 정해졌으니까 -> 연산, 제약 조건도 정해짐)
- schema를 통해 records에서 원하는 data를 핀셋으로 뽑아올 수 있음
= 원하는 data로 계산을 통해 원하는 번지로 jump
- schema는 여러 개의 tabels로 이루어져 있음
- 각 tabels는 attributes를 가지고 있으며
- attributes는 instance(record)를 가지고 있음
-2. Schema(= intention) vs Instance(=extension)
1. DataBase Schema
- 데이터베이스에 대한 설명서
- 데이터베이스 모델 설명한 결과물 -> 데이터베이스 구조, 제약 조건 포함
- 데이터베이스 카탈로그에 존재
- Schema Diagram -> DB Schema 의 tabels 구성하는 attributes를 그림으로 표현한 데이터 설계 도면
- Schema Construct : 스키마의 구성 요소 or 스키마 안의 객체들
2. Instance
- Database State
- 실제 데이터
- DB에서 collection of all data, individual database component
- = occurrence = snapshot
3. Schema vs Instance
- Schema
- 상태 자주 변화x
- 구조 포함 -> intention
- catalog , type , rule , structure , intention, a sequence of attributes
- Instance
- DB갱신될 때마다 변화 ( state가 변화 )
- extension
- 실체
- record , state , snapshot , extension , a sequence of values
4. 예시
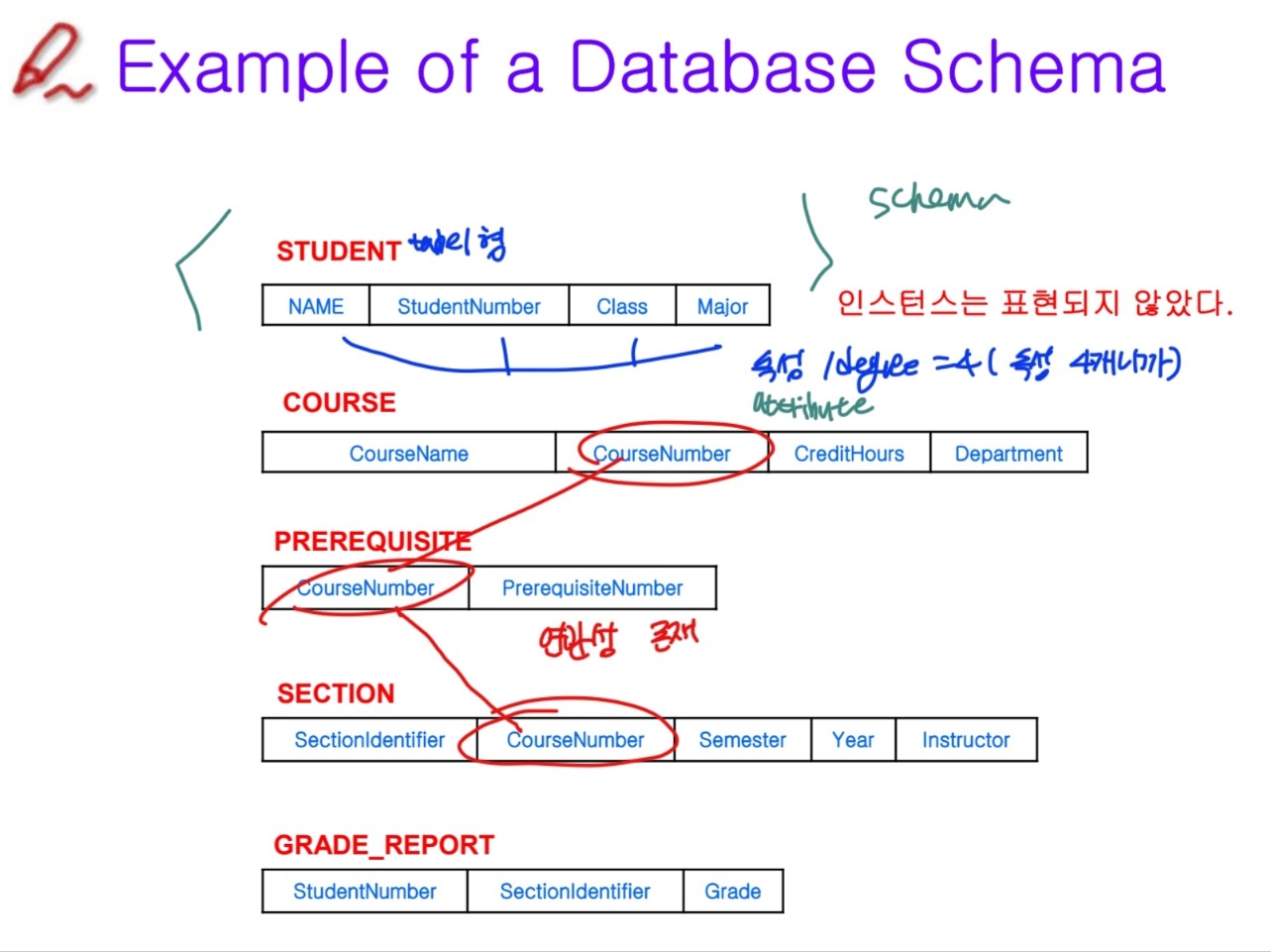
3. DB설계
-1. 데이터베이스 관리 시스템을 이용한 DB접근
- 모든 record -> 동일한 type
- 원하는 record 확인하는 방법?
- 주민번호 | 학번 | 이름 | 주소
-> record안에서 원하는 번지로 jump(key사용)
=> 이것이 가능한 이유: 디스크 카탈로그 덕분
-2. DBMS
- 응용 프로그램 <--> 데이터베이스 관리 시스템 <-->데이터베이스
=> 이런 형식으로 접근하도록 설계
4. 3단계 데이터베이스 구조
- 데이터 독립성(Program-data independence)을 제공하기 위해
- 데이터에 multiple view를 제공하기 위해
=> Three - Schema Architecture가 만들어짐
- 3단계 구조로 나누고 단계별로 스키마를 유지하며 스키마 사이의 mapping을 정의하는 궁극적인 목족 => 데이터 독립성을 실현하기 위함
- 데이터 독립성: 하위 스키마 변경하더라도 상위 스키마가 영향을 받지 않는 특성
-1. 구조
- DBMS schema를 3level로 구분하여 정의
1.External schemas(제일 바깥)
- 다양한 사용자들의 관점(view)에서 DB를 이해, 표현
=> 사용자마다 DB의 구조가 다름
- 권한에 따라 data를 볼 수 있음
- 1개의 DB에는 external schema가 여러 개 존재도 o, 사용자들끼리 공유도 o
2. Conceptual schema
- 전체 데이터베이스에 대한 데이터의 구조 + 해당 데이터에 부여되는 제약 조건 기술하는 스키마
- 현재까지 우리가 배웠던 스키마임
- 시스템이나 관리자의 관점에서 모든 사용자에게 필요한 데이터 통합
-> 전체 데이터베이스의 논리적 구조 정의
- 1 DB 1 Conceptual schema
3. Internal schema
- Physical data model을 표현
- Data storage의 관점에서 이해,표현
-> 전체 DB가 실제로 저장 장치에 저장되는 방법 정의
= low-level schema
- user에게 record를 전달하려면?
: 상위 level view가 Conceptual schema로 옴 -> Internal schema에 mapping -> 하드디스크의 위치/구조 매칭 -> 핀셋으로 data집어서 유저에게 record 전달
-> external schema(=user/사용자)가 해당 정보 볼 수 o
-2. mapping
mapping 이란
- external schema(고수준)참조하는 프로그램이
-> internal schema(저수준)를 참조하는 프로그램으로 변경되는 것
mapping의 용도
- user가 보는 view를 기반으로 한 질의 -> computer가 보는 view의 관점으로 변환 => 각 level간에 mapping = query변환 필요함
- 프로그램들이 external schema참조할 때 필요함
- DBMS가 internal schema에 map하기 위해 필요함
5. 데이터 독립성
-1. mapping
mapping 이란
- external schema(고수준)참조하는 프로그램이
-> internal schema(저수준)를 참조하는 프로그램으로 변경되는 것
mapping의 용도
- user가 보는 view를 기반으로 한 질의 -> computer가 보는 view의 관점으로 변환 => 각 level간에 mapping = query변환 필요함
- 프로그램들이 external schema참조할 때 필요함
- DBMS가 internal schema에 map하기 위해 필요함
- 하위 레벨로부터 독립하기 위해 상위 레벨 직접 안바꾸고 mapping만 바꿈
-> 독립성
-2. 데이터 독립성
- 1개의 DB -> 3가지 유형의 스키마 -> 이 스키마들은 모두 같은 DB를 표현
-> 실제 data는 물리적 저장 장치에 저장된 DB에만 존재 -> user가 자신의 external schema를 통해 원하는 data얻으려면 internal schema에 따라 저장된 DB에 접근해야 함 -> 3가지 level 의 schema 사이에 유기적인 대응 관계 (=mapping)가 성립해야 함
- 이렇게 DB를 3가지 구조로 나누고 단계별로 schema를 유지하며 스키마 사이에 mapping정의하는 궁극적인 목적 =>데이터 독립성
- 데이터 독립성이란 하위 스키마를 변경하더라도 상위 스키마가 영향을 받지 않는 것 -> 스키마를 바꾸는 것이 아니라 mapping만을 변경
-> 응용 프로그램들은 external schema(상위 스키마) 참조만 함( 변경 x )
- 가능한 상위 레벨의 program은 바꾸지 않음
논리적 데이터 독립성
- external schema나 이용하는 응용 프로그램 바꾸지 않고도 conceptual schema가 변경될 수 있도록 DBMS가 지원하는 특성
- 하위 스키마에 새로운 내용 추가/변경 되어도 상위 스키마는 영향받지 x
물리적 데이터 독립성
- conceptual schema를 바꾸지 않고도 internal schema(디스크 내 record위치 정보 등)만 변경해도 되도록 지원하는 특성
6.DBMS 언어
-1. DDL
- schema정의 언어
- 관리자와 database designer들이 conceptual schema 표현하기 위해 DDL 사용
- DDL -> internal schema(tables, index 등 conceptual schema)
-> external schemas(사용자 views) 정의하기 위해 사용
-2. DML
- instance 정의 언어
- Data Manipulation Language -> 이때 query = SQL
- 고급 언어 내재 방식 -> ESQL
- 프로그램 안 -> 범용 프로그래밍 언어 안 -> query넣음
- 언어 실행 -> SQL만남 -> DB로 감 -> 커서/data가져옴
-> query끝 + loop 계속 돔
- 참고) 범용 프로그래밍 언어: C, C++, C#, JAVA, Phython 등
- 문답식 방식
- DBMS가 제공하는 질의 창을 통해 query를 직접 작성하여 질의
