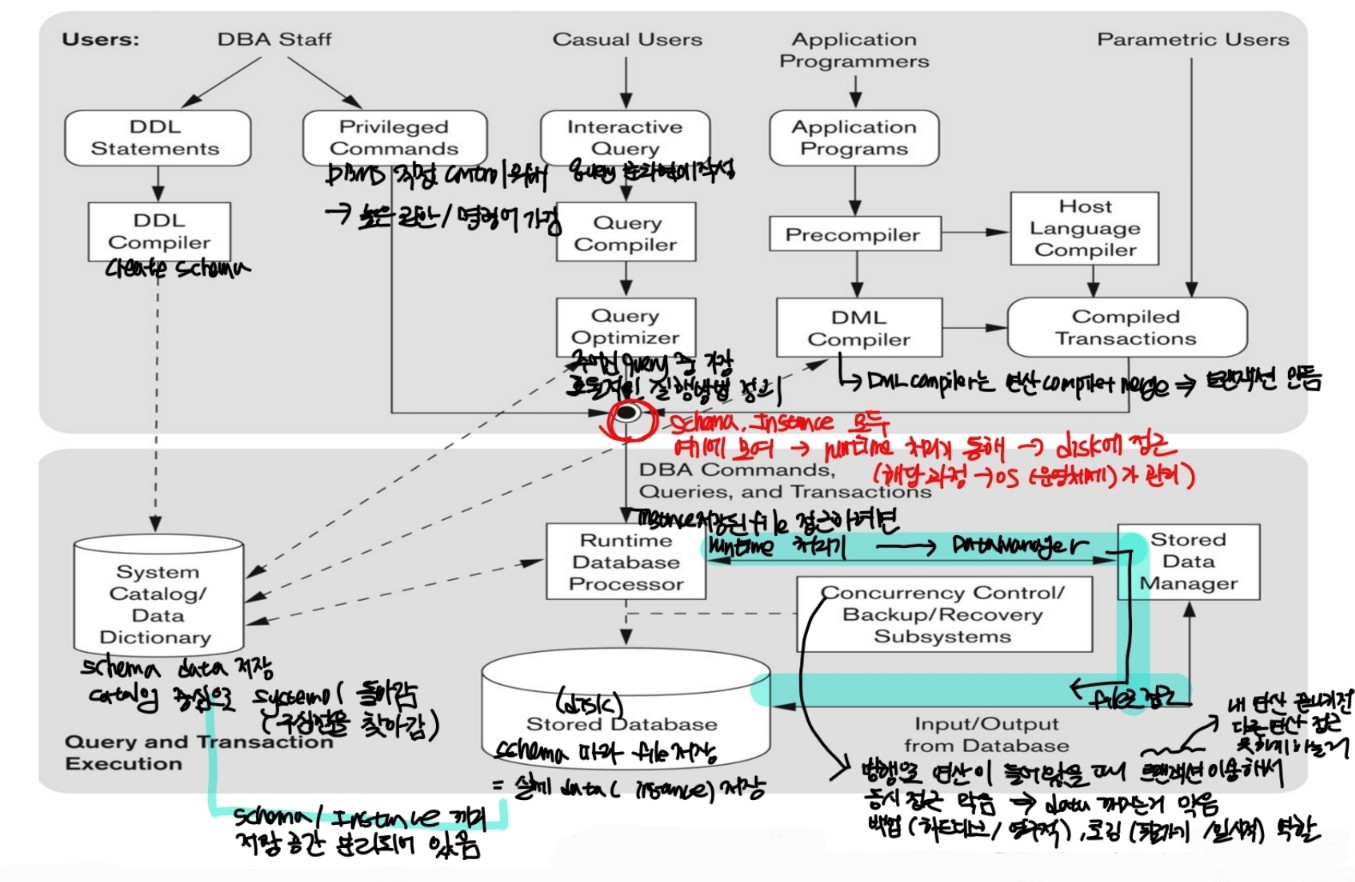
1. DBMS Component Modules
-1. 데이터베이스 관리 시스템 구성도
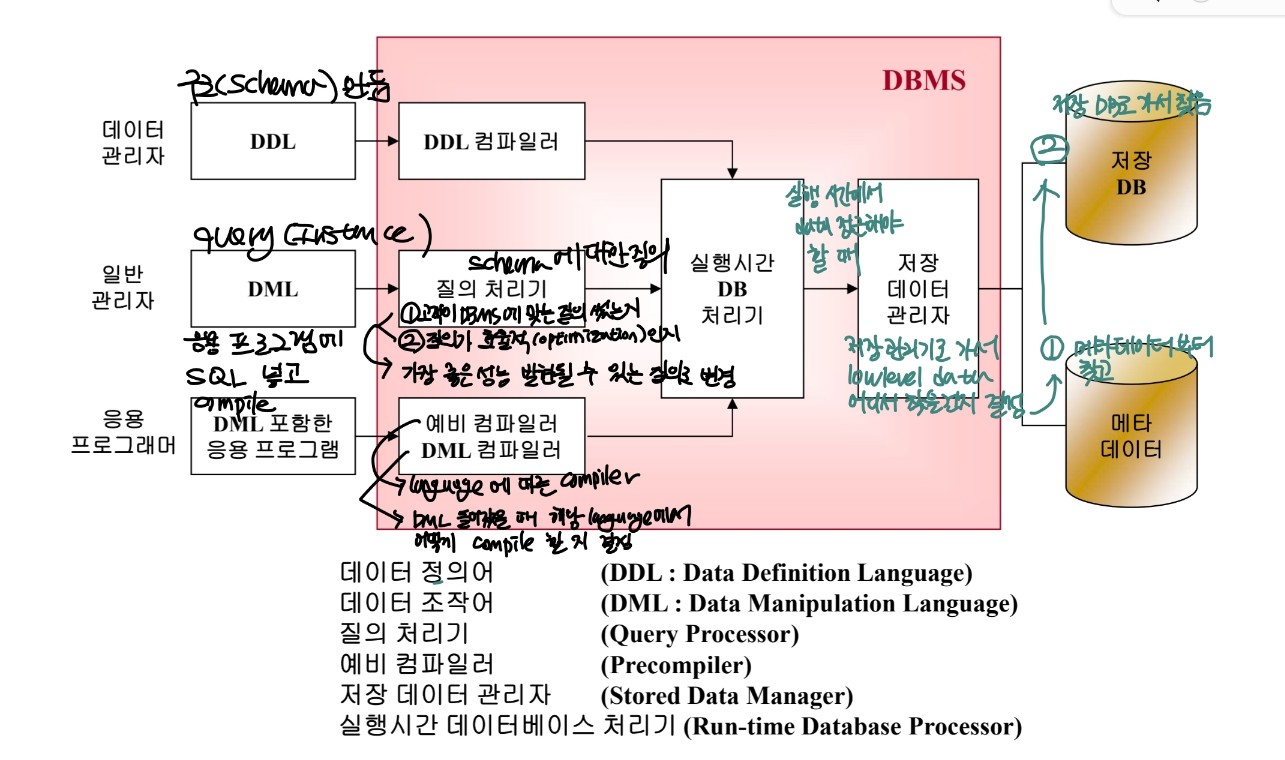
-2. Typical DBMS Component Modules
-
구성도
-
고객이 query통해 정보를 질의 -> 해당 정보의 attributes포함한 instances 전체 return
=> 이유? : select한거 이외에 나머지 정보들도 모두 이용하여
table들 끼리 join하기 위함 -> 연관된 table로 계속 확대해서 수많은 attributes를 활용하기 위함
=> join optimize하는 것이 중요함 -> 마음속에서 join의 cost를 예측할 줄 알아야 함
2. DBMS Architectures
-1. Centralized and Client-Server DBMS Architectures
- DB가 중앙에 1개 있는 것
- access 하는 방법: IP 알려주면 -> DB접근 O
- user가 terminals(PC,태블릿 등등) 로 접근 -> 중앙 서버에서 연산(수행)
-2. 2-tier Client-Server Architectures
- Client <-> Server 끼리 정보를 주고받음/ 둘 다 연산 o
- 중앙 DB에 핵심 서버가 있음에도 Client - Server 2-tier 구조 유지하는 이유?
=> client측 에서도 어떤 data를 가지고 있는 것을 원하기 때문
= server 에서 data를 가지고 와서 client에서 keeping하려는 목적 - web server 설치하고 -> DBMS server 설치해야 함
-> 그래야 web로 DBMS 접근할 수 있음 - 여러 개의 server -> 여러 개의 client -> 여러 개의 DBMS
- files와 other non-DBMS는 manages data이다.
Client
- client software module로 적절한 interface제공
-> 다양한 server resources 접근, 활용 o - disk 없는 machine라면 -> 접근만 o
(1-tier Architectures와 똑같은 상태가 되어서 display만 가능
= monitor역할) - disk가 있어야 client로 server처럼 연산 가능
- 서버와 연결 -> socket
Server
- Client에게 query와 transaction 제공
- transaction
- 병행제어
: 어떤 연산 끝나기 전 다른 연산 x - transaction 수행 시 atomic action한다 (=원자성)
- actomic action하는 단위
- 많은 작업을 isolation한 상태로 처리하려면
-> 병행 제어가 필요 -> 이 역할을 DBMS가 해줌
- 병행제어
- Application --API/Standard interface--> DB server
- standard interface 종류
: ODBC(C++), JDBC(Java)
-3. 3-tier Client-Server Architectures
- client 접근 -> 중간 business logic -> DBMS로 접근 못 하게 함
- middle tier 통해 client와 server연결
-> Client가 직접 DB에 접근하지 않아 data의 무결성, 성능 증가
client(GUI, Web Interface) <-> middle tier(Application Server or Web Server) <-> Database Server
3. DBMS 분류
-1. DBMS분류
- data model 기반 분류
- Legacy
: NetWork, Hierarchical(Tree같은거) - Currently Used
: Relational, Object-Oriented, Object-based
여기서 Relational -> DB tabel형
(relation이 중요한 이유 -> key를 통해 table들 끼리 join하여 data를 확장하기 때문) - Recent Technologies
: Key-Value storage systems, NOSQL, XML DBMSs
- Legacy
-2. 분산된 DBMSs의 변화
- Homogeneous DDBMS(동질)
- Heterogeneous DDBMS(이질)
: 만약 연결된 DB끼리 서로 Heterogeneous라면?
-> data가 분산되어 있으므로 중간에서 DB가 관리를 잘할수 있도록 도와줘야 함. - Federated or Multi-database Systems
: 약결합 시스템(loosely coupled) = 분산처리 시스템- 각 process마다 독립된 메모리를 가짐
- 2개 이상의 시스템을 통신망으로 연결한 시스템
- 각 시스템은 독립적인 작동 o, 상호 통신도 o
: 상호 통신 시 메시지 전달 or 원격 프로시저 호출 - 독립적임 -> process끼리 결합력이 약함
- DDBMSs(분산DB) = client-server based database systems
- 완전히 분산된 환경은 x
-> 하지만 a set of database servers, supporting a set of clients
= a set of -> 순서 중요 x
(아마도 순서 없이 database servers와 clients가 있음을 뜻하는듯)
- 완전히 분산된 환경은 x
4. Database 설계
- 개념적 스키마(Conceptual Schema)를 작성하는 것
- 개념적 Database 설계와 물리적 Database 설계로 구분o
-1. 개념적 Database
- 개념적 설계 : 정보 사용을 위한 상위 Model개발
- 설계 과정에서 추상화 Model구축
- 엔티티, 관계, 프로세스, 무결성, 제약조건 등 나타냄
- 엔티티: 서로 구분이 되며 조직에서 DB에 나타내려는 객체(사람,사물,장소 등) 의미
- 관계: 2개 이상의 엔티티들 간의 연관
- 프로세스: 관련된 활동/관련된 function
-> ex) 우리가 그린 그림이 그려지는 과정 - 무결성 제약조건: Data의 정확성과 비즈니스 규칙
-> ex) Skill통해서만 다음 단계로 이동 가능
- 엔티티, 관계, 프로세스, 무결성, 제약조건 등 나타냄
- 개념적 설계의 최종 산출물: 한 조직의 Conceptual Schema
-2. 물리적 Database
- 물리적 설계 : 물리적 저장 장치(disk), 접근 방식(access path) 다룸
- access는 index로 설명
- access path 잘못됨 -> index잘못됨 (물리적으로 index 잘못설정)
-3. ER Model
- 초기, 고수준(개념적) Database설계 표현하는데 사용하는 Model(그림)
- ER Model을 이용하여 관계 DataModel 그림
- Entity <-> Attribute <-> Entity간의 관계성으로 표현
- ER Model -> ER Diagram으로 표현
: 엔티티 타입 ->☐, 관계 타입 -> ♢, Attribute-> ㅇ - ER Model은 관계 DataModel(Conceptual Schema)로 쉽게 바꿀 수 있음
-4. 개념적 수준의 Model
- 응용 세계를 모델링할 수 있도록 하는 방법론
- Entity-Relationship Model이 제일 인기있는 Model
- Database구조나 Schema를 하향식으로 개발할 수 있는 틀 제공
- 구체적인것 거의 고려 x = ADT
- 개념적인 DataModel이 사상될 수 있는(=Conceptual schema가 될 수 있는) 구현 DataModel이 존재함
- 구현 단계에서 사용되는 3가지 DataModel
1) 관계 DataModel 2) 계층 DataModel 3)네트워크 DataModel
5. Database 설계 개요
-1. Database설계 개요
- = schema 설계
- 한 조직의 운영, 목적 지원하기 위해 Database를 생성하는 과정
- 주요 목적: 요구하는 Data, Data간의 관계를 표현하는 것
- 훌륭한 DB설계
- relationship(관계성)
- 시간의 흐름에 따른 Data의 모든 측면 나타냄
- Data중복, null Data최소화 -> 결함 최소화함
- DB에 대한 효율적인 접근 제공
- 무결성(integrity)
: 깔끔하고 일관성 있음 - 이해하기 쉬워야 함
-2. DB설계 주요 단계
- 요구사항 수집 및 분석 -> 개념적 설계 -> DBMS 선정 -> 논리적 설계
-> 물리적 설계 -> Transaction설계 -> 기타 여러 작업 - DBMS 선정 -> 논리적 설계 이유?
: DB에 따라 Schema가 달라지기 때문 - Transaction설계
: value의 integrity보장 -> atomic(all or nothing/원자성/하나 처리 전 다른거 처리 x) 덕분 -> 동시성 제어(conquerecy control)의 핵심 요건 - 데이터베이스 설계 단계(그림)

1) 요구사항 수집/ 분석 단계
- 요구사항 수집, 의견 평가, 조정
- 요구사항에 관한 지식 기반으로 Entity, Attribute, Relationship결정
- Entity: 서로 구분이 되며 조직에서 DB에 나타내려는 객체
ex) 공급자, 수요자, 회사, 물건 - Attribute: 속성
ex) 수요자의 주민번호, bier, 주소 - Relationship: 관계
ex) 수요자와 공급자간의 관계
- Entity: 서로 구분이 되며 조직에서 DB에 나타내려는 객체
- Data처리에 관한 요구사항에 대해
-> 적절한 연산, 연산들의 의미 재분석, 사용자/결과/outlier(이상치)/양/타입 등 분석
2) 개념적 설계 단계
- 설계 결과 ER Diagram으로 표현
- 사용자들의 요구사항 -> Conceptual Schema 만들어짐
- 논리적 설계 단계의 입력으로 사용
- 높은 추상화 수준의 DataModel + 정형적인 언어 -> Data 구조 명시
- 대표적인 DataModel = ER Model
- ER Model 에서 결정하는 것
- entity 타입
- relationship 타입
- attribute
- attribute domain(타입,ex,정수, 실수 텍스트)
- 기본키(내가 정한 키)
- 후보키
- entity 타입
- 완성된 ER Schema -> ER Diagram으로 표현
3) DBMS 선정 단계
4) 논리적 설계 단계
: 설계 결과 -> 해당DB의 Schema로 표현됨
- DBMS의 Data Model로 -> 논리적 Schema 생성
- Conceptual Schema 에 알고리즘 적용 -> 논리적 Schema생성
- 관계 Data Model로 논리적 Schema 나타내는 경우
-> ER Model로 표현된 개념적 Schema를 관계 Database Schema로 사상(mapping) - 정규화 과정(normalization)통해 더 좋은 관계 Data Schema로 변환
- DB설계자가 요구사항 수집, 분석 후 바로 논리적 설계 단계로 가는 경우
-> 좋은 관계 Database Schema생성되지 x
5) 물리적 설계 단계
- 설계 결과 -> 성능 향상으로 나타남
-> DB의 성능과 관련된 가장 중요한 기술 => index - index 다시 구축
- 역인덱스를 이용하여 -> 검색엔진 성능 향상 가능
- 성능의 주요 기준
- 응답 시간
- Transaction 처리율
- 확장성
- 유연성
6) Transaction 설계 단계
- 설계 결과 : 흩어진 일들이 하나로 묶여진 프로그램 계획서 생성
- Transaction 이란
- all or nothing, atomic action
- 완성될 Database에서 동작할 응용 프로그램
- Database는 Transaction에서 요구하는 모든 정보를 포함해야 함
- 요구사항 수집, 분석 후 Database설계과정과 별도로 Transaction 설계를 진행할 수 있음
- 검색, 갱신, 입력, 출력 유형으로 분류
-> 고객의 최종 필요성을 중심으로 프로그래밍을 고려하는 레벨 - A,B가 동시에 들어왔을 때 A만 들여보내고 B는 기다리게 함
-> 하지만 이때 동시성 레벨이 떨어진다는 문제가 있음
-> 따라서 이 문제를 해결하기 위해 A,B를 같이 들어오게 한 후
같은 data의 Schema를 조정하여 동시성 레벨을 높여준다
= transaction 안에서 waiting하게 함
