ELK Stack
ELK Stack은 로그 수집기술로 분석 및 저장을 담당하는 ElasticSearch, 수집 기능을 담당하는 Logstash, 시각화 하는 도구인 Kibana의 3가지 기술로 구성되어있다.
ELK Stack 사용 이유
ELK Stack은 기술 접근성과 사용성에서 기존의 기술들보다 편하다는 강점이 있고, 추가적으로 개발해야하는 부분이 거의 없다는 것이 강점이다.
ElasticSearch 강점
검색을 하기 위해 사용되는 ElasticSearch는 검색엔진이긴 하지만 데이터 적재를 위한 저장소로도 활용이 가능해 큰 메리트가 있다.
하나의 클러스터를 구성해 놓은 상태라면 다른 용도로 사용하는 것에 추가적인 일은 인덱스를 생성해주는 일 밖에 없다.
LogStash 강점
데이터를 수집하기 위해 사용하는 LogStash의 경우, 기존에 사용하던 Apache Flume과 크게 다르지 않지만 개발 과정 없이 설정만으로 실행할 수 있다는 점이 편리하다.
Kibana 강점
데이터 시각화 측면에서 직접적으로 데이터를 가공하여 사용하는 차트 솔루션에 적용하는 것을 직접 구현해야 했지만 Kibana를 사용하면 엘라스틱서치 내의 데이터를 추가적인 개발없이 설정만으로 바로 사용할 수 있다.
ELK Stack의 3가지 기술
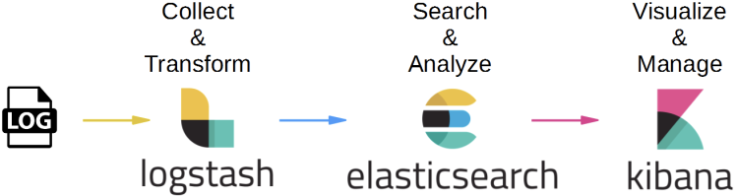
LogStash( Data Processing )
- 서버 내의 로그, 웹, 매트릭 등 다양한 소스에서 데이터를 수집하여 입력
- 데이터 변환 및 구조 구축
- 데이터 출력 및 송신
ElasticSearch( Storage )
- 데이터 저장
- 데이터 분석
- 데이터 관리
Kibanan( Visualize )
- Dashboard를 통한 데이터 탐색
- 팀원들과 공유 및 협업에 도움
- 액세스 제어 사용 가능
ELK Stack 장단점
장점
-
강력한 유연성과 호환성
-> 엘라스틱 서치, 로그스태시, 키바나는 각각 데이터의 검색, 수집, 시각화를 담당한다. 결과적으로 용도별로 분리할 수 있어서 구조적 안정성과 다양한 시스템과 유연한 호환성을 가진다. -
자유 스키마
-> JSON 방식의 Key - Value 형식의 데이터를 사용해 형식이 자유롭다. -
확장( Scale - Out ) 가능한 데이터베이스
-> 처음부터 확장을 고려하여 만들어져서 여러 개의 서버를 엮어서 성능 향상을 기대할 수 있는 클러스터 방식을 구성할 때 상대적으로 관련 정보에 쉽게 접근 가능하다. -
데이터 처리 방식을 개별 설정 가능
-> 데이터 처리 절차를 프로그래밍 언어를 이용한 코딩으로 명시할 시, 로그스태시를 포함하는 ELK Stack 구성 시 유연성 확보 가능하다. -
실시간 데이터 처리
-> 메세지 큐와 결합하면 강력한 실시간( RealTime ) 데이터 수집 및 처리 시스템으로 만들 수 있다.
단점
-
초기 데이터 구성 및 이관 문제
-> 빠른 데이터 처리를 장점으로 말하고 있으나, 초기 데이터 구성이 기존에 보유한 데이터를 엘라스틱서치로 이관하는 것에서 시작하는 경우가 많아서 성능 저하를 일으킬 수 있다. -
커널 변수의 불필요한 사용
-> ELK Stack을 구성하는 솔루션 중 로그스태시는 리눅스 운영체제 커널의 cgroups에 해당하는 변수를 참조하는 내용이 있는데, 커널 컴파일 설정에 따라 cgroups 내의 변수 일부는 존재하지 않을 수 있어서 데이터 수집 목적에 필수적이지 않은 변수가 존재하지 않아 프로그램이 중단되는 문제가 있다. -
초창기부터 현재까지도 원활하지 못한 시간대( TimeZone ) 처리
-> 3개의 기술( 로그스태시 -> 엘라스틱서치 -> 키바나 )로 데이터가 넘어가는 과정에서 시간대 일관성이 깨지는 문제가 있다.
