Kafka
Kafka는 분산 로그를 기반으로 디스크에 보존된 로그의 끝에 메세지가 기록되고 클라이언트가 해당 로그에서 읽기 시작하는 위치를 선택할 수 있다.
Kafka 클러스터에도 여러 서버에 분산 및 클러스팅하여 가용성을 높일 수 있으며, 개발자 중심의 설계로 구성되어 비동기식이고 고성능 방식이다.
Kafka의 특징
프로듀서와 컨슈머의 분리
- pub/sub 방식을 통해 메세지를 보내는 역할과 받는 역할이 분리되어 있다.
멀티 프로듀서, 멀티 컨슈머
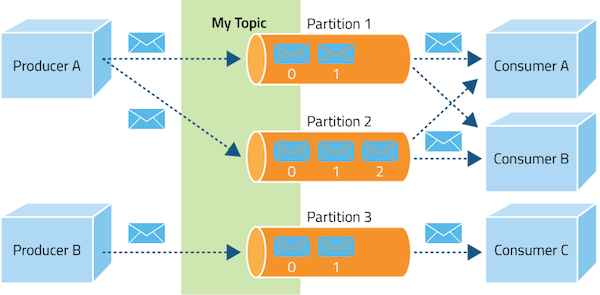
- Kafka는 중앙집중형 구조로 하나의 토픽에 여러 프로듀서, 컨슈머가 접근 가능하다.
프로듀서는 1개 이상의 토픽으로 메세지 전송 가능
- 컨슈머는 1개 이상의 토픽에서 메세지를 가져올 수 있다.
- 멀티 기능이 필요한 이유 : 데이터 분석 및 처리 프로세스에서 하나의 데이터를 다양한 용도로 사용하는 경우가 많아졌기 때문이다.
디스크에 메세지 저장
- RabbitMq, ActiveMq : 컨슈머가 메세지를 읽으면 큐에서 삭제한다.
- Kafka : 보관 주기 동안 디스크에 메세지를 저장 -> 트래픽이 급증하여 컨슈머의 처리가 늦어져도 카프카 디스크에 메세지가 보관되어 손실을 방지한다.
확장성 : 시스템 확장에 용이
- 분산 시스템을 기반으로 설계되어 구성 및 복제에 대한 설정을 쉽게 할 수 있다.
- 확장 시 서비스의 중단 없이 온라인 상태에서 작업 가능하다.
높은 성능
-
분산 처리 가능한 점으로 하나의 서버/노드에서 장애가 발생하면 다른 서버/노드에서 대신 처리 가능하다.
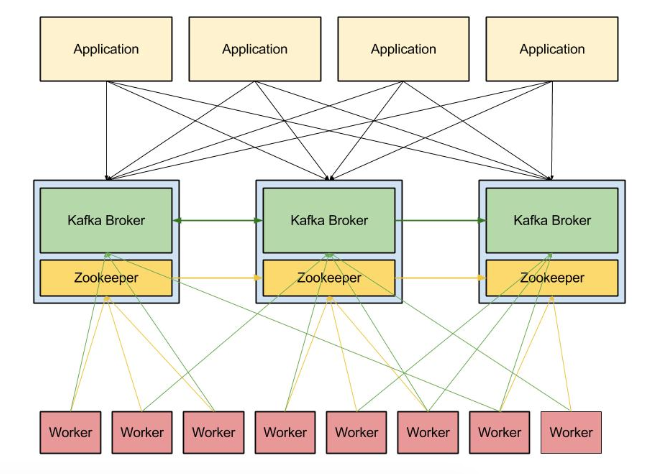
-
TCP 기반의 프로토콜을 사용하여 오버헤드가 감소한다.
Kafka의 pub/sub 모델
카프카는 pub/sub 모델로 만들어졌으며, pub/sub 모델이란 중앙에 메세지 시스템 서버를 두고, 메세지를 보내고( publish ), 받는( subscribe ) 형태의 통신 구독을 신청한 수신자만 메세지를 전달받을 수 있는 구조이다.
pub/sub 모델 장점
- 개체가 빠지거나 수신 불능이 되어도 메세지 시스템만 살아있으면 전달한 메세지가 유실되지 않는다.
- N:M으로 연결되는 것이 아니기에 확장성에 용이하다.
pub/sub 모델 단점
- 직접 통신하는 것이 아니기 때문에 메세지가 정확하게 전달되었는지 확인하기 위한 과정이 복잡하다.
- 메세징 시스템이 존재해 메세지 전달 속도가 느리다.
RabbitMq VS Kafka
두 기술 다 메세지 브로커라는 응용프로그램으로 서비스 및 시스템이 정보를 통신하고 교환 할 수 있도록 하는 소프트웨어이다.
메세지 브로커는 지정된 수신인에게 메세지를 확인, 라우팅, 저장 및 배달한다.
Kafka는 고성능을 추구하기 때문에 비교적 무겁다고 한다. 따라서 대용량 데이터를 다루지 않는다면 가벼운 RabbitMq가 적절하다.
현재는 Kafka의 사용 사례들이 늘고 있는 추세이고, 개발자들이 스트리밍 데이터를 더 쉽게 처리할 수 있도록 해주는 클라이언트 라이브러리, Kafka Strames가 있다.
Kafka의 사용이 적절한 곳
kafka는 복잡한 라우팅에 의존하지 않고 최대 처리량으로 스트리밍( 실시간 처리 )하는 데 가장 적합하여 스트리밍 데이터를 저장, 읽기, 분석하는 프레임워크가 필요한 경우, 정기적으로 감사하는 시스템이나 메세지를 영구적으로 저장하는 데 이상적이다.
RabbitMq의 사용이 적절한 곳
RabbitMq는 신속한 요청 - 응답이 필요한 웹서버에 적절하며, 장시간 실행되는 테스크, 안정적인 백그라운드 작업 실행, 애플리케이션 간의 내부 통신이 필요할 때 사용하는 것이 이상적이다.
