Lecture 15
강의 내용
- Recap: language models (LMs)
- What does a LM know?
- Techniques to add knowledge to LMs
- Add pretrained entity embeddings
- Use an external memory
- Modify the training data
- Evaluating knowledge in LMs
Recap: language models
언어 모델은 다음 단어를 예측하는 것이다.
The students opened their __.
빈칸에는 books, laptop 등 다양한 단어가 들어간다.
최근에는 BERT와 같은 언어모델은 masked token을 예측하기도 한다.
I [MASK] to the [MASK].
요즘 언어 모델은 텍스트의 다양한 활용에 대해 쓰인다.
• Summarization
• Dialogue
• Autocompletion
• Machine translation
• Fluency evaluation
그럼 언어 모델이 아는 것 이 무엇인가?
• iPod Touch is produced by __ .
• London Jazz Festival is located in __ .
• Dani Alves plays with __ .
• Carl III used to communicate in __ .
• Ravens can __ .
빈칸에 들어갈 단어는 무엇인가?
언어 모델은 다음과 같이 예측 했다.
• iPod Touch is produced by Apple .
• London Jazz Festival is located in London .
• Dani Alves plays with Santos .
• Carl III used to communicate in German .
• Ravens can fly .
언어 모델의 예측은 보통 말이 된다. 하지만 항상 factually correct하지 않다.
어떠한 현상들이 있을까?
- Unseen facts: 학습 중에 보지 못한 사실들이 있을 수 있다.
- Rare facts : 사실들의 수가 기억하기엔 매우 적을 수 있다.
- Model sensitivity: 학습 중에는 사실을 봤지만, 프롬프트에 나타내기에 민감할 수 있다.
가장 challenging 인 것은 지식을 확실하게 기억할 수 없는 점이다.
그럼 이러한 단점에도 LM 모델을 활용해야하는 걸까?
- downstream 작업을 할 때 편리하기 때문이다.
- 기존 traditional knowledge base를 대체할 수 있다. SQL로 구성된 지식 베이스 대신 LM이 지식 베이스를 대체할 수 있다.
전통적인 지식 베이스는 SQL 쿼리문으로 지식을 찾는다.
우리는 모든 정보를 데이터베이스에 저장하고, sql문으로 지식을 검색한다.
언어 모델은 지식 베이스처럼 행동할 수 있다. 사전 훈련된 모델에서 fine-tuning을 통해 지식을 배울 수 있다.
전통적인 기법에 비해 언어 모델은
- 비정형적이고 라벨링이 되지 않은 텍스트에 대해서도 학습이 가능하다.
- 유연한 자연어 쿼리문을 사용할 수 있다.
의 장점을 가진다.
하지만 단점으로는,
- 해석하기 어렵다.
- 신뢰하기 힘들다.
- 정보를 추가하거나 삭제하기 힘들다.
라는 것들이 있다.
Techniques to add knowledge to LMs
LM에 지식을 넣는 방법이 크게 3가지가 있다.
- Add pretrained entity embeddings
- Use an external memory
- Modify the training data
Add pretrained entity embeddings
pretrained word 임베딩들은 entity에 대한 개념을 가지고 있지 않다.
Korea, Republic of South Korea 둘 다 같은 '한국'을 의미하지만 다 다른 embedding을 가진다.
만약 우리가 각각의 entity에 대해 같은 임베딩을 부여하면 어떻게 될까? entity linking을 잘 한다면 매우 유용할 것이다!
Washington was the first president of the United States.
문맥 단어를 보니 워싱턴은 조지 워싱턴과 연결될 가능성이 높다라는 것을 알아내야 한다.

Entity linking은 우리에게 어떤것이 텍스트에 대한 임베딩이 관계가 높은지 말해준다.
Entity embeddings는 단어 임베딩과 비슷하지만, knowledge base에서 필요한 entity를 위한 것이다.
다양한 방법들로 entity embedding들을 훈련시킨다.
• Knowledge graph embedding methods (e.g., TransE)
• Word-entity co-occurrence methods (e.g., Wikipedia2Vec)
• Transformer encodings of entity descriptions (e.g., BLINK)
가장 중요한 문제가 있다.
어떻게 다른 임베딩 공간에서 사전 학습된 entity 임베딩들을 합칠 것인가?
문맥과 entity 정보를 결합하기 위해서 fusion layer(융합 계층)을 만들면 된다.
문장의 개체와 단어 사이에 알렺ㄴ 정렬이 있다고 가정하자.
는 j번째 단어의 임베딩이다.
는 일치하는 entitiy 임베딩을 의미한다.
ERNIE: Enhanced Language Representation with Informative Entities
ERNIE 모델은 텍스트에서 인물 장소, 조직과 같은 중요한 실체들을 인식하고, 이들 간의 관계를 이해하는데 중점을 둔다.
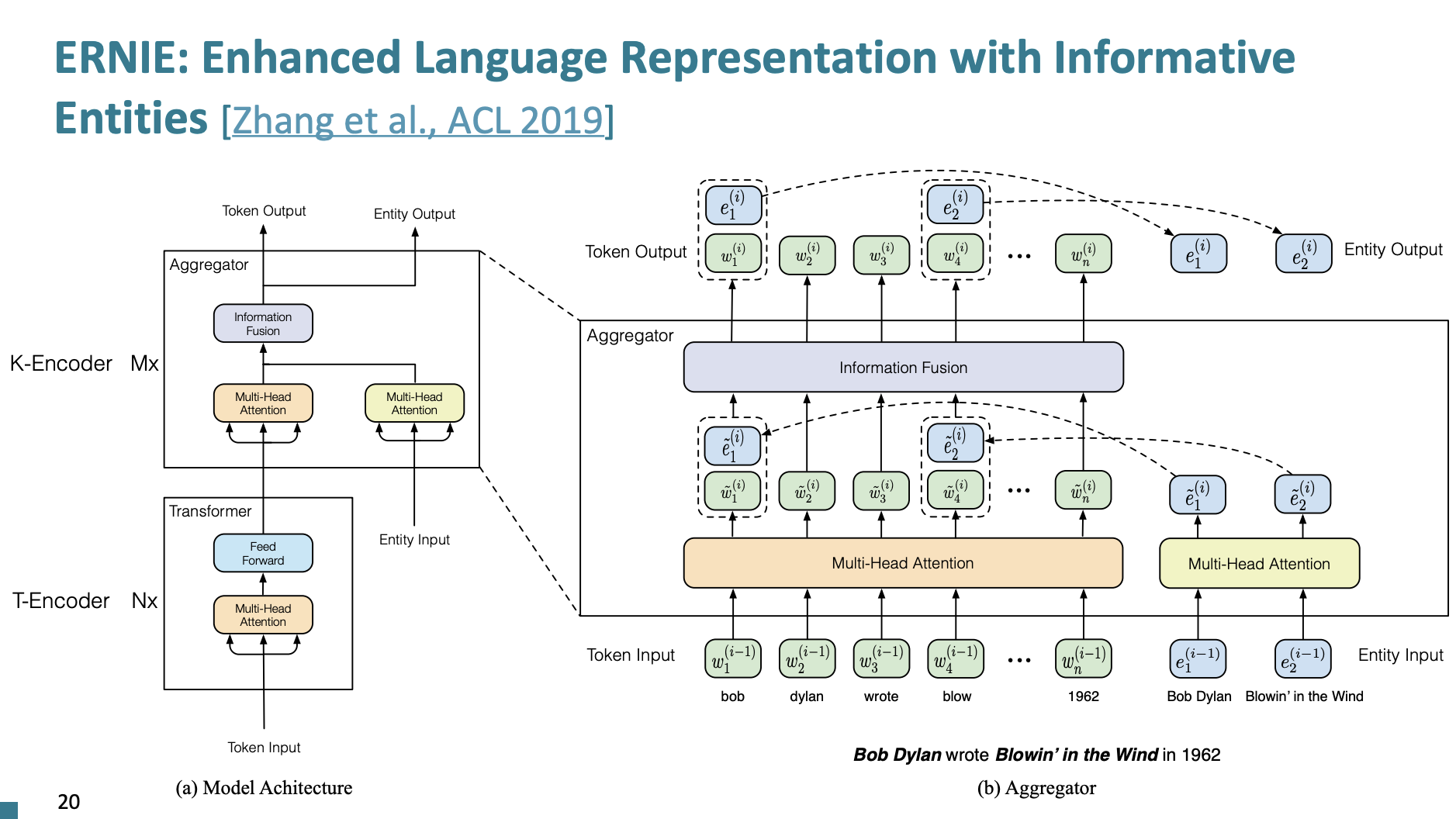
두가지 Encoder로 구성된다.
- Text Encoder
- Knowledge Encoder
- entitiy와 token 임베딩을 위한 두가지 multi-head attentions(MHAs)가 구성된다.
- MHAs를 합치는 fusion layer가 있다.
3가지로 Pretrain 된다.
- Masked language model
- next sentence prediction
- Knowledge pretraining task(dEA): 이것은 토큰과 entity 가 정렬된 것 중 랜덤으로 MASK해서 예측하도록 하는 것이다.
dEA = r denoising entity autoencoder from Vincent et al
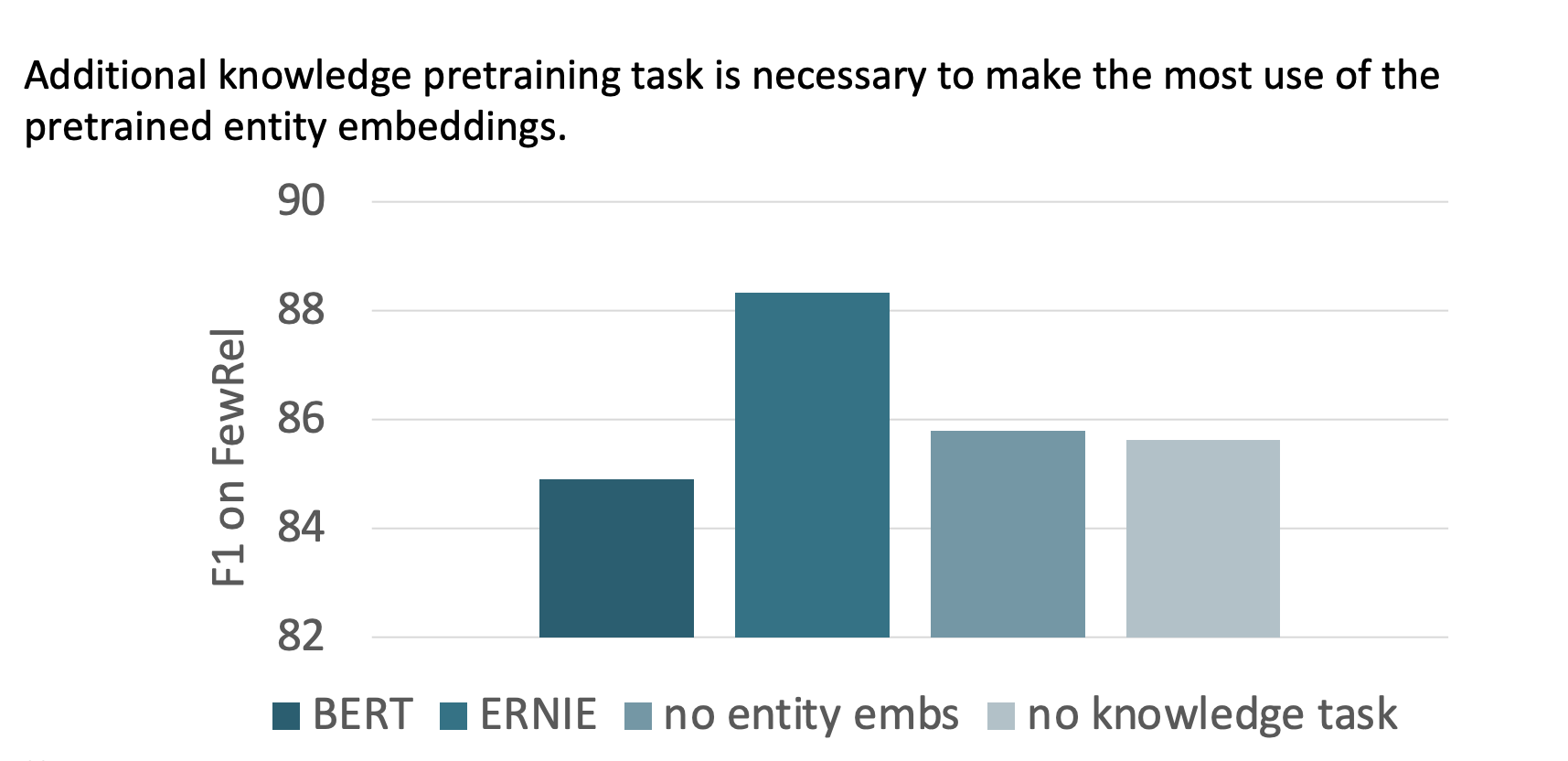
BERT에 비해 ERNIE가 뛰어난 성능을 보였다고 한다.
장단점을 살펴보자,
우선 장점
- entity와 context를 fusion layer와 knowledge pretraining으로 결합함
- downstream task 성능을 향상
단점
- text-entity 주석이 매우 필요해짐. 이러한 데이터는 구하기 힘듦
- 더 비싼 사전 훈련이 필요
KnowBERT
KnowBERT는 integrated entity linker (EL) 를 pretrain한다.
- EL이 entity를 예측하기 때문에 주석이 더이상 필요하지 않게 된다.
- EL을 학습하는 것은 지식을 더 잘 인코딩할 수 있다.
- ERNIE 처럼, KnowBERT는 fusion layer을 사용한다.
Use an external memory
이전의 방법은 pretrained entity embeddings에 의존해야한다. 만약 fact들이 변경되었다면? 다시 train을 해야하는 불편함이 존재한다.
좀 더 direct한 방법이 있지 않을까?
외부 메모리에 접근하는 모델을 만들어보자!
장점은
- Factual 지식들을 업데이트하고 제거하는데 좀 더 용이하다는 점
- 좀 더 interpretable 하다는 점이다.
KGLM
Using Knowledge-Graphs for Fact-Aware
Language Modeling (KGLM) 에 대해 알아보자.
Knowledge Graph에서 언어모델 조건을 지정하는 것이 Key idea이다.
언어 모델은 확률 계산을 통해 다음 단어를 예측한다.
KGLM모델도 entity 정보를 사용해서 다음 단어를 계산하는 것이다. 여기서는 LSTM을 사용한다.
우선 "Local" knowledge graph를 먼저 만든다.
Local KG는 시퀀스와 관계있는 entity만 있는 subset을 의미한다.
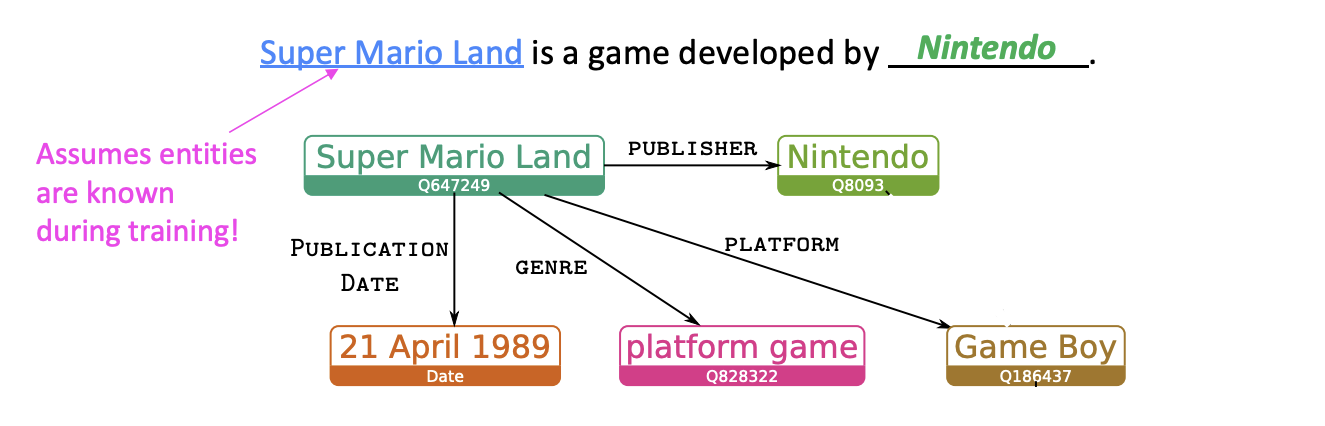
위 그림은 Super Mario Land와 Nintendo, Game Boy 등의 단어와의 관계를 나타낸 Local KG이다.
훈련 중에 entity가 알려져 있기 때문에 훈련을 위해 이 entity에 주석이 달린 데이터가 있다고 가정하는 것이다.
그럼 local KG를 언제 사용해야 할까? 다음 단어를 예측하는 데 실제로 유용할 수 있는 시기를 어떻게 알 수 있나?
그럼 다음 단어는 3가지 종류가 있다.
- Related entity(in the local KG)
- New entity(not in the local KG)
- Not an entity
LSTM의 hidden state를 활용하여 3가지 중 어떤 종류인지 예측한다.

만약 KG에 Super Mario Land와 Nintendo가 아무 관계가 없다면, 기존 LSTM대로 예측된다.
더 자세히 어떻게 예측하는지 알아보면,

Nintendo에는 상위 엔터티가 Super Mario Land하나 있다.
트리플 중에 가장 관련이 깊은 것을 선택한다.
Related entity (in the local KG)를 찾는 경우
- local KG에서 가장 높은 점수의 부모와 관계를 찾는다.
- 그리고 tail entity를 다음 entity로 선택한다.
- 다음 단어를 예측하기 위해서 다음 어휘를 가져와서 별칭들로 확장한다. 닌텐도를 가져왔다면, Ninendo Co 등으로 확장시킨다.
New entity (not in the local KG)를 찾는 경우
- 전체 KG에서 가장 높은 점수를 찾는다.
- 가장 높은 점수의 entity를 선택
- 해당 entity의 별칭까지 포함한다.
Not an entity의 경우
- 다음 entity는 없다.
- 다음 단어는 기존 단어장에서 찾는다.
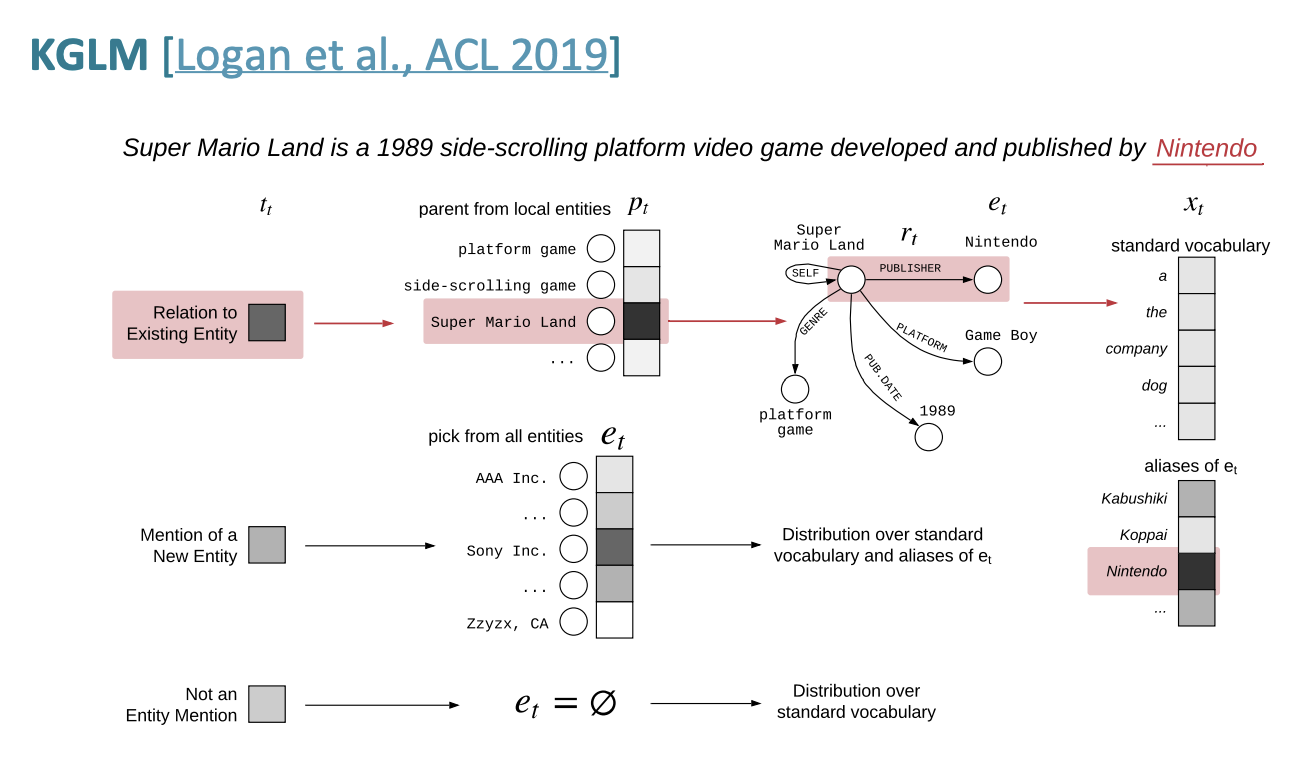
실행은 위 다이어그램처럼 실행된다.
- 결과
- GPT-2 보다 좋은 성능- GPT-2 보다 KGLM이 좀 더 specific 한 토큰을 예측
- facts 수정, 업데이트 지원
Nearest Neighbor Language Model(knn-LM)
텍스트 시퀀스 사이의 비슷함을 학습하는 것이 다음 단어를 예측하는 것보다 쉽다는 아이디어이다.
그래서 neareest neigbor 데이터스토어에 모든 텍스트 시퀀스 표현을 저장한다.
- k개의 가장 비슷한 시퀀스를 찾는다.
- k시퀀스에 대해서 일치하는 값을 검색한다.
- knn 확률과 LM확률을 결합한다.
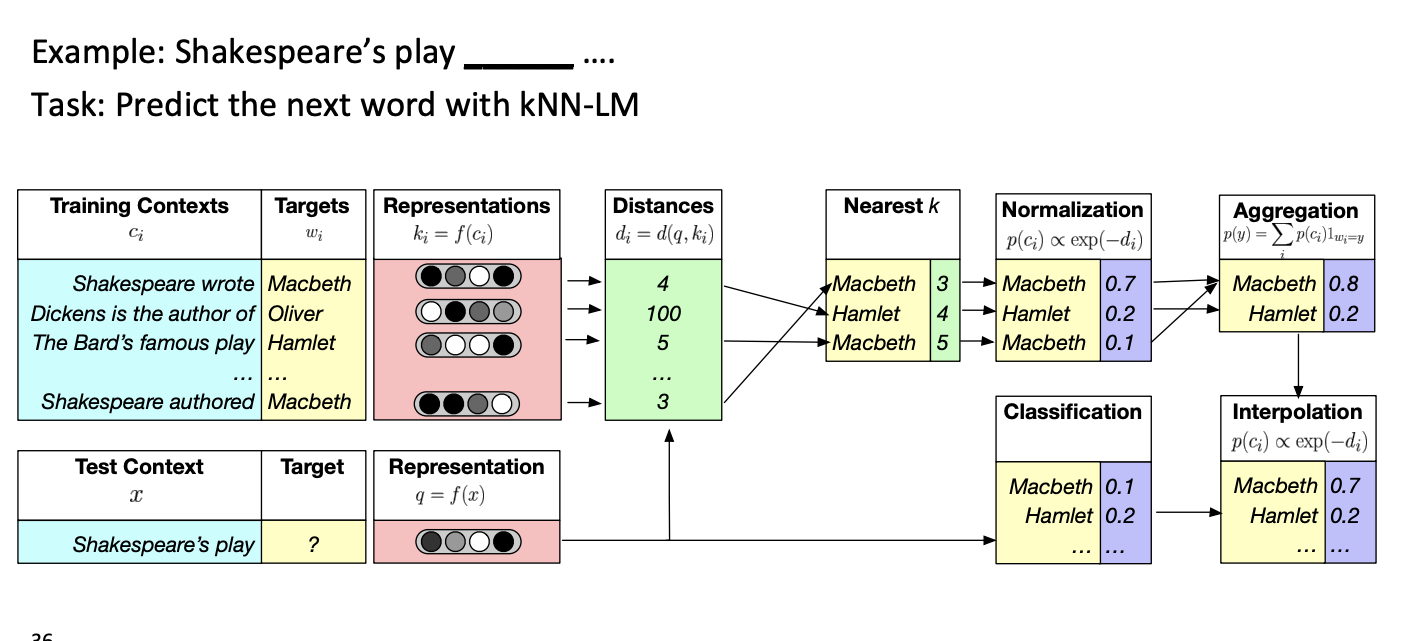
위 그림을 통해 간단하게 이해해보자.
거리를 우선 계산한 다음 가장 가까운 k개를 찾고 정규화를 시킨다. 만약 동일한 것이 있다면 통합(Aggregation)을 한다. 그리고 test셋과 보간법을 통해 답이 Macbeth라는 것을 찾는다.
Modify the training data
그럼 훈련 데이터를 수정하면 어떻게 될까?
비 정형 텍스트에 대해 암묵적으로 지식을 통합할 수 없을까?
가능하다. 훈련 데이터를 수정하면 되는 것이다.
해당 방법의 장점은
- 추가적ㅇ니 메모리랑 계산이 필요하지 않다는 점
- 아키텍처를 수정하지 않아도 된다는 점이다.
WKLM
Weakly Supervised KnowledgePretrained Language Model 인 WKLM에 대해 알아보자.
핵심 아이디어는 참과 거짓인 지식 사이에서 모델이 구별할 수 있도록 훈련하는 것이다.
거짓인 지식을 만들어내기 위해서 같은 종류이지만 다른 entity로 멘션을 수정한다.
- 모델은 entity가 수정되었는지 아닌지 예측한다.
- 같은 종류로 제한하는 것은 언어적으로 올바른 문장을 만들어내기 위해서이다.
참인 문장 : J.K. Rowling is the author of Harry Potter.
거짓인 문장: J.R.R. Tolkien is the author of Harry Potter.
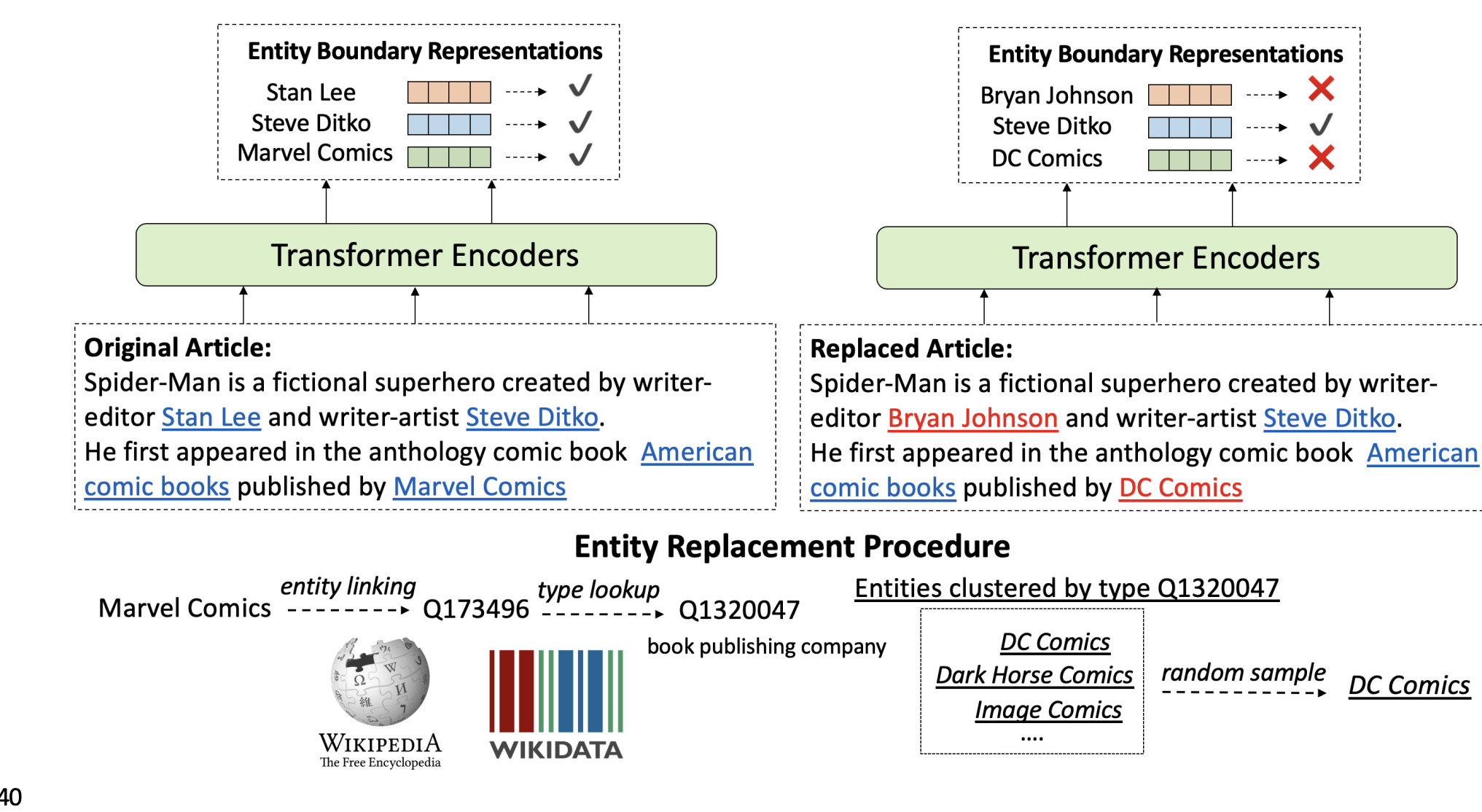
원래의 기사에서 변환될 entity를 골라서 변환시킨 다음 encoder에 넣고 참인지 거짓인지를 판단한다.
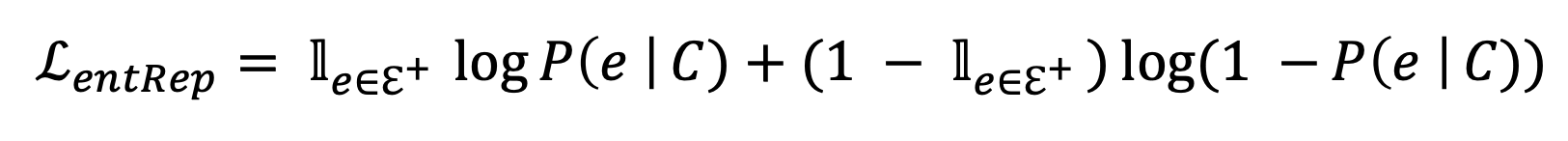
(e = entity, C = context, = true entity mention)
참인지 거짓인지를 구별하기 위해서 entity replacement loss를 사용한다.
Total loss 는 Masked language model loss와 entity replacement loss를 더함으로써 계산한다.
MLM은 token-level, entRep은 entity level로 정의된다.
Experiments
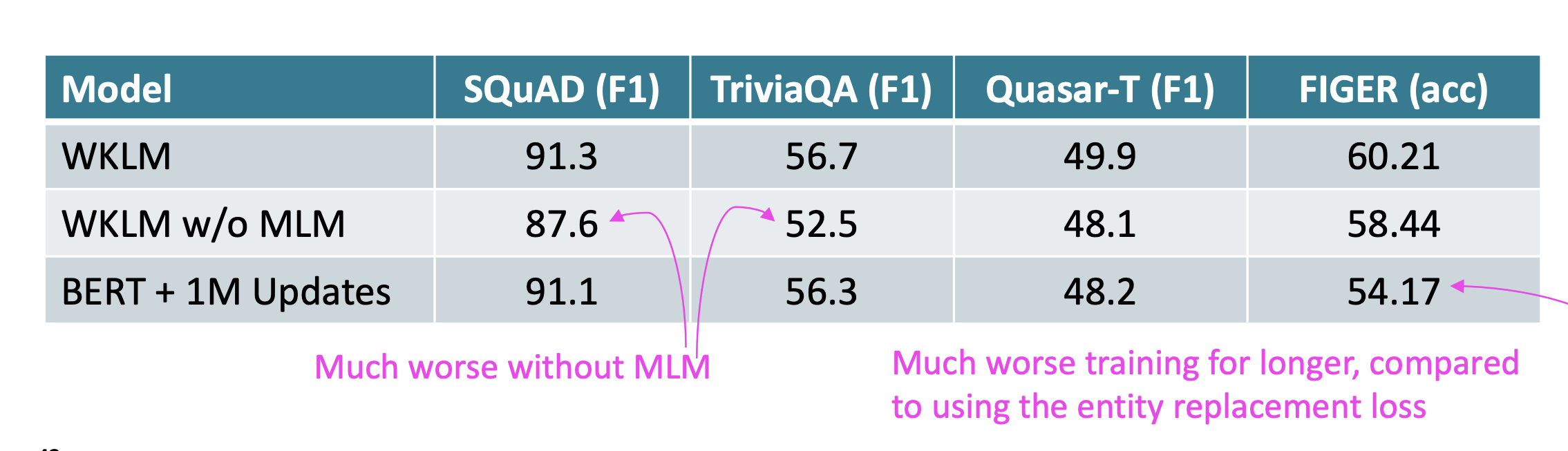
- 실험 결과 BERT와 GPT-2보다 성능이 좋았다.
- ERNIE보다 downstream(entity typing)에 대해 성능이 좋았다.
- MLM loss 계산은 downstream 작업 성능에 효과적이었다.
- 하지만 MLM loss 계산만 수행하는 것보다 WKLM이 더 성능이 좋았다.
Learn inductive biases through masking
Masking 만으로 factual knowledge를 배울 수 있을까?
여기 몇가지 최근 연구들이 있다.
- ERNIE1: Enhanced Representation through Knowledge Integration
- How Much Knowledge Can You Pack Into the Parameters of a Language Model?
- "salient span masking"을 사용한다.
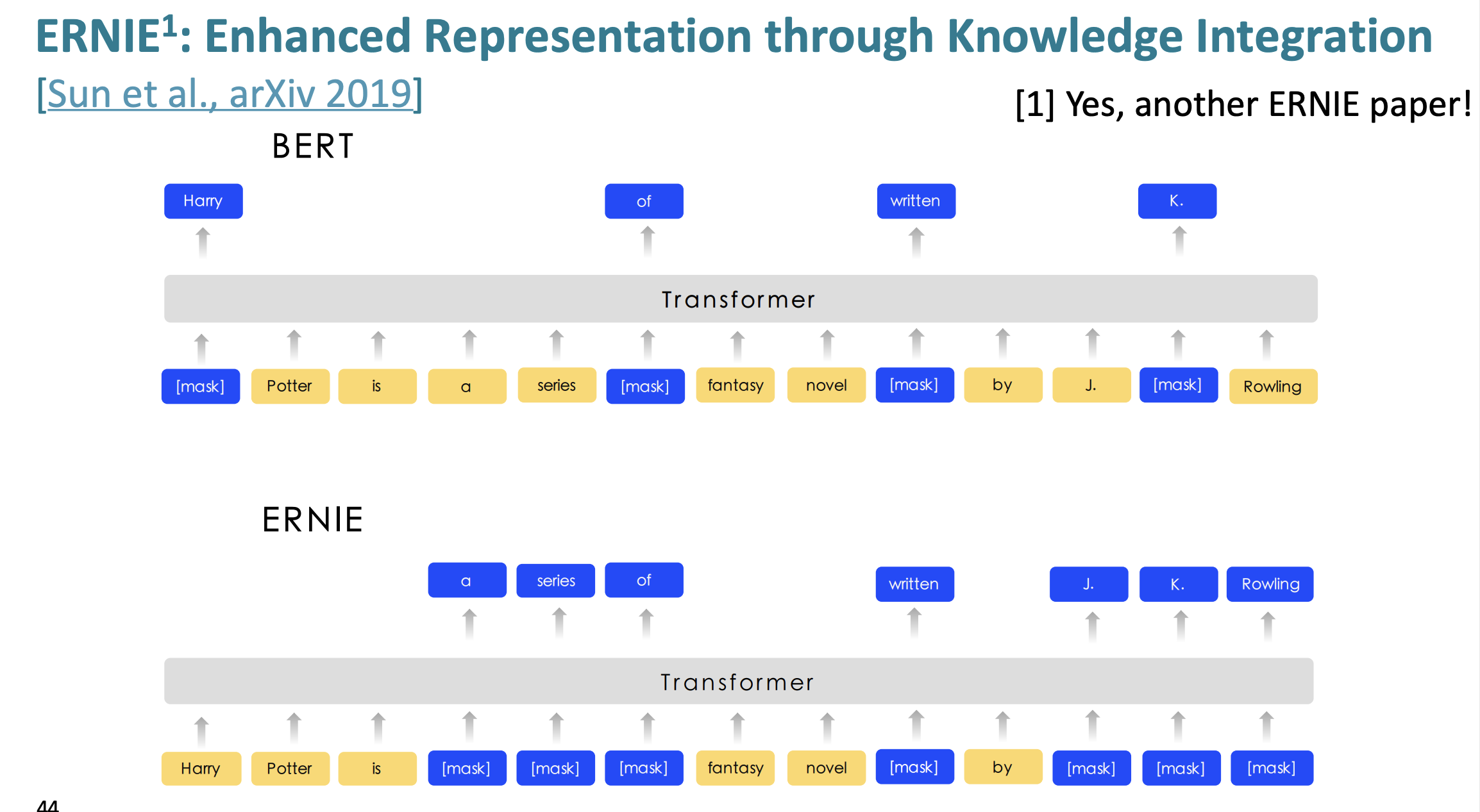
BERT에서는 token별로 masking을 처리했다면 ERINE에서는 entity별로 masking을 하는 방법이다.
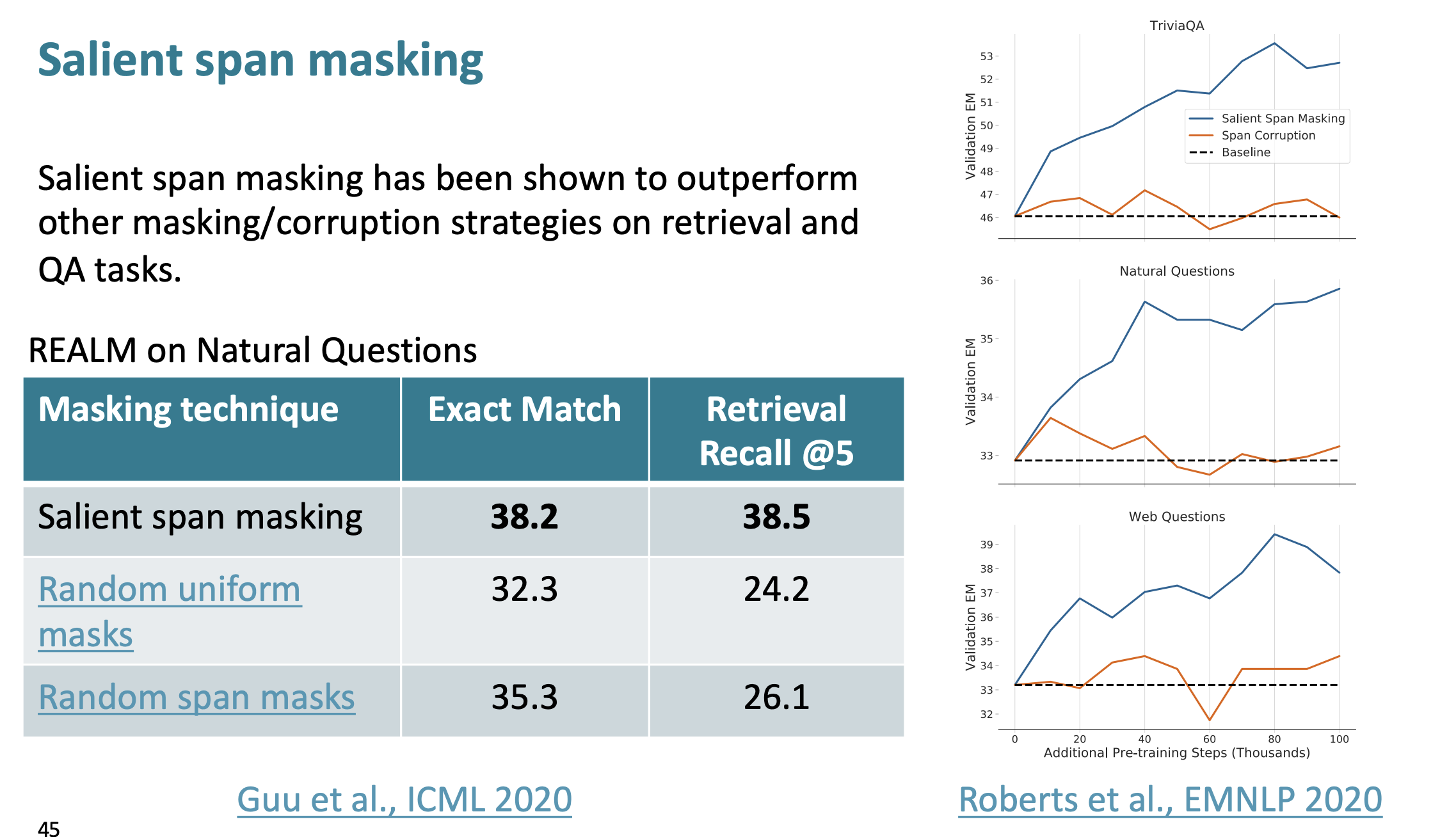
"Salient span masking"은 이전의 방법들보다 검색과 QA 작업에 대해서 좋은 성능을 보였다.
정리
3가지 방법에 대해 장단점을 비교해보자.
- Use pretrained entity embeddings
- KG사전학습을 통해 기존 아키텍처에 적용하는 것은 그닥 어렵지 않음
- 하지만 결과에 대해서 간접적인 방법이고, 해석하기 어려운 부분이 있음.
- Add an external memory
- 새로운 사실에 대해서 업데이트 하기 쉽고 해석도 쉬움
- 구현이 어렵고 새로운 메모리를 저장할 공간 필요함
- Modify the training data
- 모델의 수정, 추가 계산이 필요하지 않음.
- 이론적으로 분석하기 쉬움
- 모델을 변경하는 것보다 효과적인지 아직 모름.
Evaluating knowledge in LMs
LAnguage Model Analysis (LAMA) Probe
LAMA는 언어 모델에 일련의 '질문'을 하고 모델이 얼마나 '답변'을 잘 하는지 평가한다.
질문들은 일반적으로 간단한 팩트 또는 일반 지식에 관한 것이다.
예를 들어서
"파리는 프랑스의 __"와 같은 문장을 주면 모델이 이 문장의 빈칸을 완성하도록 한다.
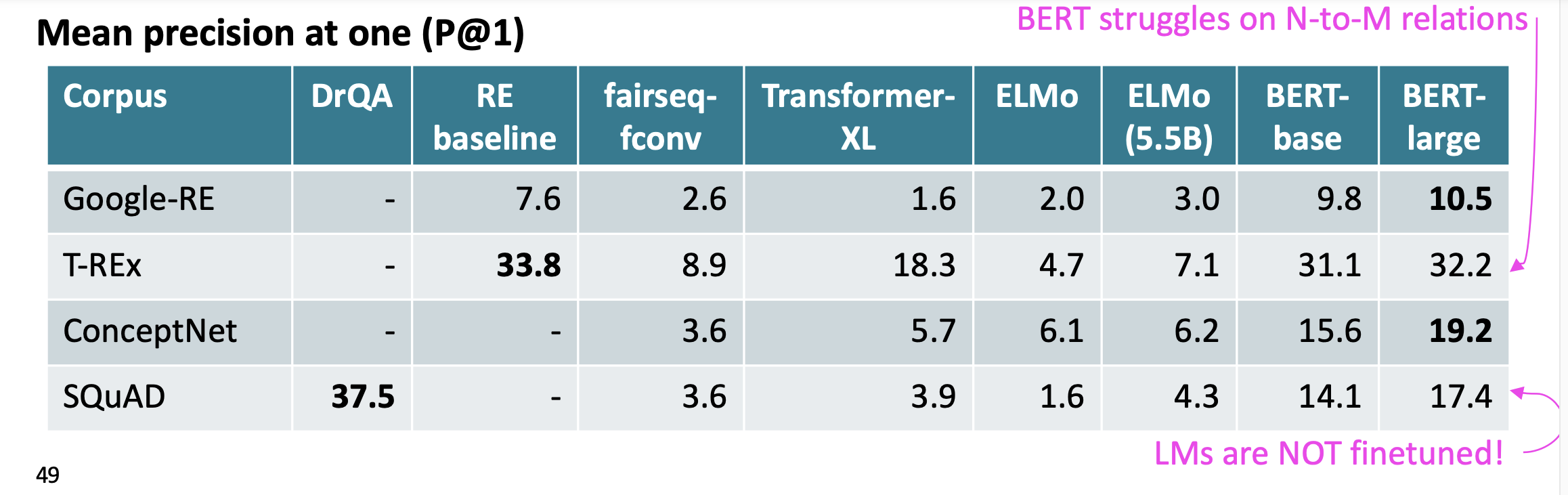
모델의 성능은 데이터 마다 달랐다.
- Google-RE는 관계 추출을 위한 데이터셋이다.
- T-REx는 Goodle-RE보다 더 많은 관계 유형과 예시를 포함한다. 위키피디아를 기반으로 한다.
- ConceptNet은 일반적인 지식을 나타내는 구조화된 그래프 데이터베이스이다. "사과는 과일이다" 또는 "새는 날 수 있다" 와 같은 지식을 포함한다.
- SQuAD는 질문에 대한 정확한 답변을 찾기위해 설계되었다. 주로 기계 독해 모델 학습에 사용된다.
BERT-large의 경우에는 관계의 경우가 단순한 경우에 점수가 높았다.
T-REx는 n대n의 관계가 많아 BERT의 점수가 그리 높지 않았다.
LM은 미세 조정이 되지 않은 경우 DrQA보다 낮은 점수를 보였다. DrQA는 Document Reader Question Answering 으로 질문 답변 시스템이다.
LAMA의 단점으로는 왜 모델이 성능이 좋은지 이해하기 어렵다는 단점이 있다. 진짜로 지식을 이해하여 문제를 해결하는 것인지 또는 겉으로 나타나는 표현만으로 문제를 해결하는 것인지 모른다.
LAMA-UnHelpful Names (LAMA-UHN)
언어 모델이 부정확하거나 오도하는 정보를 얼마나 자주 생성하는지 평가하는 것이다.
모델이 진짜 신뢰할 수 있는 것처럼 보이게 하지만 사실은 가짜인 정보와 개념을 사용할 수 있다.
기존 LAMA의 데이터셋에서 관계적 지식 없이도 답변할 수 있는 예제들을 제거한다.
문맥적 단서나 단어의 빈도수 등 비관계적 정보에 기반하여 정답을 유추할 수 있게 한다.
• BERT’s score on LAMA drops ~8% with LAMA-UHN
LAMA에서-UHN에서 BERT의 성능이 LAMA에서 보다 8%정도 떨어진다.
Developing better prompts to query knowledge in LMs
지식을 가만히 냅두고, 쿼리를 수정하는 것만으로도 정확도를 높일 수 있다.

LAMA에 대한 BERT-large의 성능은 쿼리 수정만으로 7%가 높아졌다.
Knowledge-driven downstream tasks
이전에 배운 Knowledge-enhanced systems들이 지식 기반 downstream tasks를 얼마나 잘 수행하는지 평가하고자 한다.
task에는 아래의 것들이 있다.
- 관계 추출
Example: [Bill Gates] was born in [Seattle]; label: city of birth - 엔티티 입력
Example: [Alice] robbed the bank; label: criminal - 질문 답변
Example: “What kind of forest is the Amazon?”; label: “moist broadleaf forest”
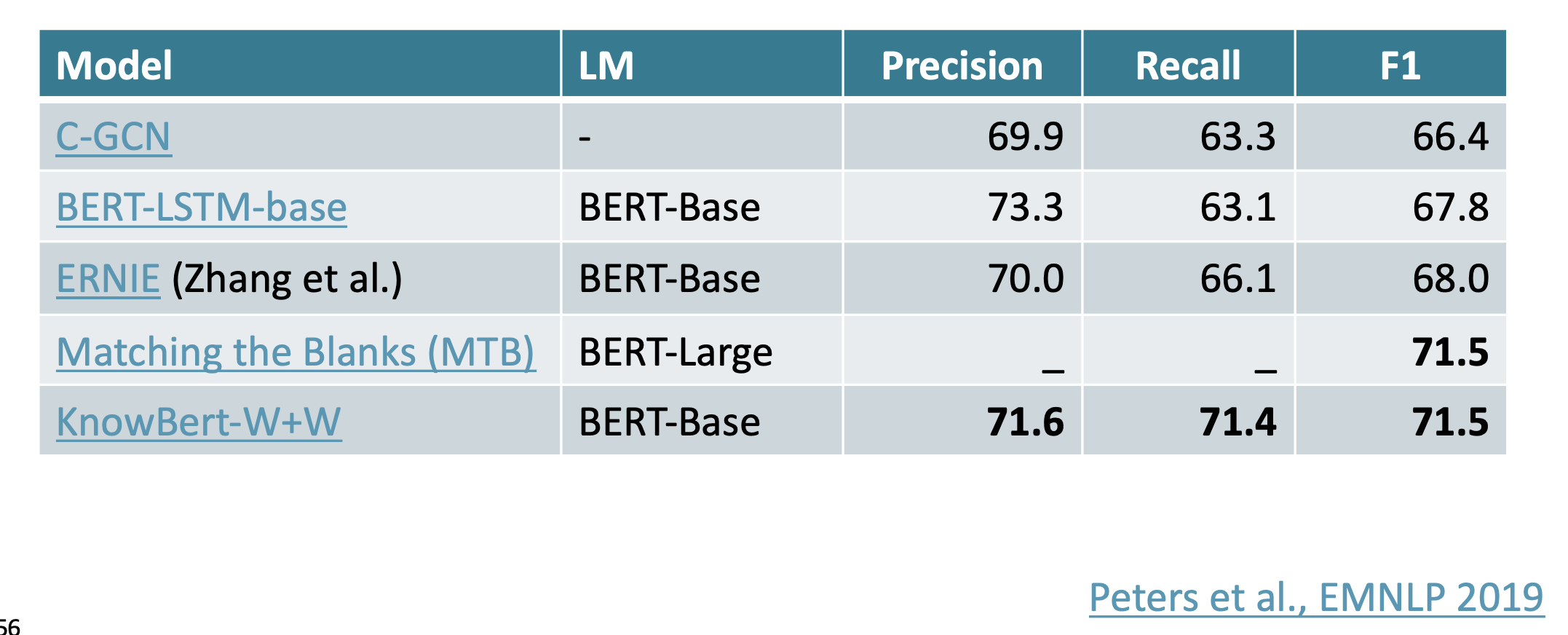
그리고 이전 모델인 BERT와 비교해서 좋은 점수를 얻었다.
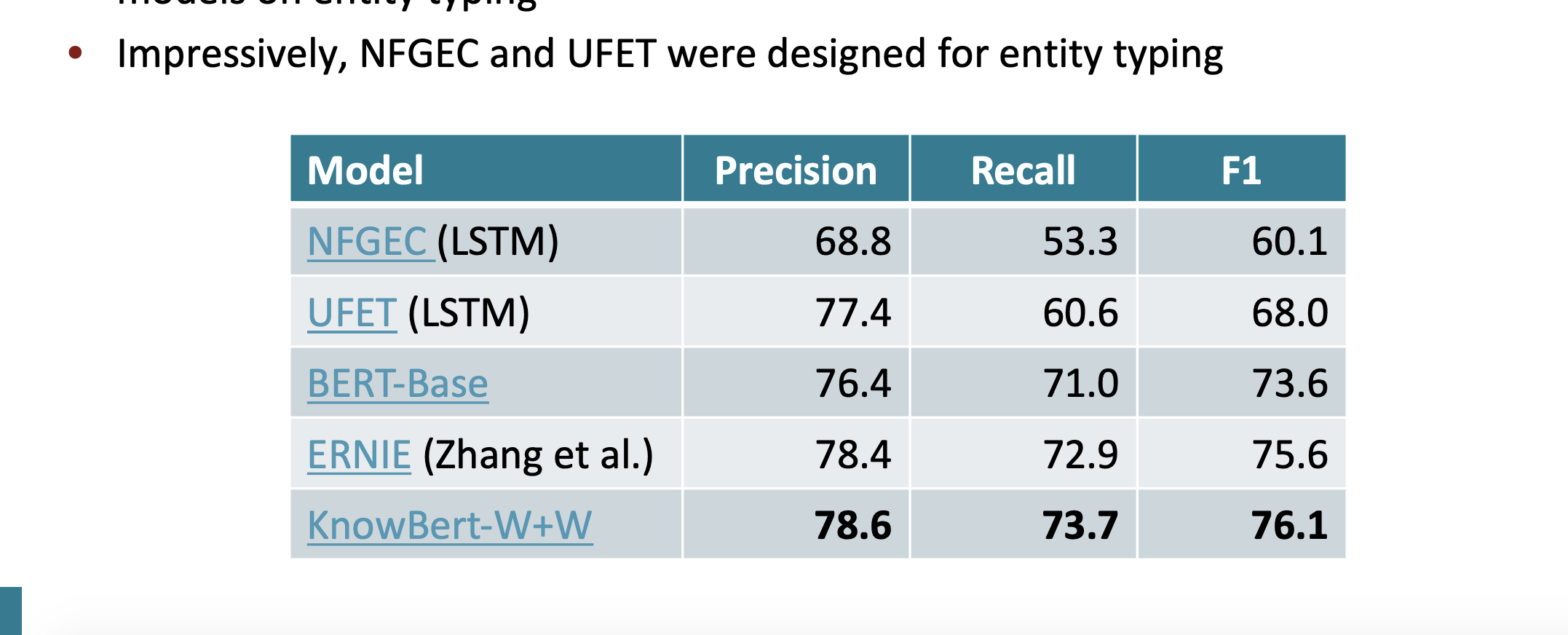
Open Entity에 대해서도 KnowBERT가 좋은 점수를 얻었다.
끝
