오늘 배울 내용은 Insights between NLP and Linguistics에 대한 내용이다.
오늘의 lecture plan 이다.
- Structure in human language
- Linguistic structure in NLP
- Going beyond pure structure (in linguistics and deep learning)
- Multilinguality in NLP
Lecture 14
오늘 내용은 거의,,, 언어학에 가까운 내용이다.
(그래서 너무 졸렸다)
Structure in human language
인간은 언어를 가지고 있고 다른 동물의 의사소통과 다르다.
- 언어는 무한한 것을 말할 수 있다.
- 하지만 뇌는 유한하다. 따라서 언어는 일종의 규칙을 가지고 있다.
- 이 규칙을 통해 무엇이든 말할 수 있게 된다.
- 인간은 눈에 보이는 것, 보이지 않는 것, 존재하지 않는 것, 추상적인 것 등등에 대해 이야기할 수 있다.
- 비슷하고 추상적인 것에 대해 미묘한 차이가 있지만 그 차이를 표현할 수 있다.
Isabel broke the window
The window was broken by Isabel
The cat is batting the toy
The toy is being batted by the cat
The plid yorbed the plof
The plof was yorbed by the plid
우리는 같은 의미의 말을 다른 구조로도 표현할 수 있다.
즉 말하는 것과 별개로, 언어의 구조에 대한 지식도 가지고 있다.
언어의 구조를 설명하기 위해서 하나의 예시를 살펴보자.
고양이가 매트위에 앉아있다.
라는 문장이 있다고 하자.
___ 매트위에 앉아있다.
빈칸에는 주어가 들어간다. "그가", "그녀가" 등등이 들어갈 수 있다.
고양이가 __위에 앉아있다.
빈칸에는 명사가 들어간다. "의자"같은 명사가 들어갈 수도 있고, "거기" 와 같은 대명사가 들어갈 수 있다.
고양이가 ___ 앉아있다.
'위'라는 전치사가 없어도 '의자에' 와 같은 것으로 대체될 수 있다.
고양이가 ___
빈칸에는 '잠잔다' 와 같은 단어 하나로도 작성할 수 있다.
_ 매트위에 ___
하지만 '매트위에'만 있다면 하나의 말로 표현할 수 없게 된다.
영어로는 ___ on the mat 이라 표현했는데, 주어와 동사가 없기 때문에 하나의 단어로 표현할 수 없다.
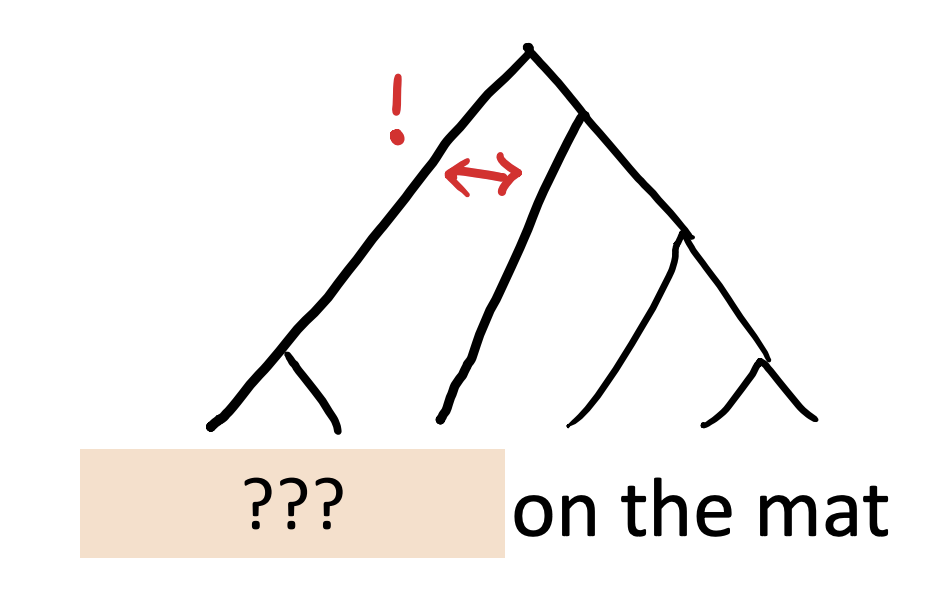
이는 문장을 트리형식으로 나눠 보면, 나눠지는 가지 부분이 다르다는 것을 알 수 있다.
우리는 암묵적으로 질문을 하는 구조에 대해서 알고 있다.
What is Leon?
What does my cat like?
❌ What is Leon a doctor and
Grammaticality
인간은 문법에 대해서 암묵적인 합의를 보았다.
그러니까 규칙을 사용해서 생성할 수 없다면 비문법적인 것이다.
예를 들어서 영어에서는 SVO 순서로 문장을 작성한다.
주어의 대명사에는 I, she, he, they 와 같은 것들이 있고 목적어의 대명사에는 me, her, him, them 과 같은 것들이 있다.
그래서 "I love her"는 문제가 없지만, "Me love she"는 문제가 있다고 생각하는 것이다.
대충 의미는 뭔지 이해가 가지만, 이렇게 작성하면 안될 것 같다.
사실 문법만 따지면, 아무런 의미가 없지만 문법이 맞는 문장이 있을 수도 있다.
“Colorless green ideas sleep furiously”
격렬하게 잠든다..? 이상한 의미이지만 문법에는 오류가 없다.
즉 문법은 쓸모없는 발화를 허용할 수 있고, 완벽하게 의미가 있는 발화를 차단할 수 있다. 문법은 우리의 가능성을 제한할 수도 있다는 것이다. 예를 들어서 판타지 공포 요리 소설이 있다고 하자, 그러면 나는 이렇게 아래 문장을 적고 싶을 수 있다.
양파가 요리사를 다졌다.
결과적으로 언어는 매우 Compositional한 것이다.
Linguistic structure in NLP
그럼 중요한 건 우리는 언어학을 공부하려는 것이 아니다.
자연어 처리에서 언어의 구조에 대해 배워보자.
NLP에서도 인간처럼 discrete rules로 언어를 만들까? 당연하다!
다음 문장을 보고 영화에 대한 감정 평가를 해보자!
"My uncultured roommate hated this movie, but I absolutely loved it"
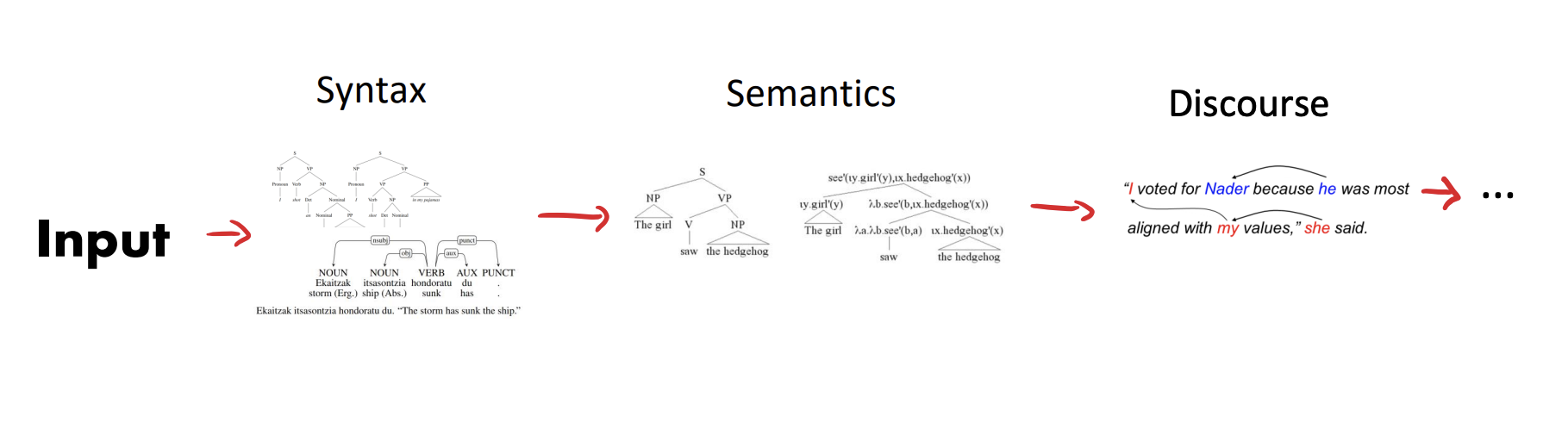
인공지능은 일단 입력 문장을 보고 구문을 판단한 다음 의미를 파악하고 Discourse를 확인하고 ... 이러한 파이프라인을 통해언어를 이해하게 된다.
GPT의 등장으로 위 문장에 대한 감정분석은 매우 쉬워졌다. 금방 "Positive"하다는 감정을 알아챈다.
Testing structure
인간은 쉽게 새로운 단어를 기존 구조에 통합시킬 수 있다.
기존에 보지 못한 단어 "chortled"같은 단어도 인간은 앞 뒤 문맥을 통해서 단어의 의미를 유추할 수 있다. 기계도 이러한 능력을 가질 수 있나?
COGS benchmark
COGS benchmark는 자연어처리 분야에서 구문 구조 이해 능력을 테스트 하는데 사용되는 데이터셋이다. 모델이 얼마나 문장 구조를 잘 이해하고 그 구조에 따라 단어의 의미를 어떻게 해석하는지 평가하기 위해 설계되었다.
주요 목적은 구문 일반화(syntactic generalization) 능력을 측정하는 것이다. 구문 일반화는 모델이 훈련 과정에서 보지 못한 새로운 구문 구조를 얼마나 잘 처리하는 지 평가하는 것이다.
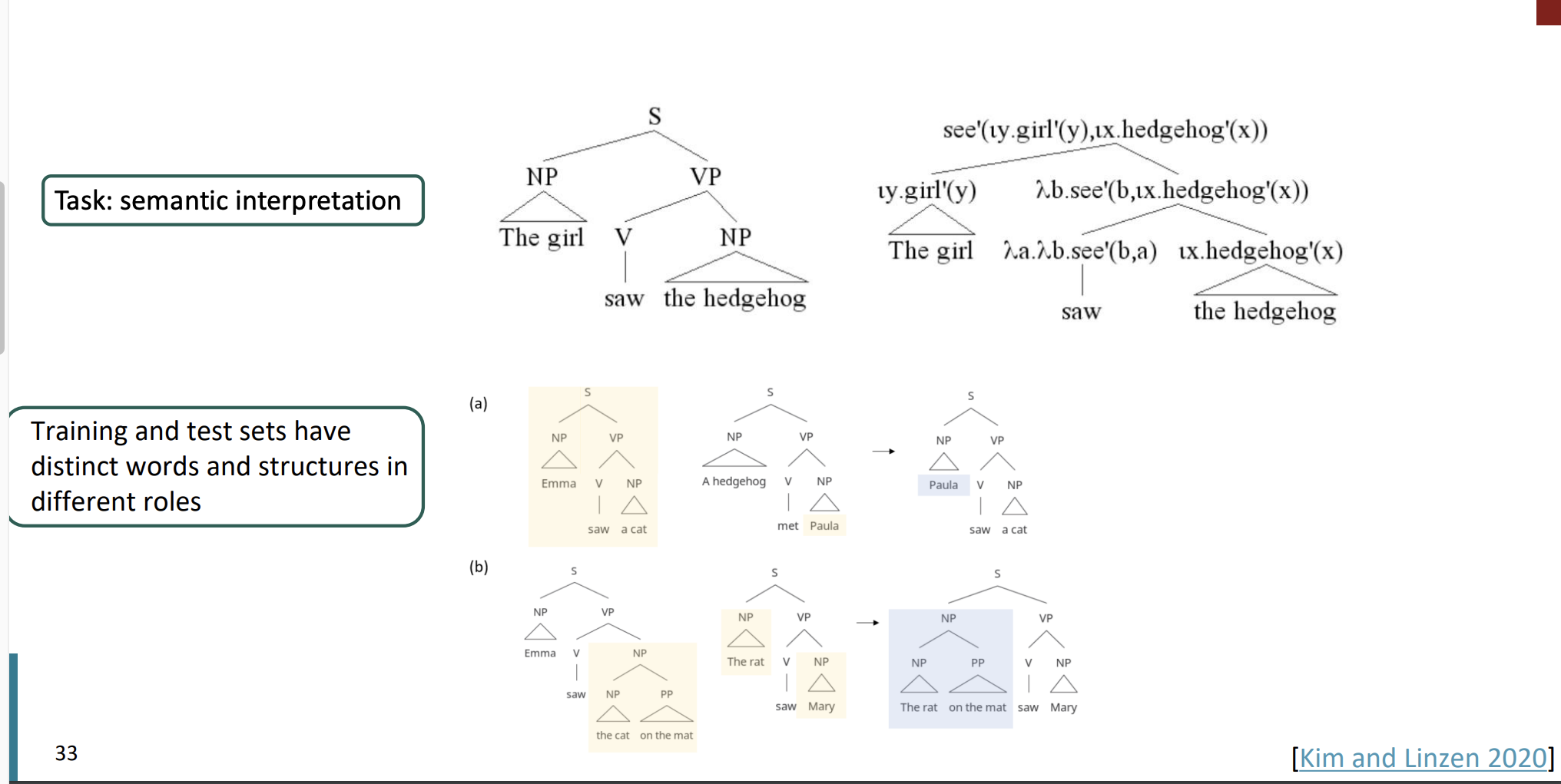
COGS는 다양한 구문 구조 데이터셋를 가지고 있다. 다음과 같은 능력을 평가하는 것이다.
- 복잡한 문장 구조 이해 : 중접된 절, 복합 문장 등 복잡한 구조를 어떻게 처리하는 지?
- 새로운 조합 처리 : 훈련 도중 본적 없는 단어르 어떻게 처리하는가?
- 일관된 단어 의미 해석 : 다양한 문맥에서 단어의 의미는 일관되게 유지 되는가?
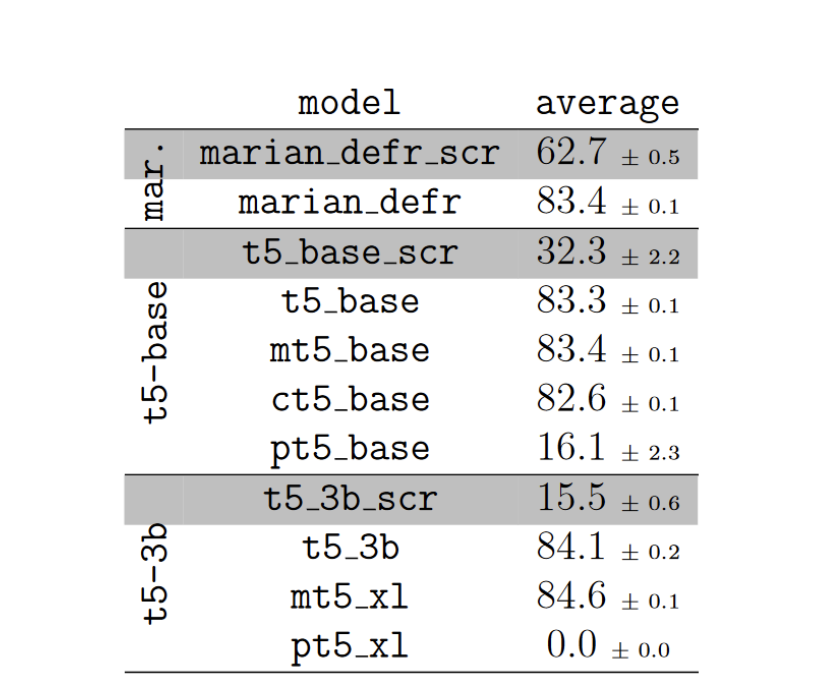
large language model은 어느정도 해결을 했지만 완전히 해결하지는 않았다.
Jabberwocky sentences
Jabberwocky sentences는 의미 없거나 매우 모호한 단어들을 사용하지만 언어의 문법 구조를 따르는 문장을 말한다.
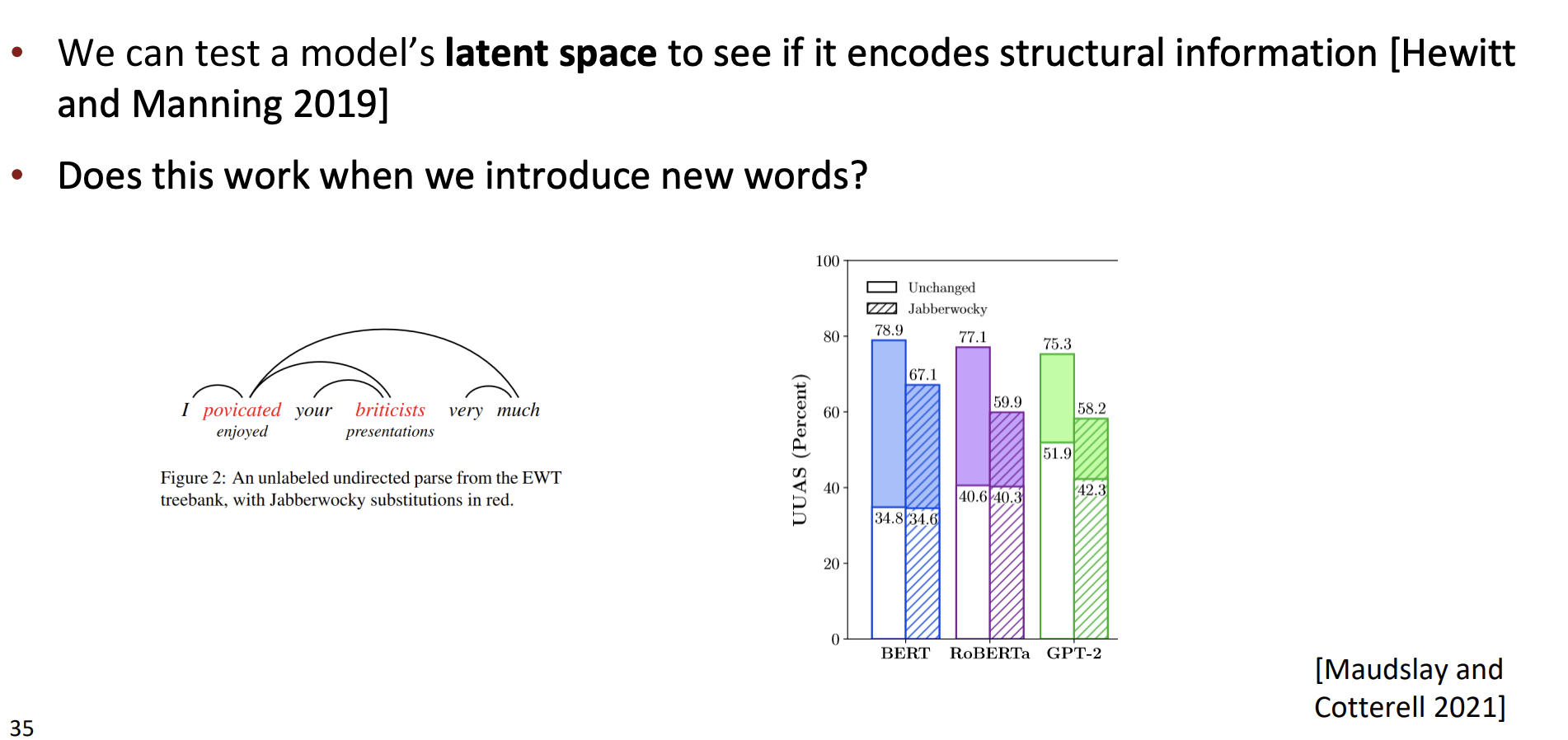
우린 모델이 구조적 정보를 인코딩하는지 확인하기 위해서 모델의 잠재공간을 테스트할 수 있다.
만약 재버워키같은 새로운 단어를 생성해내면 모델의 정확도는 어떻게 될까?
위 그래프에서 알 수 있다시피 정확도는 낮아졌다.
UUAS는 구문 분석기의 성능을 평가하는 방법이다. 구문 분석은 문장의 구조를 이해하고, 단어들 사이의 관계를 파악하는 과정이다.
UUAS는 이러한 분석에서 특정 라벨이나 방향성을 고려하는 대신, 단어 쌍 사이의 연결의 정확성만을 평가한다.
예를 들어서 "The cat sat on the mat"이라는 문장이 있을 때,
cat - sat
sat- on
등이 올바르게 연결되었는지를 확인한다.
cat이 주어인지, 목적어인지의 라벨 정보와 cat에서 sat으로의 연결인 지 등의 방향성은 고려하지 않는다.
Syntax -> Meaning
구문 구조가 의미에 어떻게 매핑이 되는것일까?
영어에서는 단어의 순서로 의미를 파악할 수 있다.
우리는 이것을 언어 모델에서 테스트할 수 있다.
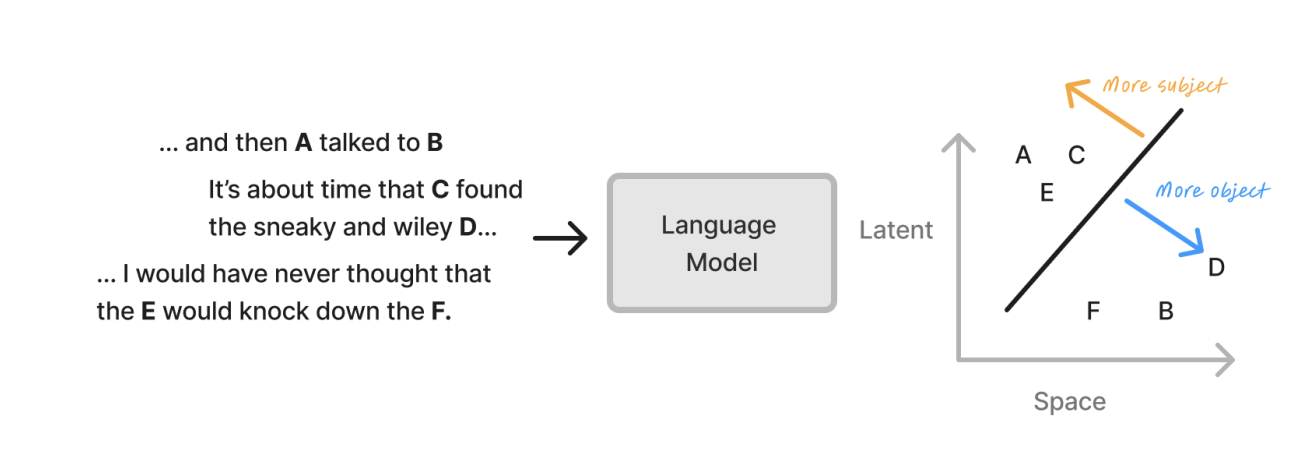
그런데 영어에는 수동태, 능동태가 있다.
같은 의미이지만 단어의 순서가 바뀌는 것이다.
The chef chopped the onion
The onion chopped the chef
이 두 문장은 의미가 동일하지만 순서가 다른 경우이다. 이 경우 다르게 처리해야하는가?
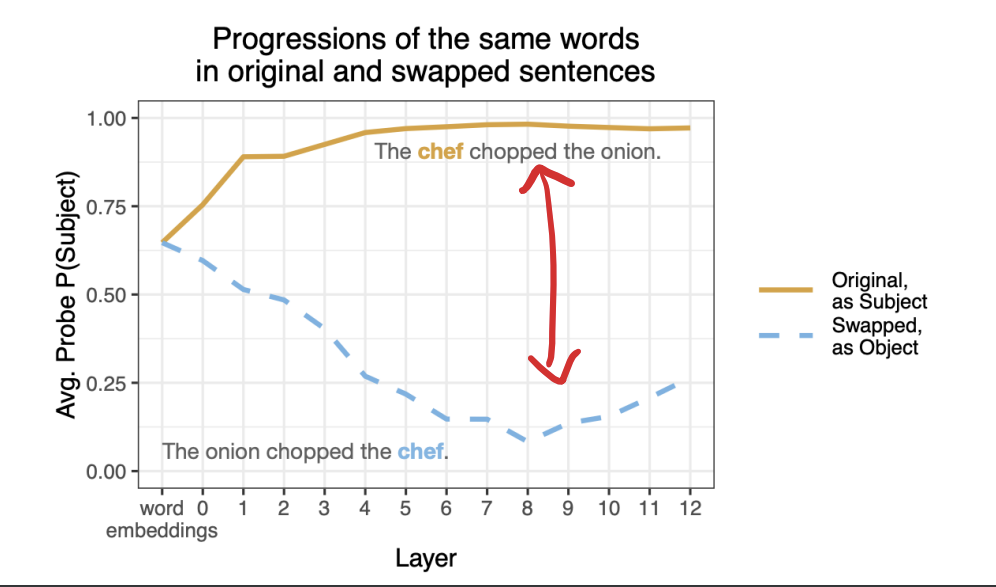
주황색 선을 보면 원래 문장에서 'chef'가 주어로 확률이 매우 뫂게 시작해서 층을 거듭하면서도 높게 유지된다. 모델이 일관되게 'chef'를 주어로 인식하고 있다는 것이다.
파란색 선을 보면 단어 순서가 바뀐 문장에서 구조적으로는 'chef'가 객체로 사용되었지만 초기 층에서는 주어로 인식하고 있다. 하지만 층을 거듭할 수록 'chef'를 주어로 인식할 확률이 감소한다.
언어가 어떻게 작동하는지 절대적인 진리는 없다.
만약 있다면, 우리는 여러 개별적인 규칙을 모두 모아서 완전한 NLP시스템을 만들 수 있을 것이다. (하지만 그렇지 않기 때문에 불가능하다!)
Going beyond pure structure
언어 구조에서 의미는 정말 많은 역할을 한다.
먹다라는 행위를 하는 것은 유사한 단어 ate, devour를 보자.
• I ate a cookie -> I ate
• I devoured a cookie ❌ ->I devoured
쿠키를 먹는 것은 괜찮지만 쿠키를 삼켜버리는 것은 안된다. 의미적으로 쿠키를 삼킬 수 없기 때문이다.
- Time/days/afternoon/harvests?/moons?/❌trees elapsed
elapsed는 무언가가 경과되는 것을 의미한다. 따라서 변화되지 않는 무언가는 elapsed의 주어로 올 수 없다,
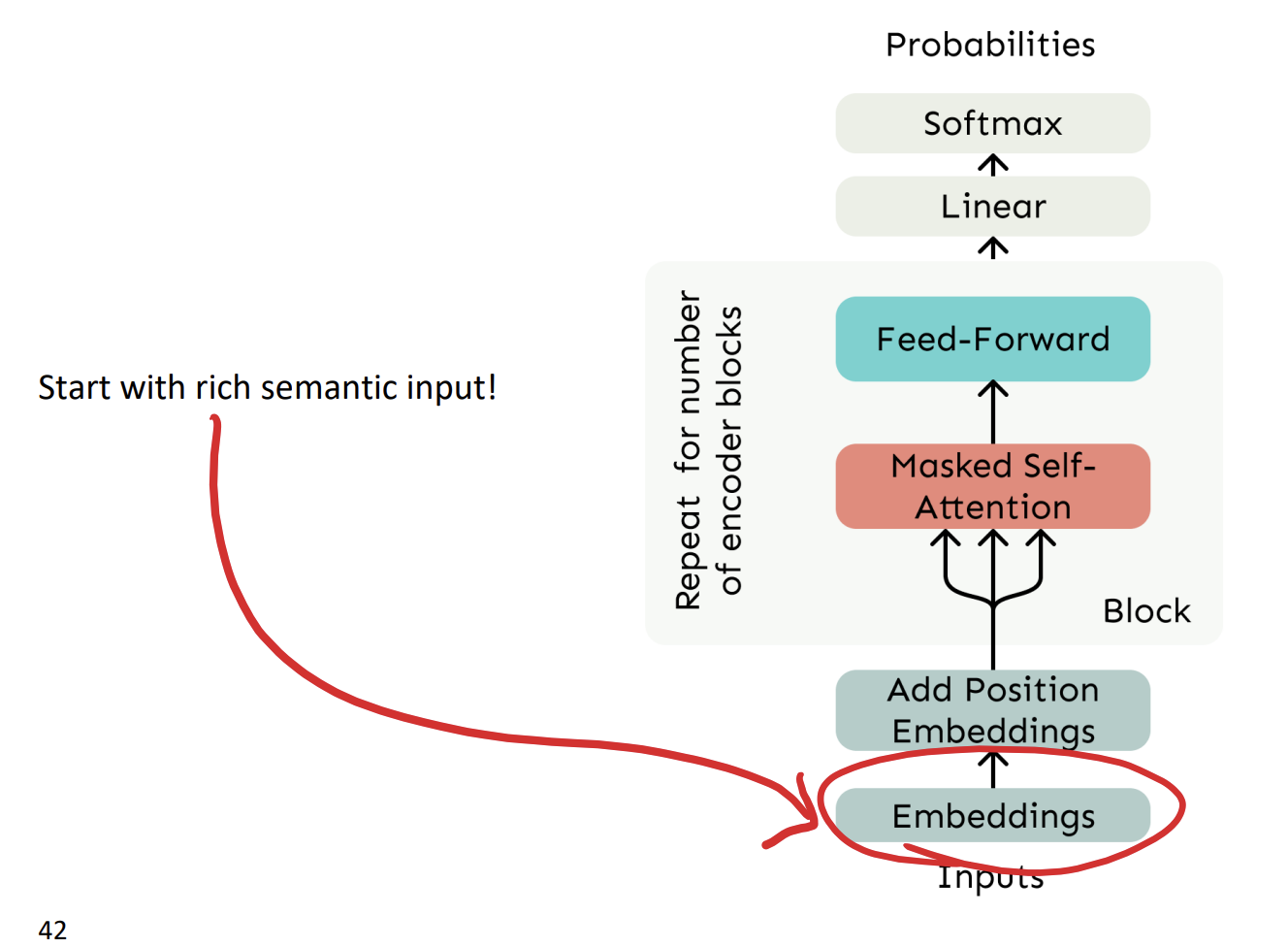
우리의 모델을 훈련하는 방식을 보면 맨 아래에 임베딩을 볼 수 있다.
여기서 우리는 굉장히 풍부한 의미를 가지는 입력값들을 넣는다.
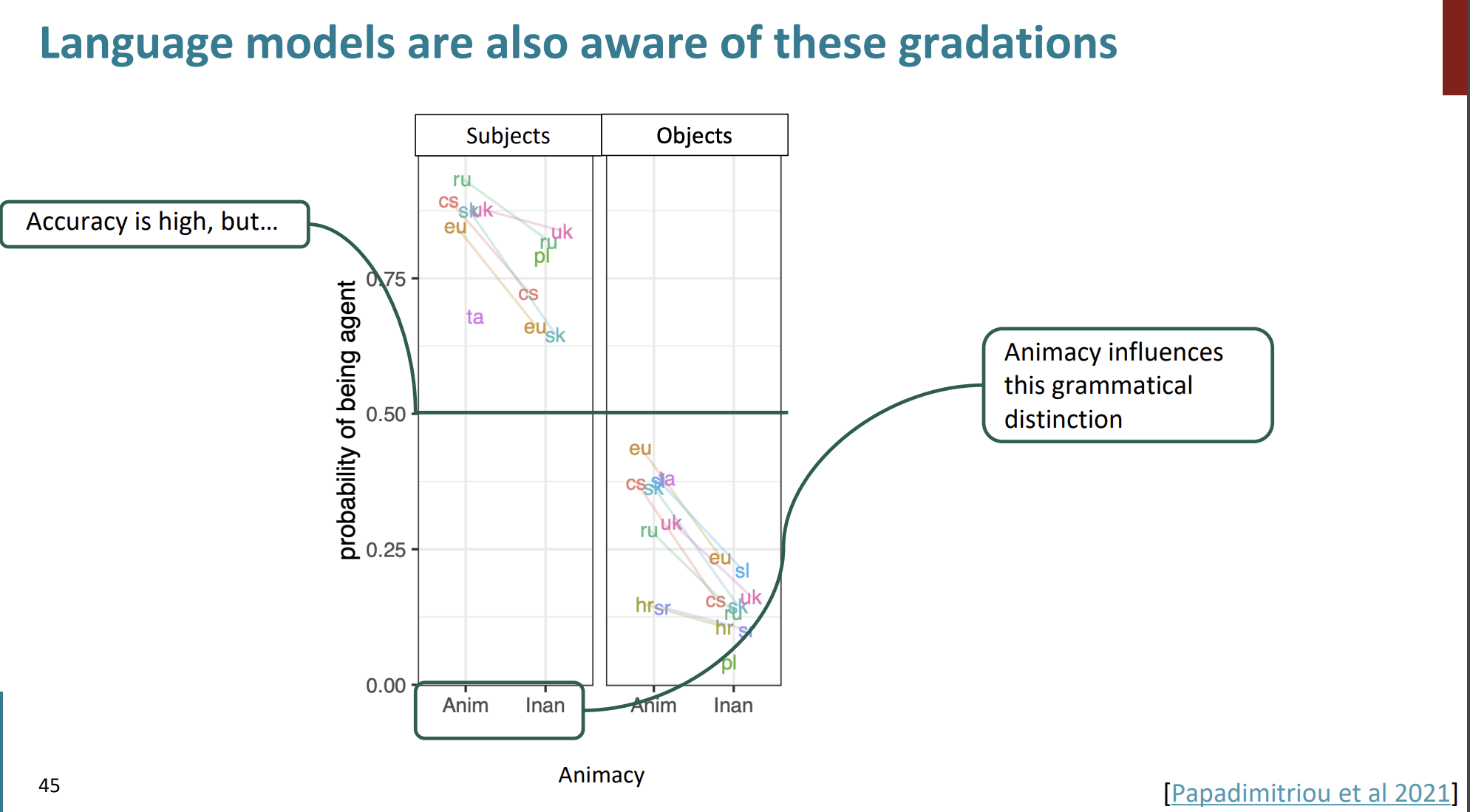
이 그래프를 해석해보자..
Animacy는 '생명력'이라는 의미이다.
생명력은 단어가 생명체인지(사람, 동물) 아니면 무생명체인지(물건, 개념) 등을 의미한다.
x축은 생명력을 나타낸다. 'Anim'은 생명체, 'Inan'은 무생명체이다. y축은 언어모델이 단어를 주체로 인식할 확률을 나타낸다.
이 그래프는 모델이 주어의 역할에 있어서 생명체를 높은 확률로 주어로 인식하는 경향이 있음을 알 수 있다.
하지만 객체의 역할에 있어서는 이러한 확률이 낮아지는 경향을 보였다. 객체에 무생명체가 있는 경우 주체가 무생명체일 확률이 가장 낮았다.
관용어
의미는 항상 개별 단어로만 이루어지지 않는다.
언어는 관용어구가 굉장히 많다.
"don’t count your chickens before they hatch"
직독직해하면 "닭이 부화하기 전에 닭의 수를 세지 말아라" 라는 것인데 이 의미는 '김칫국부터 마시지 마라'라는 의미로 쓰인다.
우리는 구문과 의미만 알고서는 모든 문장을 이해할 수 없다.
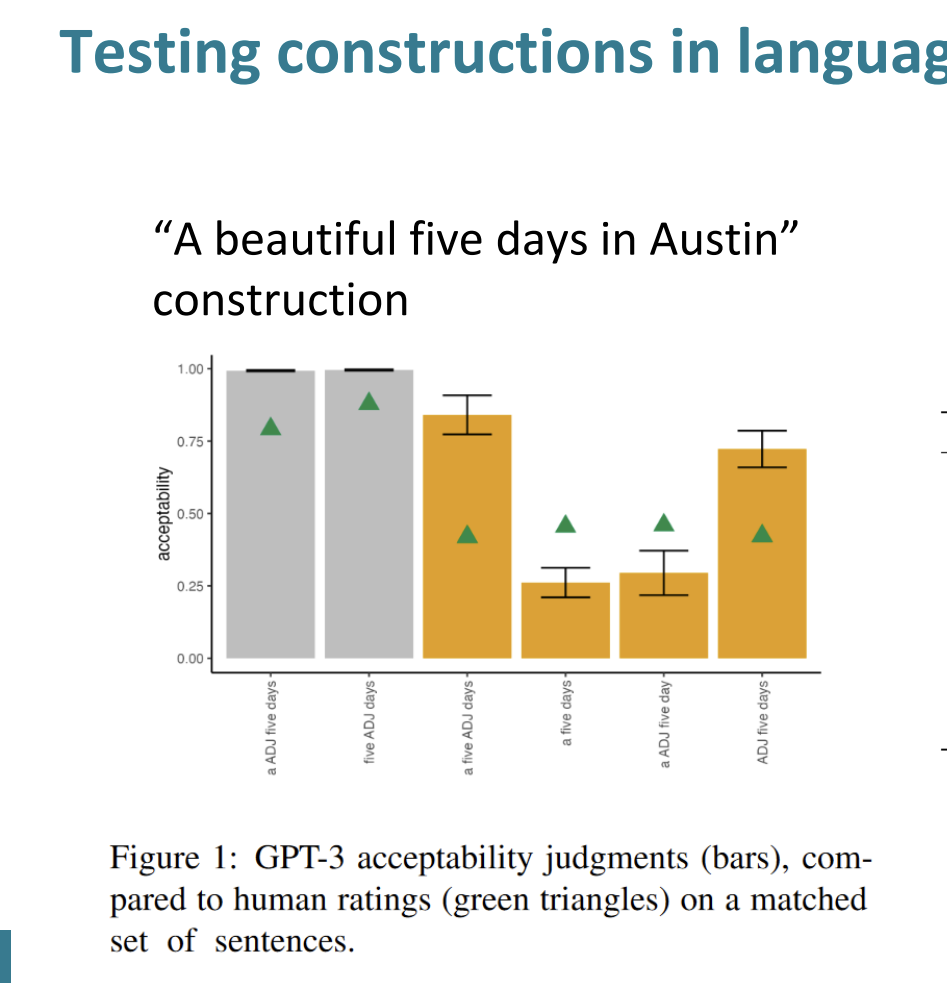
GPT-3의 수용성 판단은 막대그래프, 인간 평가자의 수요ㅛㅇ성 평가는 녹색 삼각형으로 표시했다.
'ADJ'는 형용사, NUM은 숫자, N은 명사를 의미한다.
- "ADJ Num N": "A beautiful five days"와 같이 형용사가 숫자와 명사 앞에 오는 구조이다.
- "Num ADJ N": "Five beautiful days"와 같이 숫자가 형용사 앞에 오는 구조이다.
- "Num N ADJ": "Five days beautiful"와 같이 형용사가 숫자와 명사 뒤에 오는, 비정상적인 구조이다.
- "ADJ N Num": "Beautiful days five"와 같이 숫자가 명사 뒤에 오는, 비정상적인 구조이다.
- "N ADJ Num": "Days beautiful five"와 같이 형용사와 숫자가 명사 뒤에 오는, 비정상적인 구조이다.
그래프를 통해서 GPT-3의 평가와 인간의 평가가 1,2에서 가장 높고 3,4,5에서는 상대적으로 낮았다. 하지만 비정상적인 구문에서 인간의 평가와 GPT의 평가의 차이가 꽤 컸다. 이는 GPT-3는 비정상적인 구문에 대해서 인간 평가와 다르게 평가함을 의미한다.

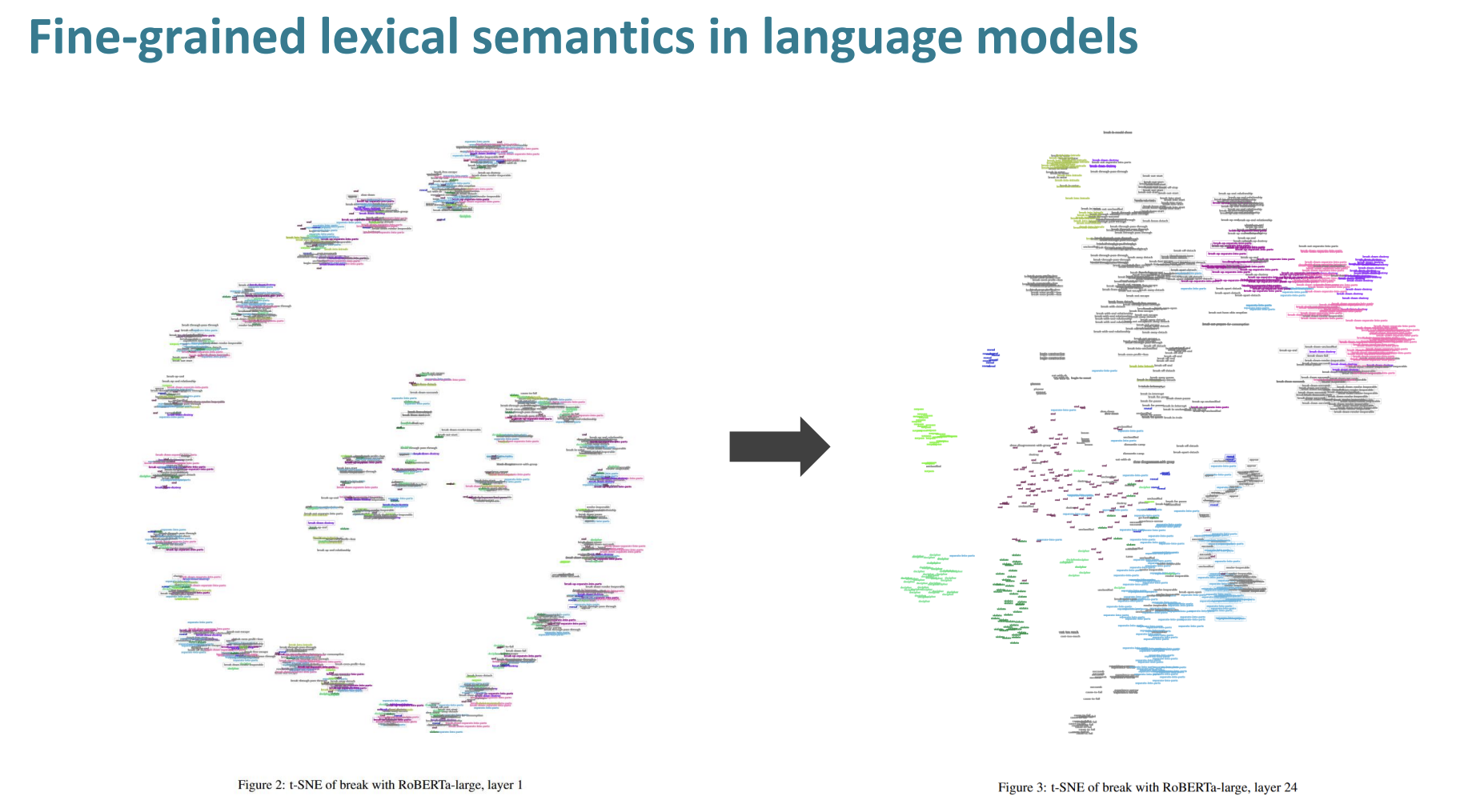
break라는 단어는 일반적으로 "깨다" 라는 의미이지만 다른 단어와 합쳐졌을 때, 다른 의미를 품게 되는 경우도 많다.
좀 더 확대한 그림
->

t-SNE을 이용해서 break의 의미를 RoBERT를 활용해 쪼갤 수 있었다. 초기의 층에서는 의미가 한군데 뭉쳐 있는 방면 24층에서는 의미 별로 어휘를 모을 수 있었다.
언어는 매우 추상적인 시스템이라는 특징을 가지고 있다.
그리고 우리는 모델이 이를 포착하길 바란다.
하지만 의미는 매우 다양하고 풍부하고 다면적이다.
현재의 딥러닝은 아주 표면적인 부분의 암기와 추상화 정도만 할 수 있다고 한다. 그리고 많은 분석과 해석 가능성 연구를 진행하고 있다.
Multilinguality in NLP
언어는 매우 다양하다.
세계에는 7000개의 언어가 있다.
하지만 우리는 모든 언어에 대한 데이터가 풍부하게 있지 않다.
리소스가 풍부한 언어도 있는 반면에, 한국어처럼 자료가 풍부하지 않은 경우가 있다.
이러한 경우 어떻게 자연어처리를 할 수 있을 까?
우리는 'Pretrained'된 언어 모델을 가지고 있다.
그들을 우리는 transfer learning을 할 수 있다.
우리는 언어를 두가지 시각으로 관찰하려고 한다.
첫번째는 Language typoloy 이고 두번째는 Language universals이다.
Language typoloy
언어를 몇가지 방법으로 나눌 수 있다.
일단 Coding of Evidentiality로 나눌 수 있다.

또는 주어 동사 목적어로 나눌 수 있다.
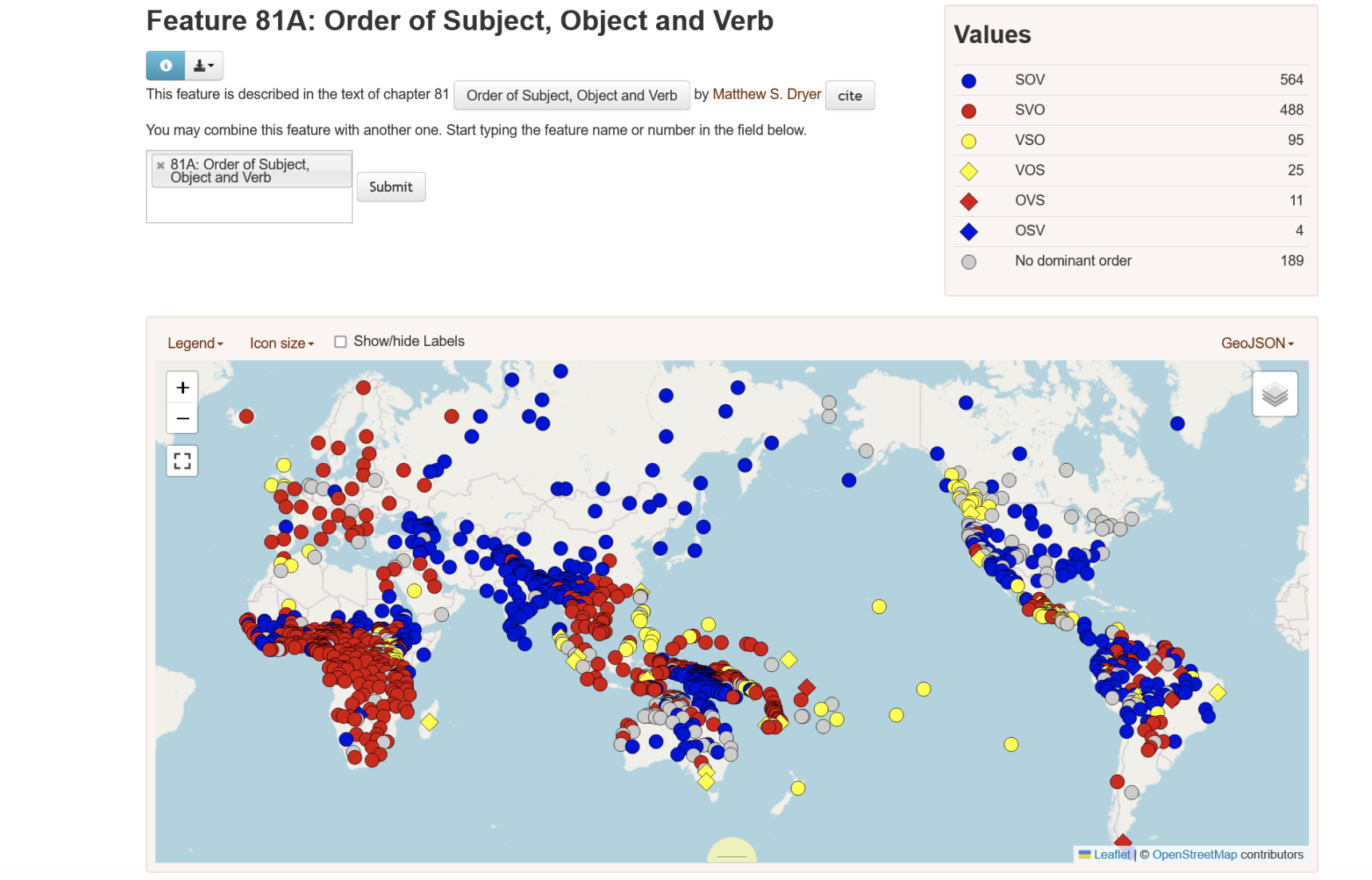
이렇게 언어가 다양한 만큼, 우리가 생각하는 방식과 전혀 다른 방식으로 언어가 구성될 수 있다는 것을 알아야한다.
Language universals
-
그럼 모든 문법에 해당하는 보편적인 문법이 존재할 까?
-
NLP관점에서는 모든 언어는 주어와 목적어, 동사 등의 관계가 존재한다고 믿는것이 수월하다.
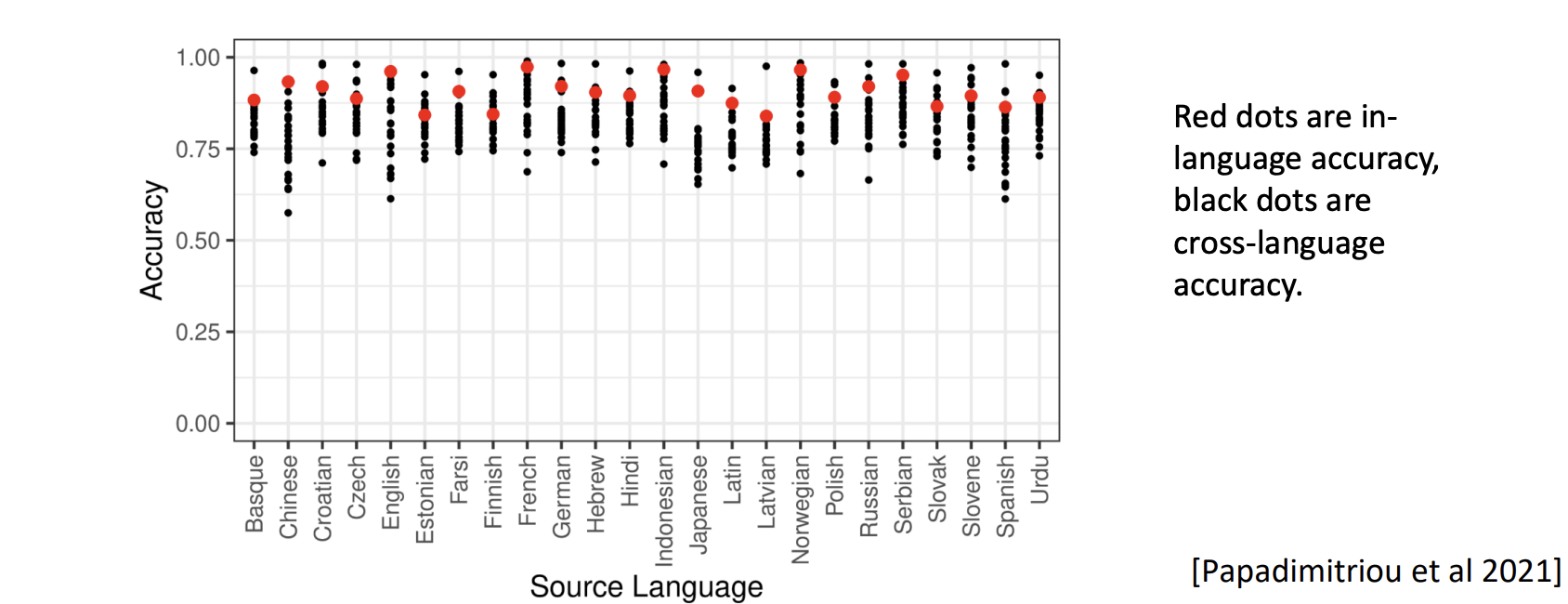
위 그래프에서 빨간점은 현재 언어의 정확성을 나타내고 검은 점들은 다른 언어들의 정확성을 나타낸다.
다중 언어 모델을 선택하고 하나의 언어로만 훈련시킨다.
훈련된 언어 그 자체로는 좋은 성능을 가지지만 다른 언어로는 좋지 않은 성능을 가진다.
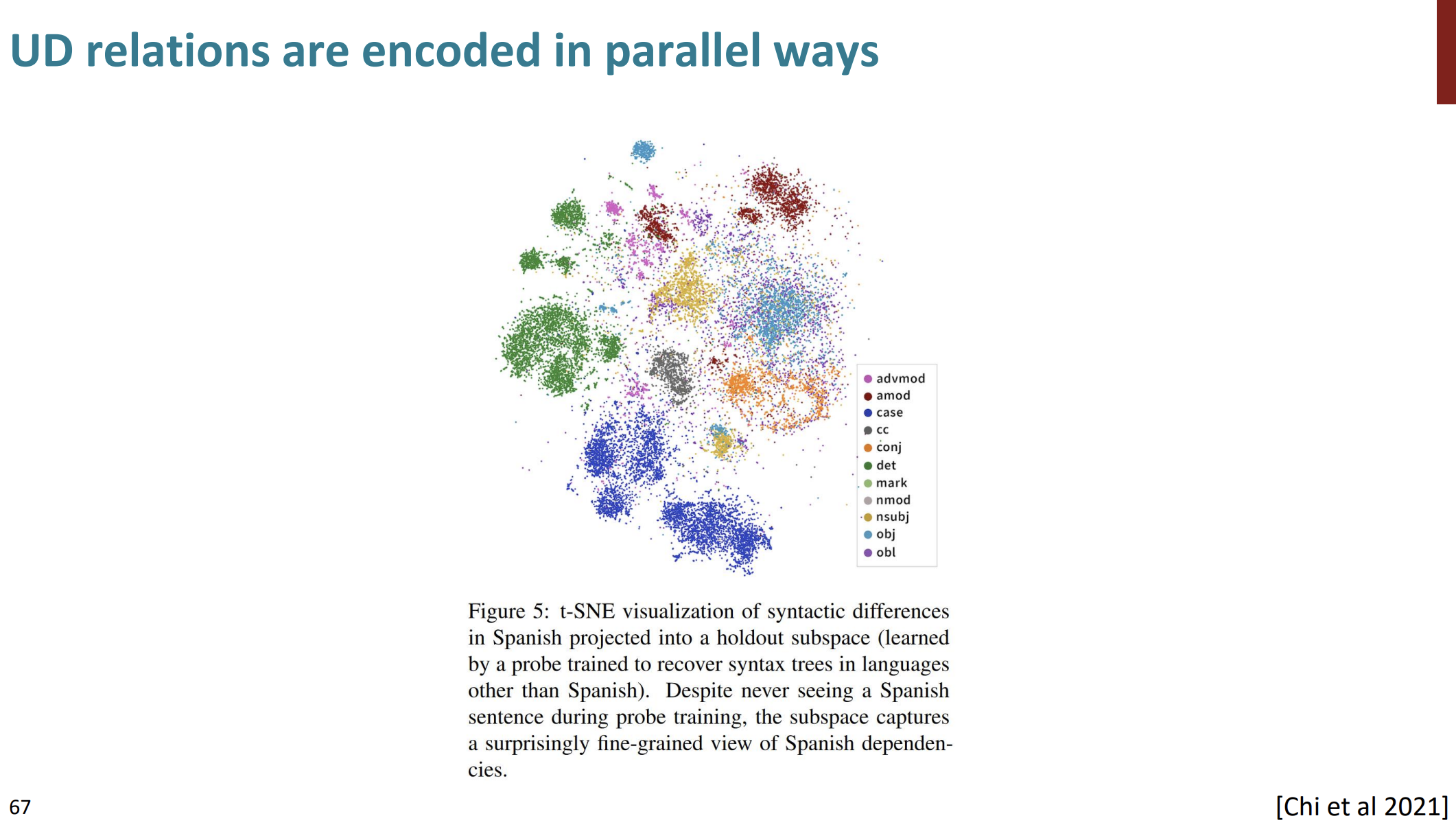
색상이 함께 모여있다.
한 언어에 대해 parser를 훈련하거나 분류를 구문 분석하고 이를 다른 언어로 전송하면 다른 언어에 대해서 클러스터가 형성된다.
t-SNE을 사용하여 스페인어의 구문적 차이를 나타낸다.
점들은 각기 다른 구문적 역할을 하는 요소들을 대표한다.
예를 들어 det은 한정사(Determiner), nsuj는 명사주어(Nomininal subject)를 의미한다.
이러한 구분은 스페인어 문장의 각 요소들이 어떻게 다른 요소들과 관계를 맺고 있는지 나타낸다.
스페인어 문장을 한번도 훈련 하는 동안 보지 않았지만 스페인어 의존 관계의 미세한 차이를 나타내고 있다.
Less parameter-sharing in multilingual models
-
AfriBERTa: 아프리카 언어에만 언어 모델을 학습. 따라서 많은 파라미터가 필요하지 않다. 적은 데이터에도 문제가 없다.
-
XLM-V : 굳이 우리가 단어장을 sharing해야하는가? 그냥 합치자~ 엄청 많은 단어(100만) 를 사용하자. cross-lingual 평가에 대해 더 좋은 성능을 가진다.
다국어 NLP는 방언에 대해서 어떻게 처리하는가?
딥러닝에서는 어떻게 처리해야하는가?
누가 언어를 번역하는가?
원래의 언어에 대해서는 어떻게 처리해야한는가?
등등 다국어 딥러닝은 매우 많은 문제점을 아직도 가지고 있다.
언어학적 통찰은 대규모 언어 모델을 이해하는데 중요한 역할을 가진다.
지금까지 딥러닝 NLP와 언어학 사이에서의 여러 통찰들에 대해 살펴보았다.
이번강의는 여기까지!
