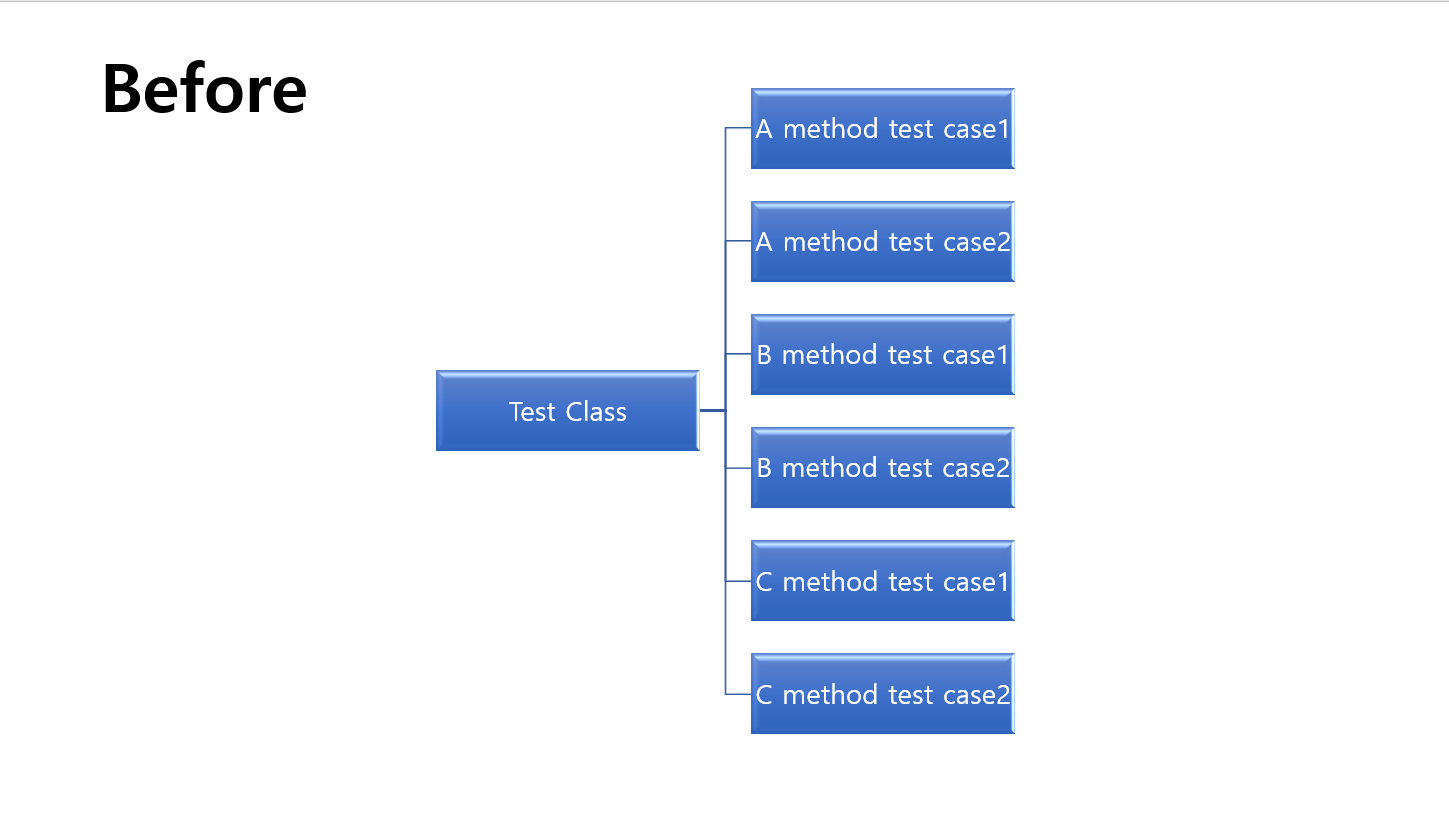
기존 테스트 코드 문제점
테스트 코드의 코드 수를 줄이기 위해 given을 전역 상태로 만들어서 테스트를 수행했다.
https://github.com/Almondia/meca-backend/commit/084fb5fa72c14e6657e49e754506c9d5c75a2529
그러나 주어진 데이터를 공통으로 사용하는 방법은 test 코드에서 given 빠지고 when과 결과만을 판독하기 떄문에 테스트 메서드 내부의 코드의 길이는 짧아졌지만 오히려 그 때문에 여럿 문제가 발생했다.
1. 모든 테스트 코드를 만족하기 위한 테스트 데이터는 가독성을 떨어뜨린다
unit test 마다 다양한 상황이 존재할 수 있다. 이에 맞는 데이터를 전부 고려해서 설계해야 하기 때문에 given에 주어지는 데이터가 무거워진다.
private void inputCategoryData() {
List<Category> categories = List.of(
Category.builder()
.categoryId(categoryIds.get(0))
.memberId(memberId)
.createdAt(LocalDateTime.now())
.modifiedAt(LocalDateTime.now())
.title(new Title("btitle1")).build(),
Category.builder()
.categoryId(categoryIds.get(1))
.memberId(memberId)
.createdAt(LocalDateTime.now().plusHours(4))
.modifiedAt(LocalDateTime.now().plusHours(4))
.title(new Title("atitle2")).build(),
Category.builder()
.categoryId(categoryIds.get(2))
.memberId(memberId)
.createdAt(LocalDateTime.now().plusHours(2))
.modifiedAt(LocalDateTime.now().plusHours(2))
.title(new Title("ctitle")).build(),
Category.builder()
.categoryId(categoryIds.get(3))
.memberId(memberId)
.createdAt(LocalDateTime.now().plusHours(3))
.modifiedAt(LocalDateTime.now().plusHours(3))
.title(new Title("dTitle"))
.isShared(true).build());
categoryRepository.saveAllAndFlush(categories);
} private void inputCardData() {
List<Card> cards = List.of(
OxCard.builder()
.cardId(cardIds.get(0))
.title(new com.almondia.meca.card.domain.vo.Title("title"))
.categoryId(categoryIds.get(0))
.cardType(CardType.OX_QUIZ)
.isDeleted(false)
.memberId(memberId)
.question(new Question("question"))
.oxAnswer(OxAnswer.O)
.build(),
OxCard.builder()
.cardId(cardIds.get(1))
.title(new com.almondia.meca.card.domain.vo.Title("title"))
.categoryId(categoryIds.get(0))
.cardType(CardType.OX_QUIZ)
.isDeleted(false)
.memberId(memberId)
.question(new Question("question"))
.oxAnswer(OxAnswer.O)
.build(),
OxCard.builder()
.cardId(cardIds.get(2))
.title(new com.almondia.meca.card.domain.vo.Title("title"))
.categoryId(categoryIds.get(1))
.cardType(CardType.OX_QUIZ)
.isDeleted(false)
.memberId(memberId)
.question(new Question("question"))
.oxAnswer(OxAnswer.O)
.build(),
OxCard.builder()
.cardId(cardIds.get(3))
.title(new com.almondia.meca.card.domain.vo.Title("title"))
.categoryId(categoryIds.get(1))
.cardType(CardType.OX_QUIZ)
.isDeleted(false)
.memberId(memberId)
.question(new Question("question"))
.oxAnswer(OxAnswer.O)
.build(),
OxCard.builder()
.cardId(cardIds.get(4))
.title(new com.almondia.meca.card.domain.vo.Title("title"))
.categoryId(categoryIds.get(2))
.cardType(CardType.OX_QUIZ)
.isDeleted(false)
.memberId(memberId)
.question(new Question("question"))
.oxAnswer(OxAnswer.O)
.build()
);
cardRepository.saveAll(cards);
}위의 코드의 데이터가 작성되지만 주어진 데이터 코드가 무엇을 의미하는 지는 쉽게 이해하기 쉽지 않다. 이 때문에 매번 테스트 코드를 추가하거나 작성할 때 데이터 생성 코드에 데이터를 추가해야 하며 추가할 때 마다 특수한 상황이 만들어지는 지에 대한 검증이 또한 필요하다. 그리고 테스트가 많아지면 자연스레 생성 데이터 코드에 대한 이해가 힘들어진다. 이는 생산성을 저하시킨다.
2. 저하된 생산성으로 인해 테스트를 대충 작성하게 된다
@Test
void test() {
OffsetPage<CategoryResponseDto> page = categoryRepository.findCategories(
1,
2,
CategorySearchCriteria.builder().build(),
SortOption.of(CategorySortField.TITLE, SortOrder.ASC));
assertThat(page).hasFieldOrPropertyWithValue("pageNumber", 0)
.hasFieldOrPropertyWithValue("totalPages", 1)
.hasFieldOrPropertyWithValue("pageSize", 2)
.hasFieldOrPropertyWithValue("totalElements", 4);
}
@Test
void findCategoryWithStatisticsByMemberIdTest() {
CursorPage<CategoryWithHistoryResponseDto> cursorPage = categoryRepository.findCategoryWithStatisticsByMemberId(
4,
memberId,
null
);
assertThat(cursorPage)
.hasFieldOrProperty("hasNext")
.hasFieldOrProperty("pageSize")
.hasFieldOrProperty("sortOrder");
}주어진 테스트 데이터가 복잡하기 때문에 단순히 querydsl코드가 정상적으로 동작? 컴파일이 정상적으로 이루어지고 테스트가 되는지만 검증한다. 그러나 이러한 코드의 문제점은 쿼리의 결과가 의도적으로 잘 나왔는지 알 수가 없다. 또한 QueryDsl은 동적으로 쿼리를 처리할 수 있는데 이는 입력에 따라 쿼리가 유연하게 변할 수 있다는 것이다. 이에 대한 테스트도 기존의 입력 데이터로는 쉽지 않기 때문에 개선이 필요하다.
테스트 코드 개선하기
Querydsl 코드가 정상적으로 동작한다는 것을 보증하기 위한 단위 테스트는 어떻게 수행할 수 있을까?
현재의 문제점은 공통된 given 데이터 코드의 크기가 커짐에 따라 테스트를 파악하기 어렵고 테스트가 까다로워지는 점이다. 이를 해결하기 위해 몇가지 방법을 고안했다.
1. Nested class 를 활용해 테스트의 depth를 늘린다
junit에는 @Nested 어노테이션을 이용해 같은 테스트 클래스 코드 내에서도 특징 별로 코드 환경을 분리할 수 있다는 장점이 있다. 이를 활용해 메서드별 테스트 코드를 분리했다.
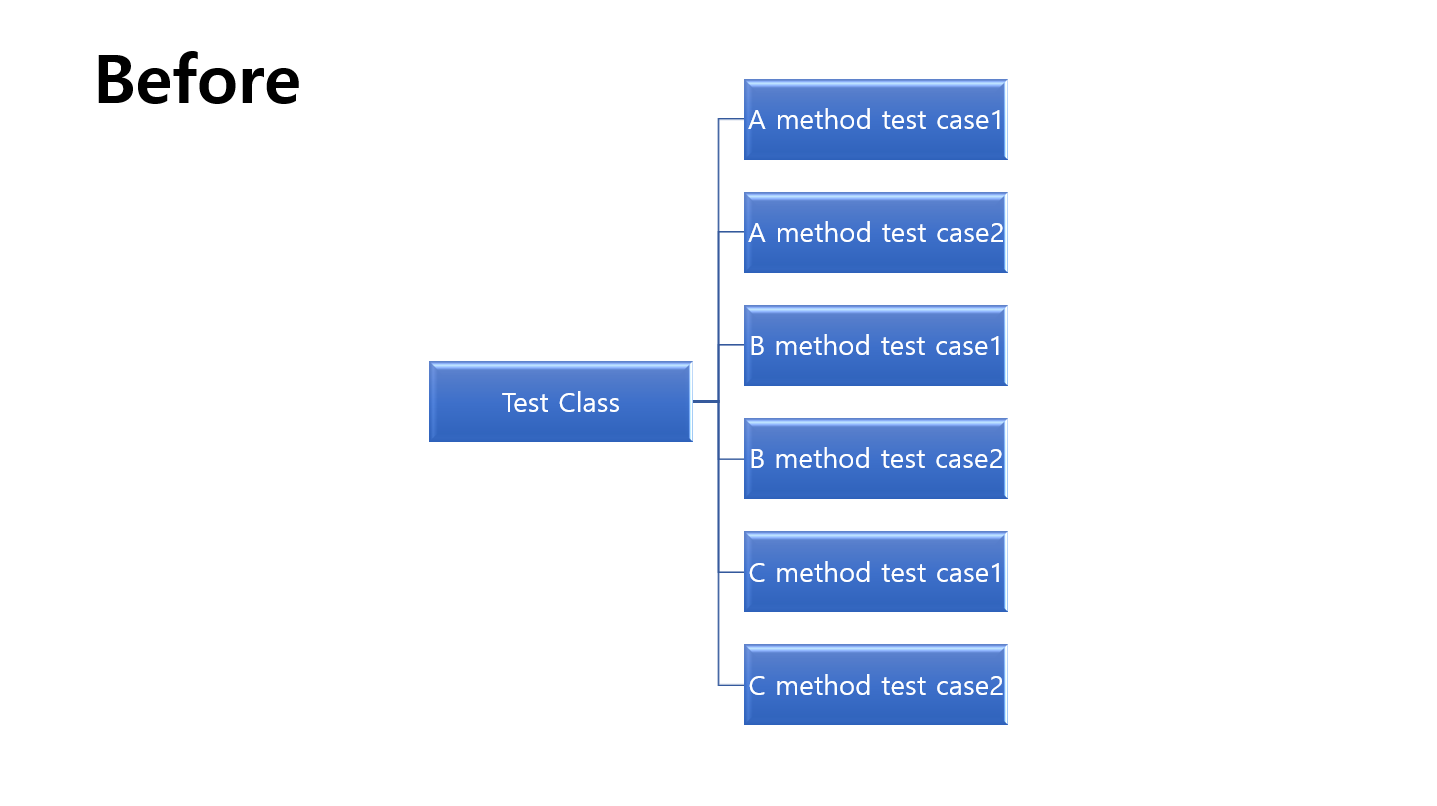
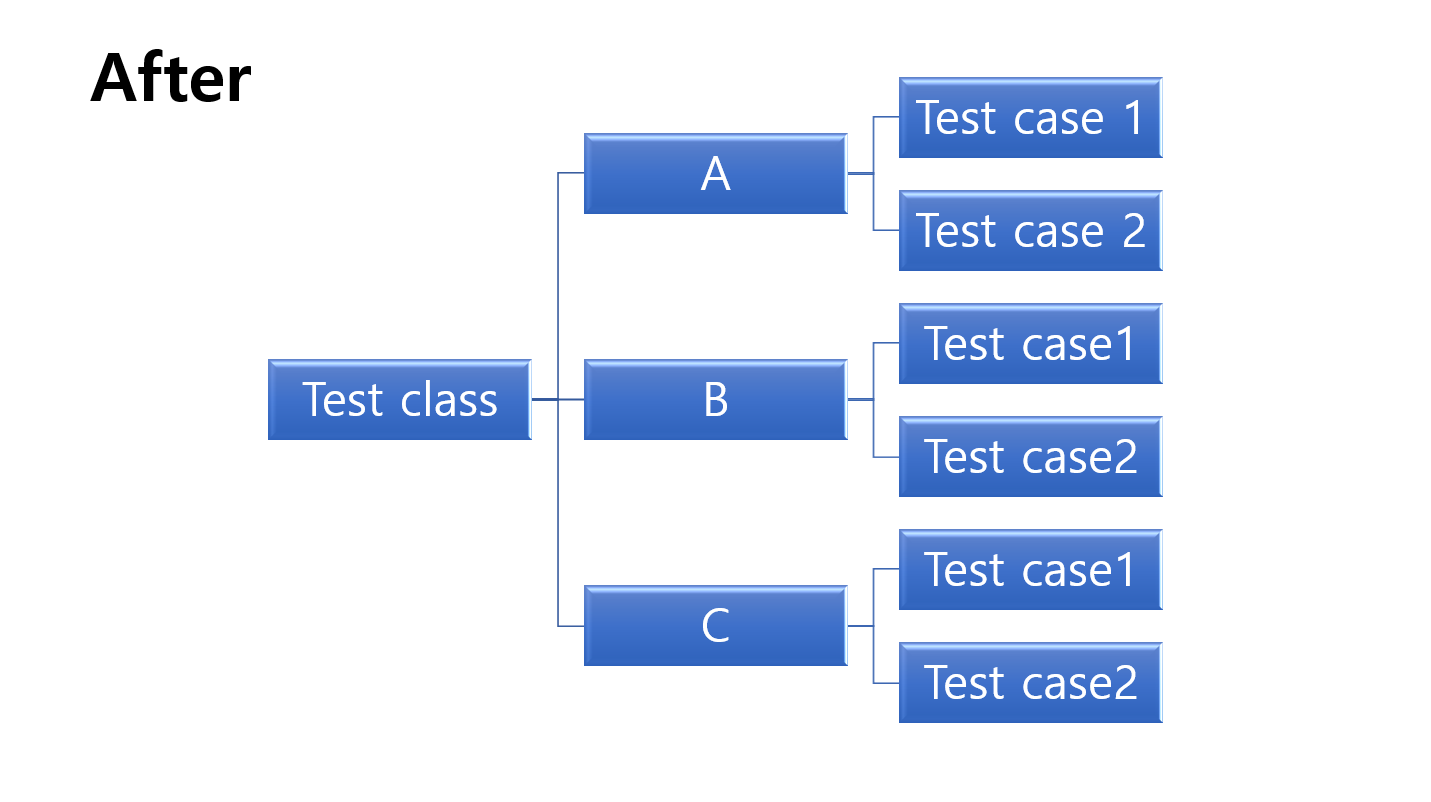
계층형 그림을 보면 After의 경우 환경 세팅을 nested class 별로 분리할 수 있어서 환경을 독립적이고 쉽게 구성할 수 있다. 그리고 테스트 코드가 커질수록 After의 방식이 훨씬 코드 구조 파악이 쉽다. 물론 개인차가 존재하겠지만 쉽다고 한 이유는 2번째 해결방안에서 자세히 설명하겠다.
2. 테스트 케이스 목록을 미리 작성하기
@Nested를 활용한 이유는 테스트 케이스 목록을 작성하면서 효율적인 방식이 필요했기 때문이다. 테스트 코드를 한눈에 보기 위해 테스트 케이스목록을 클래스 상단에 주석으로 작성했는데 만약 nested가 없다면 아래와 같이 코드를 작성해야 한다.
/**
* #### findCategoryWithStatisticsByMemberId
* 1. 카테고리가 없는 경우 contents가 비어있어야 함
* 2. 카테고리가 있는 경우 contents가 있어야 함
* 3. 카테고리가 있는 경우, pageSize가 0인 경우 contents가 비어 있어야 함
* 4. 조회후 다음 페이징 index가 있는 경우 hasNext에 다음 카테고리 id가 존재해야 함
* 5. 조회후 다음 페이징 index가 없는 경우 hasNext에 null이 존재해야 함
* 6. 조회후 pageSize보다 적은 카테고리를 조회한 경우 hasNext는 null이어야 함
* 7. share가 true인 카테고리는 조회하면 안된다
* 8. lastCategoryId를 입력받은 경우, lastCategoryId보다 작은 카테고리는 조회하지 않는다
* #### findCategoryShared
* 1. 카테고리가 없는 경우 contents가 비어있어야 함
* 2. 카테고리가 있는 경우 contents가 있어야 함
* 3. 카테고리가 있는 경우, pageSize가 0인 경우 contents가 비어 있어야 함
* 4. 조회후 다음 페이징 index가 있는 경우 hasNext에 다음 카테고리 id가 존재해야 함
* 5. 조회후 다음 페이징 index가 없는 경우 hasNext에 null이 존재해야 함
* 6. shared가 false인 카테고리는 조회하면 안된다
*/
@DataJpaTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
@Import(QueryDslConfiguration.class)
class CategoryQueryDslRepositoryImplTest {
@Autowired
CategoryRepository categoryRepository;
@Autowired
EntityManager em;
// ...
}nested를 활용하면 다음과 같이 코드를 짤 수 있다.
@DataJpaTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
@Import(QueryDslConfiguration.class)
class CategoryQueryDslRepositoryImplTest {
@Autowired
CategoryRepository categoryRepository;
@Autowired
EntityManager em;
/**
* 1. 카테고리가 없는 경우 contents가 비어있어야 함
* 2. 카테고리가 있는 경우 contents가 있어야 함
* 3. 카테고리가 있는 경우, pageSize가 0인 경우 contents가 비어 있어야 함
* 4. 조회후 다음 페이징 index가 있는 경우 hasNext에 다음 카테고리 id가 존재해야 함
* 5. 조회후 다음 페이징 index가 없는 경우 hasNext에 null이 존재해야 함
* 6. 조회후 pageSize보다 적은 카테고리를 조회한 경우 hasNext는 null이어야 함
* 7. share가 true인 카테고리는 조회하면 안된다
* 8. lastCategoryId를 입력받은 경우, lastCategoryId보다 작은 카테고리는 조회하지 않는다
*/
@Nested
@DisplayName("findCategoryWithStatisticsByMemberId 메서드 테스트")
class findCategoryWithStatisticsByMemberIdTest {
// ***
}
/**
* 1. 카테고리가 없는 경우 contents가 비어있어야 함
* 2. 카테고리가 있는 경우 contents가 있어야 함
* 3. 카테고리가 있는 경우, pageSize가 0인 경우 contents가 비어 있어야 함
* 4. 조회후 다음 페이징 index가 있는 경우 hasNext에 다음 카테고리 id가 존재해야 함
* 5. 조회후 다음 페이징 index가 없는 경우 hasNext에 null이 존재해야 함
* 6. shared가 false인 카테고리는 조회하면 안된다
*/
@Nested
@DisplayName("findCategoryShared 테스트")
class FindCategorySharedTest {
// ...
}
}취향차이가 있을 수 있지만 개인적으로 환경을 메서드별 테스트시 독립적으로 구성할 수 있다는 점과 필요한 메서드 Test의 클래스 상단에 주석을 활용하는 것이 내게는 조금 더 테스트 코드를 쉽게 이해하고 활용할 수 있었다.
3. given을 테스트 케이스마다 분리해서 작성하되 목적에 맞게 간단히 작성한다
기존 코드의 큰 문제점 중 하나는 테스트 케이스별 given을 하나로 통합해서 공통으로 제공한다는 점이다. 이는 코드의 길이를 줄일 수 있을지 모르지만 코드가 커질수록 이해하기 어렵고 매번 거대한 데이터 케이스를 필요가 없는 곳에서도 매번 실행한다는 단점이 있다. 이는 테스트 시간이 길어지는 문제점이 발생한다.
이를 해결하기 위해 given은 테스트 케이스 목적에 맞게 최대한 간단하게 작성한다. 주로 경계값과 input의 변화에 따른 결과를 테스트한다.
@DataJpaTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
@Import(QueryDslConfiguration.class)
class CategoryQueryDslRepositoryImplTest {
@Autowired
CategoryRepository categoryRepository;
@Autowired
EntityManager em;
/**
* 1. 카테고리가 없는 경우 contents가 비어있어야 함
* 2. 카테고리가 있는 경우 contents가 있어야 함
* 3. 카테고리가 있는 경우, pageSize가 0인 경우 contents가 비어 있어야 함
* 4. 조회후 다음 페이징 index가 있는 경우 hasNext에 다음 카테고리 id가 존재해야 함
* 5. 조회후 다음 페이징 index가 없는 경우 hasNext에 null이 존재해야 함
* 6. 조회후 pageSize보다 적은 카테고리를 조회한 경우 hasNext는 null이어야 함
* 7. share가 true인 카테고리는 조회하면 안된다
* 8. lastCategoryId를 입력받은 경우, lastCategoryId보다 작은 카테고리는 조회하지 않는다
*/
@Nested
@DisplayName("findCategoryWithStatisticsByMemberId 메서드 테스트")
class findCategoryWithStatisticsByMemberIdTest {
@Test
@DisplayName("카테고리가 없는 경우 contents가 비어있어야 함")
void shouldReturnEmptyCursorPageWhenNotExistCategoryTest() {
// given
Id memberId = Id.generateNextId();
Id lastCategoryId = Id.generateNextId();
int pageSize = 10;
// when
CursorPage<CategoryWithHistoryResponseDto> result = categoryRepository.findCategoryWithStatisticsByMemberId(
pageSize,
memberId,
lastCategoryId);
// then
assertThat(result).isNotNull();
assertThat(result.getContents()).isEmpty();
}
@Test
@DisplayName("카테고리가 있는 경우")
void shouldReturnCursorPageWhenExistCategoryTest() {
// given
Id memberId = Id.generateNextId();
Id lastCategoryId = Id.generateNextId();
int pageSize = 10;
em.persist(CategoryTestHelper.generateUnSharedCategory("title", memberId, lastCategoryId));
// when
CursorPage<CategoryWithHistoryResponseDto> result = categoryRepository.findCategoryWithStatisticsByMemberId(
pageSize,
memberId,
lastCategoryId);
// then
assertThat(result).isNotNull();
assertThat(result.getContents()).isNotEmpty();
}
@Test
@DisplayName("카테고리가 있는 경우, pageSize가 0인 경우")
void shouldReturnCursorPageWhenExistCategoryAndPageSizeIsZeroTest() {
// given
Id memberId = Id.generateNextId();
Id lastCategoryId = Id.generateNextId();
int pageSize = 0;
em.persist(CategoryTestHelper.generateUnSharedCategory("title", memberId, lastCategoryId));
// when
CursorPage<CategoryWithHistoryResponseDto> result = categoryRepository.findCategoryWithStatisticsByMemberId(
pageSize,
memberId,
lastCategoryId);
// then
assertThat(result).isNotNull();
assertThat(result.getContents()).isEmpty();
}
}
}코드 라인은 길어졌지만 오히려 가독성은 증가했다. 이를 보면 꼭 코드 라인을 줄이는 것이 반드시 코드의 가독성을 높이는 것은 아니라는 점을 깨달았다.
4. 테스트 전용 정적 팩토리 클래스를 만든다
@Test
@DisplayName("카테고리가 있는 경우")
void shouldReturnCursorPageWhenExistCategoryTest() {
// given
Id memberId = Id.generateNextId();
Id lastCategoryId = Id.generateNextId();
int pageSize = 10;
em.persist(CategoryTestHelper.generateUnSharedCategory("title", memberId, lastCategoryId));
// when
CursorPage<CategoryWithHistoryResponseDto> result = categoryRepository.findCategoryWithStatisticsByMemberId(
pageSize,
memberId,
lastCategoryId);
// then
assertThat(result).isNotNull();
assertThat(result.getContents()).isNotEmpty();
}위에 테스트 코드를 살펴보면 persist 과정에서 CategoryTestHelper.generateUnSharedCategory 메서드를 호출한 것을 볼 수 있다. 보통 엔티티의 경우 db에 저장하기 위해 여러 속성을 가지는 데 해당 인스턴스를 효과적으로 생성하기 위해 builder 패턴을 사용한다. 그러나 builder 패턴의 경우 코드를 너무 길게 만드는 단점이 있다. 이를 개선하기 위해 정적 팩토리를 활용한다.
public class CategoryTestHelper {
public static Category generateUnSharedCategory(String title, Id memberId, Id categoryId) {
return Category.builder()
.categoryId(categoryId)
.memberId(memberId)
.title(Title.of(title))
.isDeleted(false)
.isShared(false)
.createdAt(LocalDateTime.now())
.modifiedAt(LocalDateTime.now())
.build();
}
public static Category generateSharedCategory(String title, Id memberId, Id categoryId) {
return Category.builder()
.categoryId(categoryId)
.memberId(memberId)
.title(Title.of(title))
.isDeleted(false)
.isShared(true)
.createdAt(LocalDateTime.now())
.modifiedAt(LocalDateTime.now())
.build();
}
}정적 팩토리로 분리된 코드를 보면 몇가지는 공통으로 생성하고 필요한 부분을 인자로 받아서 인스턴스를 생성한다. 해당 코드의 장점은 메서드를 통해 어떤 인스턴스를 만드는지 의도를 좀 더 쉽고 명확하게 알 수 있다는 점이다.
엔티티 인스턴스 생성 로직을 클래스를 통해 분리함으로써 코드 라인을 줄이고 가독성을 높일 수 있다.
개선한 코드를 통해 얻은 경험
테스트 코드를 nested를 이용해 분리하고 테스트 목록을 작성하면서 쿼리에서 공유가 false인 데이터를 조회해야하는 쿼리에서 공유가 true인 데이터도 조회하는 문제가 발생했다. 이를 postman을 이용한 통합 테스트에서는 파악하지 못했는데 코드의 가독성과 given 분리로 인해 코드 생산성이 향상되면서 테스트 케이스를 보다 자세히 작성하다 보니 발견할 수 있었던 것 같다.
