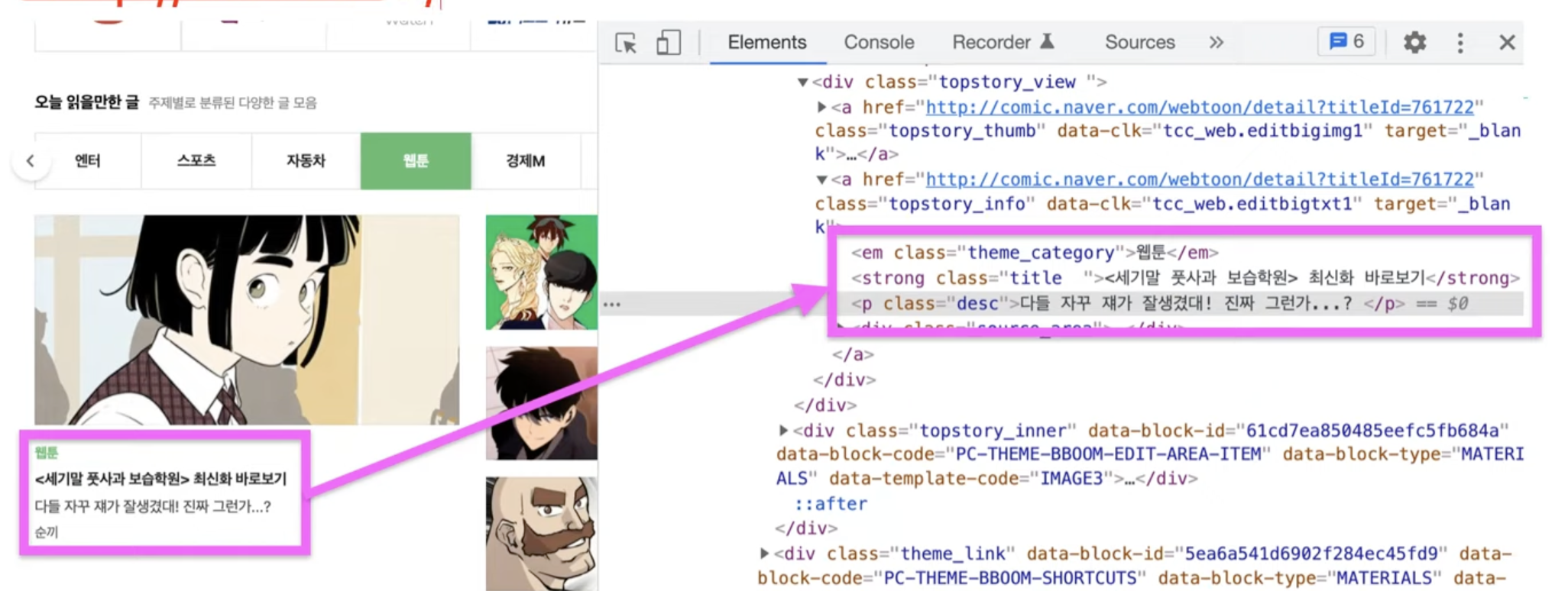
페이지에 접속해서 html 코드를 가져오면 원하는 요소를 찾아낼 수 있다. (인기검색어 등)
쉽게 해주는 라이브러리를 이용할 수 있다.
브라우저는 백엔드에 HTTP 통신을 해서 데이터를 받아온다.
HTTP는 Hyper Text transfer protocol로, 텍스트 데이터 또는 하이퍼 텍스트(HTML)를 전송하는 길이다.
즉, 백엔드에서 만들어둔 API를 통해서 데이터뿐만이 아니라 HTML도 주고받을 수 있다.
(주소를 입력하면 된당)
터미널에서 curl을 이용해서 html 파일 받아오기
curl 주소: rest api의 get방식 (get 생략 가능)curl -XPOST 주소: post방식

👇🏻
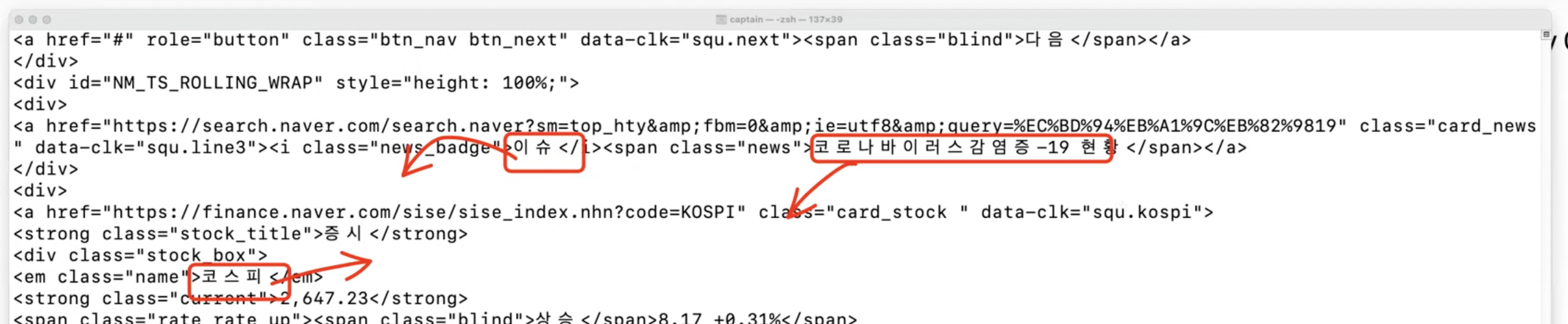
postman에서도 같은 결과가 나온다. (=> axios로도 가능하다는 뜻!)
Scraping
- 한번 가져오기
- 라이브러리 : [Cheerio]
Crawling
- 정기적으로 계속해서 가져오기
- 라이브러리 : [Puppeteer]
API를 요청하면 Text data, HTML, JSON data 등을 받아올 수 있다.
JSON을 쓰기 이전에는 XML을 사용했다. (XML: Extensible Markup Language 확장 가능한 마크업 언어)
JSON이 더 편하고 용량도 적다.
JSX: JavaScript XML (XML에서 파생됨)
OpenGraph
-
미리보기에 사용된다.
-
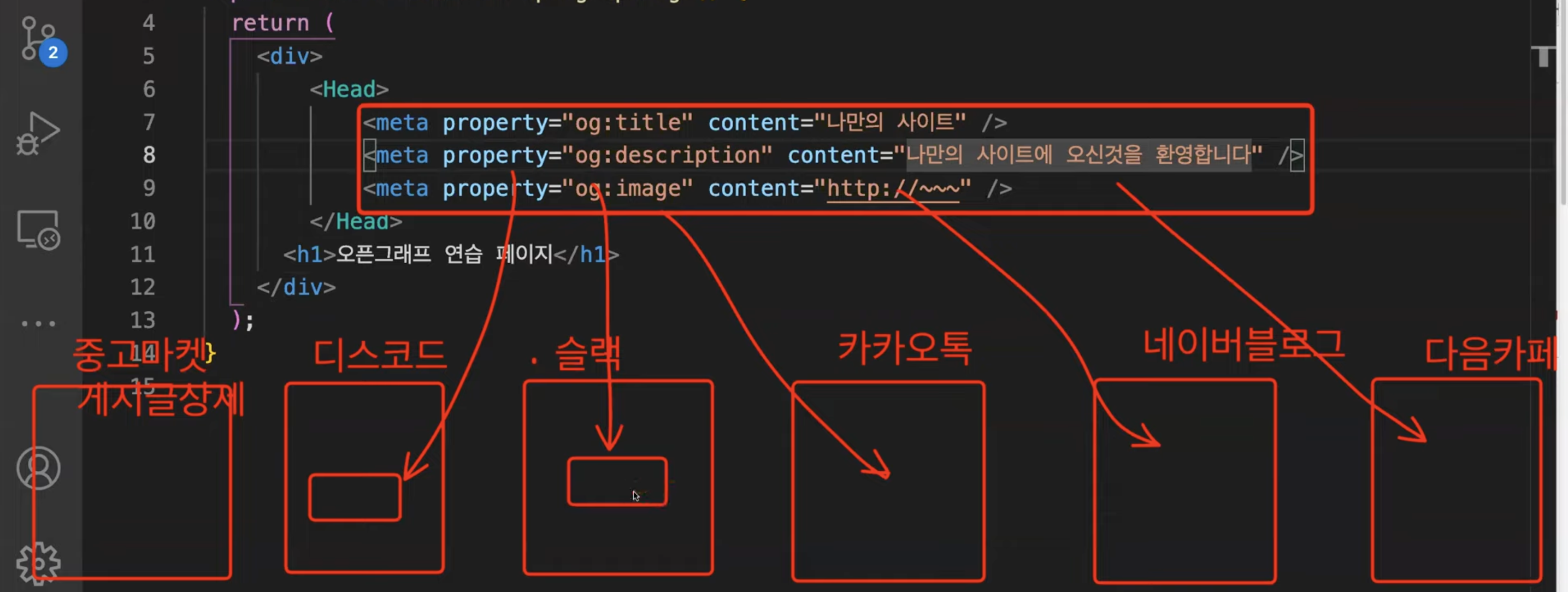
미리보기가 그려질 각 서비스에서 스크래핑해서 찾아서 기능을 구현해놔야 미리보기가 보여진다.
-
페이지마다 다르게 적용할 수도 있다.
-
html의 기능이 아닌, 개발자들 간의 약속이다. => 스크래핑 해서 찾아야 한다.
(facebook에서 최초로 만든 것이 퍼진 것이다. 트위터는 og 대신 twitter로 작성한다.) -
미리보기 구현하는 방법
제공하는 입장: og 태그를 만들어놔야 한다.
제공받는 입장: 스크래핑을 해서 og가 있는지 찾고, og가 없으면 twitter가 있는지 찾아서 미리보기를 보여준다. -
이 작업은 주로 백엔드에서 이루어진다. (CORS를 허용하지 않은 페이지는 브라우저에서 접근이 불가능하기 때문!)
제공하는 입장
- 네이버, 다음, 쿠팡
import Head from "next/head";
~~~
<Head>
<meta property="og:title" content="나만의 사이트" />
<meta property="og:description" content="나만의 사이트에 오신 것을 환영합니다" />
<meta property="og:image" content="http://" />
</Head>제공 받는 입장
- 디코, 카카오톡, 슬랙 등

import axios from "axios";
export default function OpenGraphPreviewPage() {
const onClickOpenGraph = async () => {
const result = await axios.get("https://www.gmarket.co.kr");
console.log(
result.data.split("<meta").filter((el: string) => el.includes("og:title")) // 요런식으로 끄내면 된다잉
);
};
return (
<div>
<h1>사이트 미리보기 연습</h1>
<button onClick={onClickOpenGraph}>미리보기 실행</button>
</div>
);
}네이버의 og

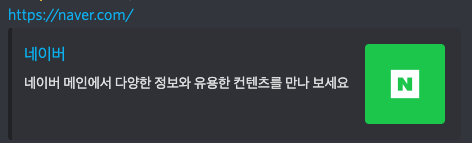
Server Side Rendering
og 동적으로 만들기
dynamic routing된 페이지는 데이터가 매번 바뀌어 내용을 알 수 없으므로 하드코딩이 불가능하다.
👇🏻 그럼 데이터를 받아서 넣어보면 어떨까?

❌ 이렇게 동적으로 값을 바꾸는 것은 불가능하다.
meta 태그에 동적인 값을 넣으면 console에서는 데이터가 잘 출력이되지만,
Postman에서 해당 페이지를 요청했을 때, content가 비어있다!!!

💡 Why?
HTML이 브라우저에 먼저 그려지고 나서, 2차적으로 useQuery등을 통해 데이터를 추가로 다시 받아와서 리렌더링을 통해 내용을 채워서 보여준다.
(데이터를 console에 출력하면 처음에는 undefined가 뜨다가 나중에 또 요청해서 데이터를 출력한다.)
브라우저와 다르게
axios, curl, postman 등은 이 작업은 동일하게 진행되는데, 처음에 데이터를 받아오고 나서 useQuery 등을 추가로 하지는 않기 때문에 값이 빈 상태로 유지된다.
스크래핑 단계에서는 처음에 그려지는 빈 내용의 html만 받아온다.
따라서 위 사진과 같은 방법으로는 동적으로 og를 만드는 것이 불가능하다.
🤔 그럼 오또캐?!?
처음부터 meta 태그에 내용이 담겨있게 만들어야 한다.
그러기 위해서는 프론트엔드 서버에서 useQuery까지 먼저 해서 보내줘야 한다!
이렇게 서버에서 데이터를 받아와서 그리는 과정을 서버 사이드 렌더링이라고 한다.
리액트만으로는 하기 쵸큼 어렵당.. Next.js 프레임워크는 함수 하나로 이 과정을 쉽게 할 수 있게 도와준다. react 18버전에서는 이게 좀 더 쉬워진다고 하는데 지켜봐야 한다~~
SEO
Search Engine Optimization 검색 엔진 최적화
특정 페이지를 접속해서 스크래핑 해오는 프로그램(크롤러 봇)이 있다.
일회성으로 한번 스크래핑 해오는 것이 아니라 정기적으로 여러번 여러 사이트를 돌아다니면서 axios로 데이터를 가져와서 페이지마다 키워드를 가져와서 저장해놓고, 점수를 매긴다.
데이터가 비어있으면 크롤러봇이 점수를 매길 수가 없어서 검색 엔진에 불리하다ㅜㅜ
검색 엔진에 최적화(SEO)를 하고싶으면,
크롤러가 가져갈 것을 대비해 데이터를 채워줘야 한다.
그렇기 때문에, SSR이 필요하다.
(예외: 구글은 잠깐동안 데이터가 오기를 기다려준다. 어느정도 기다리기는 하지만 가급적으로 SSR을 권장한다.)
모든 페이지가 SSR을 하는 것은 아니다.
상황에 맞게 나눠야 한다.
주로 상세 페이지(게시글 상세, 상품 상세 등)에 SSR이 필요하다.
SSR vs CSR
-
SSR을 하면 서버에서 받아오기 때문에 브라우저가 새로고침 된다.(옛날 방식)
-
Client Side Rendering은 빈 내용을 먼저 보여주고 데이터를 받아오면 보여줘서 페이지 전환 속도가 훨씬 빠르다.
getServerSideProps
export default function OpenGraphProviderSSRPage(props) {
return (
<Head>
<meta property="og:title" content={props?.ssr.name} />
<meta property="og:description" content={props?.ssr.remarks} />
<meta property="og:image" content={props?.ssr.images?.[0]} />
</Head>
);
}
// 함수명 변경 불가능, page에만 작성할 수 있다.
// 페이지 기준으로 SSR을 하기 때문이다. (컴포넌트 기준이 아니다.)
export const getServerSideProps = async () => {
console.log("여기는 서버입니다.");
// 1. 여기서 API 요청
const graphQLClient = new GraphQLClient(
"https://backend10.codebootcamp.co.kr/graphql"
);
const result = await graphQLClient.request(FETCH_USEDITEM, {
useditemId: "639a8202531bd200286b7839",
});
// 2. 받은 결과를 return -> return 하면 해당 페이지 함수의 props로 들어간다.
// 반드시 props로 return해야 한다.
return {
props: {
ssr: {
name: result.fetchUseditem.name,
remarks: result.fetchUseditem.remarks,
images: result.fetchUseditem.images,
},
},
};
};
_app.tsx 설정 변경
서버에서 props를 전달할 때 _app.tsx를 통해서 전달하기 때문에 props를 전달해줄 수 있게 추가해줘야 한다.
결과
데이터를 잘 받아온다!

SSR 주의사항
-
검색이 되면 안되는 페이지는 적용하지 않는다!!
(관리자 페이지 등) -
SSR을 이용하면 페이지 로딩 시간이 길어진다.

블로그 및 깃허브에 너무 유용한 정보가 많아서 잘 보고 갑니다!! ☺️