GAN이란?
Generative(생성적) Adversarial(적대) Network(신경망)
GAN은 서로 경쟁하는 두개의 신경망으로 구성된 네트워크다
그럼 GAN의 구조를 보도록 하자🧐
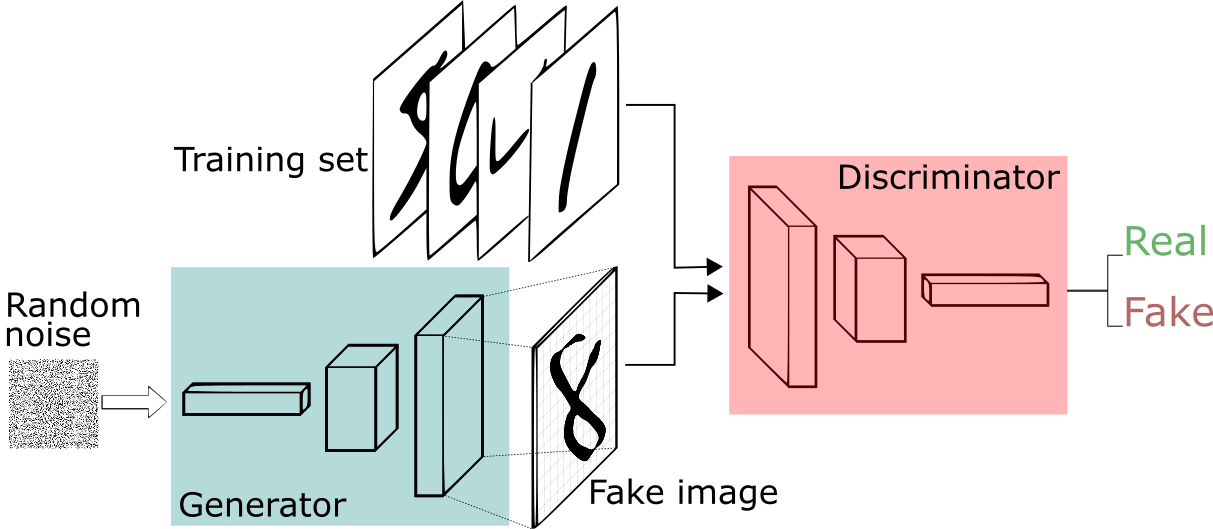
GAN은 생성기 신경망과 판별기 신경망으로 이루어져있다.
그리고 CNN, RNN, LSTM과 같은 모든 신경망을 생성기와 판별기로 이용가능하다.
GAN과 관련된 주요 개념
GAN을 학습시킬때 사용하는 목적함수와, 품질을 판단할때 사용되는 옌센-섀년 발산(JS 발산)을 보자🧐
목적함수
진짜 이미지와 유사한 이미지를 만들기 위해서 생성된 이미지와 진짜 이미지간의 유사도를 높이게 하기 위하여 목적함수를 이용하여 유사도를 측정한다.
- : 판별기 모델
- : 생성기 모델
- : 진짜 데이터 분포
- : 생성기가 생성한 데이터 분포
- : 예상되는 출력 내용
훈련중에 판별기(D)는 최대화하는 방향으로, 생성기(G)는 최소화하는 방향으로 학습이 진행이 된다. GAN을 학습을 시켜보면 판별기와 생성기가 균형을 잡게 되는데, 이를 모델이 수렴했다고 하고, 이 균형을 내시 균형(Nash Equilibrium)이라고 한다. 반대의 경우를 모드 붕괴(Mode Collapse)라고 한다.
KL Divergence (KL 발산)
쿨백-라이블러 발산은 두 확률 분포가 얼마나 다른가를 측정하는 방법이다.
아래는 두 확률 분포 p와 q사이의 KL 발산을 나타낸다.
- 이산형 확률 변수 :
- 연속형 확률 변수 :
다만, KL 발산은 비대칭적이기 때문에, 두 확률분포 사이의 거리를 측정할때는 사용하면 안된다.
대신 JS 발산을 사용하여야 한다.
JS Divergence (JS 발산)
옌센-섀넌 발산은 대칭적이며 두 확률 분포 사이의 거리를 측정하는데 쓰인다.
아래는 두 확률 분포 p와 q사이의 옌센-섀넌 발산을 나타낸다.

.