자료구조
1.링크드 리스트
.png)
링크드 리스트 각 노드가 데이터와 포인터를 가지고 한 줄로 연결이 되어 있는 방식으로 데이터를 저장하는 자료 구조 이다. 노드의 포인터가 다음이나 이전의 노드와의 연결을 담당하게 된다. 이런식으로 연결이 가능하다. 무작위로 저장이 되어 있는 데이터의 형식에 n
2.메모리, 배열(array)
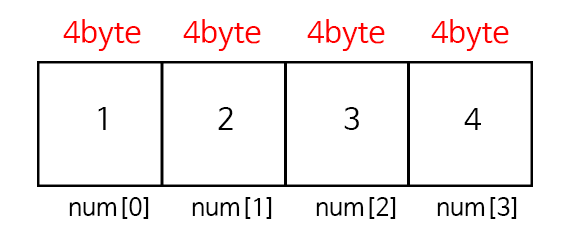
스토리지 : 데이터가 영구적으로 저장되는 곳, 저장되어 지는 용량이 큼장점 : 저장하는 용량이 크다, 사용자나, 외부충격이x 지워지지 않는다.단점 : 저장하는데 오래걸리고, 로딩이 오래걸린다. ex) 창고 메모리 : 데이터를 임시로 저장 하는 곳장점 : 저장이 빠
3.더블 링크드 리스트
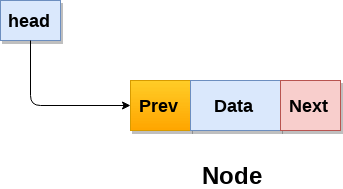
싱글 링크드 리스트는 한 개의 데이터와 링크를 걸고자 하는 포인터로 이루어진 노드의 연결로 만들어진 리스트 이다.더블 링크드 리스트는 여기에 prev라는 이전을 연결하는 포인터가 한 개 더 생긴 것을 의미한다.이런식으로 데이터, Prev, Next 가 한개의 노드를 구
4.해시 테이블
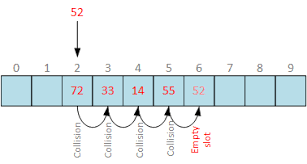
해시함수(hash) 해시 테이블을 알기전 우선 적으로 해시함수를 알아보자, 해시 함수는 임의의 데이터를 고정된 길이의 데이터로 매핑하는 것을 의미 한다. 그리고 이러한 매핑해주는 과정을 보고 해싱이라고 한다. 우리 주변에서 해싱을 하는 대표적인 경우는 bycrpt를
5.트리(tree)

tree(트리) 계층형 트리 구조를 시물레이션 하는 추상 자료형 루트 값과, 부모-자식 관계의 서브 트리고 구성되며 서로 연결된 노드의 집합입니다. 우리 주변에서 쉽게 볼 수 있는 위 아래 개념을 컴퓨터에서 표현한 구조 재귀로 정의된 Recursive defined 자
6.정렬이론 -2 (quick sort)
알고리즘 퀵 정렬(quick sort) divide and conquer 과정을 사용 하는 정렬은 '합병 정렬' 말고도 퀵 정렬이라고 있다. 퀵정렬은 하나의 기준점을 정한 뒤, 기준 왼쪽은 기준 보다 작은 값 오른쪽은 많은 값을 정렬한 뒤 또 그 값 에서 기준을 정하는
7.알고리즘 이론 (Brute Force, Divide and Conquer, Dynamic programing, greedy Algorithm)
두 리스트에 있는 값을 차례로 추출 한 뒤 비교 후 작은 값을 새로운 리스트에 차례로 넣어주는 방식으로 정렬하는 방법하나의 기준(pivot)을 정한뒤 왼쪽은 기준보다 작은 값, 오른쪽은 기준보다 큰 값을 배분하는 방법으로 리스트 내부에서 정렬해 나가는 방법퀵 정렬은 따
8.정렬 이론 -1 (Divide and Conquer - 합병정렬)
알고리즘 Divide and Conquer(분할 정복 방식) - 알고리즘에서 어려운 축에 속하는 방식으로 divide(분할), conquer(정복), combine(결합) 이 세가지의 단계로 진행이 된다. 그리고 주로 '재귀 함수'가 많이 사용이 된다. 합병 정렬(M
9.시간복잡도, 점근표기법, 재귀
점근표기법 - 컴퓨터 공학자들이 시간과 공간에 관여하는 알고리즘을 나타내는 표기법이다. O(n)으로 표기한다. - 표기법에서 나타내는 항은 가장 큰 변수를 중심으로 표시된다. 그 이유는 사소한 숫자에와의 차이에는 모든 항의 영향력이 크지만 대입되어지는 값이 10000,