저장 공간
- 스토리지 : 데이터가 영구적으로 저장되는 곳, 저장되어 지는 용량이 큼
- 장점 : 저장하는 용량이 크다, 사용자나, 외부충격이x 지워지지 않는다.
- 단점 : 저장하는데 오래걸리고, 로딩이 오래걸린다.
ex) 창고
- 메모리 : 데이터를 임시로 저장 하는 곳
- 장점 : 저장이 빠르고, 로딩이 빠르다.
- 단점 : 컴퓨터가 종료 되거나 창이 꺼지면 저장되어 있는 데이터가 없어짐
ex) 책상서랍
왜저장 공간이 두 개로 나뉘어져 있는가?
영화를 예로 들 수 있다.
영화가 저장이 되어있는 장소는 스토리지 이다. 하지만 스토리지에서 영화를 재생하게 되면 로딩도 느리고 영화가 재생이 되는데 끊길 가능성이 있다.
그래서 영화를 메모리로 복사를 한 후 메모리에서 영화를 재생하게 된다면 로딩이 빨리 이루어 지기 때문에 끊김없이 재생이 된다.
그래서 각 상황에 맞게 저장소를 사용하면 된다.
자료구조에서는 메모리를 많이 다루게 될 예정이다.
RAM(Random Access Memory)
임의 접근 메모리라는 뜻을 가진 Ram은 말 그래도 메모리 저장소 이다.
- 저장 위치만 알면 접근시 항상 일정 시간이 걸린다.
- 어떤 메모리 던지 위치만 알면 바로 접근이 가능하다.
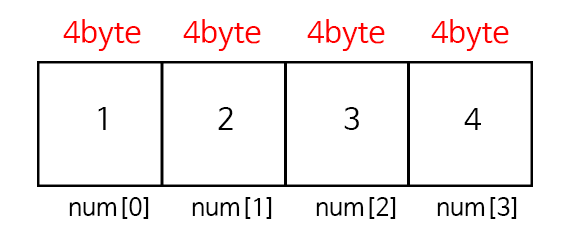
배열
우리가 알고 있는 메모리는 이런식으로 만들어져 있다. 이 각 칸마다 가질 수 있는 가장 기본적인 용량의 크기는 바이트이다.
1KB = 1,000 바이트
1MB = 1,000KB = 1,000,000바이트
1GB = 1,000MB = 1,000,000KB = 1,000,000,000바이트
Reference(참조)
- 데이터에 접근 할 수 있게 해주는 값
- 주소보다 조금 더 포괄적인 표현
- 의미는 실질적으로 다르나 자료구조를 배울 때에는 주소=참조 라고 생각해도 된다.
ex) 'x=95' 라고 할때
정확히말해서 'x는 95' 이다 라고 말하면 오답이다.
정확히 말하면 x는 95를 가리킨다. 이렇게 말해야한다.
그 이유는 x는 95가 저장된 메모리 주소를 이야기하기 때문이다.
배열
배열은 Python의 list라고 생각 하면 된다. 그리고 C의 배열에서 파생되어 졌다.
차이점
num_list = [2,3,4,5] 라고 할때
c언어의 배열에는 메모리에 2,3,4,5 가 각각 저장이 되어있다.
파이써은 메모리에 저장되어 있는게 '2,3,4,5' 가 있는 것이 아닌 메모리 어딘가에있는 2,3,4,5를 가리키고 있는 주소가 저장이 된다.
그래서 배열의 크기와 타입을 다 정해줘야만 하는 C언어와는 다르게 Python에서는 다양한 타입의 요소를 리스트에 저장을 할 수 있다. 그리고 주소가 저장이 되기 때문에 자료의 크기 또한 신경 쓰지 않아도 된다.
그래서 배열의 정의를 보면
배열이란 인덱스를 이용한 데이터 저장/접근법 이다.
배열에서 데이터를 저장하고 가지고 오는 법
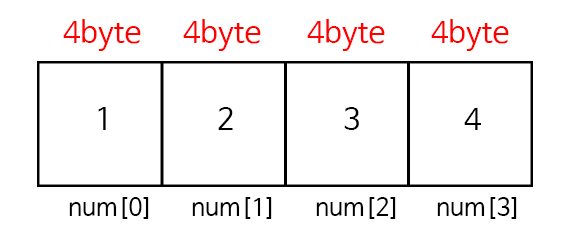
C언어 에서의 배열의 각 크기는 4바이트 이다. 그래서 그림에 있듯이 한 칸당 4바이트가 들어가게 된다.
그리고 num[0]에서 '0'이 배열의 인덱스가된다.
인덱스의 주소를 구할 수 있는데
시작주소 + 크기 x 인덱스
이런식으로 구하면 된다.
만약 시작 주소가 1000이라고 한다면
인덱스 0의 주소는 1000 + 4 x 0 으로 '1000'가 된다.
인덱스 1의 주소는 1000 + 4 x 1 으로 '1004'가 된다.
인덱스 2의 주소는 1000 + 4 x 2 으로 '1008'이 된다.
인덱스 3의 주소는 1000 + 4 x 3 으로 '1012'가 된다.
즉 배열의 인덱스를 알기 위해서는 '주소'를 알아야 한다.
배열의 장점
배열의 시간 복잡도를 따져볼때 단순히 접근 할 때에는 단순히 O(1)이 차지한다.
주소만 알고 있으면 한번에 접근 할 수 있다.
배열 탐색
- 접근 : 인덱스를 통해 원한느 값을 찾는 것을 의미합니다.
- 탐색 : 특정 조건을 만족할 만한 것을 찾는 것을 의미한다.
선형탐색
처음부터 하나하나 내가 원하는 값이 맞는지 확인 하는 것이다.
시간 복잡도: 배열의 처음부터 탐색하는 것이기 때문에 -> O(n)
배열 접근 연산 : O(1)
배열 탐색 연산 : O(n)
배열의 종류
- 정적 배열 : 크기가 종류가 고정되어 있는 배열 -> '배열'
- 동적 배열 : 크기가 요소의 갯수만큼 자동으로 늘어나는 배열 -> '동적배열'
그럼 왜 정해줘야만 하는가?
만약 요소의 개수를 5개로 정해준 배열에 한 개를 추가하려고 하면 새로운 배열을 만들어서 추가해야한다.
-> 어떤 타입을 담을 건지, 몇개를 담을 것인지에 따라서 메모리의 수가 결정이 된다. 그래서 메모리가 저장이 되어있고 요소를 추가하게 되면 메모리의 공간에 데이터가 있는지 없는지 알 수가 없다. 그래서 이런 위험성을 배제하기 위해 고정시켜 놓는다.
그럼 필요한 요소 수보다 더욱 많이 들어가도록 설정을 해주게 된다면?
다른 데이터를 저장할 때 요소를 저장하고 남은 공간이 낭비되게 된다.
동적배열(Dynamic Array)
상황에 맞게 크기가 변경이 된다. 정적배열을 이용해 만든 것이다.
배열의 메모리가 다 사용되게 되면 자동으로 메모리가 일정크기만큼 늘어난다.
이러한 C의 동적배열이 python의 list가 된다.
- 파이썬 뿐만 아니라 동적배열을 자료형으로 제공하는 대부분의 언어들은 실제 사용하는 대부분의 언어들은 실제 사용하는 배열의크기와 상관없이 저장해 놓은 공간만 사용할 수 있게 처리를 해 줍니다.
배열의 추가 연산(append operation)
- 정적 배열에 남은 공간이 있을 때 : O(1)
- 그냥 추가 하면 되기 때문에 - 정적 배열이 꽉 찼을 때: O(n)
- 추가해야 될 자리를 찾아가야 하기 때문에
분할 상환 분석
어떠한 알고리즘에서 시간 복잡도를 이야기 할때 대부분 보수적으로 이야기를해 최악의 상황을 이야기 합니다.
그래서 동적 배열에서 따지게 되면
경우 1의 경우에는 O(1)이지만 경우 2가 되면 O(n) 입니다. 그래서 최악의 상황으로 추가연산의 시간복잡도는 O(n)이라고 이야기를 하게됩니다.
하지만 경우2 보다 경우1 상황이 더욱 빈번하게 일어나는데 최악의 상황이라고 O(n)이라고 단정짓는 것은합리적이지 않다.
그래서 분할 상환 분석 이라는 방법을 통해 이야기 할 수 있다.
이 방법은
'시간 복잡도를 이야기 함에 있어 최악으로 이야기 하는 것이 아니라 평균으로 이야기를 하는 것을 의미한다.'
같은 동작을 n번 했을 때 드는 시간이 X라고 한다면 동작을 한 번 하는데 걸리는 시간은 'x/n' 이다.
동적 배열을 분할 상환 분석을 사용해 이야기 해보면
경우 1. 새로운 동적 배열 맨 끝에 단순히 저장하는데 걸리는 시간
경우 2. 더 큰 배열을 만들고 그 배열의 기존의 데이터를 옮기는데 걸리는 시간
경우1
| x번째 추가 | 걸리는 시간 |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
| .. | 1 |
| x | 1 |
이런식으로 O(1)의 시간복잡도가 나오게 된다.
경우 2
| x번째 추가 | 걸리는 시간 | 새로운배열에저장하는데 걸리는 시간 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 1 |
| 3 | 4 | 2 |
| 4 | 4 | 0 |
| 5 | 8 | 4 |
| 6 | 8 | 0 |
| 7 | 8 | 0 |
| 8 | 8 | 0 |
| 9 | 16 | 8 |
동적배열에서 배열의 크기를 늘려갈 때 1,2,4,8 이런식으로 점점 늘어 간다.
추가 연산을 진행 할 때
데이터를 복사해서 저장하는데 걸리는 시간을 따져보게 되면
m+m/2+m/4+m/8+.....+1 이런식으로 나가게 된다.
추가 연산시 8이 걸렸다는 이야기는
수용가능 크기가 8이었지만 크기가 부족해 16개를 담을 수 있는 새로운 배열로 늘렸다고 복사했다고 할 수 있다.
그리고 현재 배열에 있는 요소의 수는 항상 가장 마지막 데이터를 저장한 데이터의 수 보다 크다.
추가연산을 n번하고 마지막에 옮겨 저장한 데이터의 수를 m라고 했을 때
복사해서 걸리는 시간은 : '2m-1'이다.
연속으로 추가 연산은 n번을 하게 되면 데이터를 옮겨서 저장하는 것은 2n작다.
추가 연산 되는 부분은 1로 수렴하게 되기 때문이다.
두 경우 합치기
지금까지 나온 내용을 종합 해보면 동적배열에 n개의 데이터를 연속으로 추가하게 되면
1. 새로운 데이터를 저장하는 데에는 n의 시간이 들고
2. 데이터를 저장하는 데에는 2n보다 적은 시간이 걸린다.
이 두 시간을 합치면 3n보다 적은 시간이 듭니다.
이걸 시간 복잡도로 표시하면 O(3n) = O(n)이 됩니다.
추가연산이 1번이 아닌 n번 했을 때 걸리는 시간이 O(n)이기 때문에 분할 상환 분석을 사용해서 '걸리는 시간 / 추가 연산을 했는 횟수' 로 계산 해보면
O(n) / n 이 되고 O(1)가 됩니다.
그럼 최악의 경우 분석 과 분할 상환 분석중 어떤 것을 써야 할까?
분할 상환 분석을 사용하더라도 시간 복잡도가 줄어드는 것은 아니지만
최악의 경우보다 분할 상환 분석의 복잡도가 더 적다면, 분할 상환 분석을 한 복잡도를 사용합니다.
동적 배열의 추가(append)를 한 경우엔 O(n)이 걸리지만 분할 상환 분석을 사용하게 되면 O(1)이 걸린다.
라고 표현 하면 됩니다.
정리
연산 시간 복잡도를 따져보면
| 배열 | 동적배열 | |
|---|---|---|
| 접근(access) | O(1) | O(1) |
| 탐색(search) | O(n) | O(n) |
| 삽입(insert) | N/A | O(n),맨뒤O(1) |
| 삭제(delete) | N/A | O(n), 맨뒤O(1) |
배열은 배열의 크기 와 수가 고정이 되어 있기 때문에 삽입과 삭제가 이루어 지지 않는다.
그래서 동적배열에서 삽입과 삭제는 위에 말했던 대로
동적 배열의 추가(append)를 한 경우엔 O(n)이 걸리지만 분할 상환 분석을 사용하게 되면 O(1)이 걸린다.
이런식으로 이야기 하면 된다.
낭비하는 공간
배열(정적 배열) : 크기가 고정되어 있기 때문에 낭비하는 공간이 없다.
동적 배열 : 공간을 낭비 할 수도 있고 안 할 수도 있다.
출처 : 코드잇 자료구조
