Apache Spark 기초
Spark 개요 (소개, 특징, RDD)
Apache Spark
- Unified Engine : Support end-toend applications
- High-level APIs : Easy to use, rich optimizations
- Integrate Broadly : Storage systems, libraries, etc
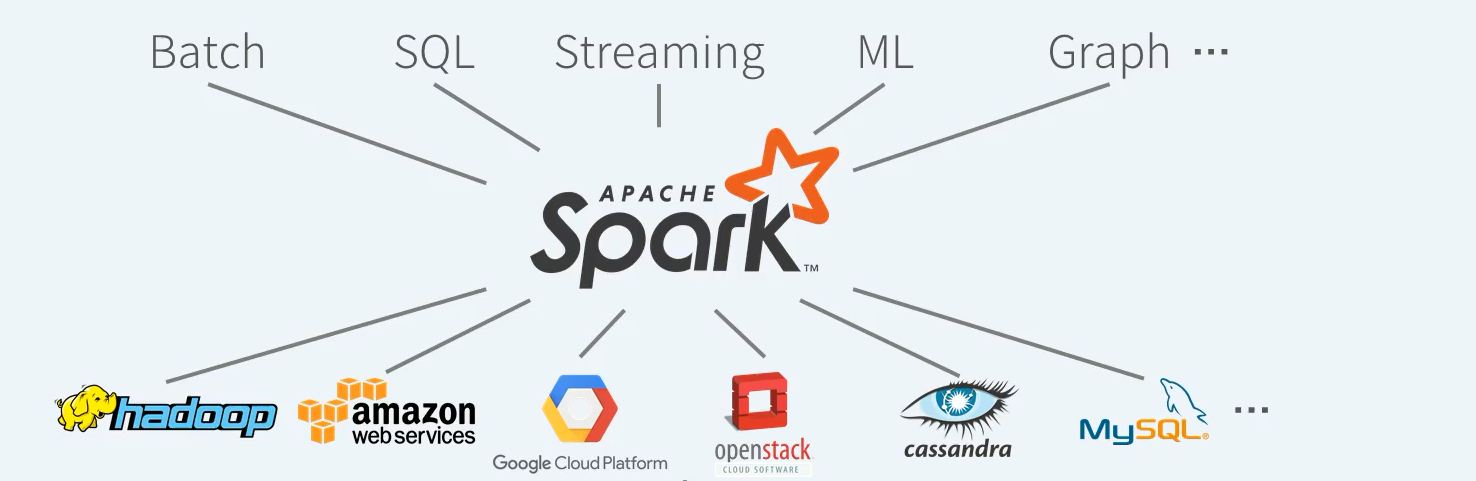
아파치 Spark은 빅데이터에 대한 컴퓨터 연산을 다수의 서버로 구성된 클러스터에서 분산 병렬처리하기 위한 오픈소스 엔진이다.
일반적으로 데이터를 모아서 일괄처리하는 배치작업부터 구조화된 데이터에 대한 처리를 수행하는 SQL 작업, IOT 센서데이터와 같은 지속적으로 들어오는 실시간 데이터를 스토리지에 저장 없이 바로 처리하는 스트리밍 작업, 분산 환경에서의 대용량 학습 데이터를 통한 머신러닝 트레이닝 및 추론 작업, 그리고 버택스 엣지 구조?의 그래프 데이터에 대한 병렬 연산과 같이 다양한 작업을 개별 엔진이 아닌 하나의 엔진에서 처리할 수 있는 통합 데이터 처리 엔진이다.
Spark은 저장소가 아니다. 외부의 데이터를 읽어 분산 환경에서 원하는 형태로 데이터를 처리한 후 그 결과를 다시 외부에 저장하는 컴퓨팅 엔진이다.
Apache Spark란? (1/2)
- Apache Spark는 대용량 데이터 프로세싱을 위한 빠르고 범용적인 인메모리 기반 클러스터 컴퓨팅 엔진
- 분산 메모리 기반의 빠른 분산 병렬 처리
- 배치, 대화형 쿼리, 스트리밍, 머신러닝과 같은 다양한 작업 타입을 지원하는 범용 엔진으로 Apache Hadoop과 호환
- Scala, Java, Python, R 기반 High-level APIs 제공
Apache Spark란? (2/2)
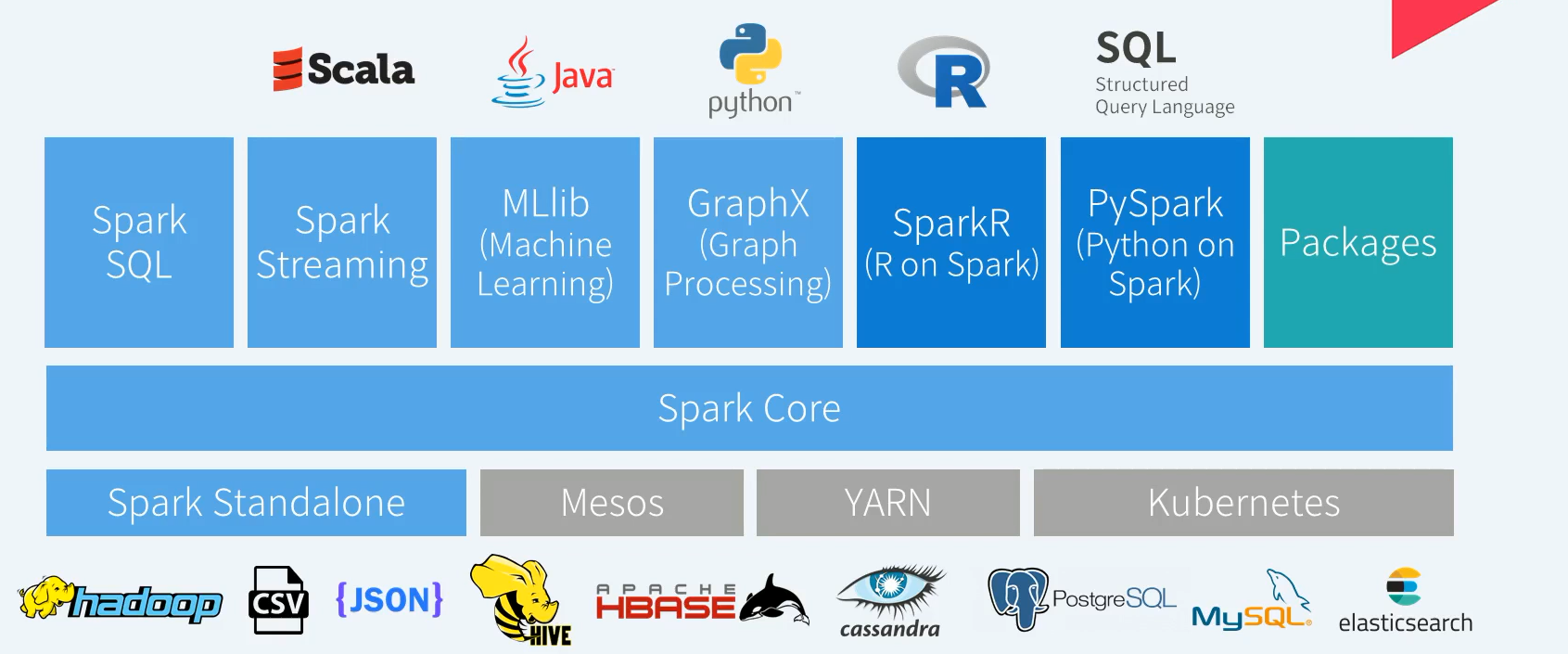
Spark은 클러스터 환경에서 분산 병렬 연산이 가능하도록 설계되어 있다.
클러스터 매니저가 별도로 존재한다. ex) Hadoop YARN, apache Mesos, Kubernetes
Spark Core는 분산 병렬 연산을 위한 작업 스케쥴 및 오류 발생시에도 문제없이 연산을 지속할 수 있는 폴트 토로론스?와 같은 다양한 핵심 기능 제공
이와 더불어 Spark의 기본데이터 모델인 RDD를 기반으로 데이터 연산을 분산 병렬로 처리합니다. Spark Core에서 다양한 확장 라이브러리가 동작한다. Spark SQL, Spart Streaming , MLlib, GraphX
기존 R과 Python 환경에서 Spark를 사용하기 위한 추가 패키지형태의 SparkR, Pyspark도 같이 제공
오픈소스 spark 커뮤니티는 글로벌하게 활동하고 있다. spark 공식 배포판에 없는 기능들은 별도의 공개된 비공식 패키지로 확장 가능하다.
Apache Spark 특징 (1/2)
- In-Memory 컴퓨팅 (물론 Disk 기반도 가능)
- RDD (Resilient Distributed Dataset) 데이터 모델
- 다양한 개발 언어 지원 (Scala, Java, Python, R, SQL)
- Rich APIs 제공 (80여개 이상, 2 ~ 10x Less Code)
- General execution graphs => DAG (Directed Acyclic Graph) => Multiple stages of map & reduce
- Hadoop과의 유연한 연계 (HDFS, HBase, YARN and Others)
여러 단계의 Map&Reduce 작업을 워크플로우 형태로 연달아 이어서 처리 할 수 있다. 이러한 연속된 작업은 DAG 형태로 관리되며 Spark 내부에서 최적화되어 수행된다.
Apache Spark 특징 (2/2)
- 빠른 데이터 Processiong (In-Memory Cached RDD, Up to 100x Faster)
- 대화형 질의를 위한 Interactive Shell (Scala, Python, R Interpreter)
- 실시간(Real-time) Stream Processing (vs. MapReduce for stored Data)
- 하나의 애플리케이션에서 배치, SQL 쿼리, 스트리밍, 머신러닝과 같은 다양한 작업을 하나의 워크플로우로 결합 가능
- Both fast to write and fast to run
RDD (resilient Distributed Dataset) (1/2)
- Dataset
- 메모리나 디스크에 분산 저장된 변경 불가능한 데이터 객체들의 모음
- Distributed
- RDD에 있는 데이터는 클러스터에 자동 분배 및 병렬 연산 수행
- Resilient
- 클러스터의 한 노드가 실패하더라도 다른 노드가 작업 처리 (RDD Lineage, Automatically rebuilt on failure)
RDD는 실패에 강한 즉, 데이터 처리 과정중 실패로부터 쉽게 회복 가능한 분산 데이터 셋 구조를 추상한 모델입니다.
RDD (resilient Distributed Dataset) (2/2)
- Immutable
- RDD는 수정이 안됨. 변형을 통한 새로운 RDD 생성
- Operation APIs
- Transformations (데이터 변형, e.g. map, filter, groupBy, join)
- Actions (결과연산 리턴 / 저장, e.g. count, collect, save)
- Lazy Evaluation : All Transformations (Action 실행 때까지)
- Controllable Persistence
- Cache in RAM / Disk 가능 (반복 연산에 유리)
RDD가 제공하는 API는 크게 3가지로 나뉩니다. Cache 관련 API와 RDD 내의 데이터를 변형하는 API를 Transformations API, RDD 내의 데이터를 가져오거나 외부의 저장하는 등의 API를 Action API로 나뉩니다.
RDD 생성 -> RDD 변형 -> RDD 연산
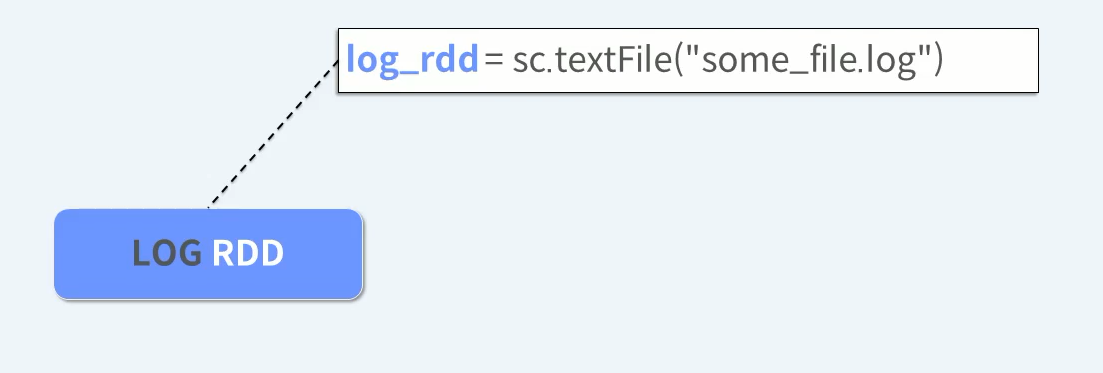
외부 데이터를 읽어 RDD에 담는다. 외부 데이터를 읽을 때 부터 분산 병렬로 읽게된다
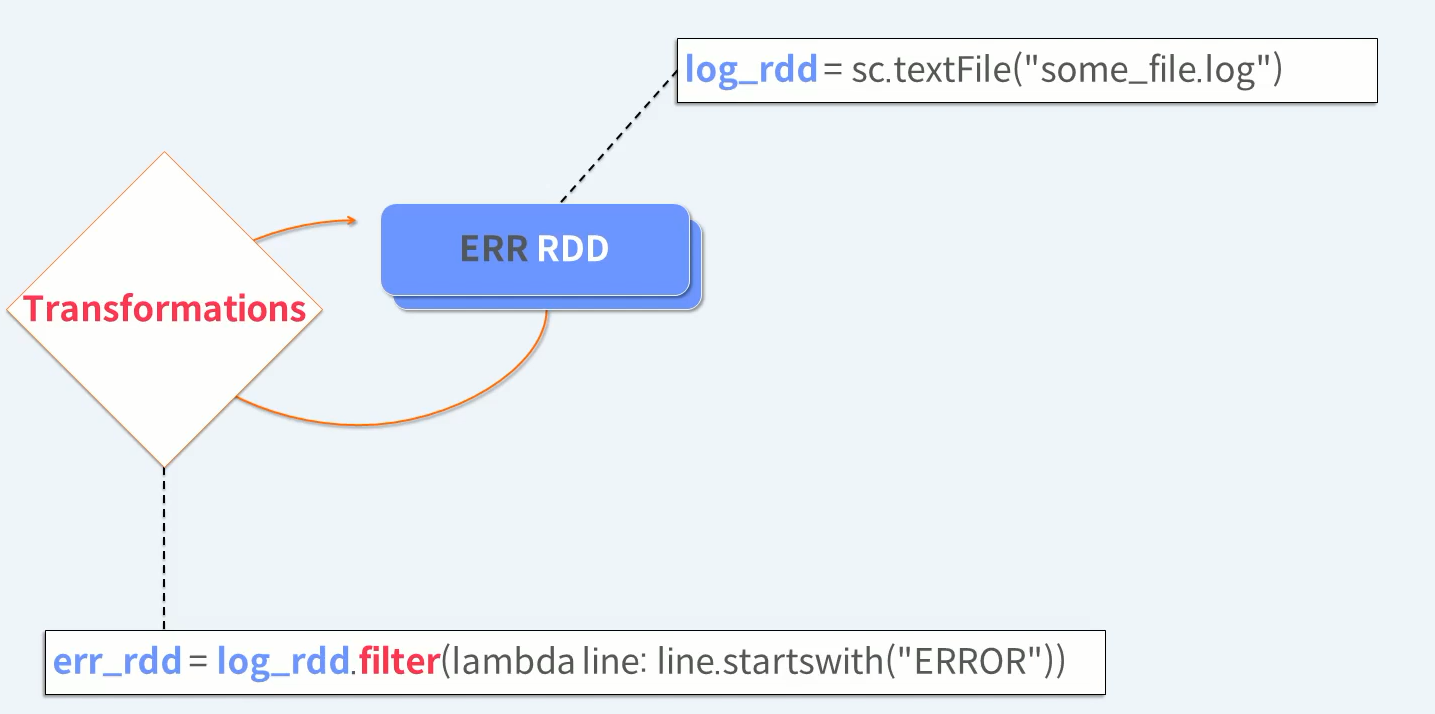
원하는 형태의 데이터가 될 때 까지 RDD Transformations을 반복 수행한다.
Transformations은 기존 RDD 내용을 바꾸는 것이 아니라 바뀌어진 새로운 RDD를 생성한다.
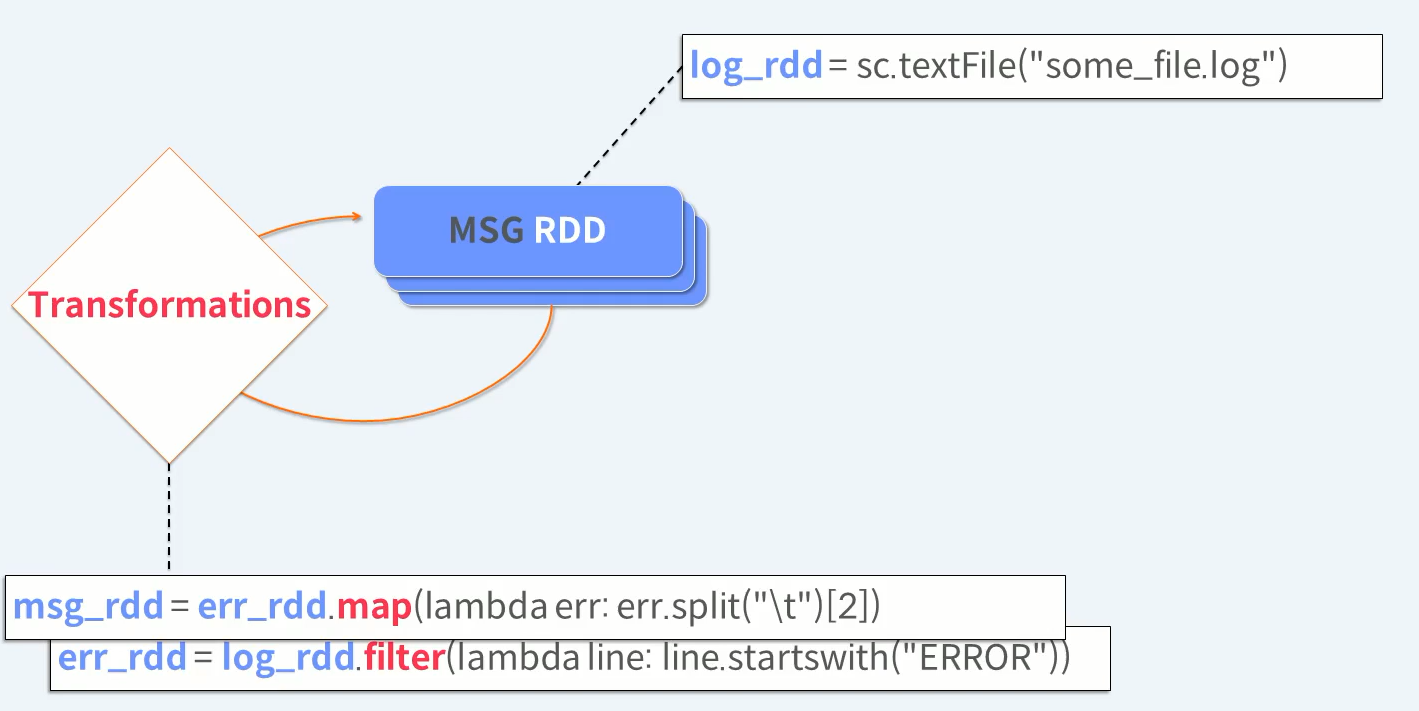
Transformations 작업을 계속 반복 수행 합니다.
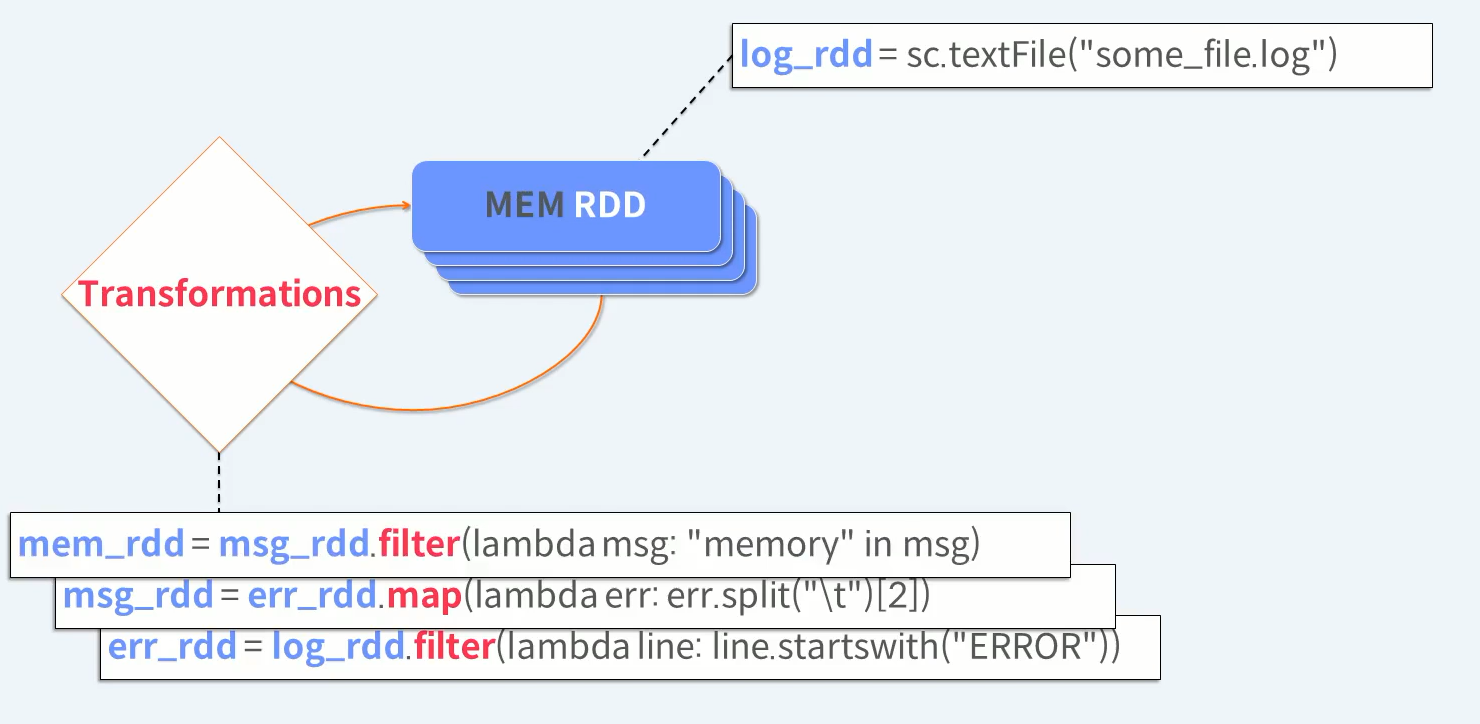
Transformations을 한번 더 수행하면 최종 원하는 모습의 데이터를 가지는 RDD를 얻게 됩니다
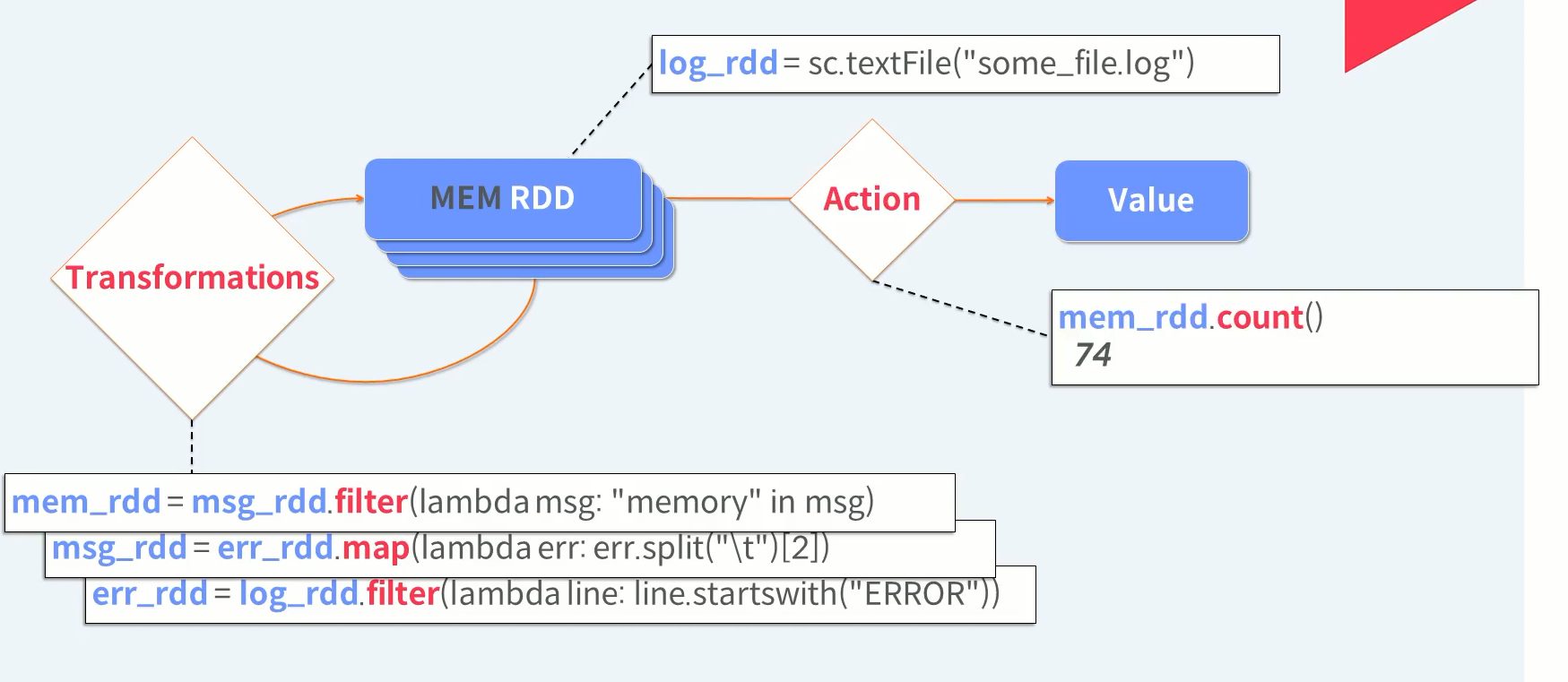
최종 RDD에 원하는 Action을 수행합니다. 데이터가 몇건 있는지 살펴 볼까요
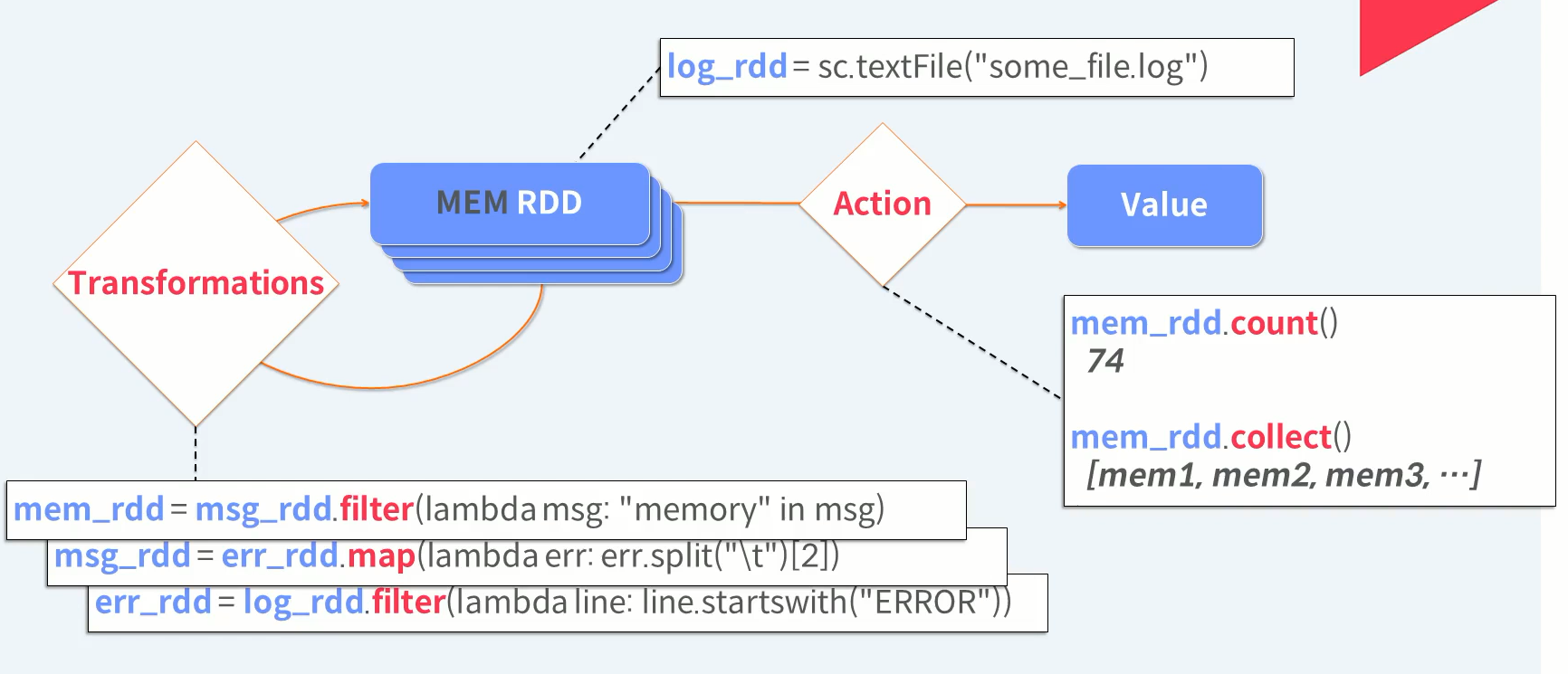
이번에는 원하는 데이터를 배열로 다 가져와 봅시다. 이 때 드라이브로 가져오는 데이터의 크기가 너무 크다면 메모리가 부족해서 Out of Memory 즉 OM 예외가 발생할 수도 있다.
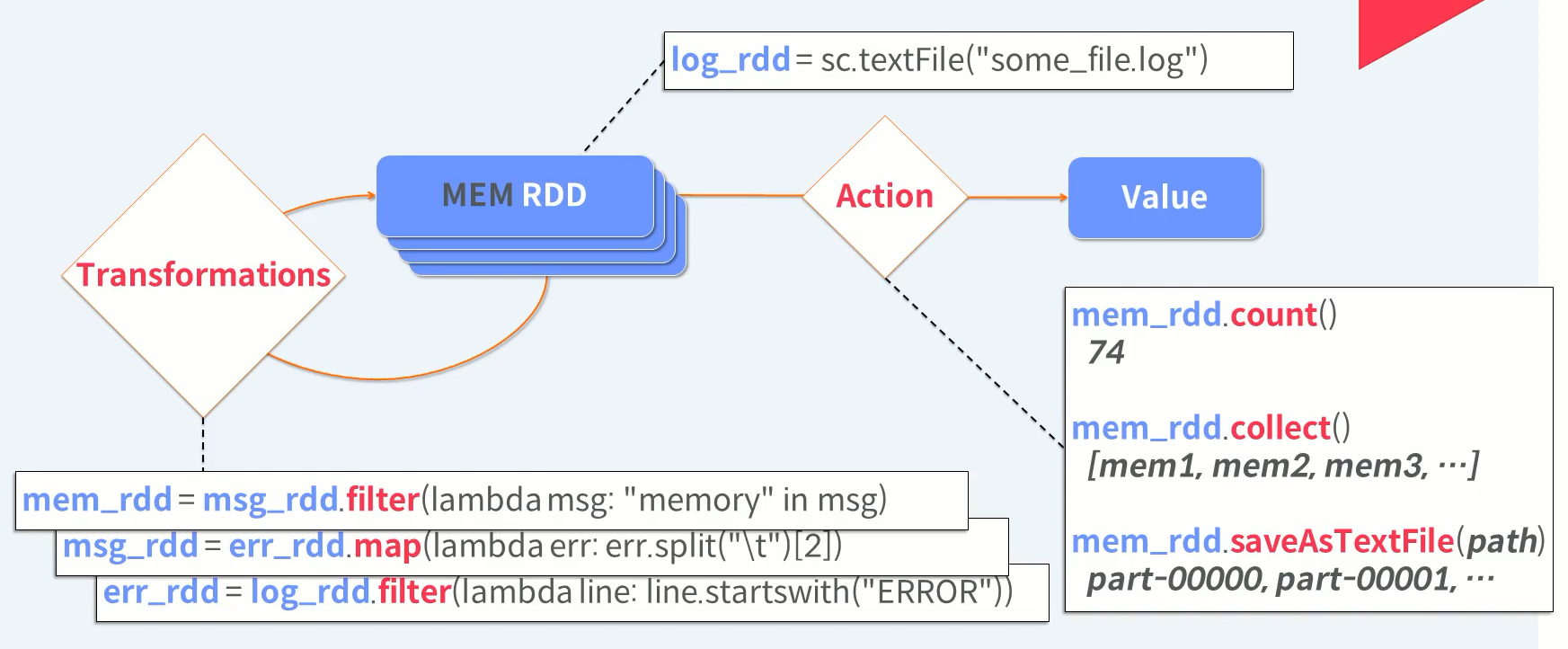
마지막으로 원하는 데이터를 향후 분석을 위해 외부 저장소에 저장합니다. 저장 작업도 RDD 내 파티션 단위로 병렬 처리되어 개별 파일로 저장이 됩니다.
Spark 개요 (지원 언어, Interactive Shell)
Spark Language Support

원하는 언어의 API를 이용하여 Spark Application을 개발해 독립적으로 실행 할 수 있다.
Interactive Shell
Spark이 제공하는 대화형 Shell을 통해서 Spark을 배우는 입문 초기에 Spark의 다양한 기능을 보다 쉽게 직접 테스트해보고 경험 해볼수 있습니다.
Spark의 Interactive Shell은 로컬 실행 뿐만 아니라 Spark이 지원하는 다양한 클러스터 매니저에 연결하여 클러스터 내의 분산수행도 가능합니다.
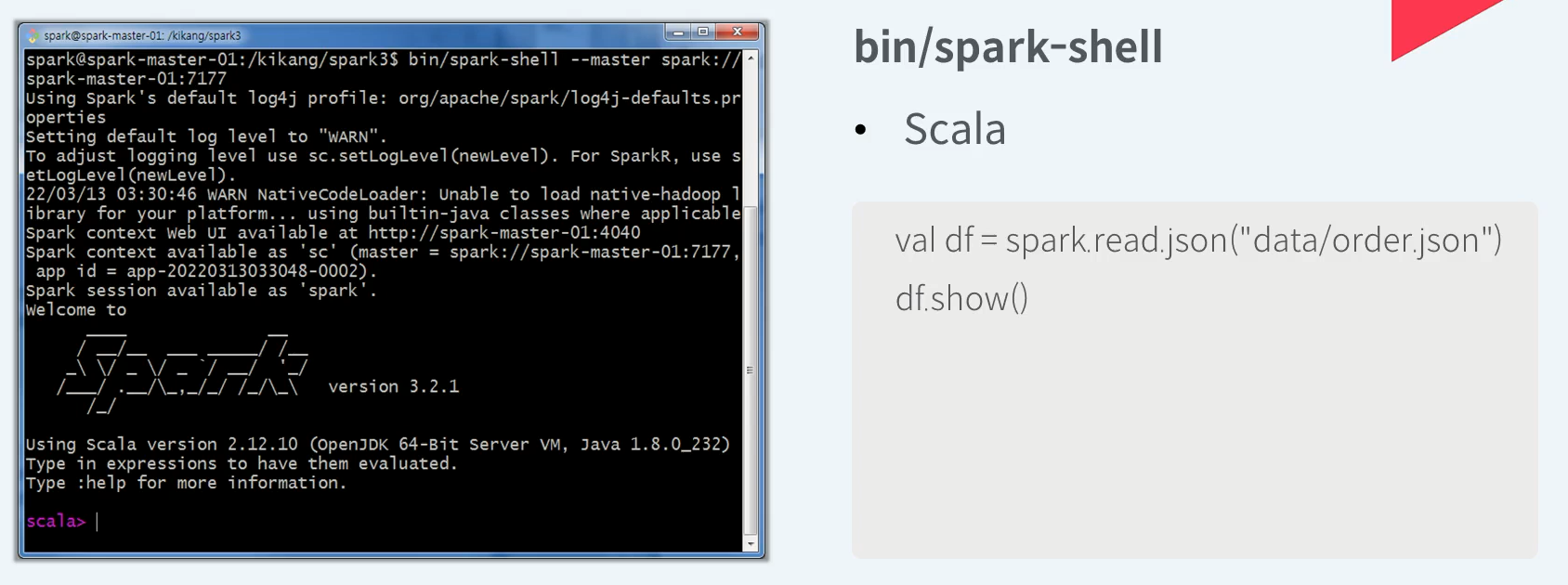
Spark이 지원하는 여러 언어 중 Scala로 spark api를 사용할 수 있는 대화형 쉘인 Spark Shell 이다.
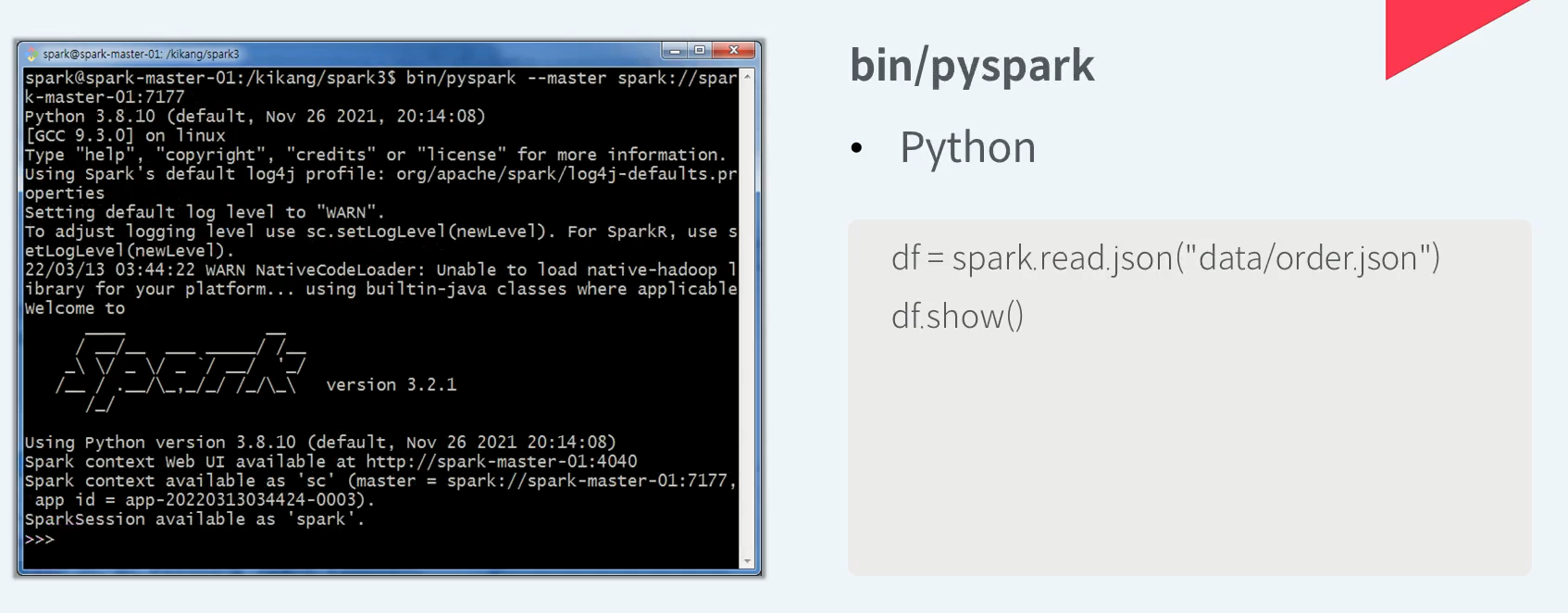
Python으로 Spark API를 사용할 수 있는 대화형 쉘인 pyspark 이다.
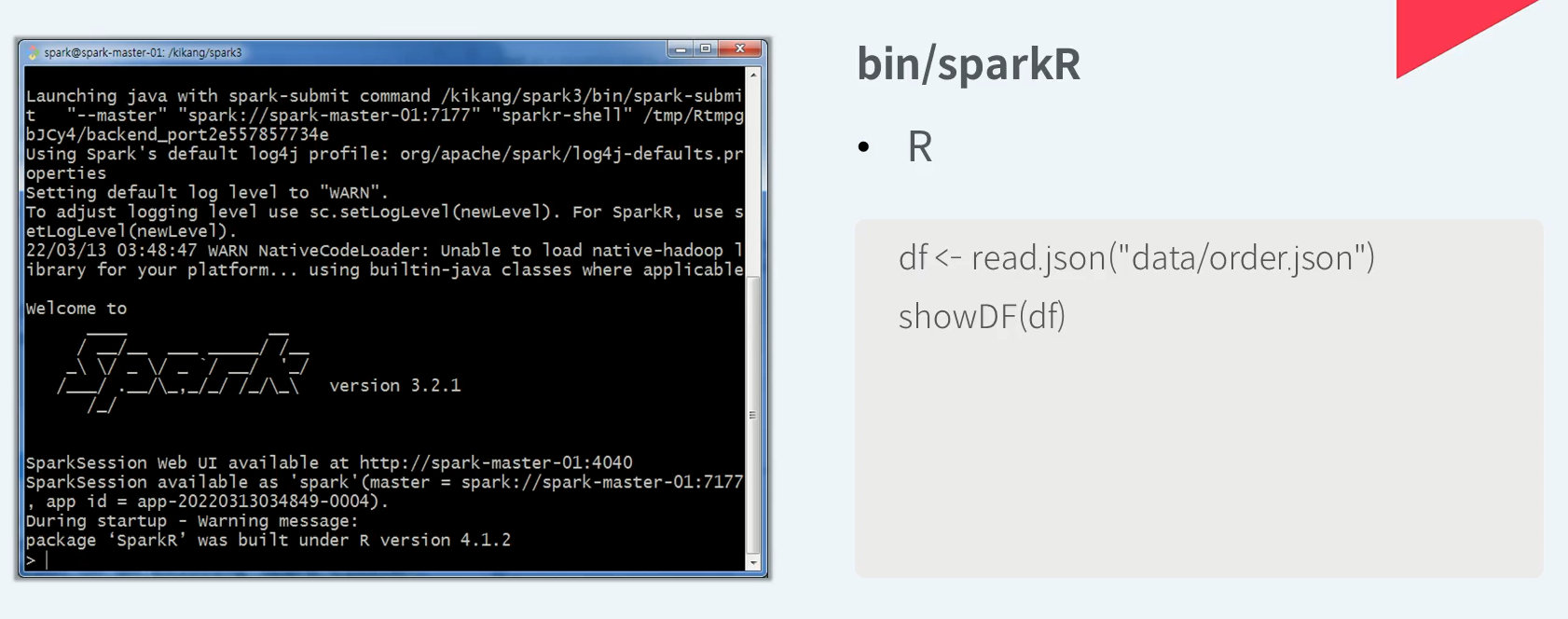
R로 Spark API를 사용할 수 있는 대화형 쉘인 SparkR 이다.
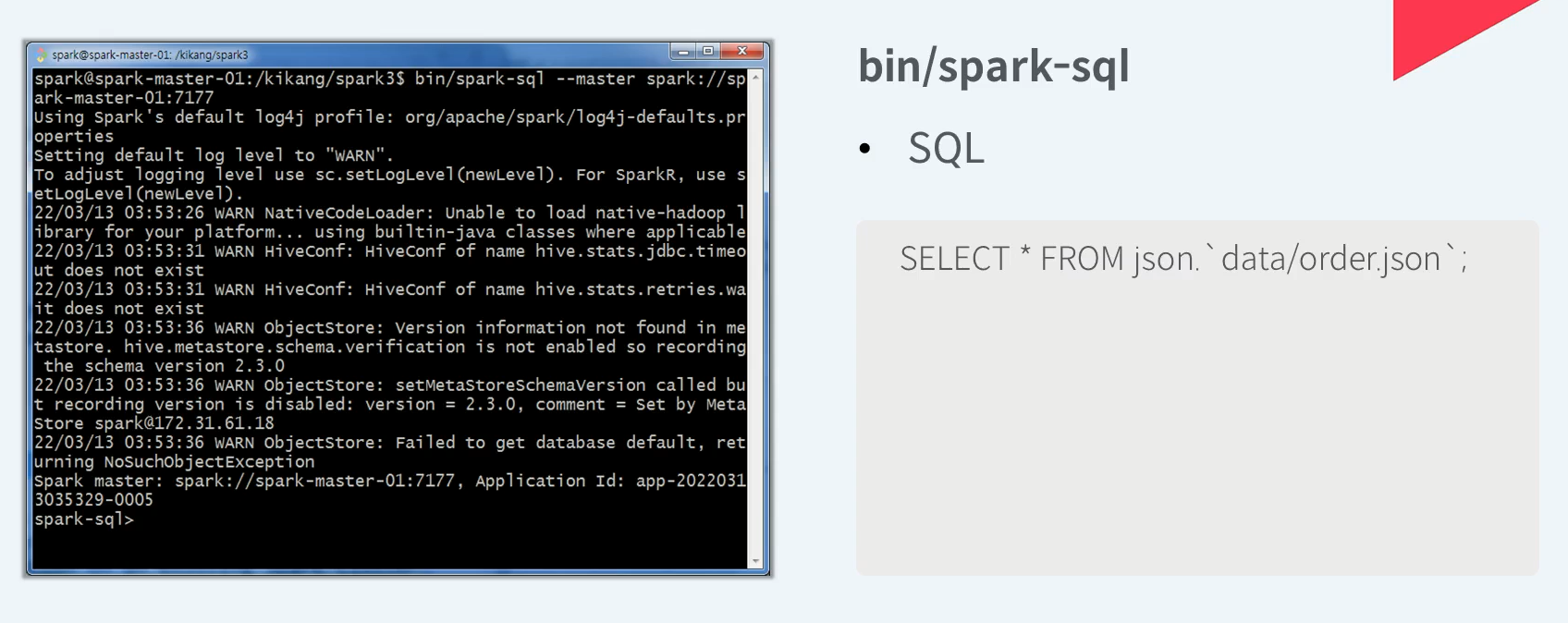
SQL 쿼리를 위한 대화형 쉘인 Spark Sql 이다.
Spark 개요 (Web Notebook, Zeppelin / Jupyter / RStudio)
Web Notebook
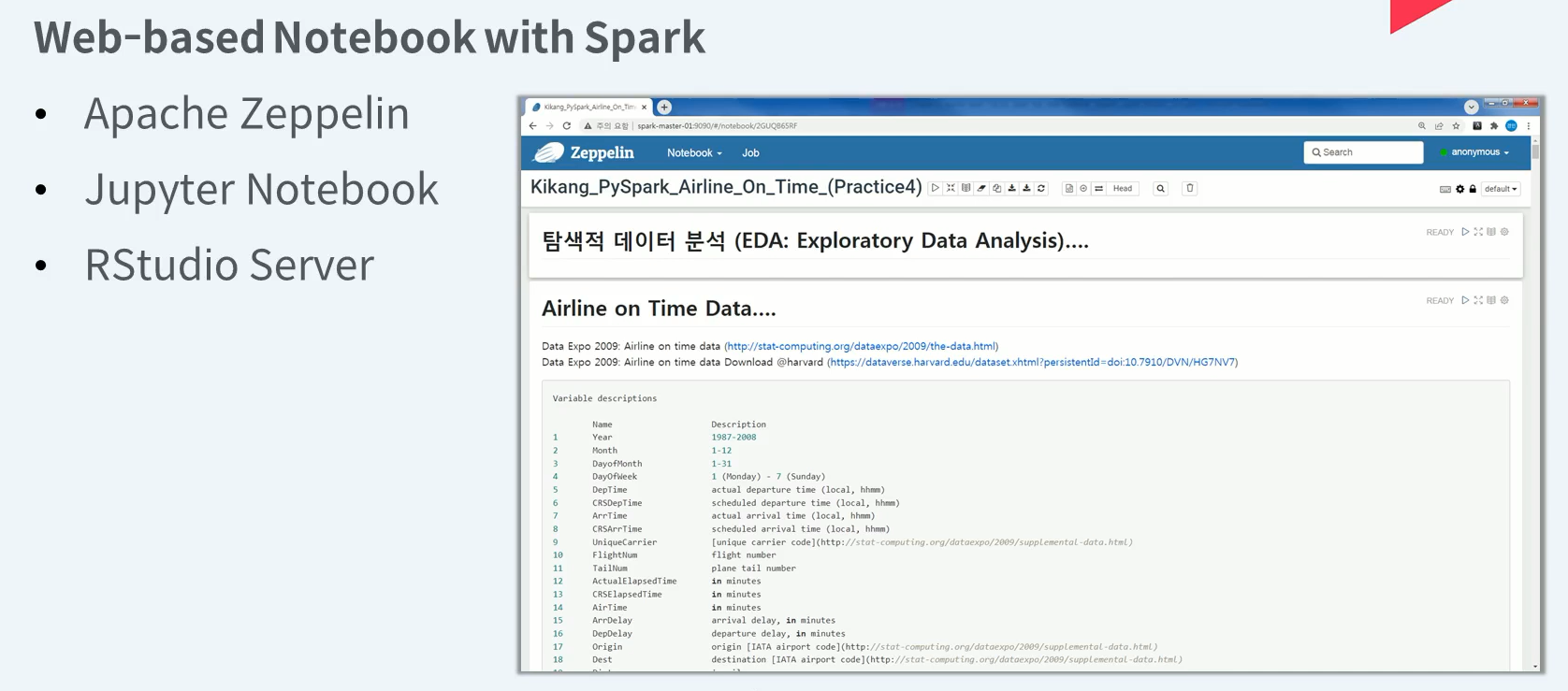
웹 기반 노트북은 대화형 분석이 가능하고 작성한 코드를 저장할 수 있으며 언어별 차트 라이브러리 및 노트북 자체 차트 기능을 통해 분석한 내용에 대해 시각화가 가능합니다
Web Notebook (w/ Spark)
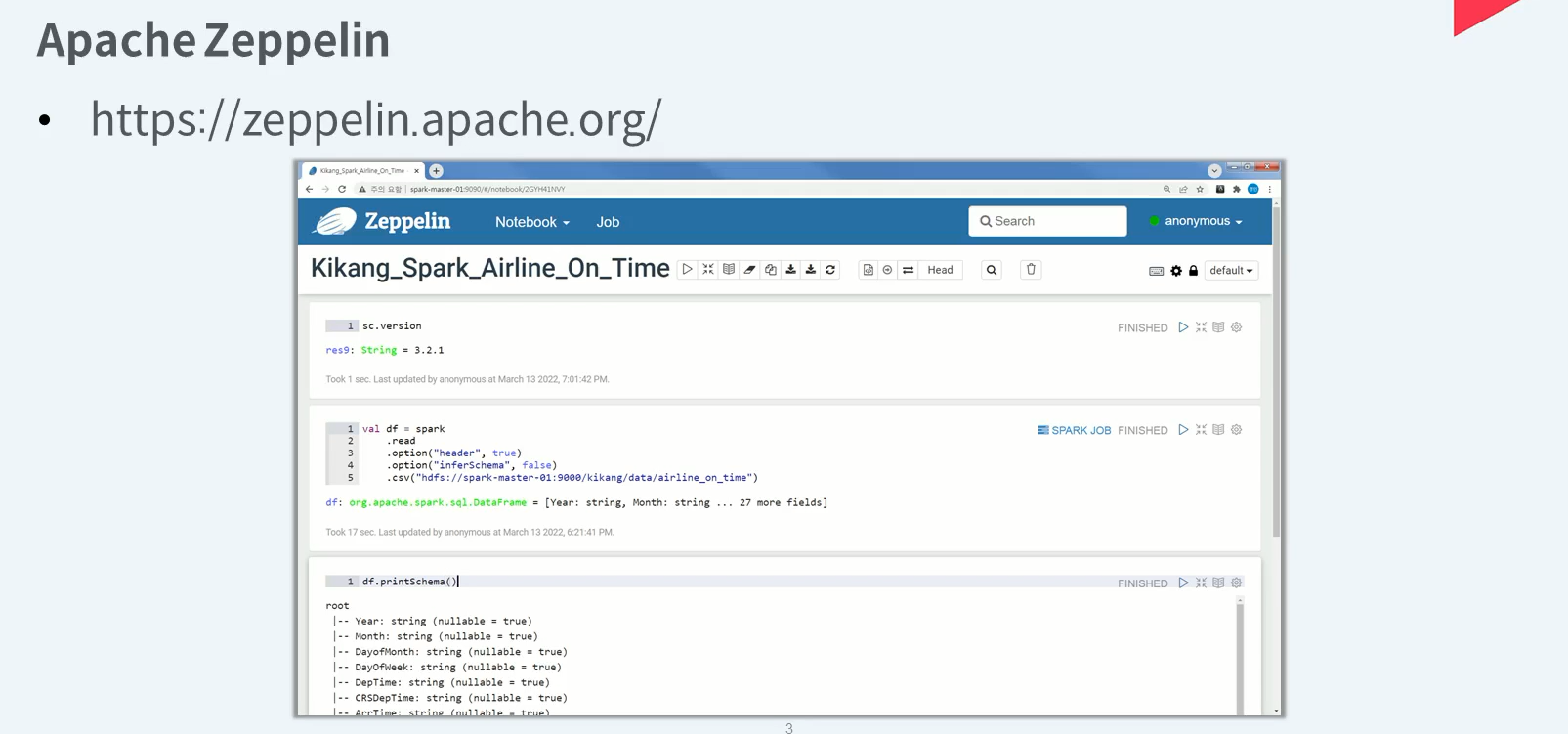
Apache Zeppelin은 하나의 노트에서 여러 클러스터에 접근 가능합니다.
Apache Zeppelin은 하나의 노트에서 여러 언어로 Spark Code를 작성할 수 있습니다.
Apache Zeppelin은 하나의 노트에서 Spark 위의 다른 Shell도 실행 가능합니다.
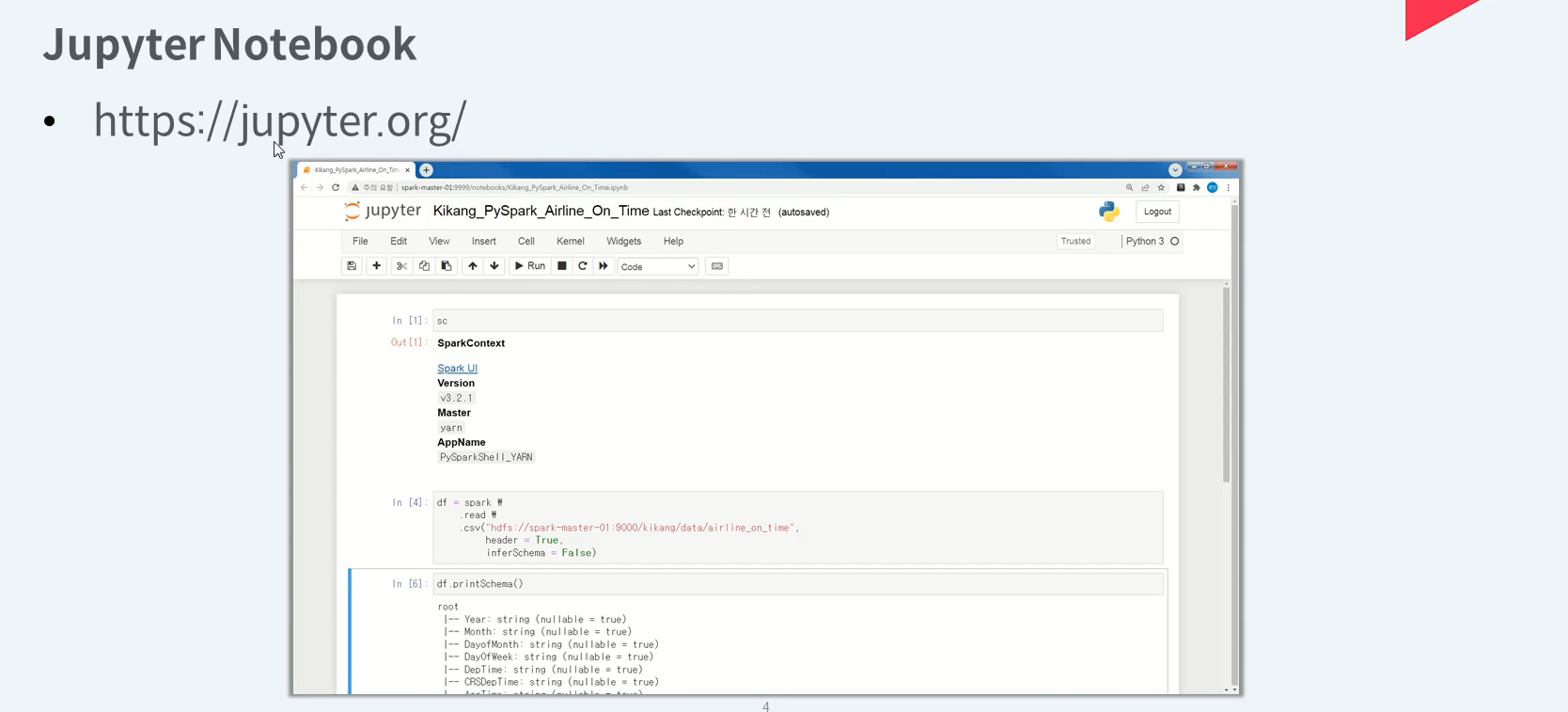
Jupyter Notebook은 주로 파이썬 기반 웹 노트북으로 많이 사용하고 있다
파이썬 언어로 spark 사용할 경우 익숙한 환경을 제공한다.
spark 연동 시 노트 하나가 하나의 Spark application이 됩니다
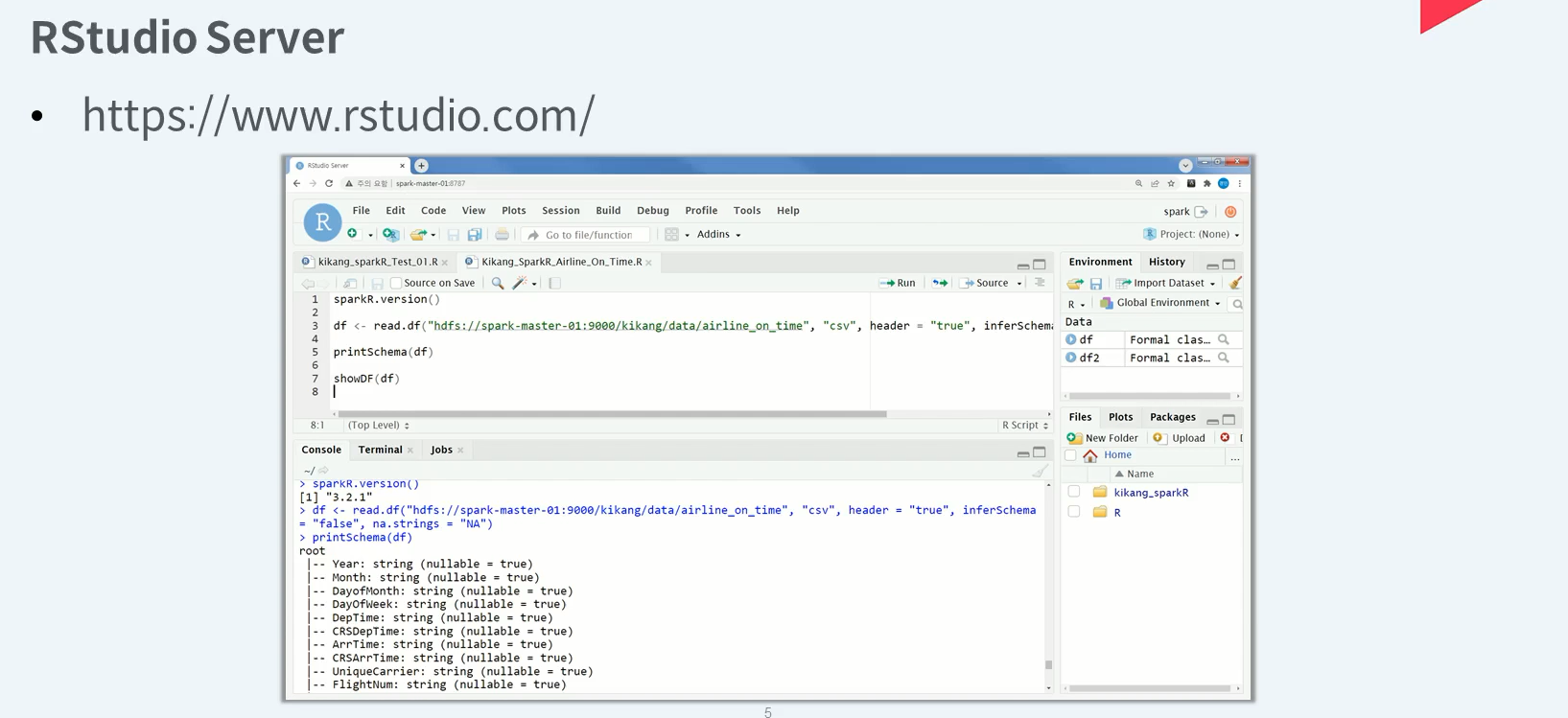
RStudio는 설치형 R Studio환경을 웹 브라우저에서도 경험 할수 있게 해주는 웹 기반 노트 환경을 제공합니다.
Spark 개요 (Web UI, Driver / Cluster Manager)
Administrative Web UIs
- Driver (Spark Application)
- History Server
- Cluster Manager (Cluster Resource Manager)
Driver (Spark Application) Web UI
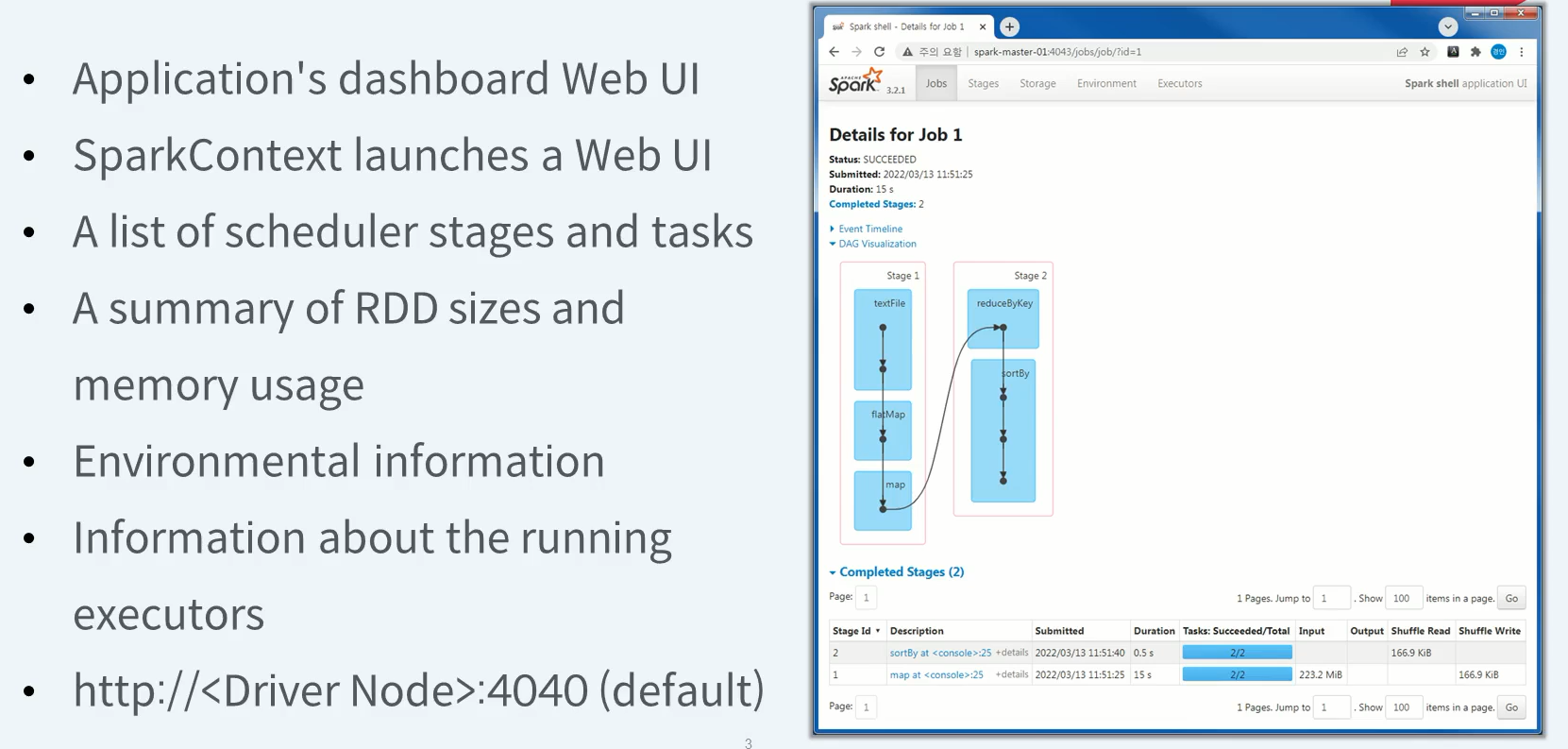
Spark Context가 제공하는 UI
Web UI의 Default port는 4040, 만약 사용중이라면 포트 번호를 1씩 증가시키면서 할당한다.
History Server Web UI
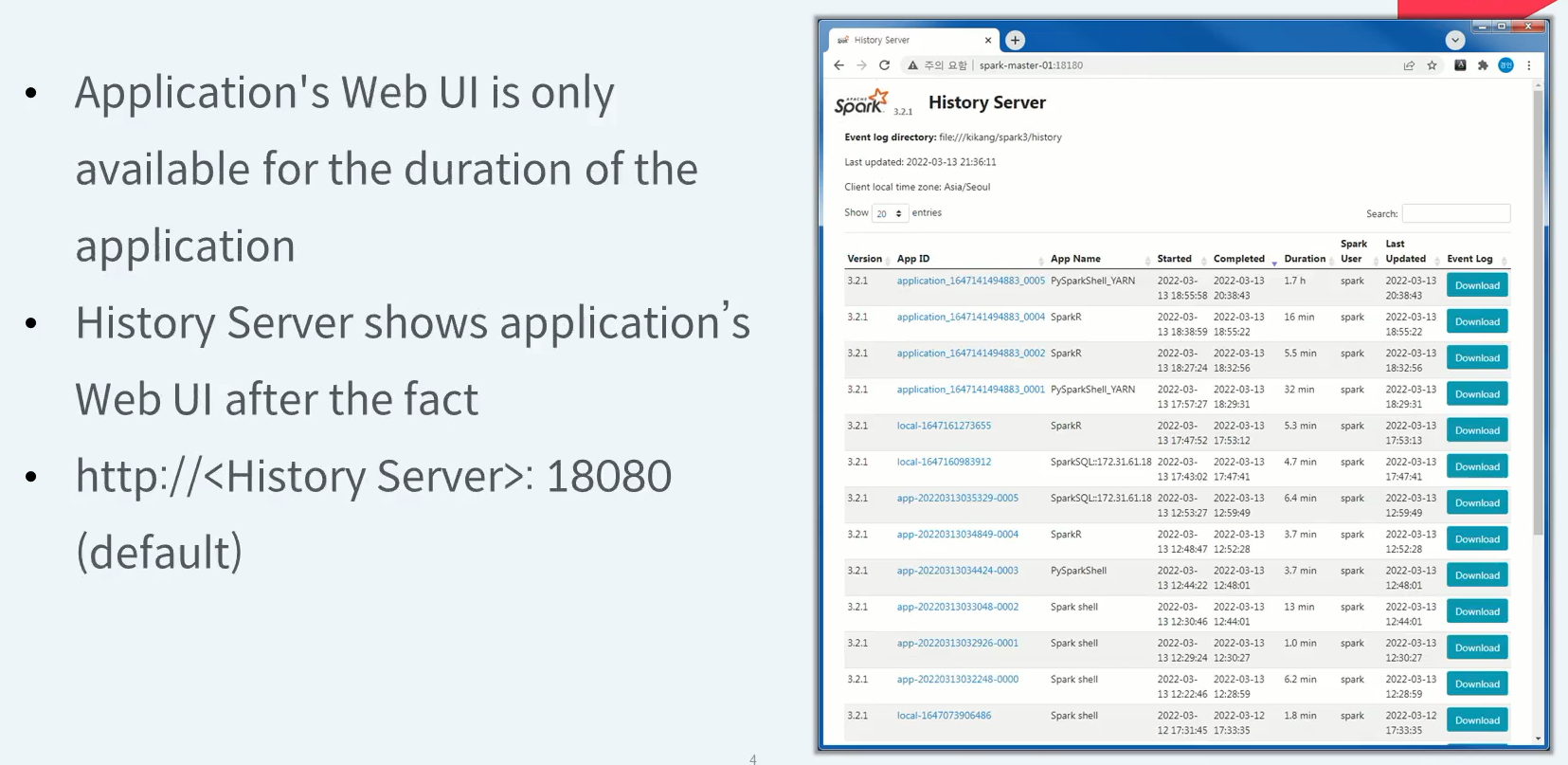
이미 실행이 끝난 Spark Applicaiton의 실행내역을 볼 순 없을까요?
Spark Applicaiton 실행 시 수행한 이벤트를 어딘가에 기록 한다면 볼 수 있다.
Spark Standalone Web UI
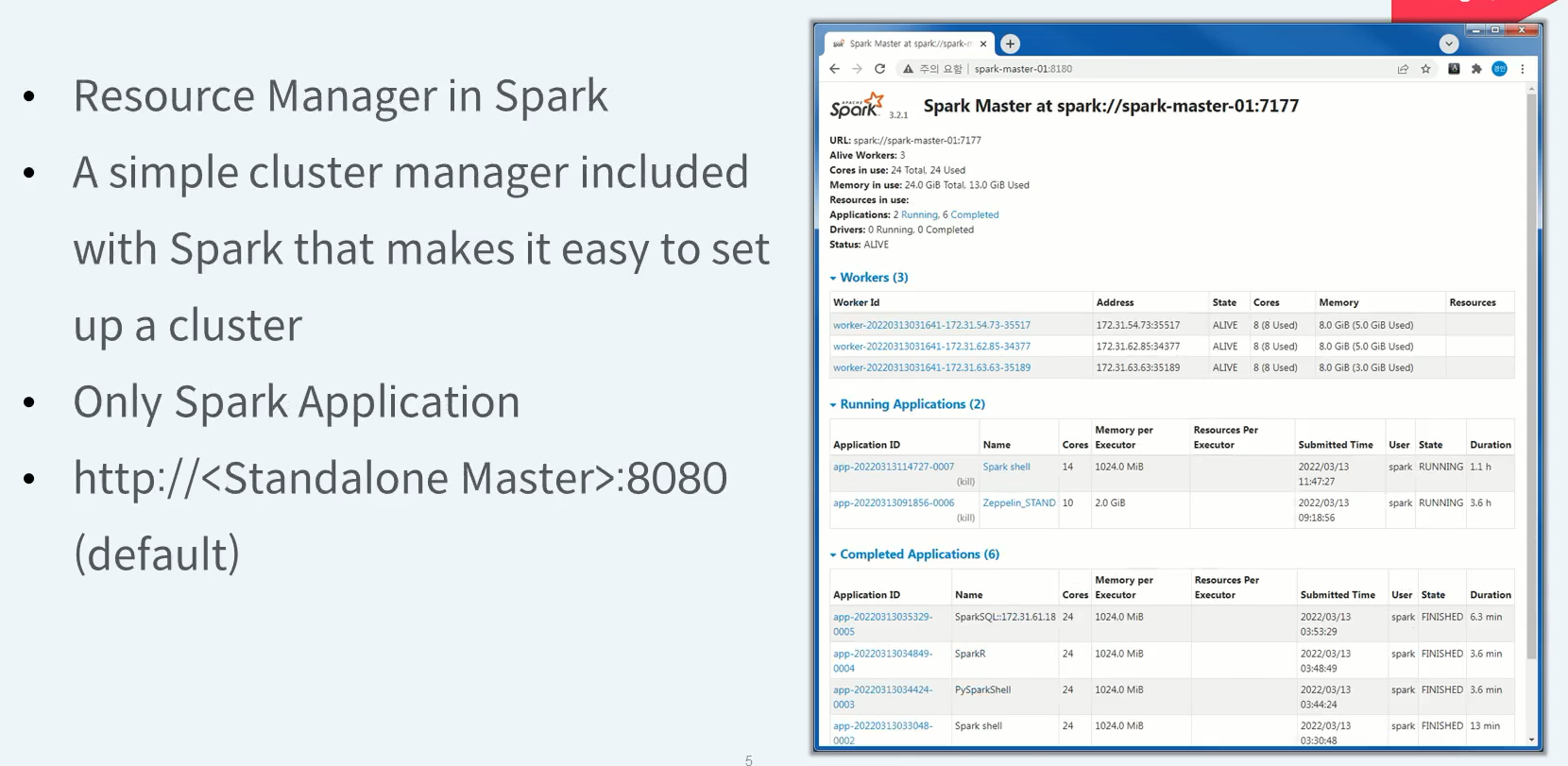
Spark 배포판 내부에 기본적으로 포함되어 있다.
빠르고 가벼운 Spark Application 전용 클러스터 매니저가 필요하다면 Spark Standalone 클러스터 매니저를 실행시키면 된다.
Hadoop YARN Web UI
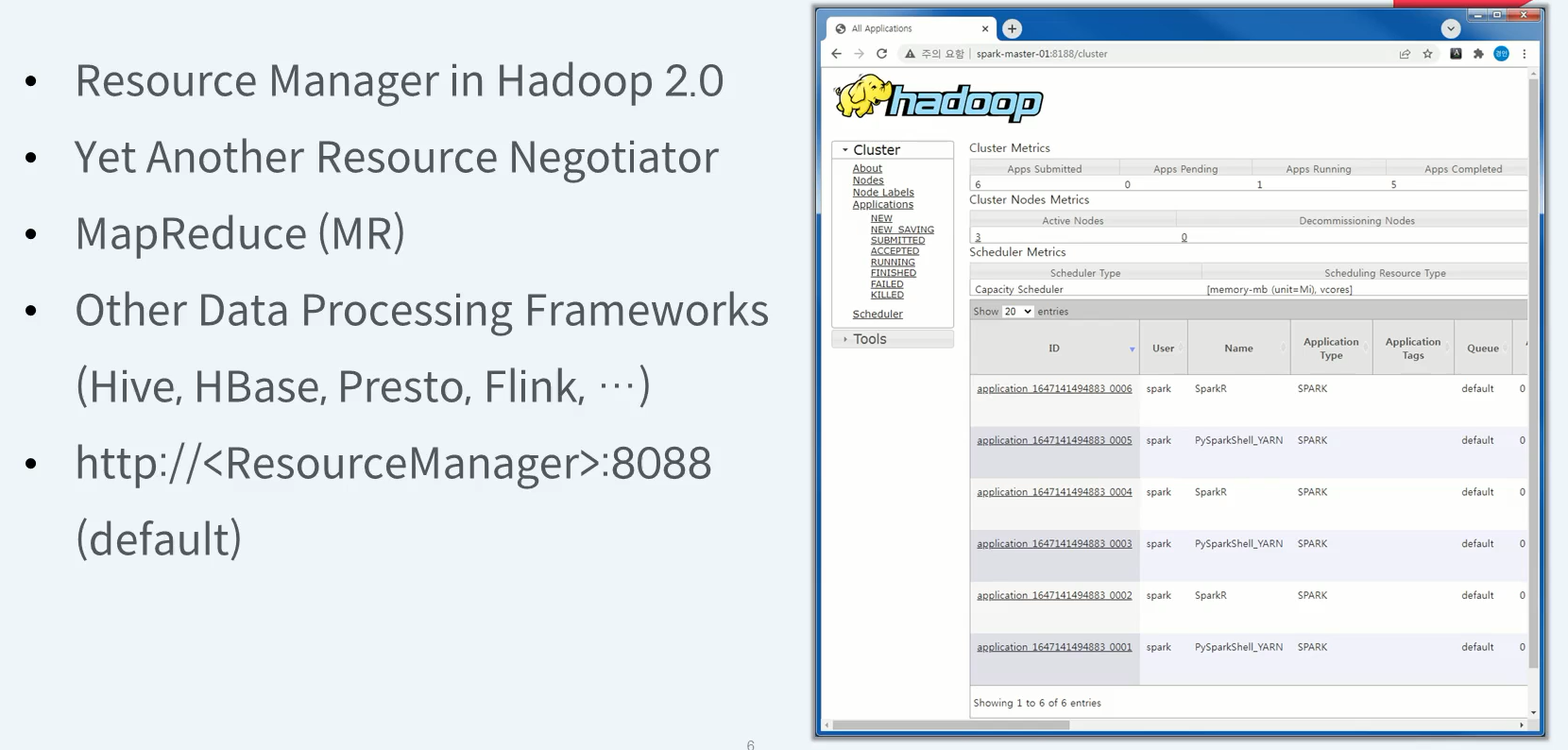
hadoop mapReduce 뿐만 아니라 클러스터 환경에서 구동 가능한 다양한 Application 플랫폼을 지원합니다. Spark을 포함하여 Hive, HBase, Presto, Flink 등이 있다
Spark 개요 (Spark vs. MapReduce)
Hadoop - on Disk .... Limitations
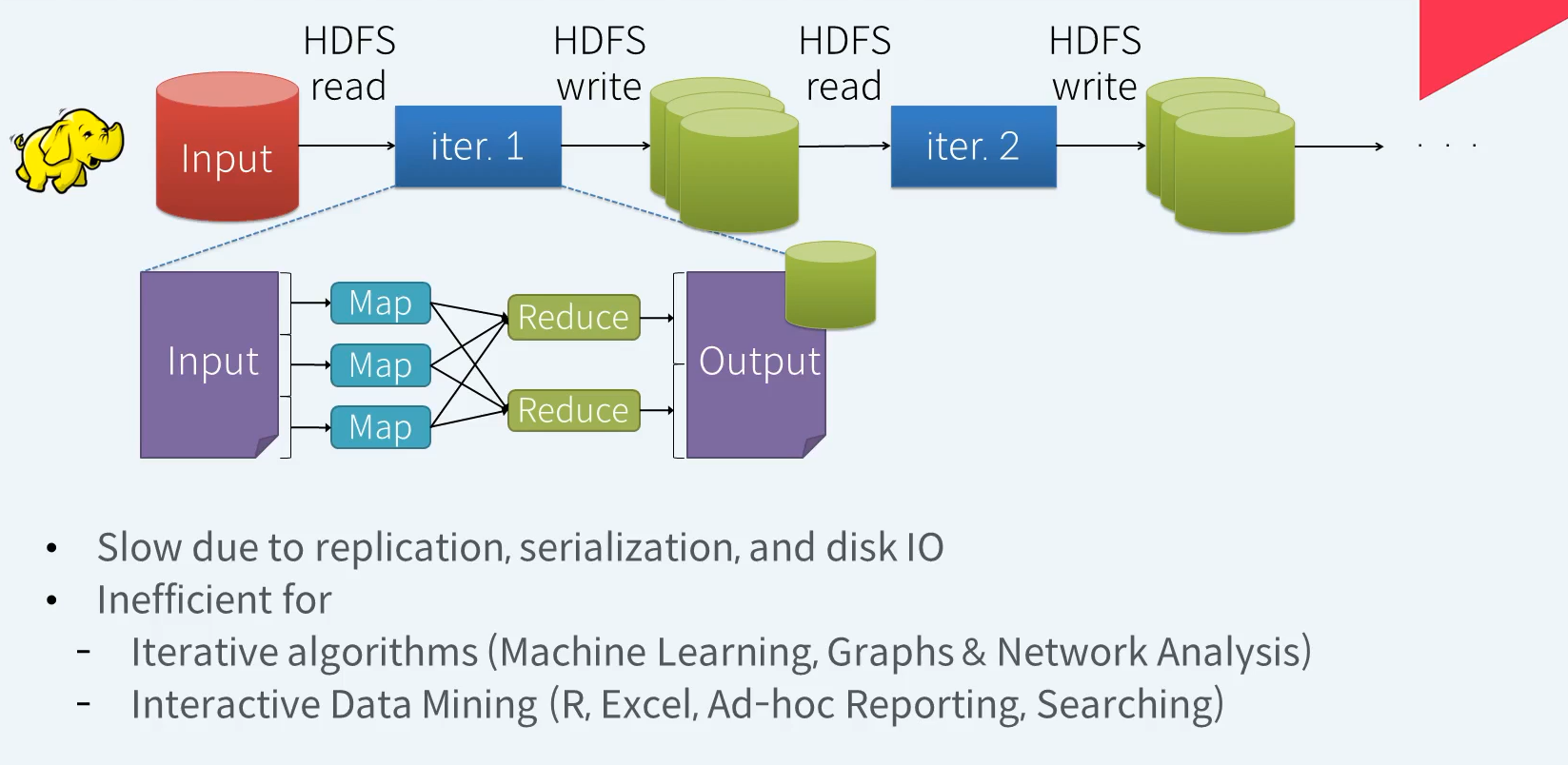
맵리듀스는 기본적으로 HDFS에서 데이터를 읽어 연산 처리 후 그 결과를 다시 HDFS에 기록합니다. 데이터 연산은 Map 과 Reduce 라는 2개의 스테이지로 구분되어 처리됩니다. 필요한 데이터 처리를 위해 이러한 Map과 Reduce작업을 반복하게 됩니다. 데이터 처리 결과를 HDFS에 Write할때 데이터는 복제되고 직렬화 되며 기본적인 Disk IO가 발생하기에 다소 느린편이다.
머신러닝, 그래프, 네트워크 분석과 같은 반복적인 연산을 필요로 하는 알고리즘을 처리하는데 있어서는 HDFS에서 데이터를 읽고 쓰는 MapReduce 작업을 반복해야 하기에 다소 비효율적인 처리방식이라 볼 수 있다.
대화영 데이터 마이닝 작업에도 그리 효율적이지 않다.
Spark - Solutions ? In Memory + DAG ...
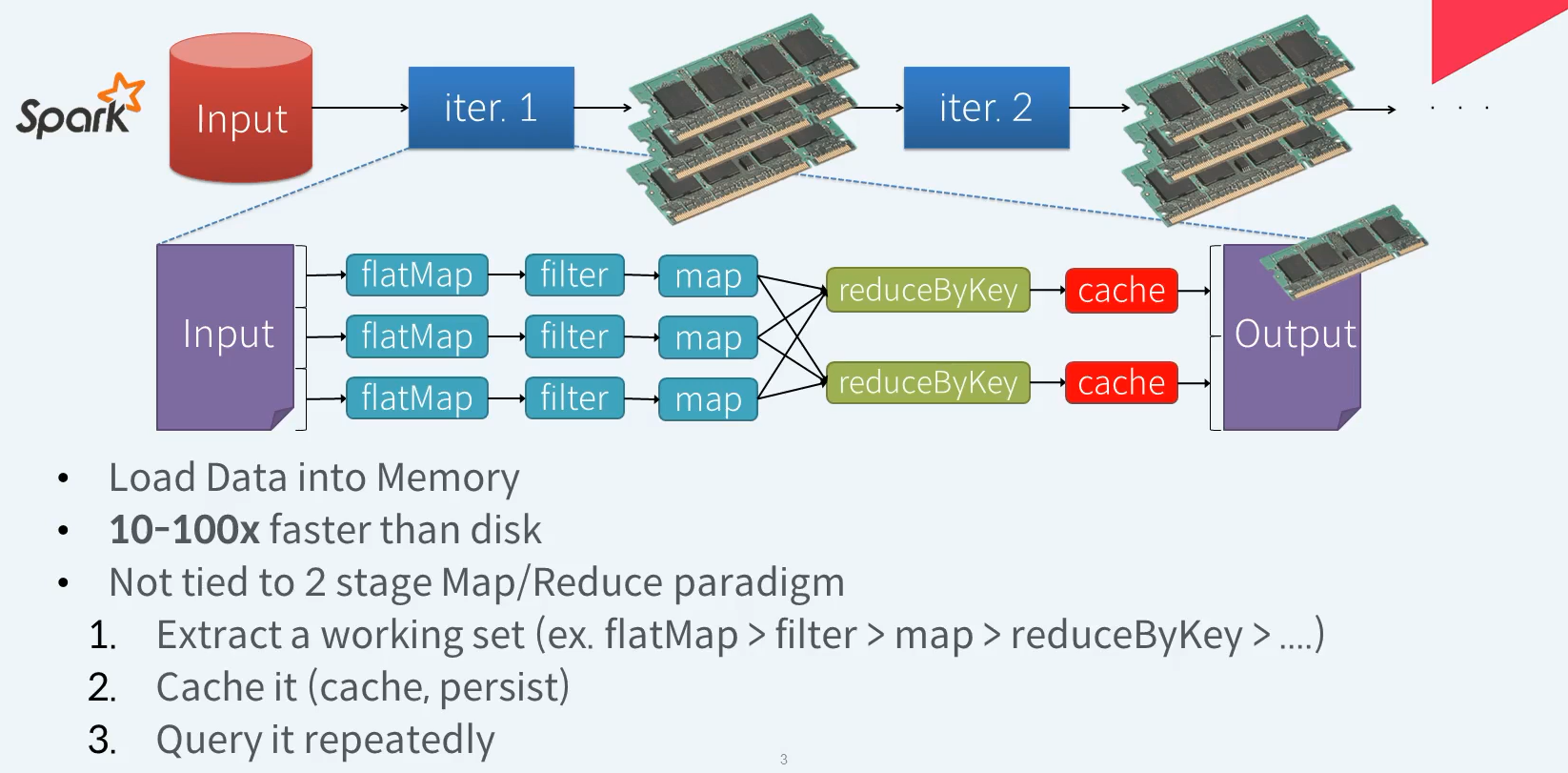
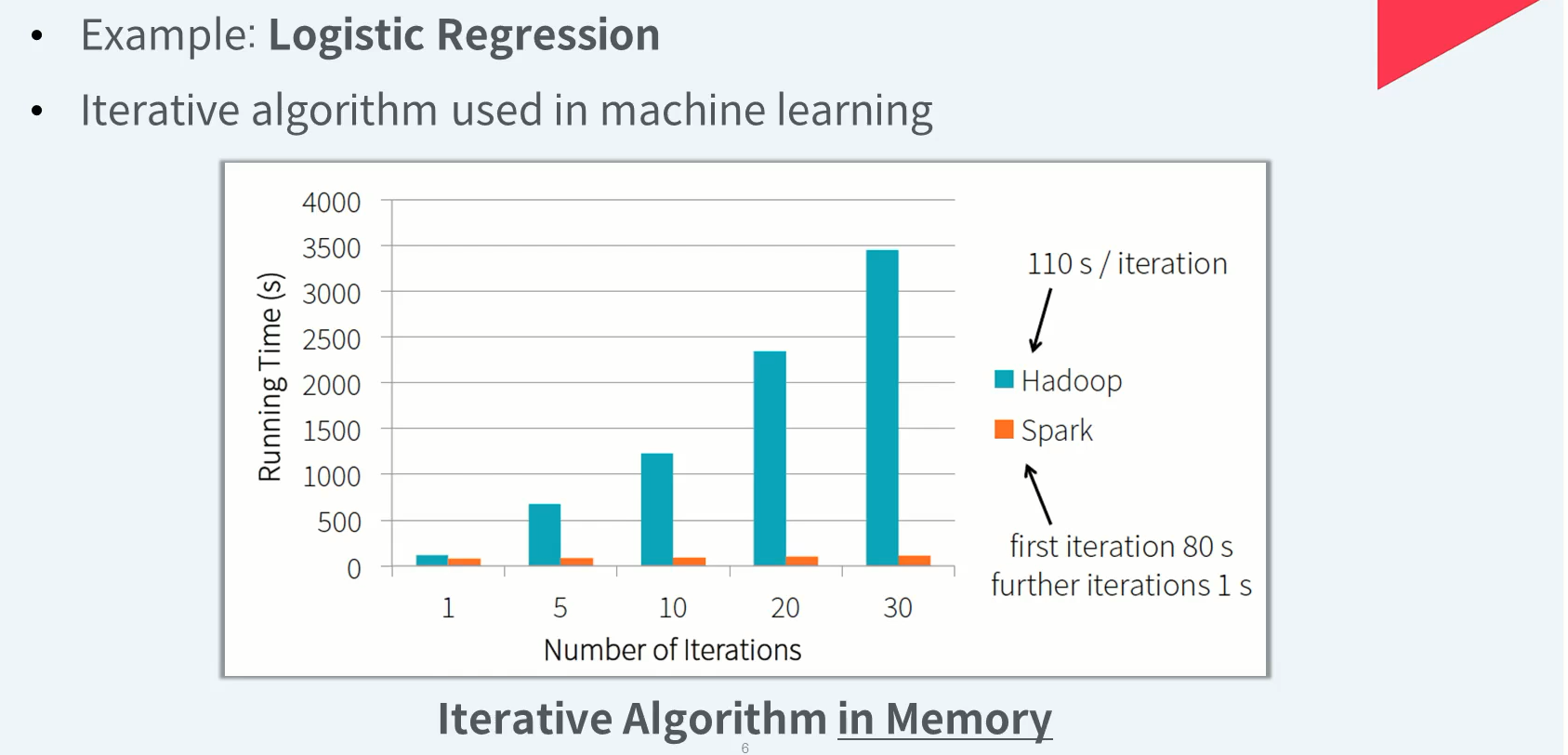
Spark은 반복적으로 사용하게 될 데이터를 메모리에 캐시 하여 디스크보다 빠르게 재사용할 수 있음. 디스크보다 10 ~ 100배정도 더 빠르다고 말함(참고용)
Spark은 데이터를 처리하는 방식도 Map과 Reduce라는 2개의 스테이지로 얽메이지 않음.
flatMap, filter, map, reduceByKey 다양한 상위레벨 API를 체인과 같이 연속적으로 사용하여 원하는 만큼 데이터에 대한 연산을 처리할 수 있다.
Spark vs Hadoop - Speed (1/3)

Spark vs Hadoop - Speed (2/3)

Spark vs Hadoop - Speed (3/3)
Spark vs Hadoop - Ease of Use (1/2)
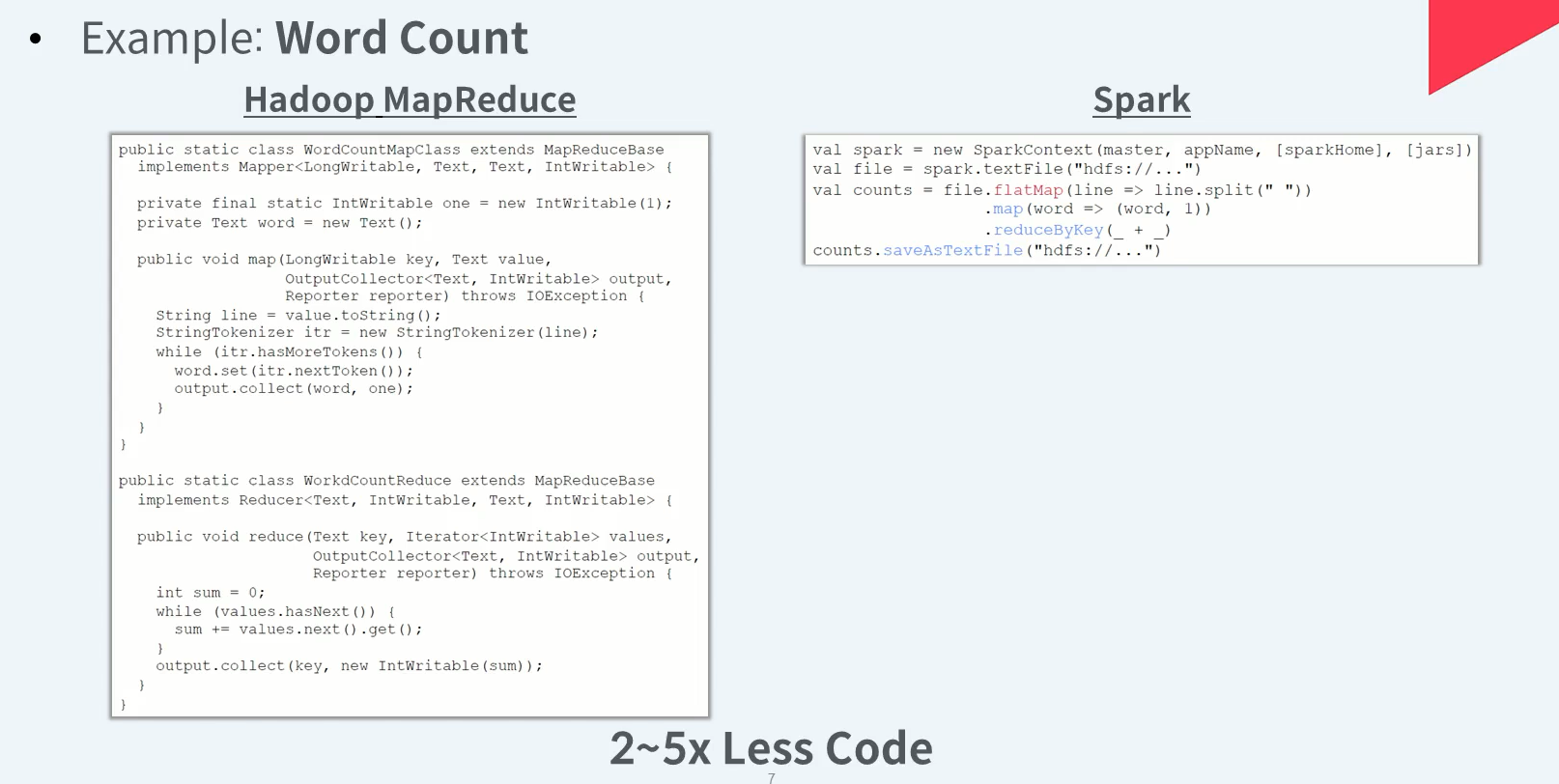
Hadoop MapReduce는 자바 언어를 이용하여 객체지향 방식의 코드로 작성해야한다.
Spark은 Scala, Java, Python, R과 같은 언어 기반으로 Spark이 제공하는 다양한 API를 사용하여 함수형 방식으로 코드를 작성하기에 상당히 간결한 코드를 유지할 수 있다.
Spark vs Hadoop - Ease of Use (2/2)

Spark은 기본적인 MapRduce를 포함하여 filter, group, join, sort 등 80여기 이상 다양한 연산을 위한 상위레벨 API를 통해 상대적으로 더 적은 노력만으로 원하는 데이터처리 코드를 보다 쉽게 작성 할 수 있다.
