lec12: NN의 꽃 RNN 이야기
Sequence data
- We don't understand one word only
- We understand based on the previous words + this word. (time series)
- NN/CNN cannot do this
우리가 사용하는 데이터중에서는 시퀀스 데이터들이 많이 있다. 음성인식이라던지 우리가 말하는 자연어를 보면 이게 하나의 데이터가 아니라 시퀀스로 되어있다.

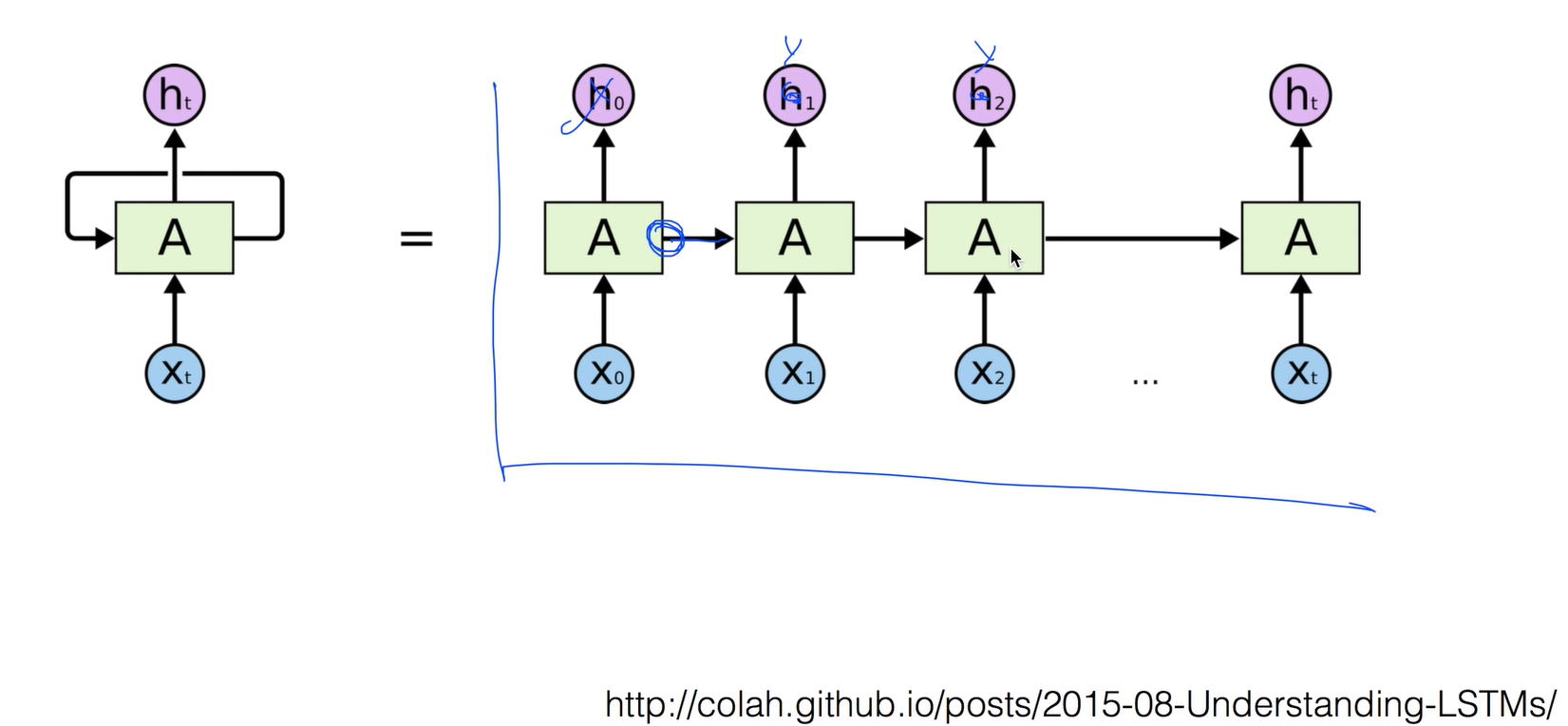
h는 y로 이해하길 바람.
이전에 계산한 State가 다음 계산에 영향을 미친다.
Recurrent Nurial Network
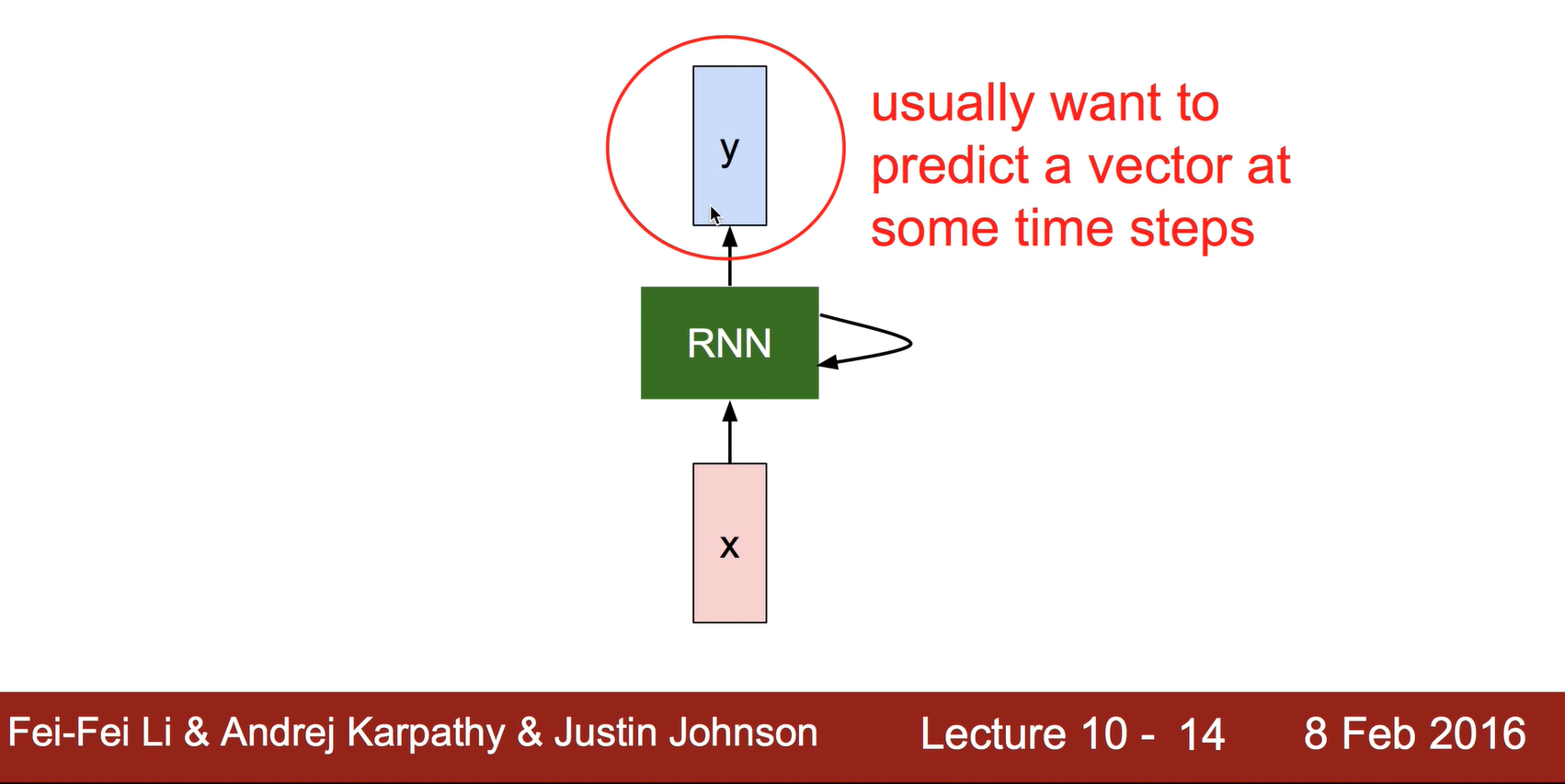
RNN은 수행해서 Y값을 뽑아내게 되는데 어떻게 계산하는 걸까요?

new State를 계산하는데 중요한것은 이전의 state(old State)가 입력으로 사용이 된다. X라는 입력값과 old State을 가지고 어떤 함수를 이용해서 계산을 한다.

주어진 function이 모든 RNN에서 동일하다
(Vanilla) Recurrent Neural Network

기초적인 RNN 연산 방법
Character-level language model example
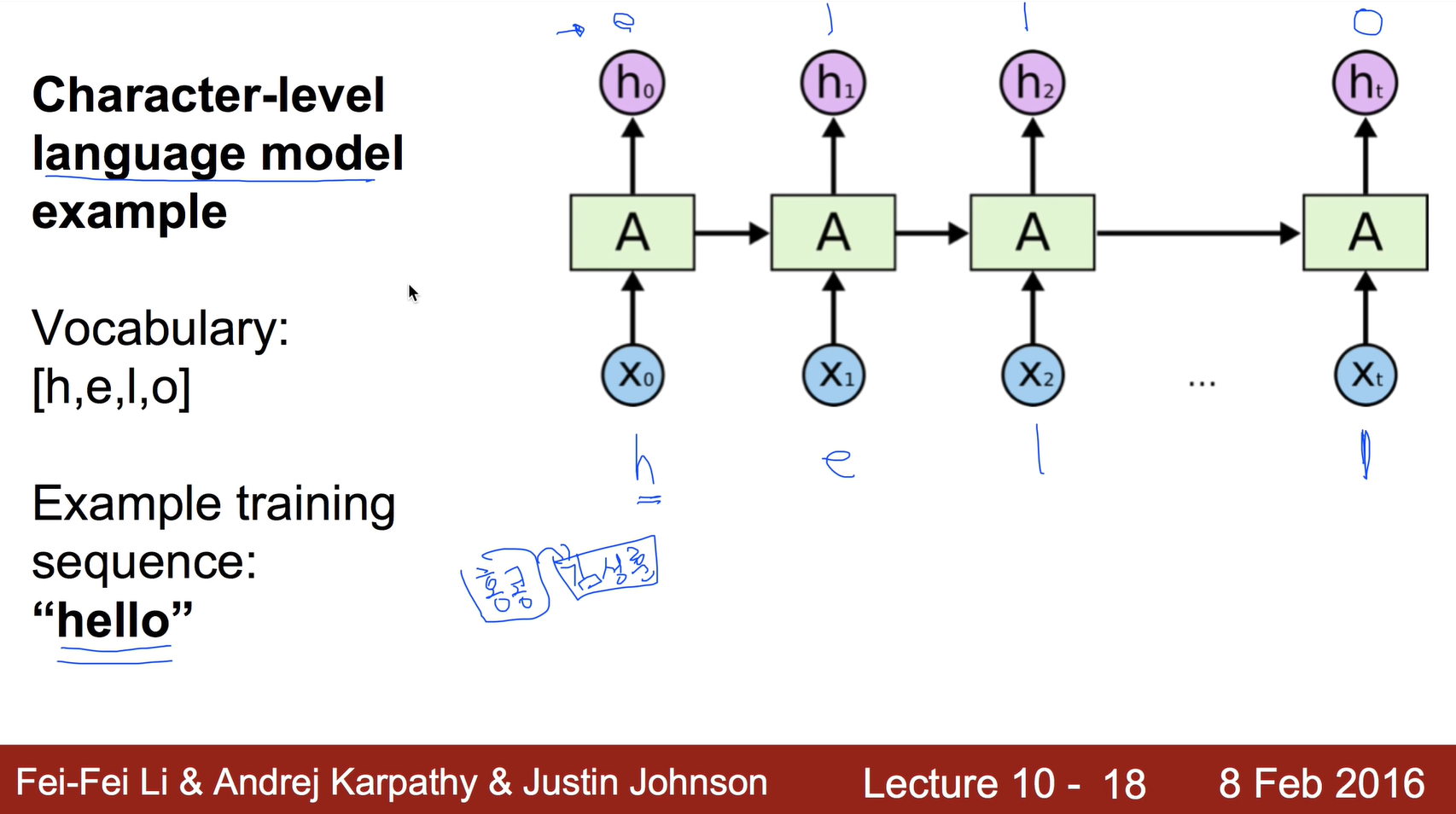
다음에 오는 글자를 예측하는 시스템을 language model
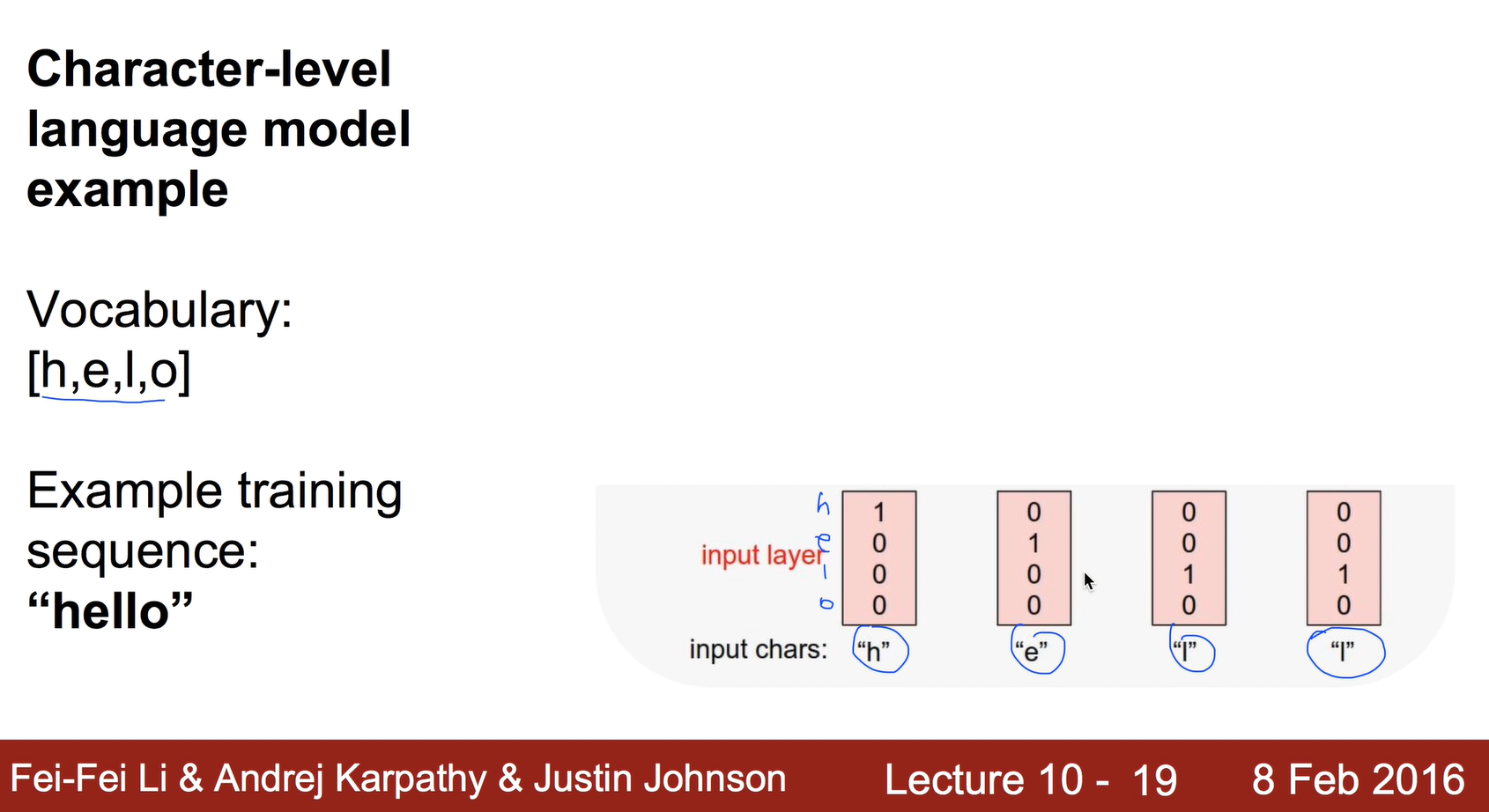
벡터로 표현하는 방법은 여러가지가 있는데 그 중 쉬운 방법은 One-hot Encoding
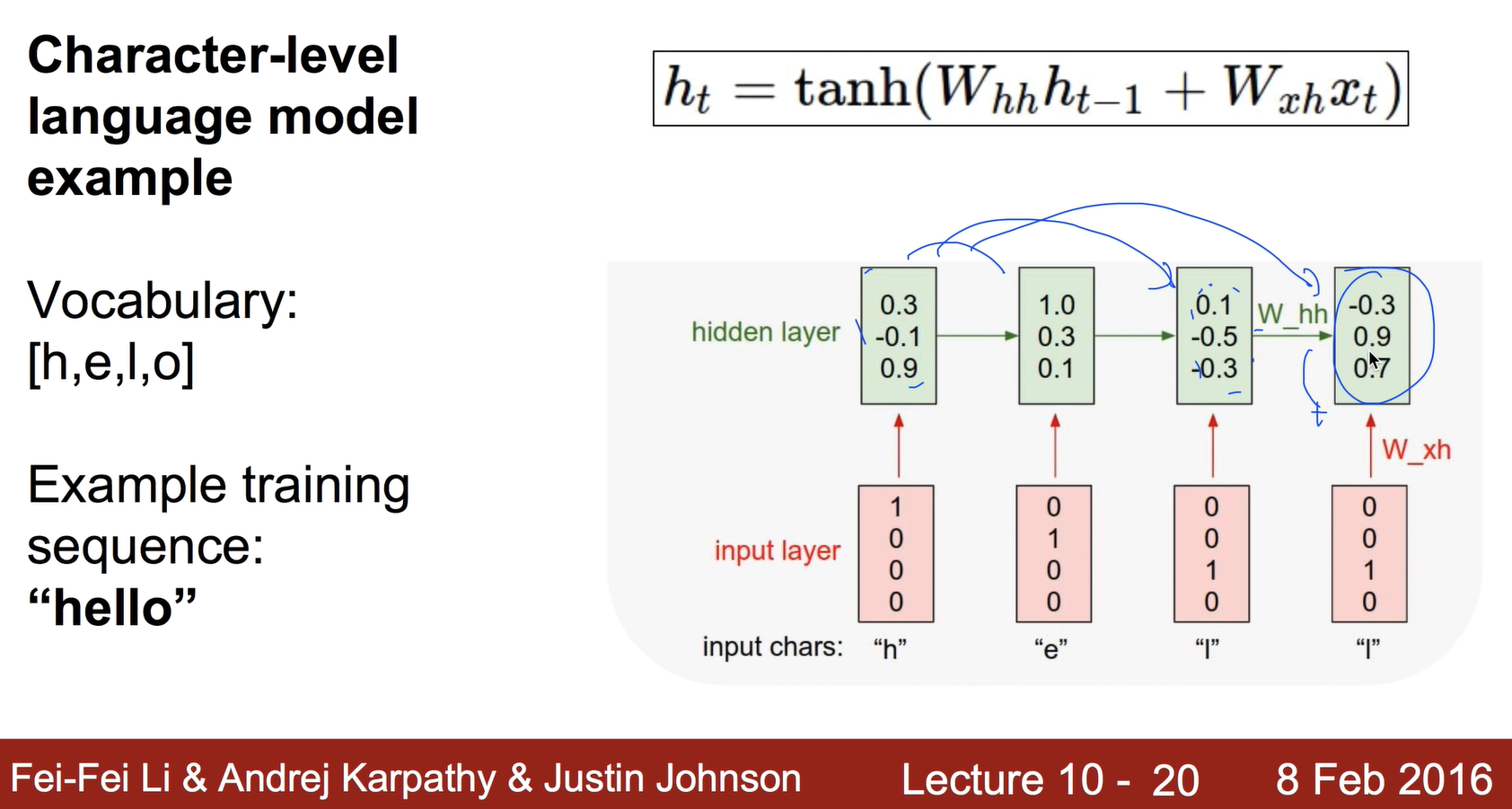
첫번째 hidden layer에는 이전 state 값이 없으니까 0으로 준다.
어떻게 보면 RNN이라는 것은 이전의 것들을 기억한다라는 의미가 있다.
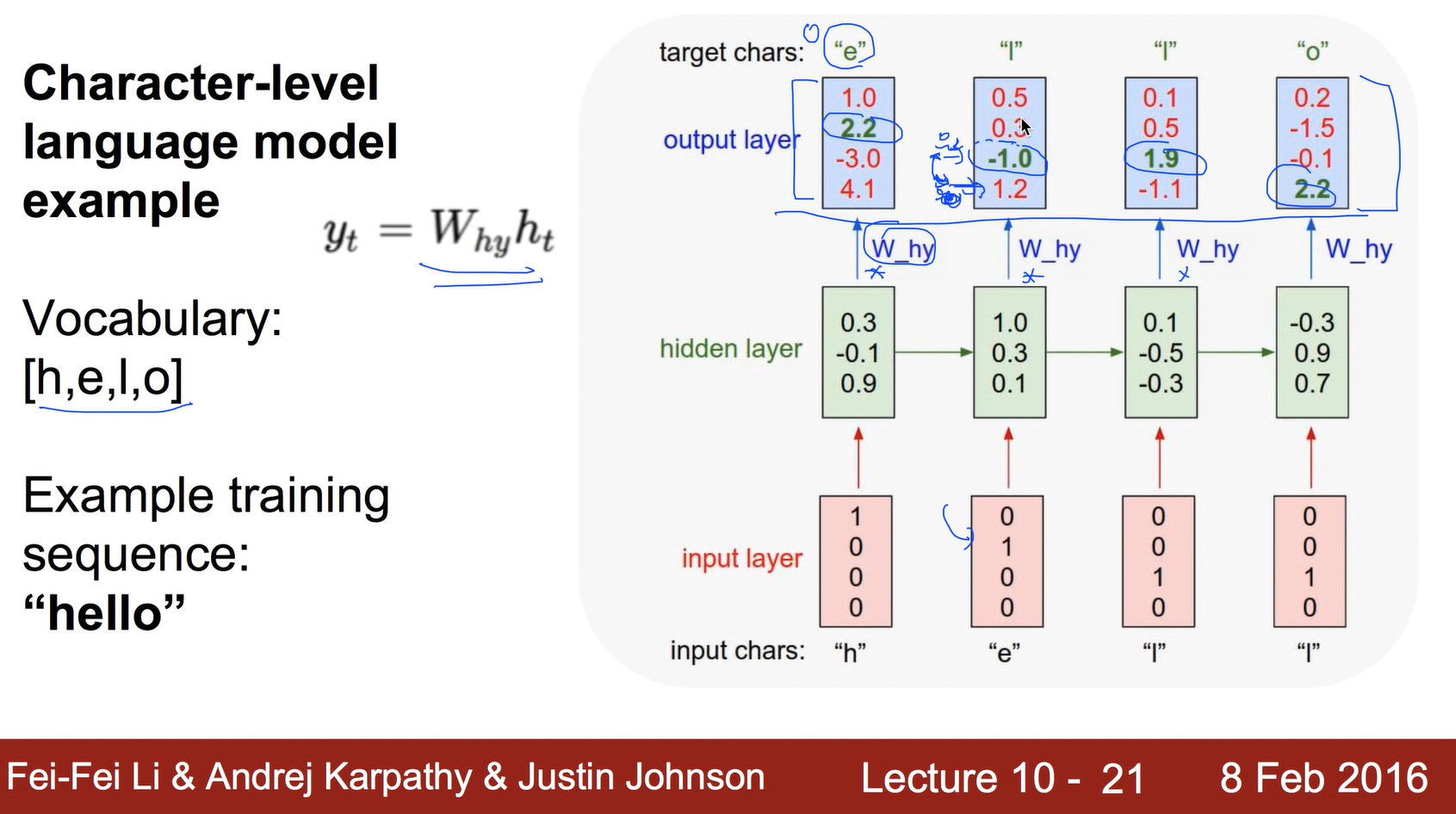
Y를 구하는 식
RNN applications
활용하는 방법이 굉장히 다양하다.
다음 단어를 예측하는 Language Modeling
Recurrent Networks offer a lot of flexibility
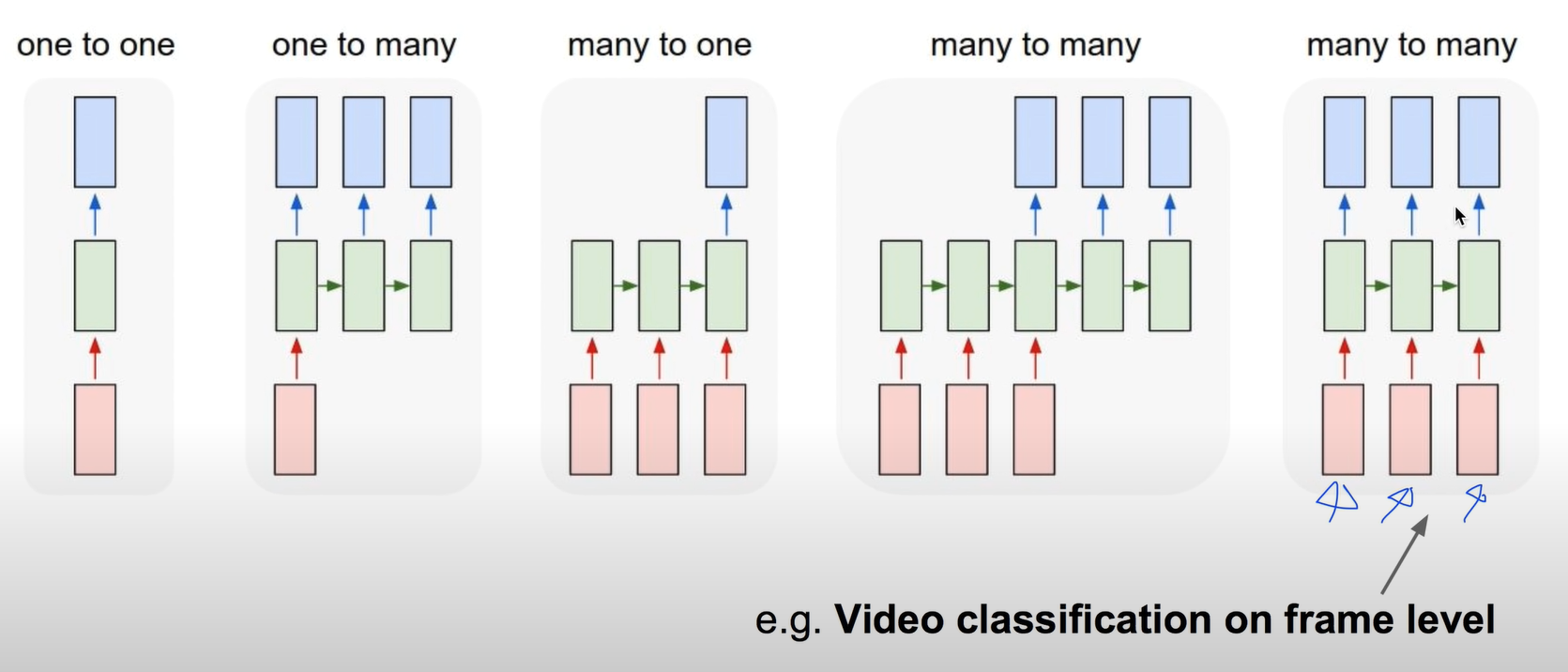
RNN을 가지고 여러가지 형태를 구성할 수 있따.
Image Captioning : sequence of words
Sentiment Classification : many to one
Maching Translation : many to many
Video classification on frame level : many to many
Multi-Layer RNN
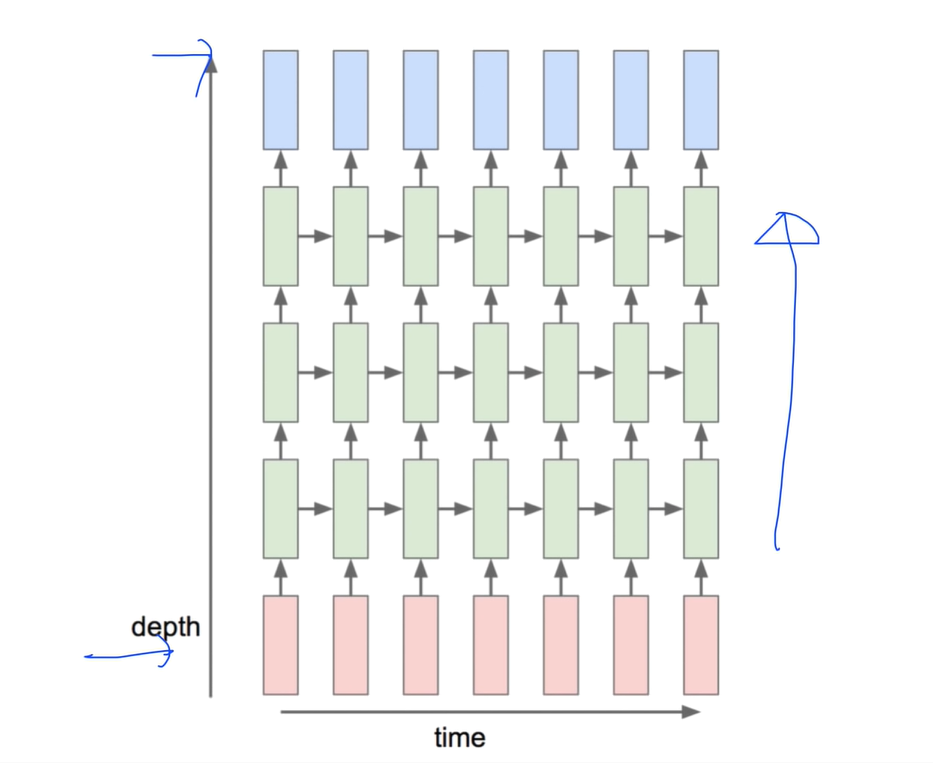
layer도 하나만 줄 수 있지만 여러개도 줄 수 있어서 더 복잡한 학습이 가능하다.
Training RNNs is challenging

