데이터 파이프라인
데이터 파이프라인 오케스트레이션
오케스트레이션이란?
- 여러 개의 컴퓨터 시스템, 애플리케이션 또는 서비스를 조율하고 관리하는 것
- 복잡한 태스크와 워크플로를 쉽게 관리할 수 있도록 도와줌
데이터 파이프라인 오케스트레이션
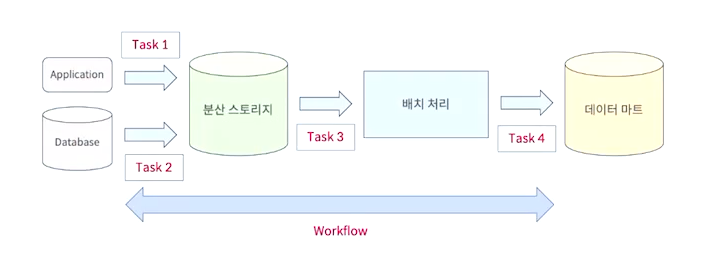
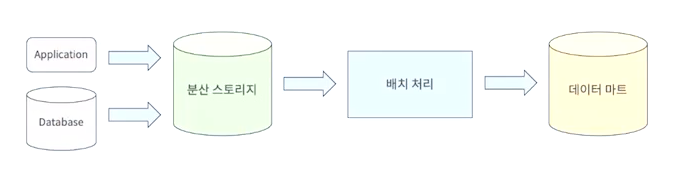
- 각 단계마다 데이터가 이동되면서 정해진 처리를 수행하고 해당 작업을 반복해서 수행한다
- 각각의 실행되는 개별처리를 Task라고 한다.
- 여러 태스크들을 실행하면서 연속적으로 데이터를 처리하는 것을 Workflow라고 한다.
워크플로 관리 도구의 필요성
- 스크립트의 한계
- 워크플로가 복잡
- 태스크의 의존 관계가 복잡
- 실패 시 처리 어려움
워크플로 관리 도구 기능
- 스케줄링
- 태스크 의존 관계 정의
- 실행 결과 알림 및 보관
- 실패 시 재실행
DAG(Directed Acyclic Graph)
DAG란 ? : 특정 기술같은게 아니라 컴퓨터 알고리즘에서 사용되는 데이터모델이다
DAG 특징
- 방향성 (Directed)
- 간선에 방향이 존재
- 비순환 (Acyclic)
- 그래프의 한 정점에서 시작하여 다시 시작 정점으로 이어지는 간선이 존재하지 않음
- 사이클이 존재하지 않음
DAG의 예

- 게임에서 사용하는 스킬트리가 대표적인 예
- 특정 스킬을 활성화 하기 위해서는 시작지점의 스킬부터 해당 스킬까지 순서에 맞춰서 찍어줘야하는 특성을 가지고 있음
Task들의 의존관계
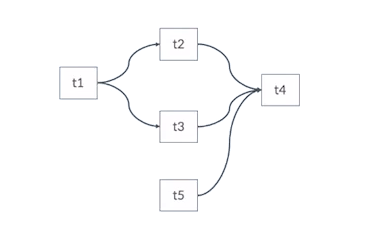
- 실제 태스크들의 의존관계를 표현하는 그림
대부분의 워크플로 엔진은 태스크의 의존관계를 DAG으로 표현한다.
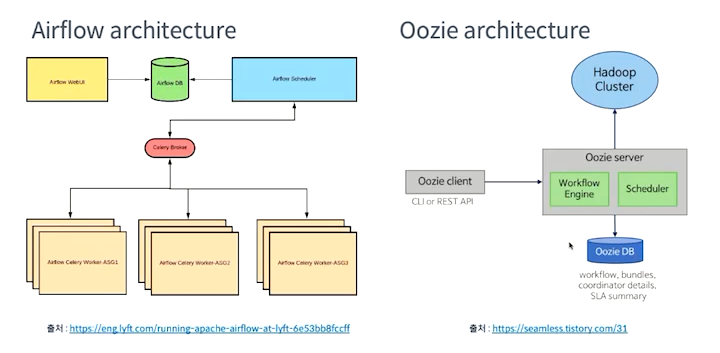
DAG 을 표현하는 방법
Airflow

에어플로는 의존관계를 파이썬으로 작성하기 때문에 파이썬 프로그래밍을 통해서 다양한처리가 가능해지는 장점이 있다.
Oozie (아파치 우지)
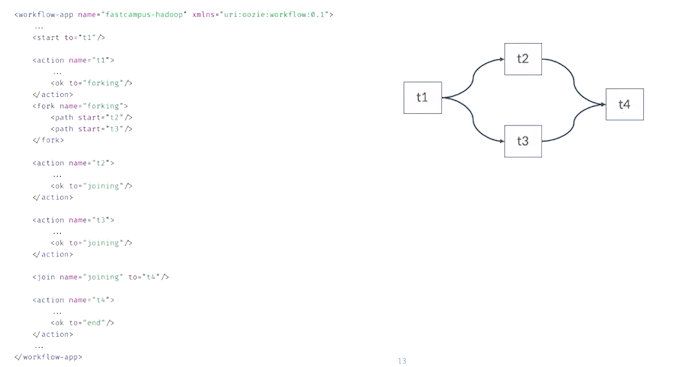
- XML로 워크플로를 정의한다.
- XML로 정의하는 경우 에어플로랑 다르게 우지에서 제공하는 기능만 사용할 수 있다
- XML로 표현하는 경우 코드가 길어지는 단점도 있다.
- 반면에 XML로 작성하게 되는 경우 워크플로를 누구나 동일하게 작성하므로 협업이나 유지보수에 용이하다
실행 결과 알림 및 보관
복구
실패 시 복구 방법
재시도
- 재시도의 경우 네트워크나 리소스 할당 문제와 같은 일시적인 문제를 대응하기에 유용하다
- 재시도 횟수가 너무 많으면 태스크의 오류로 인한 실패사항을 늦게 발견해서 대응이 늦어지는 문제가 발생할 수 있다.
- 재시도는 보통 2~3회정도 하는것을 추천
backfill
- backfill이란 일정기간동안 워크플로를 재실행하는 기능
- 새로운 워크플로를 만들고 과거부터 실행하고 싶을때 backfill을 실행함
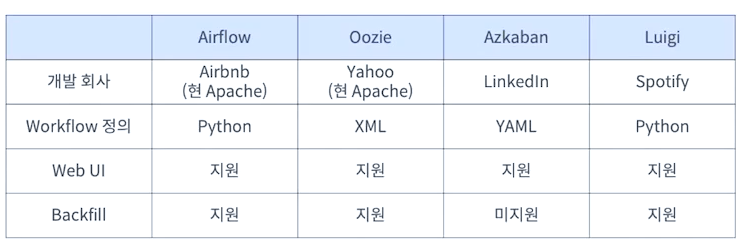
오픈소스 워크플로 관리 도구 비교
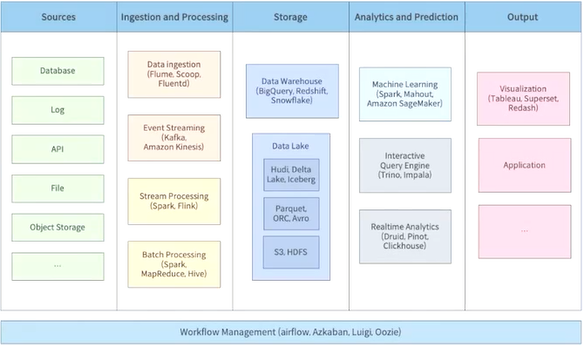
빅데이터 플랫폼과 Hadoop ecosystem
Hadoop
- 분산 파일 시스템
- HDFS(Hadoop Distributed File System)
- 리소스 관리자
- YARN(Yet Another Resource Negotiation)
- 분산 데이터 처리
- MapReduce
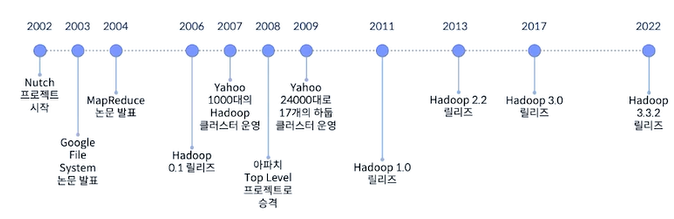
Hadoop의 역사
Hadoop ecosystem
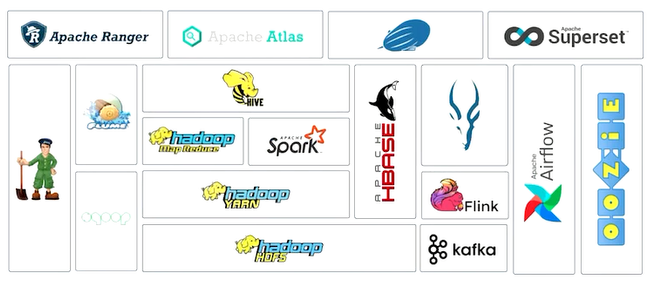
데이터 수집에 대표적인 프로젝트 : 아파치 Flume, Sqoop, 이벤트관련 수집을 위한 kafka
데이터 처리에 관련된 프로젝트 : 하둡 맵리듀스, 아파치 Spark, Hive, 임팔라, Flink
데이터 저장을 위한 프로젝트 : HDFS
워크플로 관리도구 : Airflow, Oozie
HBASE : HDFS상의 칼럼 기반 No-Sql 데이터베이스
주키퍼 : 하둡 에코시스템은 대부분 분산 시스템으로 동작하는데 이런 분산환경에서 서버간의 향후조정이 필요한데 이를 처리하기 위한 프로젝트
Apache Ranger : 하둡 에코시스템의 보안기능을 제공
Apache Atlas : 메타데이터를 관리하는 프로젝트
Apache Zeppelin : 웹 기반의 노트북, 대화형 분석을 손쉽게 해주는 프로젝트
Apache Superset : 웹 기반의 데이터 시각화 기반 툴
빅데이터 플랫폼과 Hadoop ecosystem
Hadoop cluster 구축 고려사항
클러스터(cluster)란?
- 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합
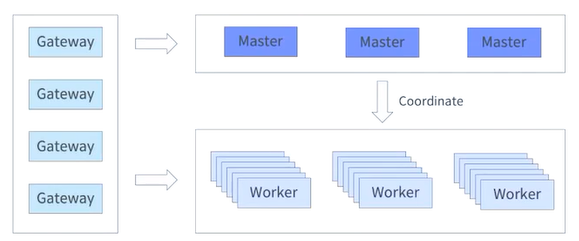
Master / Worker Architecture
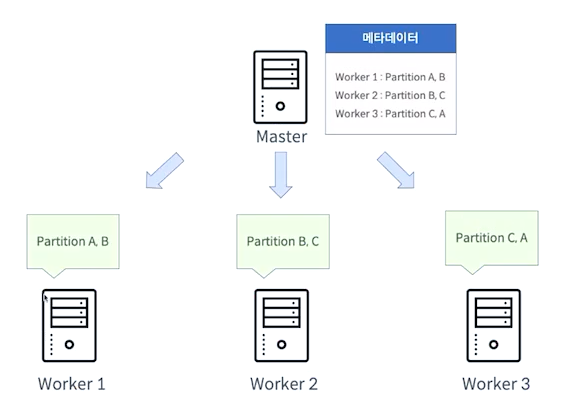
- Worker3에 장애가 나더라도 Worker3가 가진 데이터는 Worker1과 2가 나눠서 가지고 있기에 문제없이 동작이 된다.
- 하둡은 마스터 워커 구조처럼 되어있다.
클러스터 규모 결정하기
- 스토리지 용량으로 결정하기
- 저장될 데이터 크기 예측
- 복제 전략 결정
- 저장 기간 고려
- 필요한 노드 수 결정
- 스토리지 용량으로 결정하기 - 추가 고려사항
- 데이터 포맷
- 데이터 압축 여부
- 데이터 증가율의 변화
예시
- 저장될 데이터 크기 예측
- 하루에 저장되는 데이터 크기는 1TB
- 복제 전략 결정
- 복제 계수는 3
- 저장 기간 고려
- 3년
- 필요한 노드 수 결정
- 서버 한대의 저장 용량 : 5TB * 12
- 약 70대
클러스터 하드웨어 결정
- 워크로드에 따른 하드웨어 선정
- CPU
- Memory
- I/O
Apache Hadoop
Overview
Hadoop 구성요소

Hadoop 1 vs Hadoop 2
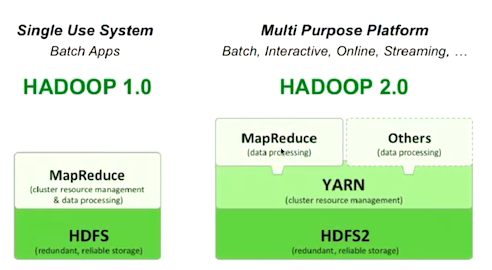
-
Hadoop1 같은 경우 HDFS랑 MapReduce 2개의 컴포넌트만 존재
-
Hadoop2 중간에 YARN이 추가되어서 MapReduce 뿐만아니라 다른 애플리케이션을 하둡 위에서 동작 시킬 수 있는 환경을 제공함.
Hadoop 1 architecture
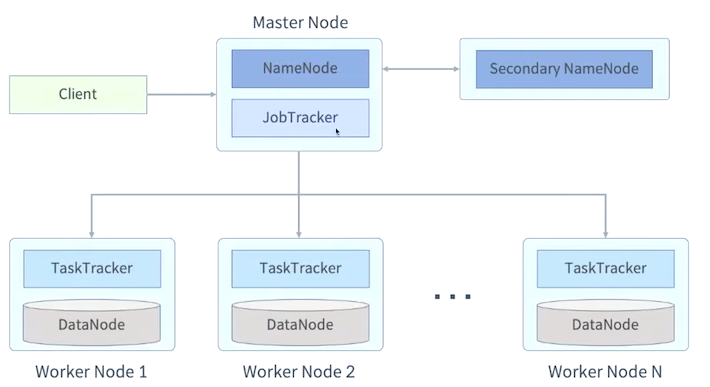
Hadoop1의 문제점
- 네임노드가 단일장애지점이다, 물론 세컨더리 네임노드가 존재하지만 동기화의 시간차이가 존재하기 때문에 일부 데이터가 유실될 수 있다.
- 잡트래커 역시 클러스터 전체 리소스를 관리하기 때문에 잡의 상태나 태스크의 할당 같은 작업들을 잡트래커에서 모두 하고 있기 때문에 부하가 많이 발생한다
- 맵리듀스 외에도 다른 작업들을 실행 할 수 없다.
Hadoop 2 architecture
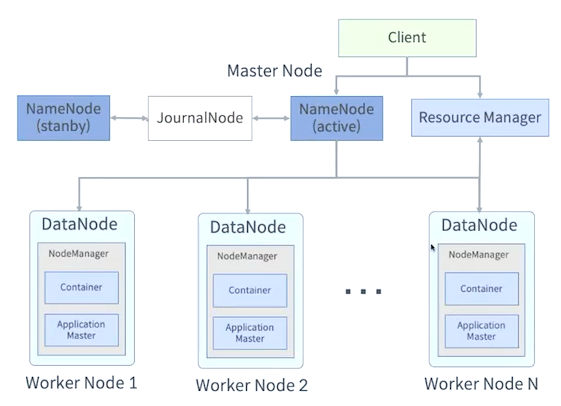
Hadoop 3
- Erasure Coding 지원
- YARN Timeline Service v2 도입
- Java 8
- NameNode 이중화 기능 강화
HDFS
분산 파일 시스템
- 네트워크로 연결된 여러 머신의 스토리지를 관리하는 파일 시스템
Google File System(GFS)
- 2003년에 논문으로 소개
- 마스터 / 워커 구조
- HDFS의 모태
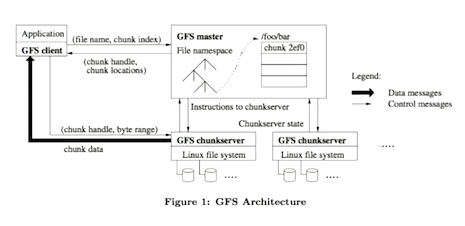
HDFS(Hadoop Distributed FileSystem)
특징
- 범용 하드웨어를 사용하여 분산 파일 시스템 구성
- 블록 단위 저장
- 마스터 / 워커 구조
- 내고장성(Fault-tolerance) 제공
- 데이터를 복제하여 일부 장애가 발생하더라도 계속 서비스를 할 수 있음
- 확장성 제공
HDFS Block
- 하나의 파일을 여러 블록으로 저장
- Hadoop2에서는 기본 블록 사이즈가 128MB(Hadoop1은 64MB)
- 실제 파일 크기가 블록 사이즈가 적은 경우 파일 크기만큼만 디스크 사용

왜 HDFS Block은 클까?
- 일반적인 디스크 블록에 비해 큼 (128MB)
- 탐색 비용 최소화
- 하드 디스크에서 블록의 위치를 찾는데 걸리는 시간이 적게 걸림
- 블록의 시작점을 탐색하는데 적게 걸림
- 메타 데이터 크기 감소
Block 단위 처리 이점
- 파일 하나의 크기가 실제 하나의 물리 디스크 사이즈보다 커질 수 있음
- 스토리지 관리 단순화
- 내고장성과 가용성을 지원하는 복제 기능 지원 적합
NameNode와 DataNode
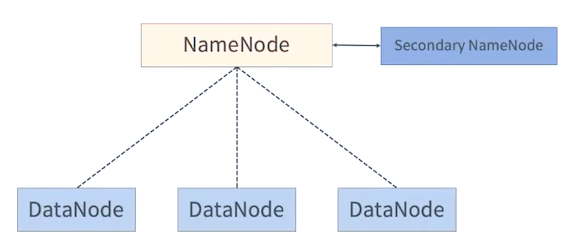
- NameNode는 파일시스템의 메타데이터를 가지고 있음
- 메타데이터는 어떤 데이터 노드에 어떤 블록 데이터 정보가 들어있는지 이와 같은 정보를 말함
NameNode
- 메타데이터 관리
- FsImage(파일 시스템 이미지): 네임스페이스를 포함한 데이터의 모든 정보
- EditLog: 데이터노드에서 발생한 데이터 변환 내역
- 데이터 노드 관리
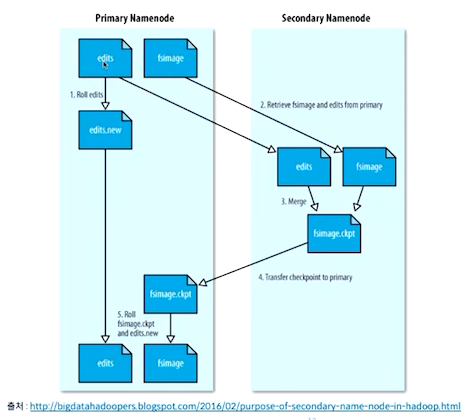
Secondary NameNode
- NAmenode의 Standby 역할이 아님
- 체크 포인트
- FsImage와 EditLog를 주기적으로 병합
- 주기적으로 NameNode의 FsImage를 백업
DataNode
- 실제 파일을 로컬 파일 시스템에 HDFS 데이터를 저장
- 하트비트를 통한 데이터 노드 동작 여부 전달
- 저장하고 있는 블록의 목록을 주기적으로 네임노드에 보고
NameNode와 DataNode
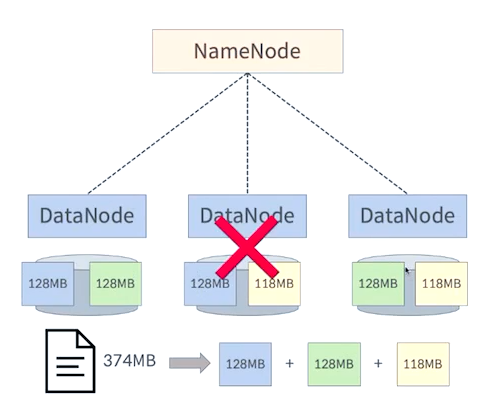
DataNode 하나가 장애가 발생이 나도 이와 같이 복제본을 가지고 있기 때문에 문제없이 데이터를 읽을 수 있는 이점이 있다.
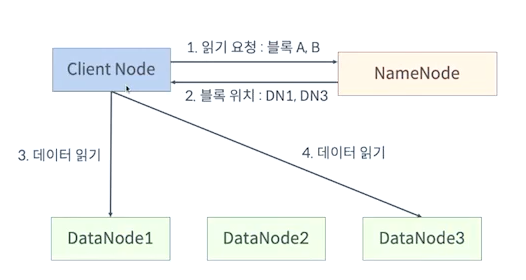
HDFS 읽기 연산
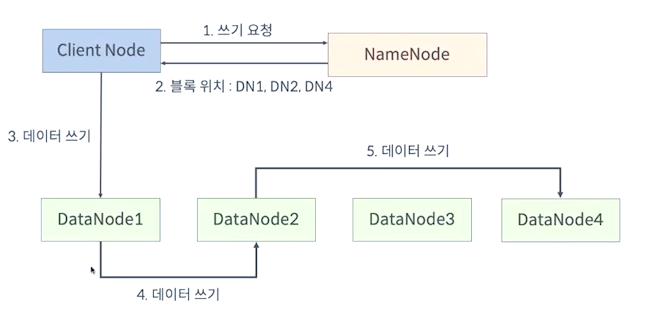
HDFS 쓰기 연산
HDFS 추가 특징
- 블록 캐싱 기능 제공
- HDFS Federation 지원
- 고가용성(HA) 지원
