
선택정렬
- 제자리 정렬 알고리즘의 하나
- 입력 데이터 이외에 다른 추가 메모리를 요구하지 않음
- 알고리즘이 단순하고 사용할 수 있는 메모리가 제한적인 경우에 사용시 성능 상의 이점이 있다
- 시간 복잡도가 Best, Average, Worst에서 모두 O(n^2)이다.
선택정렬 알고리즘의 과정
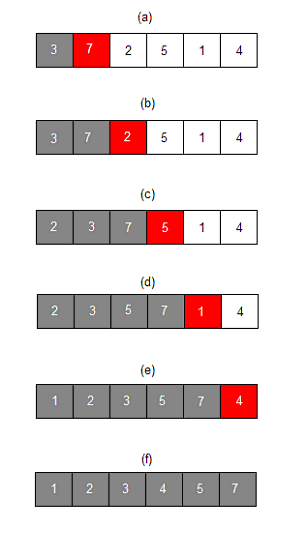
- 주어진 리스트 중에 최소값을 찾는다.
- 그 값을 맨 앞에 위치한 값과 교체한다(패스(pass)).
- 맨 처음 위치를 뺀 나머지 리스트를 같은 방법으로 교체한다.
예시
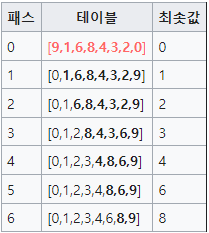
출처 : 위키백과
출처 : 위키백과
선택정렬 알고리즘의 특징
-
자료 이동 횟수가 결정된다.
-
2번째, 3번째 등 k번 째로 큰 값을 찾는 경우 유용하게 사용할 수 있다.
- 이 때의 시간 복잡도는 O(kn)
- 비안정 정렬이다
- 같은 값의 상대적인 위치가 변경될 수 있다.
선택정렬 코드화
public class Selection_Sort {
public static void main(String[] args) {
// 선택정렬 알고리즘(Selection Sort Algorithm)
int[] arr = {9, 1, 6, 8, 4, 3, 2, 0};
for(int i = 0; i < arr.length; i++) {
// +1을 하는 이유는 자기와 비교할 필요가 없기 때문
for(int j = i + 1; j < arr.length; j++) {
// '>' 일 경우 오름차순 '<' 일 경우 내림차순
if(arr[i] > arr[j]) {
int temp = arr[i]; // 값 변경해야 하기에 임시 저장
arr[i] = arr[j]; // j를 i로 변경
arr[j] = temp; // i를 j로 변경
}
}
}
for(int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " "); // 정렬 후 결과 출력
}
}
}버블정렬
- 인접한 두 항목의 값을 비교해서 일정한 기준을 만족하면 서로의 값을 교환하여 정렬하는 방식이다. 예를 들어, 오름차순 정렬은 두 항목의 값을 비교하여 앞쪽 값이 더 크면 두 항목의 값을 교환하고 내림차순 정렬은 두 항목의 값을 비교하여 앞쪽 값이 더 작으면 두 항목의 값을 교환하는 방식입니다.
예시

출처 : https://play.google.com/store/apps/details?id=wiki.algorithm.algorithms&hl=ko&gl=US
버블정렬 알고리즘의 특징
- 장점 : 인접한 값만 계속해서 비교하는 방식으로 구현이 쉬우며, 코드가 직관적이다. n개 원소에 대해 n개의 메모리를 사용하기에 데이터를 하나씩 정밀 비교가 가능하다.
- 단점 : 최선이든 최악이든 이라는 시간복잡도를 가진다.
버블정렬 코드화
public class Bubble_Sort {
public static void main(String[] args) {
int arr[] = {1, 5, 2, 3, 4, 8};
// 배열의 길이를 -1 해준 이유는 사이클 마지막 떄 정렬이 이미 되어 있다
// -1을 안해주면 반복문이 한 사이클 더 돌게 된다.
for(int i = 0; i < arr.length-1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
for(int i=0; i<arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
}삽입정렬
- 손안의 카드를 정렬하는 방법과 유사하다.
- 새로운 카드를 기존의 정렬된 카드 사이의 올바른 자리를 찾아 삽입한다.
- 새로 삽입될 카드의 수만큼 반복하게 되면 전체 카드가 정렬된다.
- 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교 하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성하는 알고리즘
- 매 순서마다 해당 원소를 삽입할 수 있는 위치를 찾아 해당 위치에 넣는다.
예시
출처 : https://ko.wikipedia.org/wiki/%EC%82%BD%EC%9E%85_%EC%A0%95%EB%A0%AC
삽입정렬 알고리즘의 특징
- 장점 : 최선의 경우 이라는 빠른 효율성을 가지고 있다. 버블정렬의 비교횟수를 줄이기 위해 고안된 정렬이다. 버블정렬의 경우 비교대상의 메모리 값이 정렬되어 있더라도 비교연산을 진행하나, 삽입정렬은 버블정렬의 비교횟수를 줄이고 크기가 적은 데이터 집합을 정렬하는 알고리즘을 작성할 때 효율이 좋다.
- 단점 : 최악의 경우 이라는 시간복잡도를 가지게 된다. 즉, 데이터의 상태와 크기에 따라 성능의 편차가 큰 정렬 방법이다.
삽입정렬 코드화
public class Insertion_Sort {
public static void main(String[] args) {
int arr[] = {1, 5, 2, 3, 4, 8};
for(int i = 1 ; i < arr.length ; i++){
int temp = arr[i];
int aux = i - 1;
while( (aux >= 0) && ( arr[aux] > temp ) ) {
arr[aux+1] = arr[aux];
aux--;
}
arr[aux + 1] = temp;
}
for(int i=0; i<arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
}병합정렬
- ‘존 폰 노이만(John von Neumann)’이라는 사람이 제안한 방법
- 일반적인 방법으로 구현했을 때 이 정렬은 안정 정렬 에 속하며, 분할 정복 알고리즘의 하나 이다.
- 분할 정복(divide and conquer) 방법
- 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
- 분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.
- 분할 정복(divide and conquer) 방법
예시
[6, 5, 3, 1, 8, 7, 2, 4]
먼저 하나의 배열을 두 개로 쪼갭니다.
[6, 5, 3, 1][8, 7, 2, 4]
그래고 다시 두 개의 배열을 네 개로 쪼갭니다.
[6, 5][3, 1] [8, 7][2, 4]
마지막으로 디시 네 개의 배열을 여덜 개로 쪼갭니다.
[6][5] [3][1] [8][7] [2][4]
이제 더 이상 쪼갤 수가 없으니 두 개씩 합치기를 시작하겠습니다. 합칠 때는 작은 숫자가 앞에 큰 수자를 뒤에 위치시킵니다.
[5, 6][1, 3] [7, 8][2, 4]
이제 4개의 배열을 2개로 합칩니다. 각 배열 내에서 가장 작은 값 2개를 비교해서 더 작은 값을 먼저 선택하면 자연스럽게 크기 순으로 선택이 됩니다.
[1, 3, 5, 6][2, 4, 7, 8]
최종적으로 2개의 배열도 마찬가지로 크기 순으로 선택하가면서 하나로 합치면 정렬된 배열을 얻을 수 있습니다.
[1, 2, 3, 4, 5, 6, 7, 8]
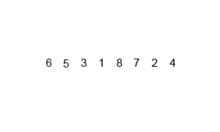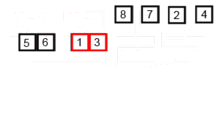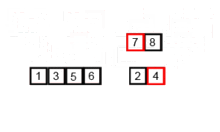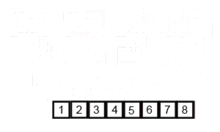
출처 : https://ko.wikipedia.org/wiki/%ED%95%A9%EB%B3%91_%EC%A0%95%EB%A0%AC
병합정렬 알고리즘의 특징
- 장점 : 퀵 정렬과 비슷하게 원본 배열을 절반씩 분할해가면서 정렬하는 정렬법으로써 분할하는 과정에서 만큼의 시간이 소요된다. 즉, 최종적으로 보게되면 이 된다. 또한 퀵 정렬과 달리 기준값을 설정하는 과정없이 무조건 절반으로 분할하기에 기준값에 따라 성능이 달라지는 경우가 없다. 따라서 항상 이라는 시간복잡도를 가지게 된다.
- 단점 : 병합정렬은 임시배열에 원본맵을 계속해서 옮겨주며 정렬을 하는 방식이기에 추가적인 메모리가 필요하다는 점이다. 데이터가 최악인 면을 고려하면 퀵 정렬보다는 병합정렬이 훨씬 빠르기 때문에 병합정렬을 사용하는 것이 많지만, 추가적인 메모리를 할당할 수 없다면 병합정렬을 사용할 수 없기 때문에 퀵을 사용해야 하는 것이다.
병합정렬 코드화
public class Merge_Sort {
public static int[] buff; //임시 배열
public static void mergeSort(int[] arr, int left, int right) {
if(left < right) {
int i;
int center = (left + right) / 2;
int p = 0; //임시 배열 인덱스
int j = 0;
int k = left; //원본 배열 인덱스
mergeSort(arr, left, center); //배열 앞부분 병합정렬
mergeSort(arr, center+1, right); //배열 뒷부분 병합정렬
for(i = left; i <= center; i++) { //임시 배열에 배열 앞부분을 넣어줌.
buff[p++] = arr[i];
}
while(i <= right && j < p) { //원본 배열의 뒷부분, 추가 배열의 앞부분의 원소끼리 비교한다.
arr[k++] = buff[j] <= arr[i] ? buff[j++] : arr[i++];
}
while(j < p) { //임시 배열의 앞부분이 모두 커서 선택이 안됐다면 원본배열 뒷부분에 붙혀준다.
arr[k++] = buff[j++]; //여기서 왜 i < right는 비교를 안할까? -> 비교를 하면서 선택을 못받은 잠재적 i값(큰 값)들은 원본배열 뒷부분에 있기 때문이다.
}
}
}
public static void main(String[] args) {
int[] arr = {3, 4, 2, 1, 6, 8, 9, 5};
int N = arr.length;
buff = new int[N];
mergeSort(arr, 0, N - 1);
for (int a : arr) {
System.out.print(a + " ");
}
}
}출처 : https://tosuccess.tistory.com/127
퀵정렬
- 찰스 앤터니 리처드 호어라는 사람이 갭라한 정렬 알고리즘
- 퀵 정렬은 불안정 정렬에 속하며, 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬에 속한다.
- 분할 정복 알고리즘의 하나로, 평균적으로 매우 빠른 수행속도를 자랑하는 정렬 방법
- 병합정렬과 달리 퀵정렬은 리스트를 비균등하게 분할한다.
예시
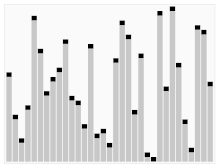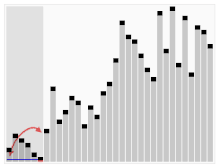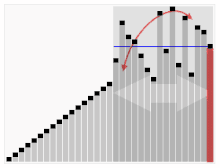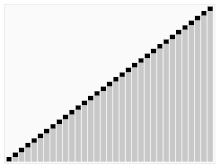
출처 : https://ko.wikipedia.org/wiki/%ED%80%B5_%EC%A0%95%EB%A0%AC
퀵정렬 알고리즘의 특징
- 장점 : 기준값(Pivot)에 의한 분할을 통해 구현하는 정렬 방법으로, 분할 과정에서 이라는 시간이 소요되며, 전체적으로 으로 준수한 편이다.
- 단점 : 기존값에 따라 시간복잡도가 크게 달라진다(안정성이 없다). 기준값을 이상적인 값으로 선택했다면 의 시간복잡도를 가지지만, 최악의 기준값을 선택할 경우 라는 시간복잡도를 갖게 된다.
퀵정렬 코드화
public class Quick_Sort {
static int partition(int[] array,int start, int end) {
int pivot = array[(start+end)/2];
while(start<=end) {
while(array[start]<pivot) start++;
while(array[end]>pivot) end--;
if(start<=end) {
int tmp = array[start];
array[start]=array[end];
array[end]=tmp;
start++;
end--;
}
}
return start;
}
static int[] quickSort(int[] array,int start, int end) {
int p = partition(array, start, end);
if(start<p-1)
quickSort(array,start,p-1);
if(p<end)
quickSort(array,p,end);
return array;
}
public static void main(String[] args) {
int[] array = {4,2,3,5,9};
array = quickSort(array,0,array.length-1);
System.out.println(Arrays.toString(array));
}
}출처 : https://heekim0719.tistory.com/282
힙정렬
- 힙 정렬(Heap sort)이란 최대 힙 트리나 최소 힙 트리를 구성해 정렬을 하는 방법으로서, 내림차순 정렬을 위해서는 최대 힙을 구성하고 오름차순 정렬을 위해서는 최소 힙을 구성하면 된다.
예시
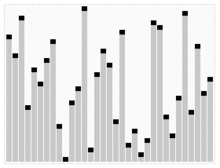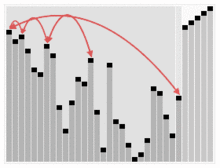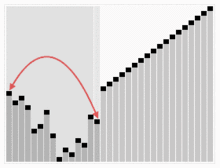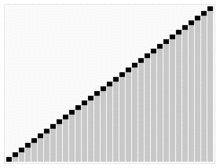
출처 : https://ko.wikipedia.org/wiki/%ED%9E%99_%EC%A0%95%EB%A0%AC
힙정렬 알고리즘의 특징
- 장점 : 추가적인 메모리를 필요로하지 않으면서 항상 의 시간 복잡도를 가진다. O(N\times logN)인 정렬 방법 중 가장 효율적인 정렬방법이라 할 수 있다. 퀵 정렬의 경우 효율적이나 최악의 경우 시간이 오래걸린다는 단점이 있으나 힙 정렬의 경우 항상 $O(N\times logN)이 보장된다.
- 단점 : 이상적인 경우에 퀵정렬과 비교했을 때 똑같이 이 나오긴 하나 실제 시간을 측정하면 퀵정렬보다 느리다고 한다. 즉, 데이터의 상태에 따라서 다른 정렬들에 비해서 조금 느린편이다. 또한, 안정성을 보장받지 못한다.
힙정렬 코드화
import java.util.PriorityQueue;
public class Heap_Sort {
public static void main(String[] args) {
int[] arr = {3, 7, 5, 4, 2, 8};
System.out.print(" 정렬 전 original 배열 : ");
for(int val : arr) {
System.out.print(val + " ");
}
PriorityQueue<Integer> heap = new PriorityQueue<Integer>();
// 배열을 힙으로 만든다.
for(int i = 0; i < arr.length; i++) {
heap.add(arr[i]);
}
// 힙에서 우선순위가 가장 높은 원소(root노드)를 하나씩 뽑는다.
for(int i = 0; i < arr.length; i++) {
arr[i] = heap.poll();
}
System.out.print("\n 정렬 후 배열 : ");
for(int val : arr) {
System.out.print(val + " ");
}
}
}