‘MapReduce: Simplified Data Processing on Large Clusters’ 논문은 2004년에 Jeffrey Dean이라는 구글의 전설적인 개발자가 작성한 논문입니다. 제프 딘으로 불리며 그에 대한 밈이 생겨날 정도로 영향력이 대단합니다. 해당 논문은 2024년 12월 기준으로 24,000 번 이상의 인용이 되었으며 Apache Hadoop 오픈소스의 기반이 되었고 대용량의 분산 데이터 처리 기술의 표준이라고 할 수 있습니다.
’맵리듀스(MapReduce)’는 대용량 데이터 처리를 분산 병렬 컴퓨터에서 처리하기 위한 목적으로 발표한 소프트웨어 프레임워크입니다. 여기서 말하는 대용량의 의미는 페타바이트 수준의 용량을 처리하는 수준입니다. 개발자는 키/값 쌍 집합을 생성하는 Map 함수와 동일한 중간 키와 연결된 모든 중간 값을 병합하는 Reduce 함수를 개발합니다. 시스템은 이 함수를 자동으로 병렬화하여 대규모 상용 시스템 클러스터(Parallelized and executed on a large cluster of commodity machines)에서 실행시킵니다. 따라서 병렬 및 분산 시스템에 대한 경험이 없는 개발자도 대규모 분산 시스템의 리소스를 쉽게 활용할 수 있습니다. MapReduce도 역시 단점이 존재하며 이를 해결하기 위해 Hive, Pig, Apache Spark, Apache Beam 등의 기술이 등장했습니다.
Map - Reduce
MapReduce는 개발자에게는 친숙한 ‘Map’ 함수와 ‘Reduce’ 함수를 응용한 기술입니다. map-reduce는 함수형 프로그래밍 언어인 LISP에서 기원하였습니다.
가령 특정 문자열의 각 단어 수를 카운팅하는 연산을 하고 싶다고 했을 때, 아래와 같이 표현합니다.
fun wordCount(input: String): Map<String, Int> {
return input
.split("\\s+".toRegex()) // 공백 또는 줄바꿈 기준으로 단어 분리
.map { it to 1 } // 각 단어를 Pair(단어, 1)로 변환
.groupBy({ it.first }, { it.second }) // 단어별로 그룹화하고 값 리스트로 정리
.mapValues { (_, values) -> values.sum() } // 값 리스트를 합산
}
fun main() {
val inputFiles = "Deer Bear River \n Car Car River \n Deer Car Bear"
val result = wordCount(inputFiles)
result.forEach { (word, count) ->
println("$word,$count")
}
}입력된 각 논리적 ’레코드’에 맵핑(Map) 작업을 적용한 다음 동일한 키를 공유하는 모든 값에 연산(reduce) 작업을 적용하여 추출된 데이터를 적절하게 결합합니다. 개발자는 이 과정에서 map 함수와 reduce 함수를 적절하게 구현하였습니다. MapReduce는 이러한 map, reduce 함수를 개발자가 작성하면 대규모 클러스터에서 분산 병렬 처리를 도와주는 기술이라고 할 수 있습니다.
MapReduce Execution
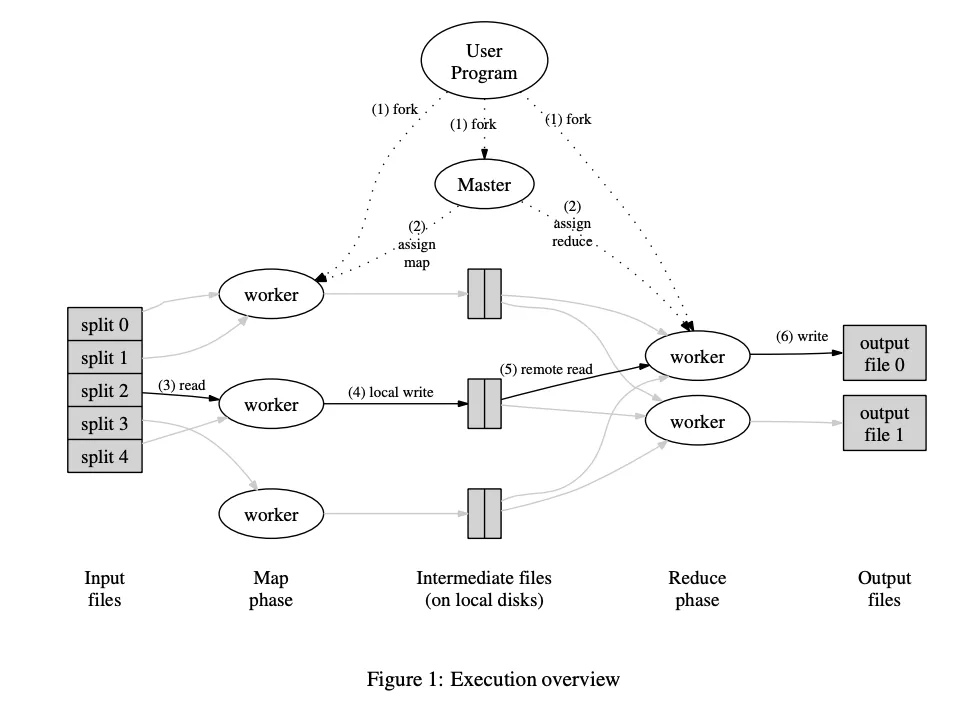
-
User Program은 Input Files를 M개의 조각으로 split 합니다. 일반적으로 개별 16MB or 64MB 크기로 나누는데 이는 개발자가 파라미터로 제어할 수 있습니다. 그 이후에 프로그램의 복사본을 fork해서 여러 인스턴스에서 실행시키게 됩니다. User Program는 파라미터와 Map, Reduce 함수가 정의되어있습니다.
-
Master는 각 작업을 유휴 Worker를 선정하여 각 Map / Reduce 작업을 할당합니다.
-
Map 워커 중 하나는 분할된 입력 파일을 읽습니다. 입력 데이터에서 key-value 값을 파싱하고 각 쌍을 사용자 정의 Map 함수를 적용합니다. Map 함수에 의해 생성된 key-value 값은 메모리에 버퍼링됩니다.
-
key-value 쌍은 각 워커의 로컬 디스크에 기록되고 R개의 분할된 지역으로 나누게 됩니다. Master는 버퍼링된 쌍의 로컬 디스크 위치를 기록하며 이를 Reduce 워커에게 전달합니다.
-
Reduce 워커는 이 위치에 대한 알림을 받고 원격 프로시저 호출을 통해 버퍼링 데이터를 읽습니다. Reduce 워커는 모든 중간 데이터를 읽으면 중간 key에 따라 정렬하여 동일한 key와 결과값을 그룹화합니다. Reduce 워커가 단일한 키만 처리하지 않기 때문에 정렬을 사용해야하며 메모리 문제 등이 있으면 외부 정렬을 사용합니다.
-
Reduce 워커는 Intermediate 데이터를 정렬하면서 key와 관련된 reduce 함수를 실행합니다. 이를 통해 reduce 파티션에 대해 최종 출력 파일을 전달합니다.
-
모든 Map 작업과 Reduce 작업이 완료되면 Master는 User Program에게 종료를 알립니다. MapReduce 실행된 결과는 R개(Reduce Worker 당 하나)의 출력 파일로 저장되며 R개의 출력 파일은 하나의 파일로 결합할 필요는 없고 그대로 사용할 수 있습니다.
같은 개념을 다시 Hadoop의 예시로 설명하겠습니다.
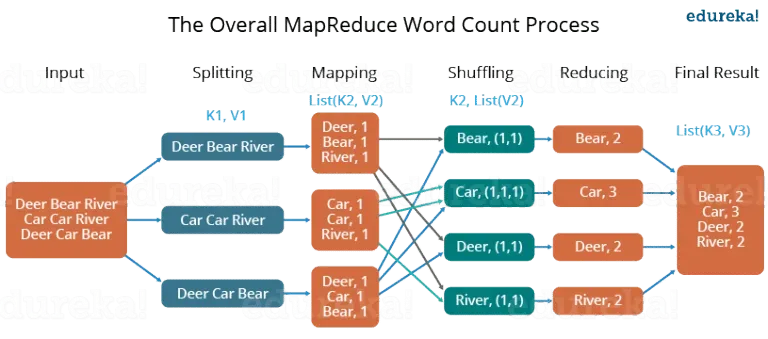
- Input 값을 적절한 크기의 3개의 파일로 분할 합니다.
- 각 매퍼의 단어를 tokenize(공백으로 split)하고 각 토큰 또는 단어에 값 1(개수)를 할당합니다.
- 각 튜플이 적절한 reduce worker에게 전달될 수 있도록 정렬 및 셔플링이 수행되는 분할 프로세스가 진행됩니다.
- 각 reduce는 전달된 목록의 값을 계산합니다.
- 모든 출력 키/값 쌍을 수집하여 파일에 기록합니다.
Master
- 마스터는 Worker의 상태(유휴, 진행중, 완료) 및 ID 보관
- 완료된 map 작업에 대해 마스터는 R개의 중간 파일 영역의 위치와 크기 저장하여 reduce 에게 전달
Worker Failure*
- Master는 주기적으로 woker 에게 ping을 보내여 헬스체크를 하며 응답을 받지 못하면 woker를 장애로 표시합니다.
- 동일한 map / reduce 작업은 다른 작업자에게 다시 예약이 될 수 있습니다.
- Map 작업의 결과물(중간 데이터)은 Map Worker 로컬 디스크에 기록되기 때문에 작업중이던 중간 데이터는 날리고 처음부터 실행됩니다.
Master Failure
- 마스터 장애가 생기면 MapReduce는 중단됩니다. SPOF
Deterministic
- MapReduce는 결정적 함수인경우에 동일한 출력에 대해서 보장을 합니다. 하지만 비결정적 함수인 경우에는 동일한 결과를 보장하지 못합니다. 이를 보장하기 위해 임시 출력 파일의 이름을 최종 파일의 이름으로 변경하여 원자적으로 기록합니다.
- 가령 reduce 함수가 최종 파일을 읽어서 작업하는 연산이 포함되어있을 때, 동일한 출력을 보장하지 못합니다.
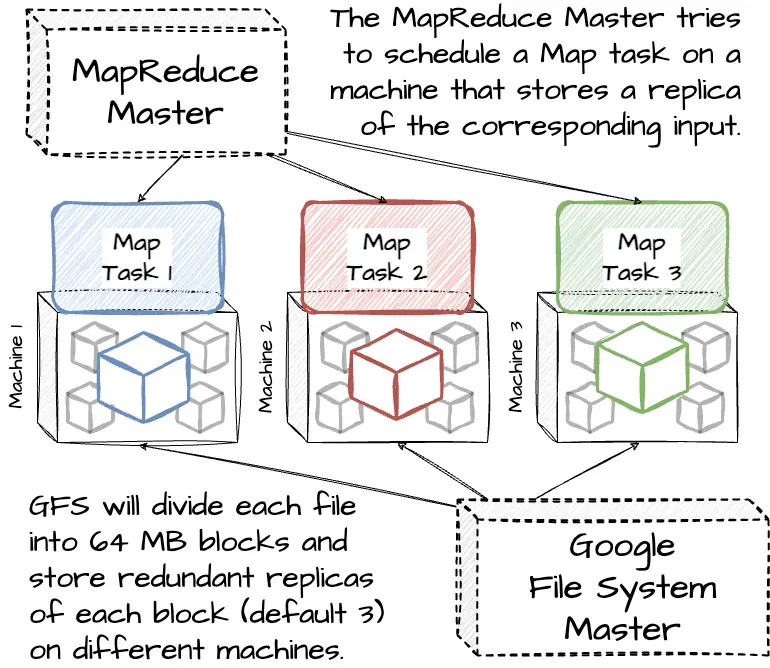
https://www.junaideffendi.com/p/everything-you-need-to-know-about
- MapReduce는 네트워크 대역폭을 최소화한 작업입니다.
- 입력 데이터를 GFS(파일 시스템)에서 관리하며 이를 여러 사본으로 저장합니다. Master는 입력파일의 위치정보를 고려하여 해당 입력 데이터의 복사본이 있는 머신에서 맵 작업을 예약합니다. 대부분의 입력 데이터가 로컬에서 읽히게 되므로 네트워크 대역폭을 거의 소비하지 않습니다.
(Distributed File System, No Data Movement)
Granularity*
- 맵 작업은 M개로 리듀스 작업은 R개로 나뉘며 M과 R이 Woker 개수보다 훨씬 커야지 이상적인 분산 연산을 수행할 수 있습니다.
- 마스터는 O(M + R)개의 스케줄링을 진행해야 하므로 메모리 용량을 계산해야합니다. (M-R 쌍당 1byte)
- 일반적으로 2,000개의 작업자 머신을 사용하여 M = 200,000, R = 5,000으로 MapReduce 계산을 수행
(병렬성, 내결함성) → input file split, chunk, retru, backup tasks
Backup Tasks
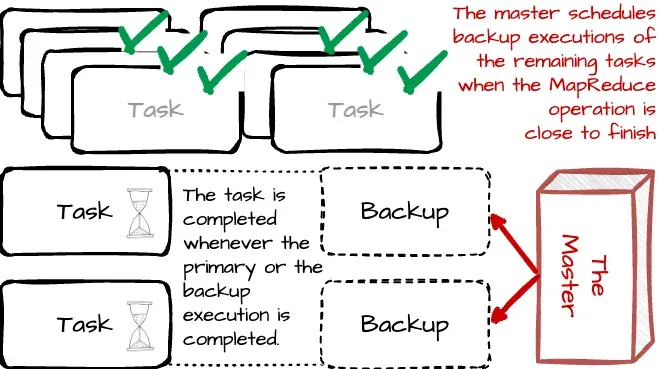
- 클러스터 스케줄링 시스템이 다른 작업을 woker에게 예약하면 CPU, 메모리, 로컬 디스크 또는 네트워크 대역폭 경합으로 인해 MapReduce 코드 실행 속도가 느려질 수 있음
- Master는 실행 속도가 비정상으로 느린 task를 Straggler로 간주함. 해당 워커 노드가 이상이 있을 수 있다고 생각하여 다른 워커에게 중복 실행을 시키고 먼저 완료된 task를 사용함.
- MapReduce 작업이 완료단계에 가까워지면 마스터가 진행 중인 나머지 작업의 백업 실행을 예약해서 백업이 완료되면 해당 작업이 완료된걸로 표시. 44% 완료시간 단축
개선점
MapReduce를 custom해서 개선할 수 있는 내용입니다.
Partitioning Function
- MapReduce는 중간키를 기준으로 R의 개수를 지정하여 파티셔닝 됩니다. 따라서 데이터 키의 특성에 따라 적절한 파티셔닝 함수를 사용해야 작업이 유용합니다.
- 예를 들어 URL의 카운트를 계산할 때, 특정 도메인에 해당하는 url의 count를 알고 싶으면 도메인을 기준으로 key를 나누는 함수를 사용해야합니다. → MapReduce 라이브러리에서 최적화된 해싱 함수
Combiner Function
- 앞에서 본 예시처럼 word:1 의 구조가 만들어지면 record 개수가 수천개가 형성될 수 있습니다. 이런 구조가 네트워크 전송 전에 병합이되면 좋기 때문에 map worker에서 reduce함수를 이용해서 combine 하는 함수를 필요로 할 수 있습니다.
- combine 함수와 reduce 함수의 유일한 차이는 출력입니다. combine 함수는 map worker에서 중간 파일로 출력이되며 reduce 함수는 reduce worker에서 최종파일로 출력이 됩니다.
Input and Output Types
- 각 입력된 파일의 범위를 의미있는 범위로 분할하여 맵 작업을 처리할 수 있습니다.
- reader는 꼭 파일이 아니라 DB 등의 데이터를 읽는 방식으로 설정할 수 있습니다.
Side-effects
- MapReduce는 애플리케이션을 원자적이고 멱등성이 있도록 만들기를 기대합니다.
- 교차 파일에서 일관성 요구상항이 있는 출력 파일을 생상하는 과정에서 결정론적이길 기대합니다.
Skipping Bad Records
- map / reduce 작업을 하면서 어쩔 수 없이 에러가 발생하는 경우가 있는데, 이는 대규모 데이터 작업에서 완벽하게 해결하는게 불가능할 수 있습니다.
- 따라서 이런 충돌을 유발하는 레코드를 감지하고 이 레코드를 skip할 수 있는 선택적 실행모드를 제공합니다. 각 worker 프로세스는 이러한 오류가 발생하는 레코드를 미리 감지하고 이를 전역변수에 저장하여 master에게 전송합니다. 이 레코드는 map / reduce 작업 재실행시 skip을 하게 됩니다.
Local Execution
- MapReduce는 모든 작업을 로컬 머신에서 순차적으로 실행하는 대체 구현을 개발했습니다.
- 사용자는 이를 통해 특정한 플래그 및 디버깅 테스트도구를 쉽게 사용할 수 있습니다.
Status Information
- Master는 내부 HTTP 서버를 실행하여 client 한테 상태 페이지를 보여줍니다.
- 완료된 작업수, 진행중인 작업 수, 입력 바이트, 중간 데이터 바이트, 출력 바이트, 처리 속도 등을 포함합니다.
Counters
- 다양한 이벤트의 발생 횟수를 세는 카운터 기능을 제공합니다. 이는 worker에서 주기적으로 master에게 핑 응답으로 제공합니다.
- 카운터 값은 상태 페이지를 통해 확인할 수 있습니다.
Shuffling
위 과정에서 우리가 잘 이해가 안되는 부분이 있습니다. Shuffling인데요. Intermediate key value(중간 데이터) 값을 reduce worker 에게 전달하기 위해서 진행되는 과정입니다.
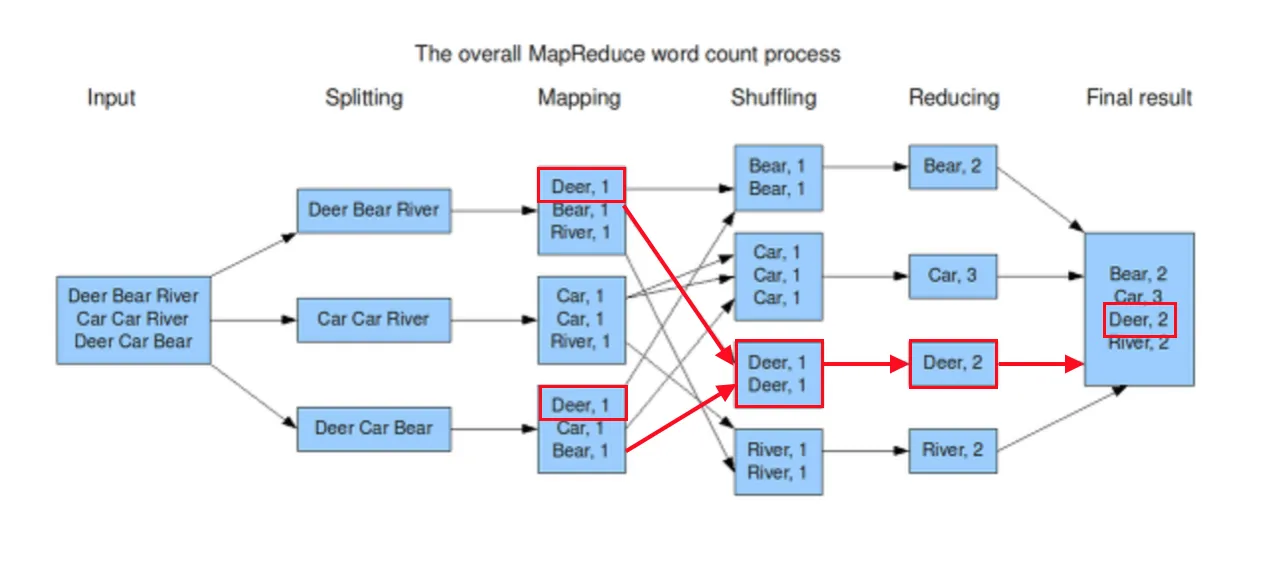
중복된 키를 찾아주고 적절하게 셔플링을 해줘야 해당하는 reduce worker가 작업을 해줄 수 있습니다.
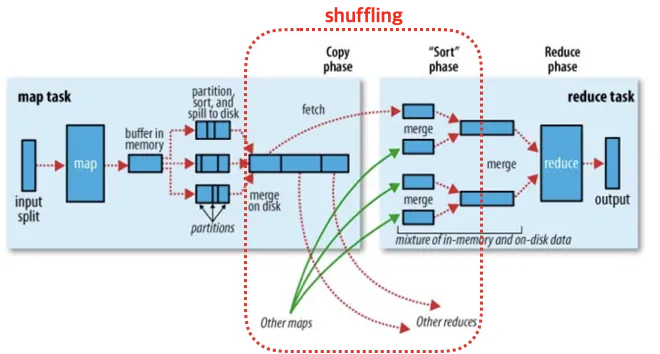
map을 통해 변환된 key-value는 메모리 버퍼에 저장되고 파티셔닝 작업을 진행합니다. 파티셔닝은 해당 키가 처리되어야하는 reduce task를 기준으로 데이터를 분리합니다. 리듀서의 개수에 따라 적절하게 해시를 해주고 그 값을 sorting해서 local disk에 적재를 하게 되는 과정이 진행됩니다.
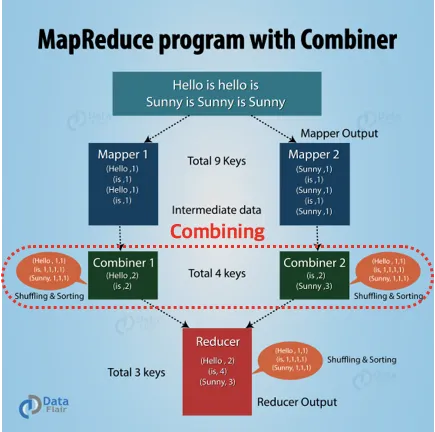
또한 이 과정에서 이전에 설명한 Combining 절차가 수행되며 map worker local disk 공간에 적재합니다. master 노드는 이제서야 이 데이터 위치를 취합하여 redouce worker에게 위치를 알려줍니다.
셔플링 과정을 정리하면 다음과 같습니다. [참조](https://blog.firstpenguine.school/31)
0. Mapping: map의 결과물로 intermediate key value가 생성됨
1. Partitioning: 각각의 키 값을 기준으로 어느 리듀서에서 처리되어야 하는지 파티션을 결정함
2. Sorting: 같은 파티션 내의 값들은 키 값을 기준으로 소팅
3. Combining: 파티션 내의 값들에 대해 미리 reduce 작업을 진행하여 데이터의 양을 줄임
4. Spill to locak disk: 처리된 값들을 Mapper 노드의 디스크 공간에 저장
5. Notify Master: 매핑 과정을 완료하였다는 알림과 파티셔닝 정보를 마스터 노드에게 알림
6. Notify Reducers: 마스터 노드는 리듀서 노드들에게 이 정보를 전달
7. Remote Read: 리듀서 노드들은 자신에게 할당된 파티션들만 매퍼들에게서 읽어와서 리듀스 작업을 준비
하지만 혹자는 이 shuffling 과정이 복잡하고 속도가 느리다고 꼬집습니다. MapReduce를 small Map, large Shuffle, small Reduce라고 불러야 한다는 농담이 있다고도 합니다.
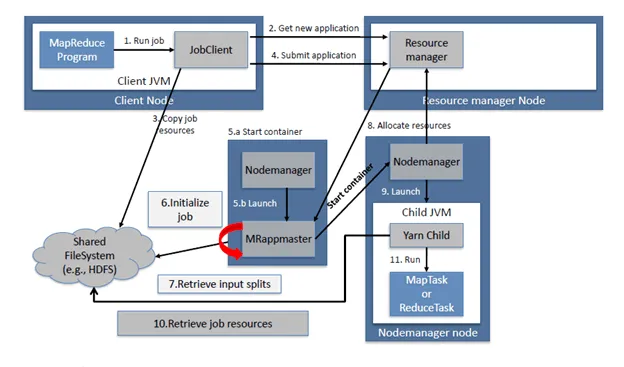
Fault Tolerance (Re-Execution)
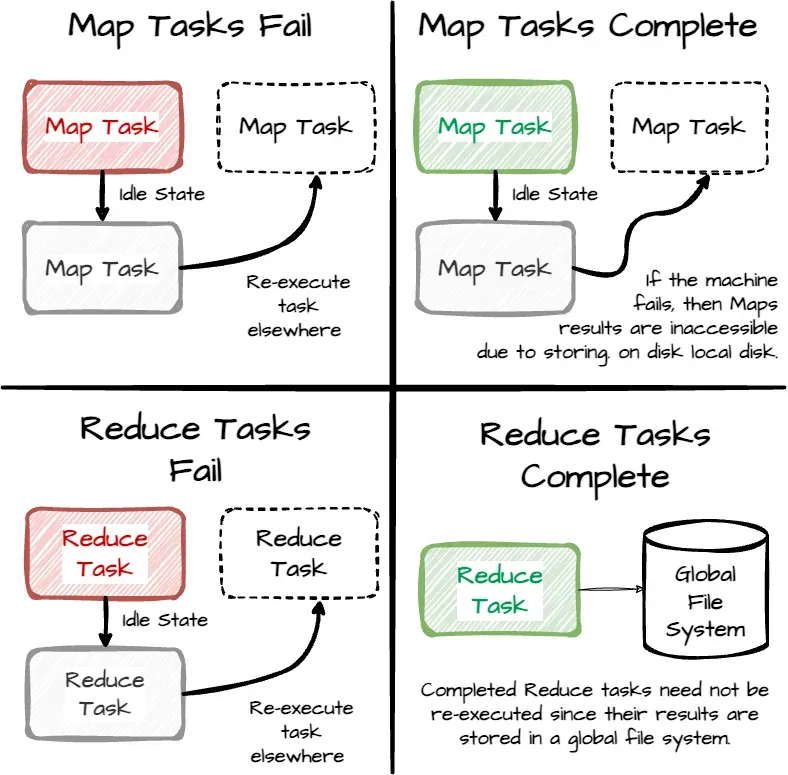
In Hadoop
HDFS(Hadoop distributed File System): 대용량 데이터를 여러 노드에 분산하여 저장하는 시스템. 데이터의 안정성 및 가용성을 보장하고 사용한다.
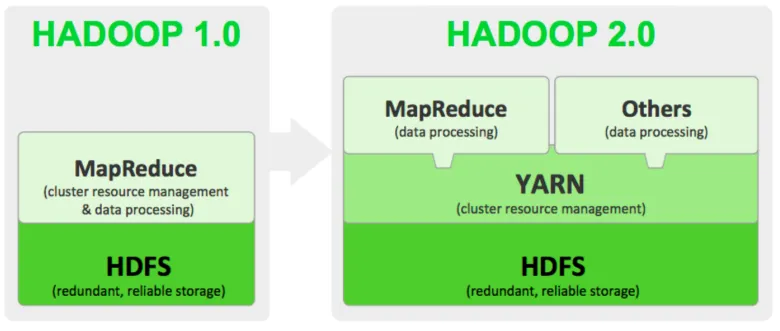
YARN 이라는 reousrce 매니저를 추가해서 다른 분산처리 알고리즘을 사용할 수도 있도록 변경
GFS → HDFS로 사용

개발자가 구현할 인터페이스
MapRduce 한계
- 셔플링 과정이 복잡하고 속도가 느립니다.
- 파일을 분산해서 사본을 뜨고, map worker에서 중간 데이터를 디스크에 기록하고, reduce worker가 이 파일을 읽어서 결과 파일을 출력합니다. 이 수많은 disk I/O는 성능을 저하시킵니다.
- data skew
- 특정 reduce worker로 데이터가 몰리는 skewed가 발생할 수 있습니다. 논리적으로 해결해야합니 다.
MapReduce Uses
Apache Spark
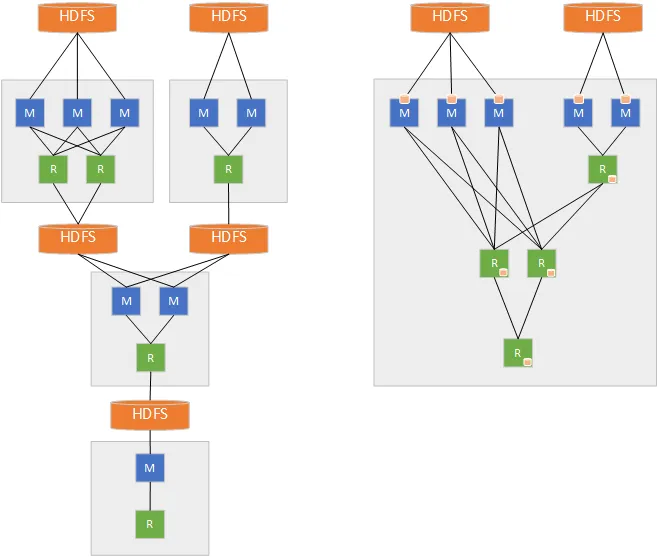
- HDFS에 중간결과를 쓰지 않고 메모리에서 데이터를 캐싱해서 처리한다. (RDD(Resilient Ditributed Datasests) 사용) 최대 100배 빠르다. 하지만 Hadoop MapReduce가 더 큰 데이터셋을 작업할 수 있다.
- Spark는 더 많은 RAM을 필요로 하기 때문에 초기 비용이 비싸다. 하지만 작업 속도가 빠르기 때문에 사용량 측면에서 적기 때문에 비용이 더 절감될 수도 있다.
- Spark는 메모리로 작업하기 때문에 중간 지점 재실행이 어렵다.
- Spark도 디스크 기반 스토리지 처리 옵션이 있고 hadoop보다 성능이 최대 10배 바르다.
- 실시간 처리가 필요한 경우 Spark가 좋은 옵션이 될 수 있다.
Apache Flink
Batch Processing이 아니라 Stream Processing의 중요성이 높아지면서 Flink를 사용하는 선택지가 생김
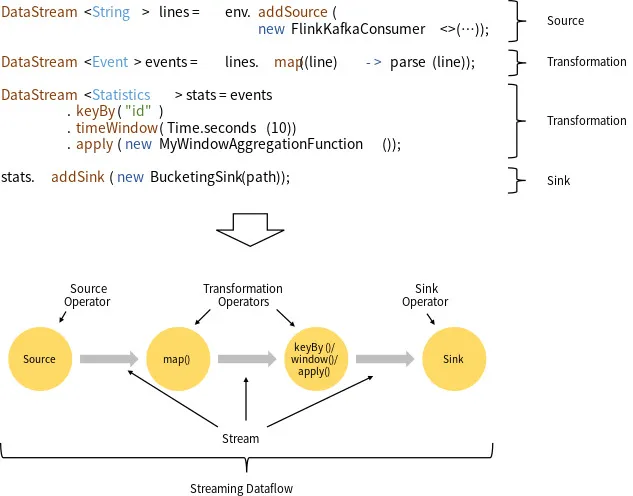
- map-reduce 와 유사한 방식으로 데이터가 변경되며 입출력이 stream으로 제공된다.
- Hadoop, YARN과 호환되며 추가 변환 기능을 제공합니다. (co-group 등)
- 셔플링 등의 문제가 되었던 작업을 줄일 수 있도록 optimizer를 제공합니다.
- 대규모 스케일아웃 작업에서는 아직 불안한 요소가 있습니다.
이외

- MapReduce를 구현한 HIVE, PIG 등이 만들어졌음. Hive는 SQL 기반, Pig는 data-flow 언어인 스크립트 언어 기반(Pig latin)
- Value 값으로 정렬하고 싶거나 Key의 Object 타입을 Text, IntWritable, LongWritable 외의 것들로 다양하게 바꾸고 싶을 때 사용.
정리
- MapReduce는 페타바이트 수준의 대용량 데이터를 분산 처리를 하기 위해 분산 파일 시스템 기반으로 병렬 처리를 할 수 있게 해주는 모델이다.
- split input - map - shuffling - reduce - output 과정이 단일한 task(backup tasks 제외)
