Overview
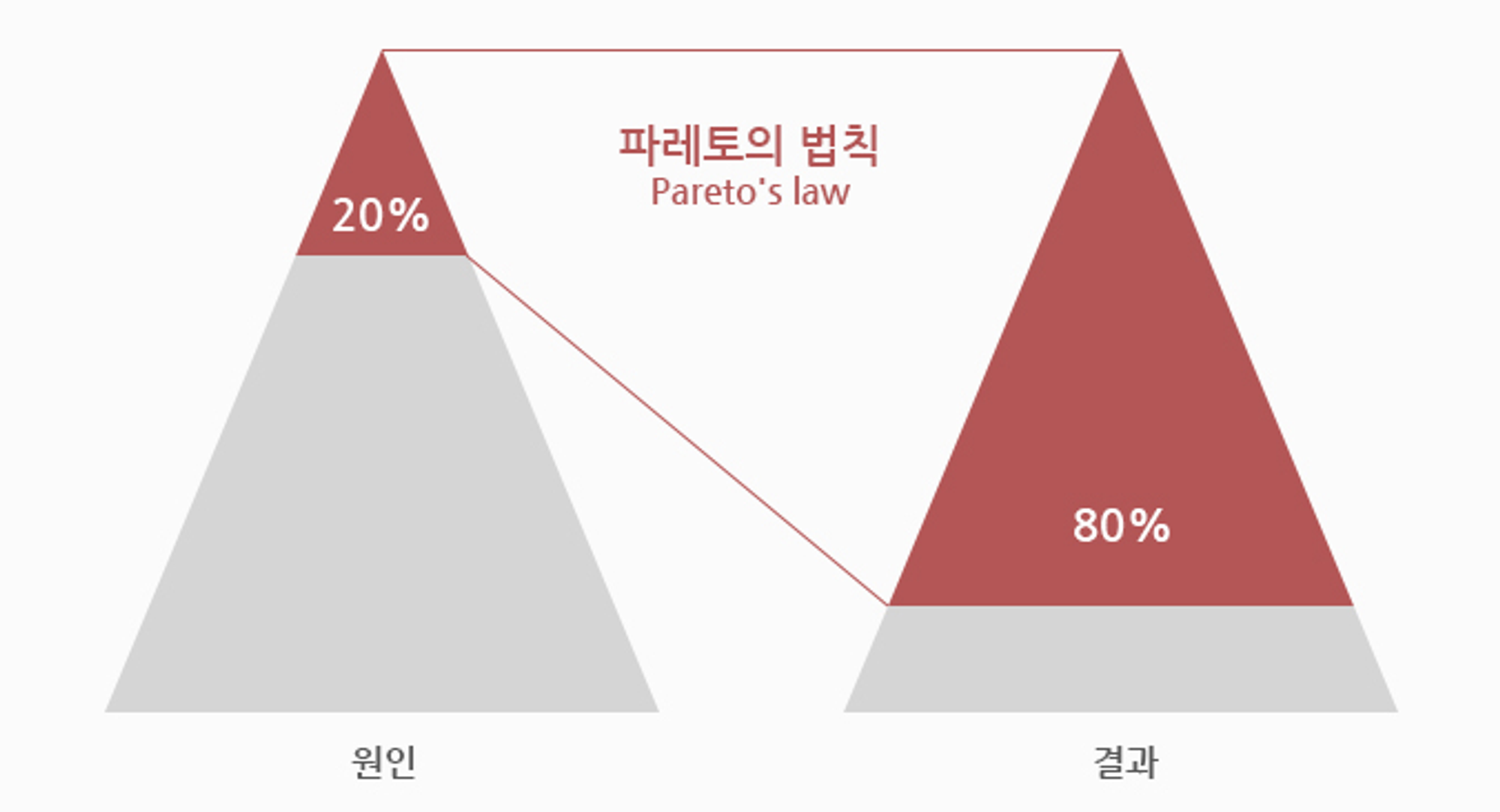
사회현상을 분석할 때 '파레토의 법칙' 이라는 유명한 이론이 있습니다. 상위 20%의 원인이 80%의 효과를 만들어낸다고 하여, 국가의 소비 80%는 상위 소득 20%의 인구가 만들어낸다는 이야기가 좋은 예입니다. 웹 사이트 접근 또한 마찬가지입니다. 하나의 웹 사이트 접근 80%가 사용하는 데이터는 고작 20%밖에 되지 않아, 이 20%를 효율적으로 관리하면 자원 관리를 극적으로 향상할 수 있다고 합니다.
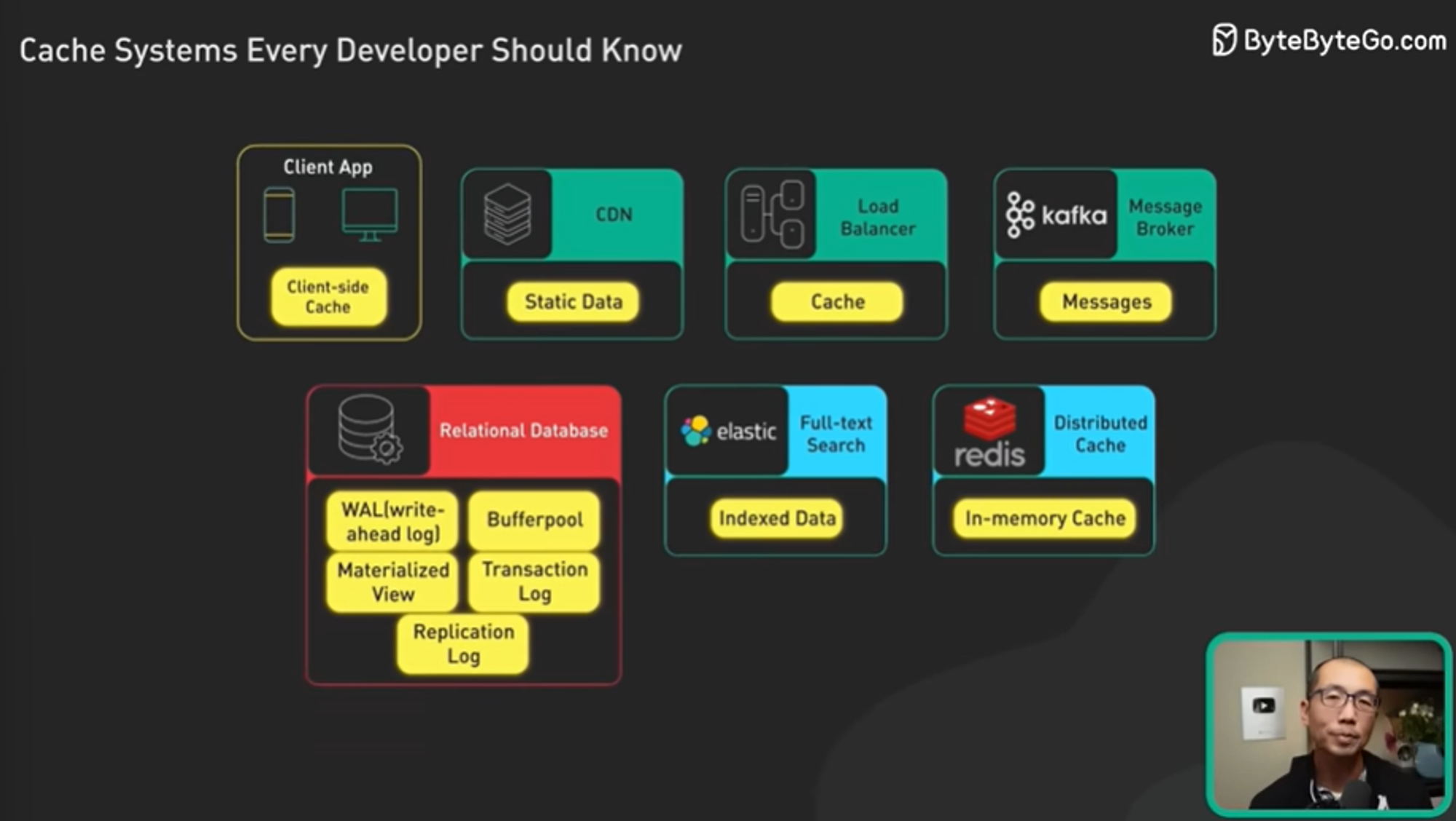
이 캐시의 다양한 활용 방법을 ByteByteGo 유튜브 영상을 참고하여 알아보았습니다. 해당 영상에서는 캐시의 활용도를 위 그림과 같이 소개하고 있습니다.
Cache
캐시는 데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목을 줄이기 위한 메모리를 말합니다. 이를 통해 데이터를 접근하는 시간이 오래 걸리는 경우를 해결합니다.
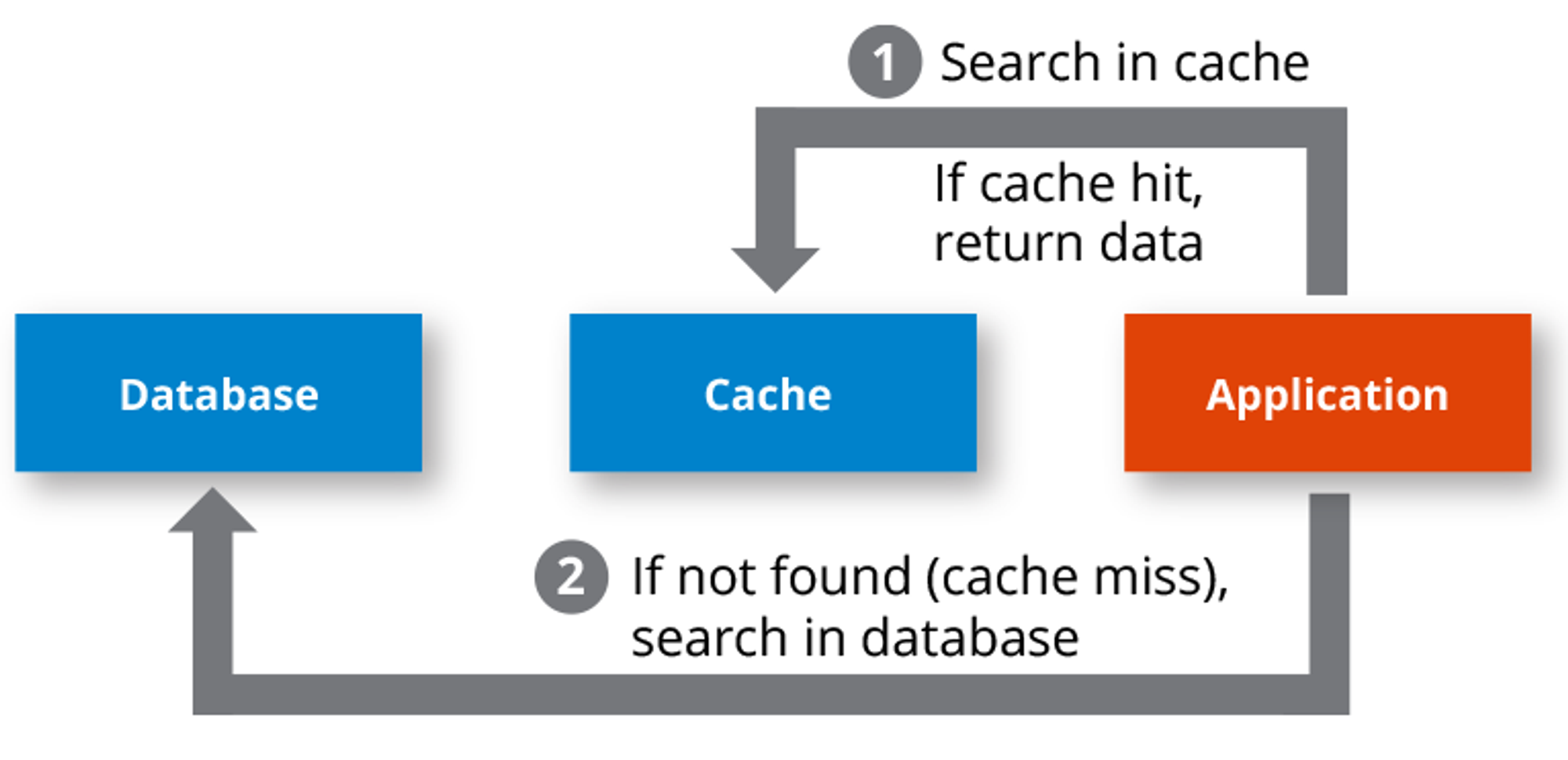
Cache Hit
캐시에서 원하는 데이터를 찾았았으면 캐시히트라고 합니다.
Cache Miss
캐시에서 원하는 데이터를 찾지 못했다면 주 메모리로 가서 데이터를 찾아오는 것을 캐시미스라고 합니다.
Cache Hit Rate
캐시 메모리 성능을 나타내기 위해 히트율을 이용합니다. 캐시 메모리는 기본적으로 전체 메모리 데이터의 일부만을 포함하므로 히트율을 높일 수 있는 캐시 교체 정책이 필요합니다.
지역성의 원리
캐시를 직접 설정할 때는 자주 사용하는 데이터를 기반으로 설정해야합니다. 여기서 자주 사용하는 데이터에 대한 근거는 ‘지역성’입니다. 지역성은 시간 지역성(temporal locality)와 공간 지역성(spatial locality)로 나뉩니다.
시간 지역성
최근에 사용한 데이터에 다시 접근하려는 특성입니다.
공간 지역성
최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성입니다.
FIFO Replacement
FIFO 교체방식은 각 데이터가 메모리에 적재될 때마다 시간 정보를 저장 및 활용하는 방식입니다. 데이터 부재가 일어났을 때 가장 먼저 적재된 데이터를 우선으로 교체합니다.

LRU 알고리즘 구현을 위해서는 데이터별 참조된 시간 정보가 기록·저장되어 있어야 합니다. 따라서 LRU 교체방식 사용 시 각 데이터에 대한 참조 시간 정보를 포함하여야 하므로 오버헤드가 발생하고 구현하기 복잡하다는 한계가 존재합니다.
LFU(Least Frequently Used) Replacement
LFU 교체방식은 각 데이터의 참조횟수를 기록하여 이용한 교체방식입니다. Fig. 3과 같이 2가 참조되어 데이터 부재가 발생했을 때 참조횟수가 가장 적은 데이터 0을 교체합니다.
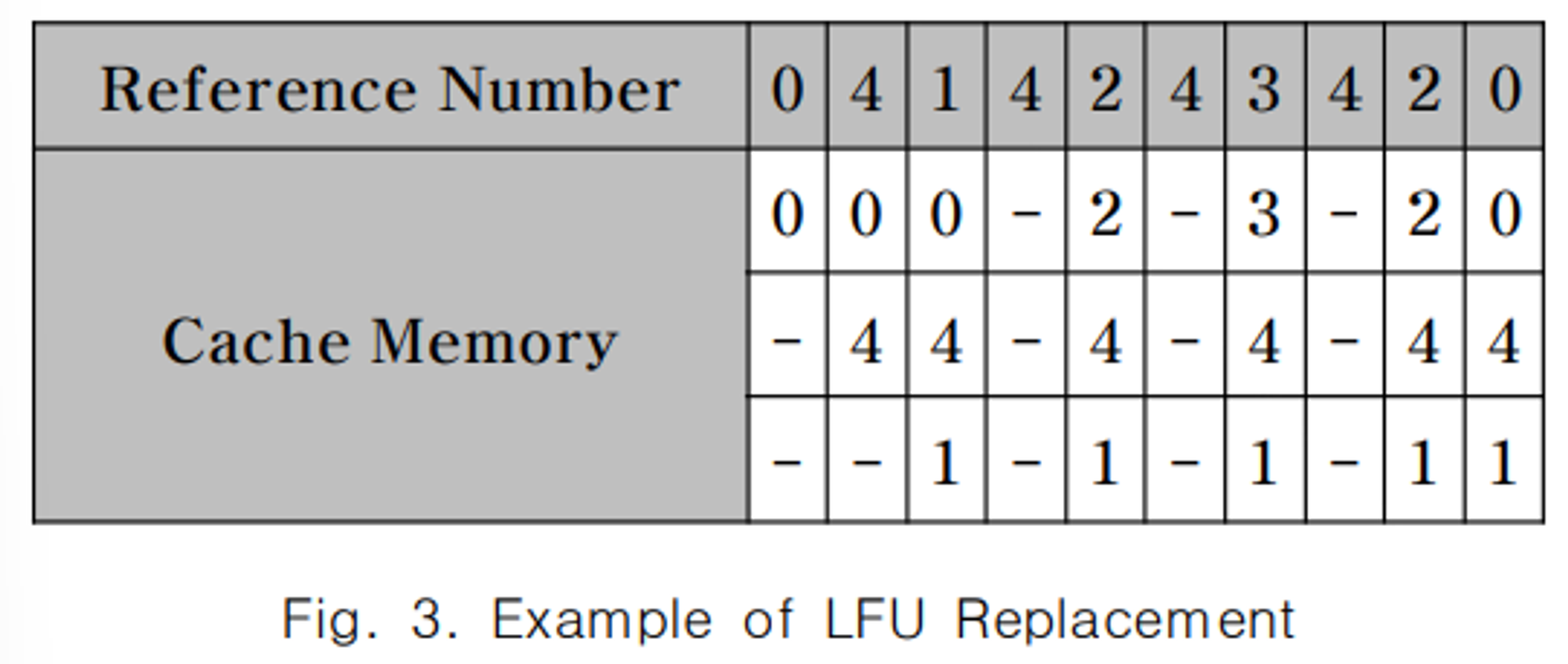
LFU 교체방식은 데이터의 참조 정보만 기록하기 때문에 참조의 최근성을 고려하지 않습니다. 이러한 특성으로 인해 과거에 빈번하게 참조된 데이터가 캐시 메모리를 차지하는 문제가 발생합니다. 즉, 최근에 참조된 데이터가 적재된 후 새로운 데이터를 참조하여 캐시 미스가 발생했을 경우 참조횟수가 낮다는 이유로 교체 대상이 되어 충분한 시간 동안 머물지 못할 수 있습니다. 따라서, 과거에 빈번히 사용된 데이터가 참조횟수가 많아 캐시를 차지하는 캐시 오염(Cache Pollution)이 발생합니다
Hardware
L1, L2, L3 캐시
CPU는 메모리에 저장된 데이터를 읽어들이면서 자주 사용하는 데이터를 캐시 메모리에 저장한 다음 다시 사용할 때 메모리가 아닌 캐시 메모리에서 가져옵니다. 이로인해 캐시 메모리는 일반 메모리보다 속도가 빠르지만 용량은 적은게 일반적입니다.
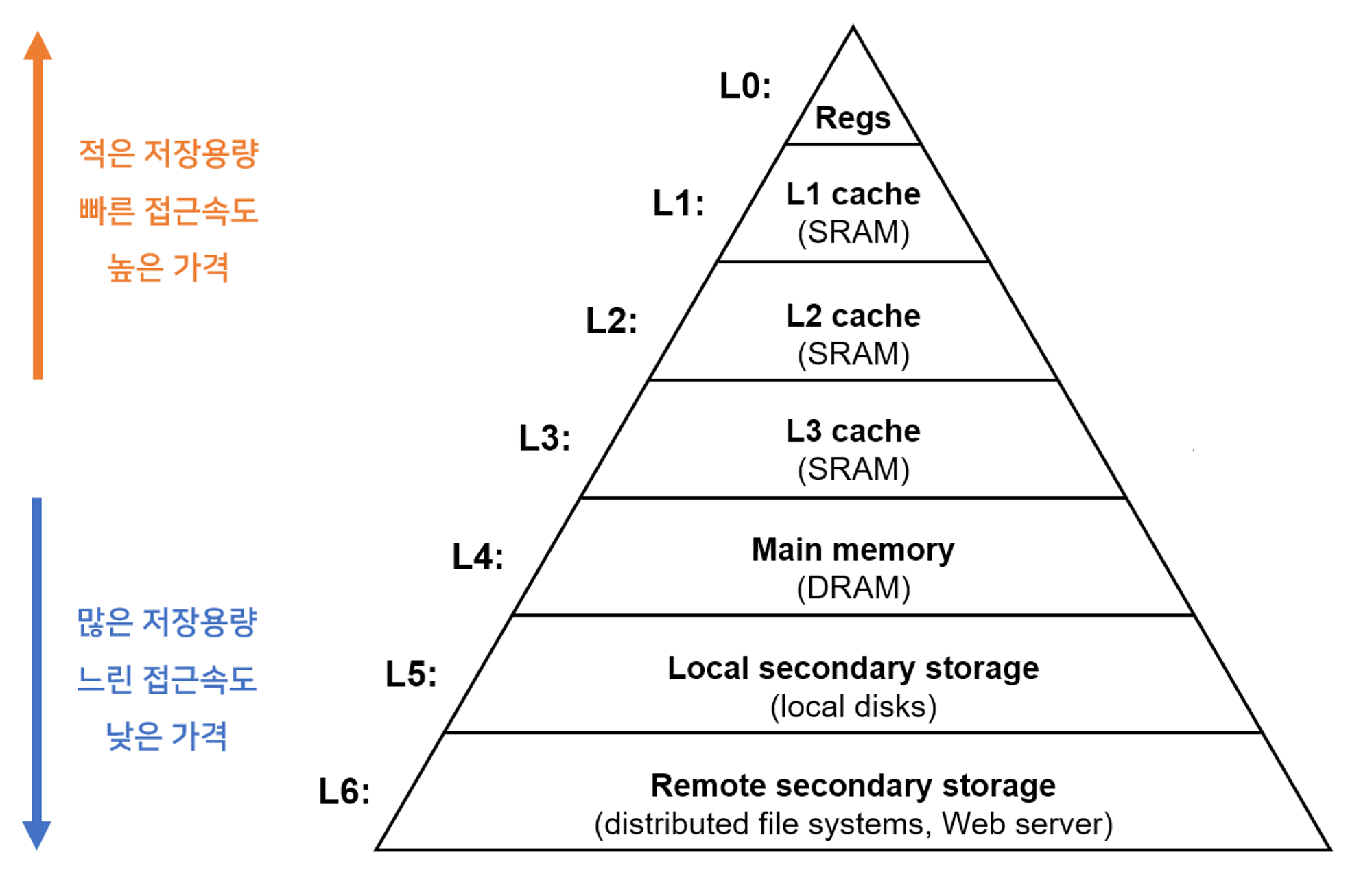
보통 이러한 메모리 구조 계층을 갖습니다. CPU는 메모리에 올라와 있는 프로그램의 명령들을 실행시키는데 찾고자하는 데이터가 해당 계층에 있다면 그 계층에서 데이터를 읽어서 사용하게 됩니다. 여기서 말하는 L은 Level을 의미합니다.
L1, L2, L3 캐싱
- L1: CPU 칩 내에서 일어나는 캐싱. 최소화되고 가장 빠른 캐싱. 보통 8~64KB 정도의 용량을 가지고 있다.
- L2: L1보다 저장소가 크고 느림. 일반적으로 CPU랑 분리된 칩에 위치. CPU 제품마다 다르지만 L2 캐시는 CPU 다이(회로판)에 별도의 칩으로 내장. 64kb ~ 4MB 정도 사용.
- L3: L2 캐시보다 크고 느림. 종종 multiple CPU cores 사이에서 공유. 요즈음 프로세서는 L3 캐시 메모리를 안들고 있는 추세. L2로도 충분히 커버 가능. L3 캐시는 CPU가 아닌 메인보드에 내장되는 경우가 많다고 함.
L1, L2 에 사용되는 SRAM은 우리가 아는 메인 메모리 DRAM에 비해 상당히 비싸다고 합니다. 그래서 많은 용량을 가지고 있지 않습니다.
TLB(Translation Lookaside Buffer)
운영체제는 컴퓨터 내의 한정된 메모리를 극한으로 활용합니다. 가상 메모리(virtual memory)는 메모리 관리 기법의 하나로 컴퓨터가 실제로 이용 가능한 메모리 자원을 추상화하여 이를 사용하는 사용자에게 큰 메모리로 보이게 만드는 것을 말합니다.
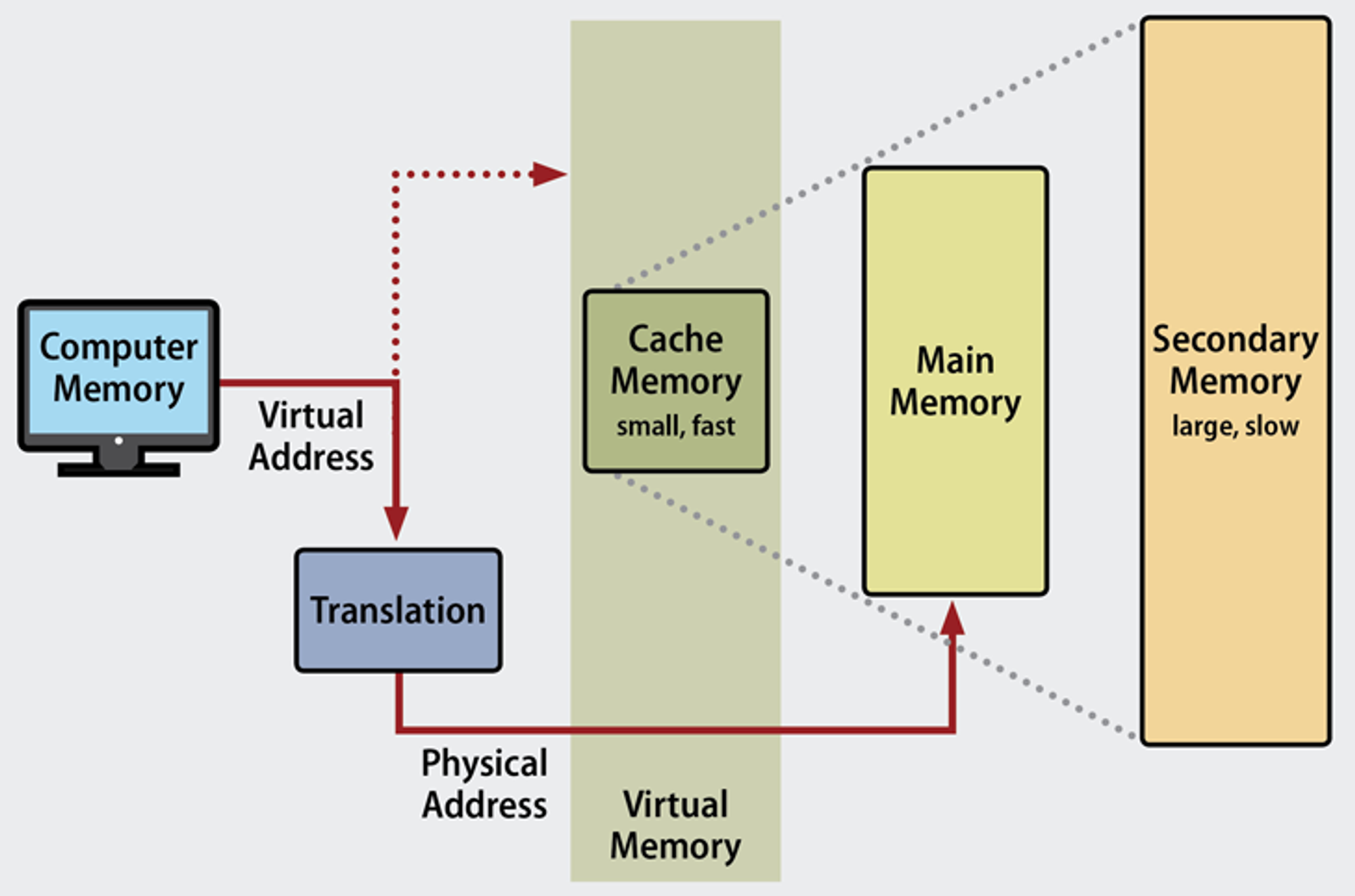
이 때 가상적으로 주어진 주소를 Virtual Address라고 하며 시렞 메모리상의 주소를 physical address라고 합니다. 가상 주소는 메모리관리장치인 MMU(그림상 Translation)을 통해 실제 주소로 변환되며 사용자는 실제 주소를 알 필요가 없습니다.
가운데에 있는 가상 메모리(Virtual Memory)에는 가상 주소와 실제 주소가 매핑되어 있고 프로세스의 주소 정보가 들어있는 ‘페이지 테이블’로 관리가 되고 속도 향상을 위해 TLB(Translation Lookaside Buffer)를 사용합니다.
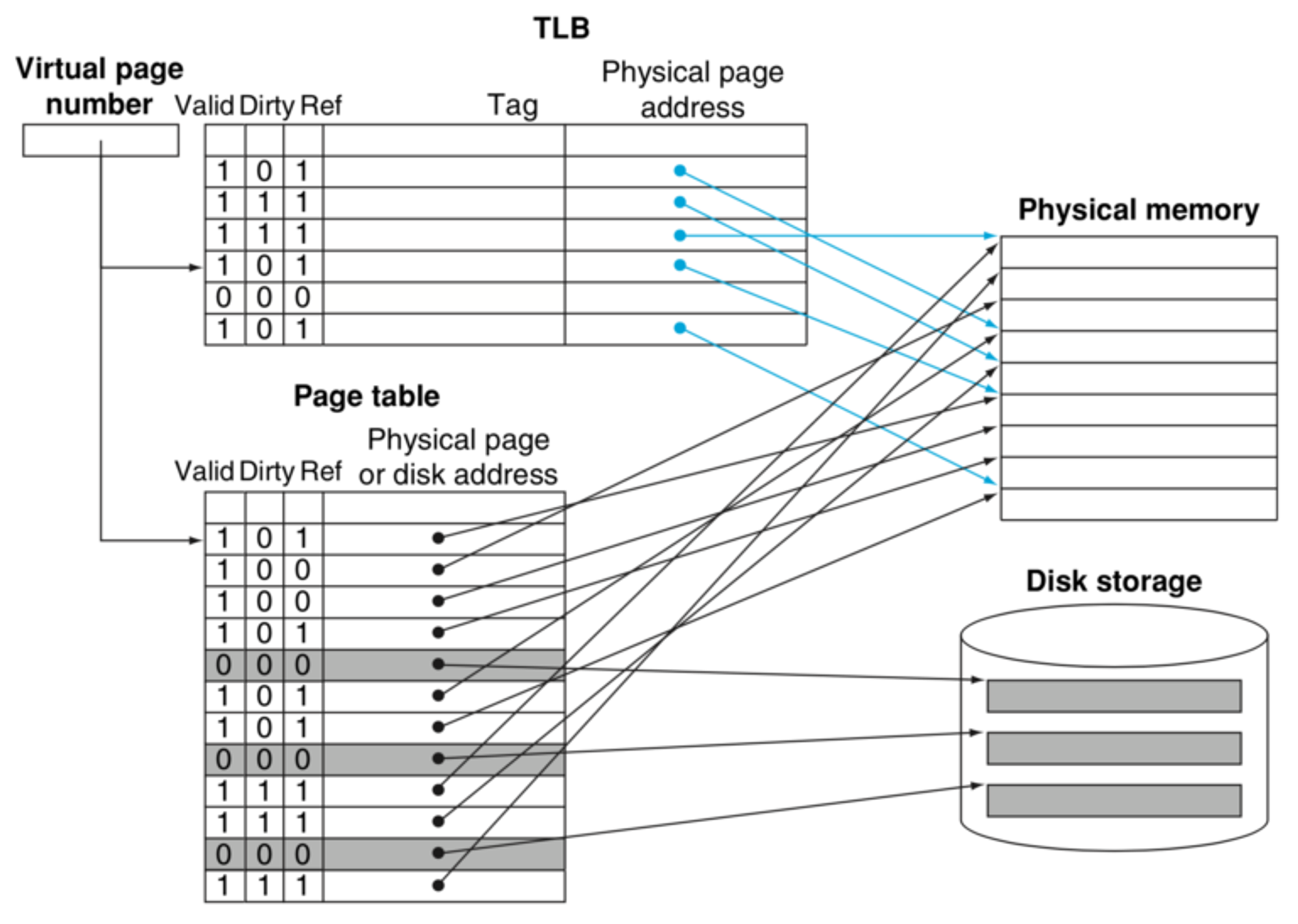
한국말로 변환색인버퍼라고 부르며 가상 메모리 주소를 물리적인 주소로 변환하는 속도를 높이기위해 사용되는 캐시입니다. 페이지 테이블(Page Table)에 있는 데이터를 캐시하여 속도를 향상시킵니다. 따라서 실제 주소를 위한 메모리 주소 접근할 때 캐시 히트가 발생하면 TLB를 통해 빠르게 접근하고 캐시 미스가 발생하면 Page Table을 통해 실제 주소에 접근한 뒤 캐싱을 하게 됩니다.
OS
page cache
페이지 캐시는 Disk I/O 성능 향상을 위해 처리한 데이터를 메인 메모리 영역(RAM)에 저장해서 가지고 있는 방법입니다. 동일한 파일 접근이 일어나면 디스크를 읽지 않고 페이지 캐시에서 읽어서 제공합니다.
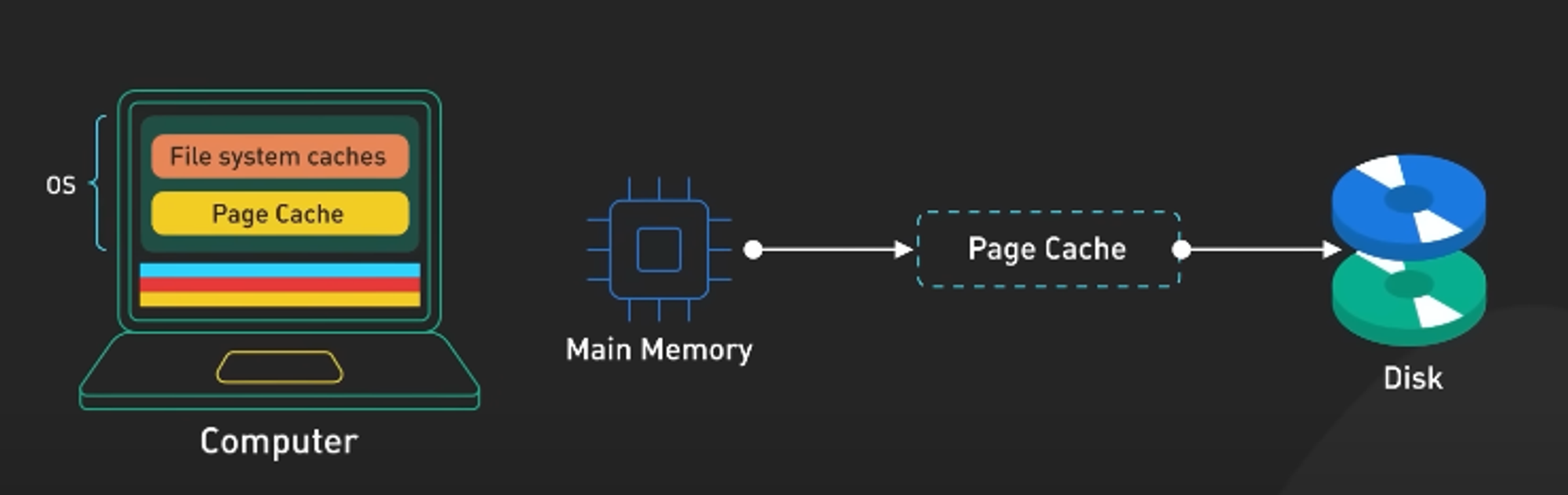
Inode cache(인덱스 노드 캐시)
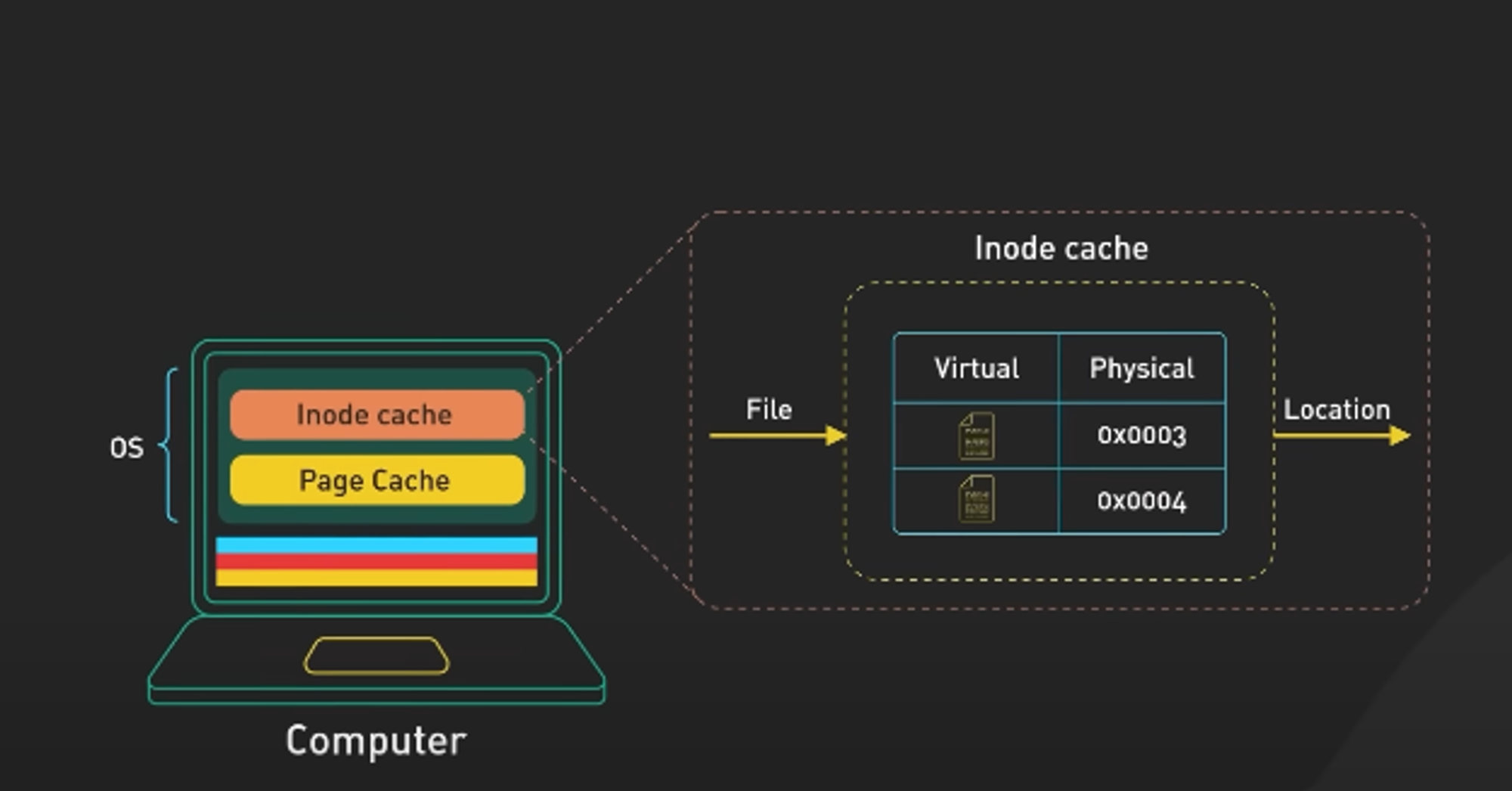
파일 혹은 디렉토리 접근의 요청 숫자를 줄여서 속도를 빠르게 하는 방법입니다. 모든 파일이나 디렉토리는 하나씩 inode 를 가지고 있습니다. 한 개의 inode는 해당 파일의 소유권, 권한, 종류, 실제 데이터 주소 등의 메타 데이터를 가지고 있습니다. 우리가 외부에서는 파일 이름만으로 읽고 쓰는 것으로 보이지만 내부적으로는 inode 정보를 참조해서 처리됩니다.
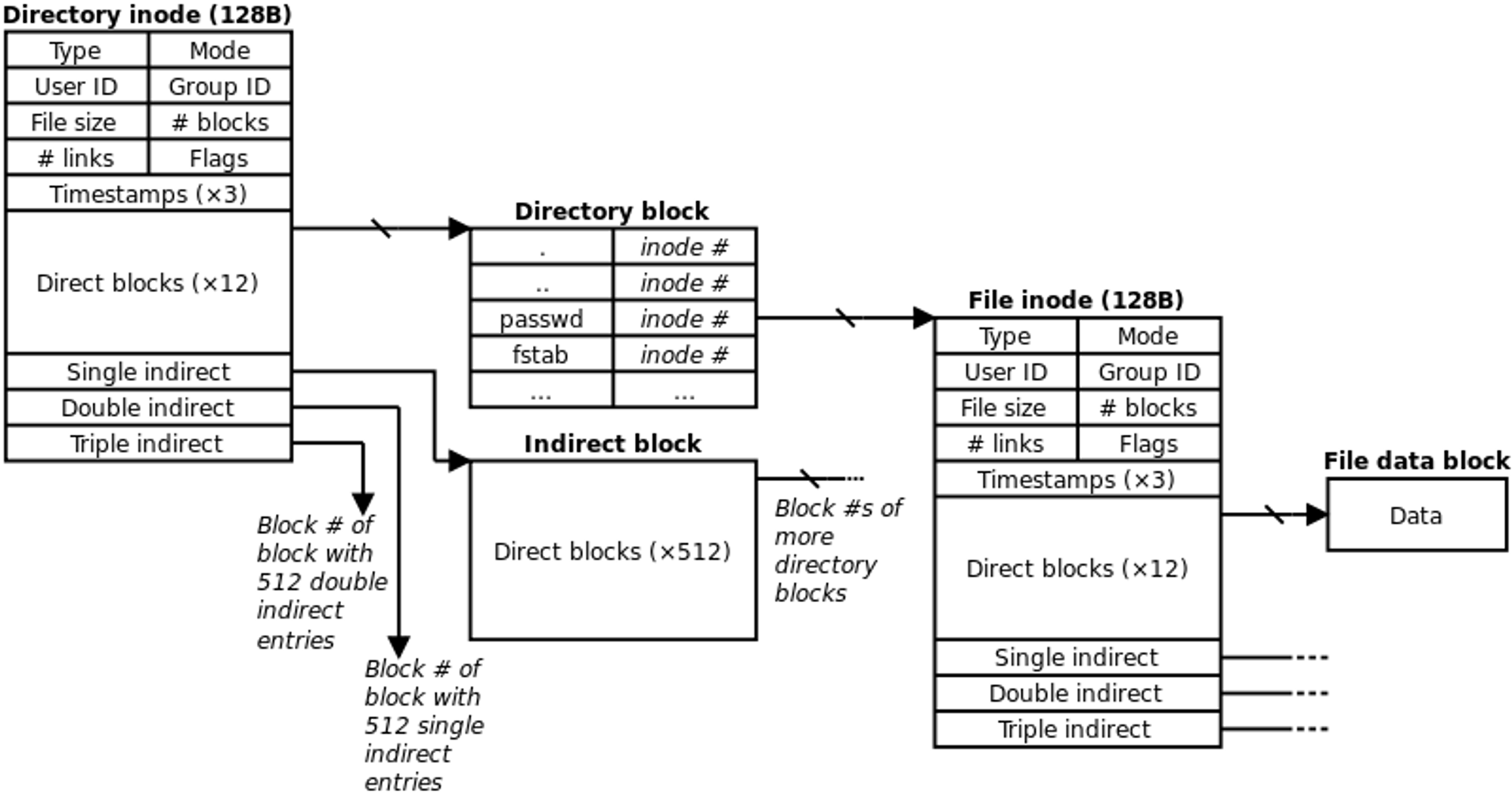
Front-end & Back-end
HTTP Cache
웹 브라우저는 http 응답 데이터를 더 빠르게 가져올 수 있도록 캐싱합니다. 우리는 처음에 http를 통해 데이터를 요청하고 그 결과는 http 헤더의 캐시 만료 정책과 함께 반환됩니다. 같은 데이터를 요청할 때 만료기간이 지나지 않았다면 이 캐시에 있는 데이터를 가져오게 됩니다.

이 캐시는 브라우저 캐시에 저장됩니다. 이 캐시는 조건부로 요청을 받을 수 있는데 마지막 업데이트 날짜를 사용하는 If-Modified-Since, 데이터별 버전 관리인 ETag를 통해 조건부 캐싱을 할 수 있는 If-None-Match, Cache-Control 헤더를 통해 캐시를 무효화할 수 있는 등의 기능이 있습니다.
웹 브라우저의 캐시 방식
- 쿠키
- 만료기한이 있는 key-value 저장소
- 4KB
- 보통 서버에서 만료기한 정해서 발행
- 로컬 스토리지
- 만료기한이 없는 key-value 저장소
- 웹 브라우저를 닫아도 유지되고 도메인 단위로 저장 및 생성
- 10MB
- 세션 스토리지
- 만료기한이 없는 key-value 저장소
- 탭 단위로 세션 스토리지 생성. 탭 닫을 때 데이터 삭제
- 5MB
CDN(Content Delivery Networks)
이미지, 비디오 등의 웹 asset 및 정적 콘텐트를 효과적으로 사용하기 위한 방법입니다. 주로 물리적으로 떨어져있는 사용자에게 콘텐트를 빠르게 제공할 때 사용하며 js 파일 등도 CDN을 이용하는 경우가 많습니다.
이를 통해 웹사이트 로딩 속도가 빨라지고 콘텐츠 제공의 안정성이 높아집니다. 캐싱 방법은 동일하게 최초에는 origin server에서 로드를 하며 동시에 CDN 장비에 저장합니다. 보통 만료시간을 가지고 있어 일정 시간이 지나면 삭제됩니다. 이러한 CDN을 프록시 서버로 달아 다른 기능도 용이하게 하는 경우도 많습니다.
Load Balancer
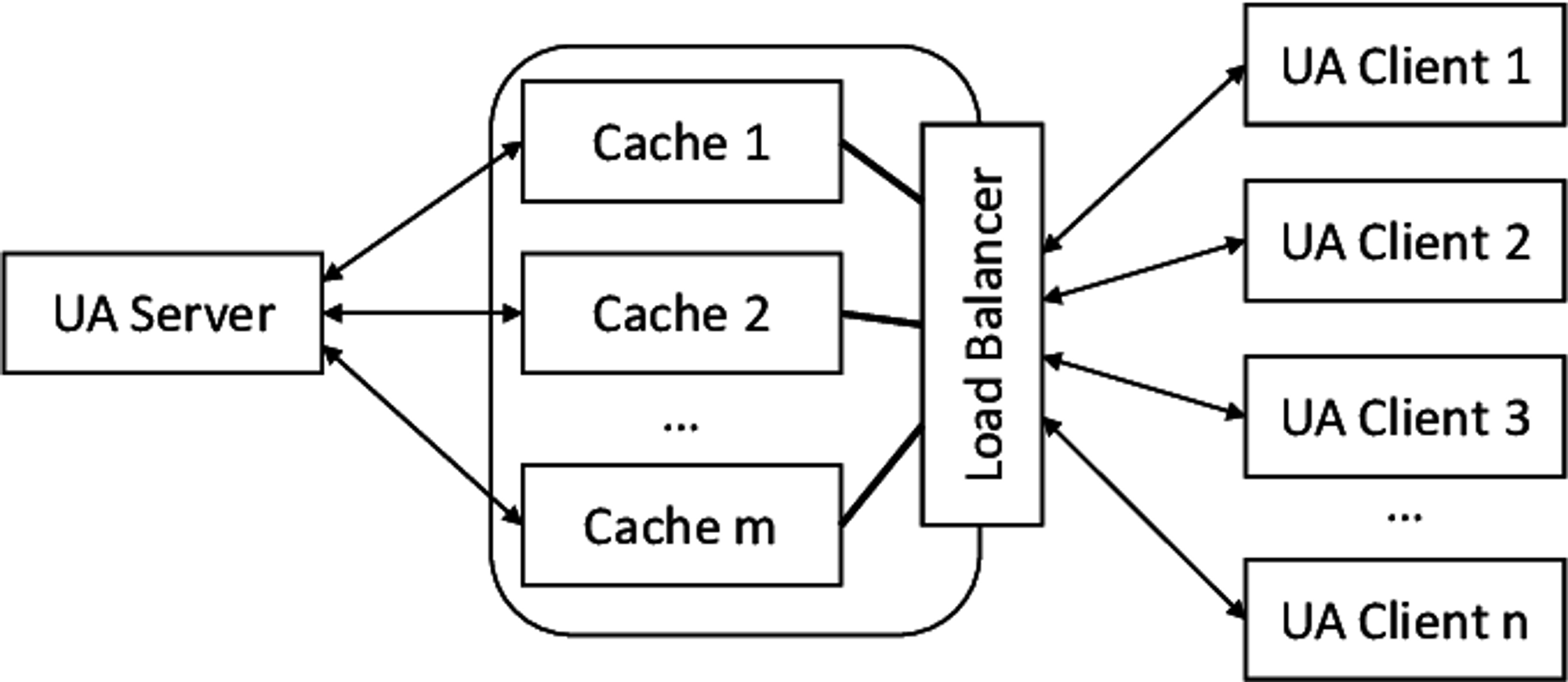
몇몇의 로드밸런서는 백엔드 서버의 부하를 줄이기 위해서 리소스를 캐싱하기도 합니다. 응답을 캐싱하거나 같은 콘텐츠를 요청하는 경우 캐싱된 데이터를 반환합니다. 응답속도를 빠르게 하고 서버의 부하를 줄일 수 있습니다.
Message Broker
캐싱은 언제나 인메모리에 저장되는 것은 아닙니다. 카프카 등의 메시지 브로커는 보관주기를 정해놓고 disk 많은 메시지를 캐싱합니다. 컨슈머는 이 캐싱된 데이터를 가져올 수 있습니다.
Redis(in-memory db)
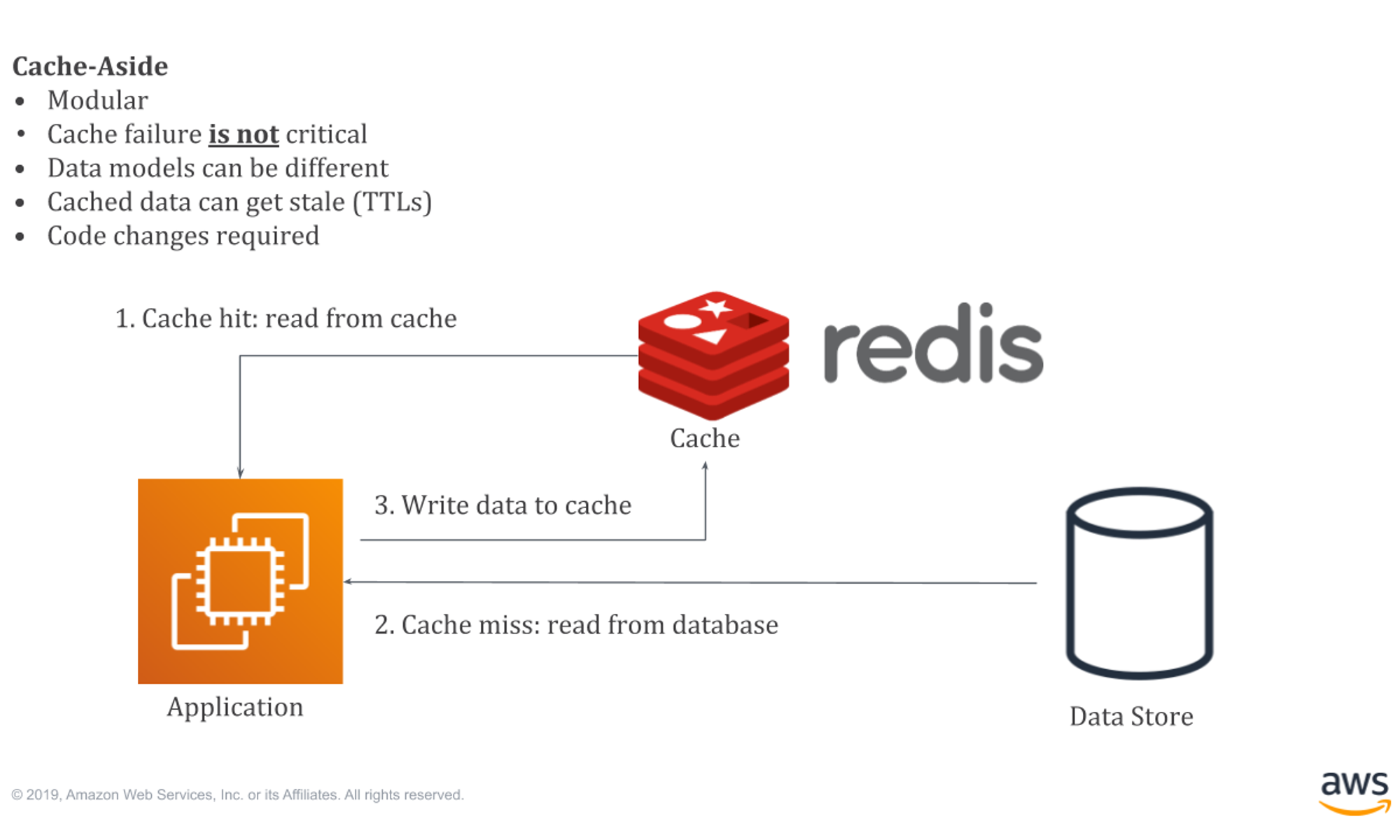
서버는 성능 향상을 위해 인메모리 저장소(대표적으로는 레디스) 등을 통해 캐시 기능을 설계합니다. 일반적인 데이터베이스에 비해 읽기/쓰기 연산 속도 빠릅니다.
RDB
WAL(Write-ahead log)
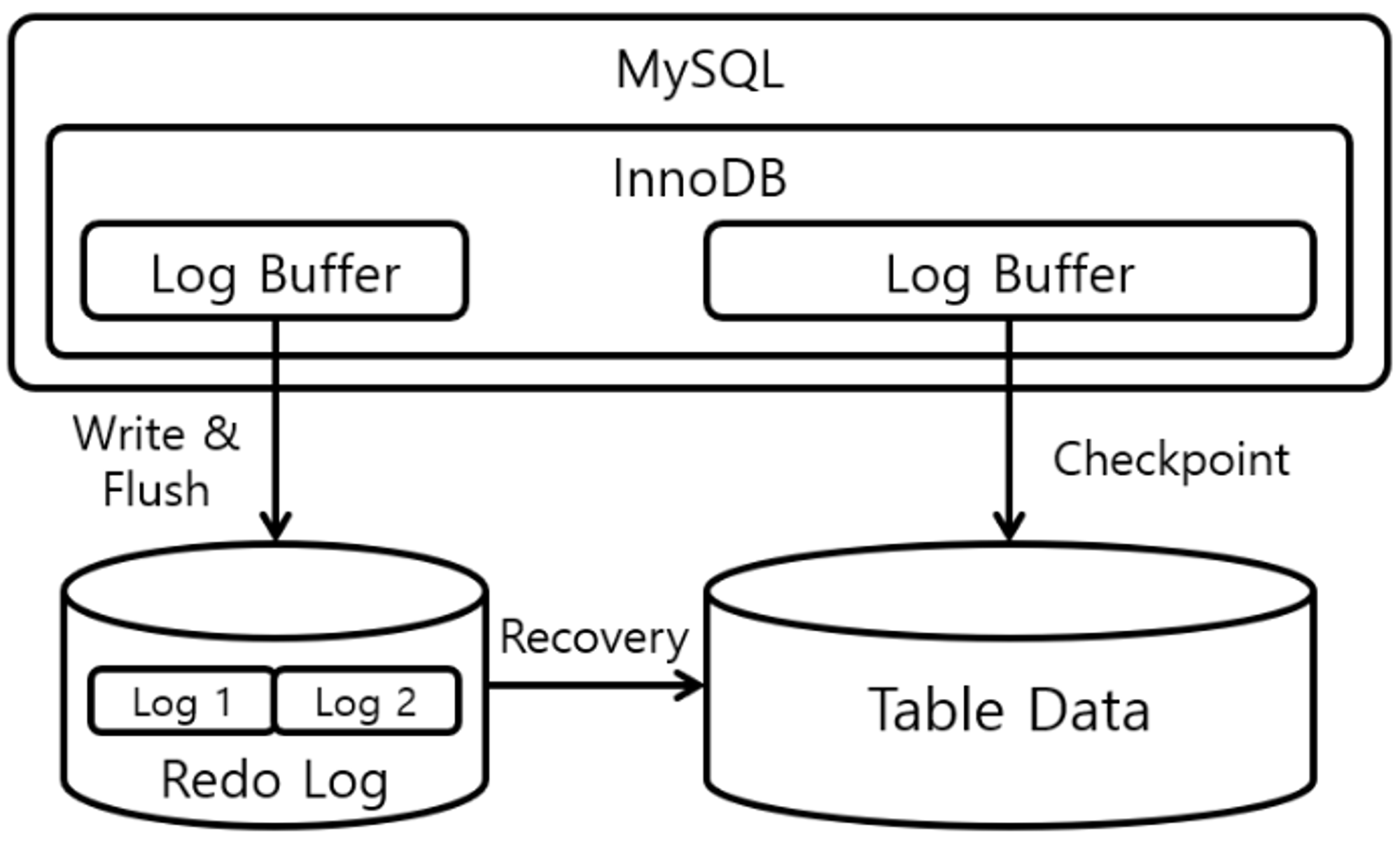
데이터는 전형적으로 B-tree에 인덱싱 되기 전에 WAL(Write-ahead log)에 쓰여집니다. 모든 트랜잭션과 업데이트 로그를 기록하여 트랜잭션의 Durability(내구성)을 보장합니다.
Buffer Pool

MySQL의 스토리지엔진인 InnoDB는 LRU 알고리즘을 통해 최신의 테이블이나 인덱스 데이터를 캐시합니다. 처음에 사용된 데이터는 Old Sublist에 위치하며 접근 빈도 높아질 수록 Head위치하고 New Sublist로 저장됩니다. 반대로 가장 오래된 데이터는 버퍼가 차면 제거됩니다.
Reference
