합성곱 신경망
CNN은 이미지 인식과 음성 인식 등 다양한 곳에서 사용된다.
특히 이미지 인식 분야에서 딥러닝을 활용한 기법은 거의 다 cnn을 기초로 한다.
- CNN은 신명망과 같이 레고 블록처럼 계층을 어떻게 조합하여 만든다.
- 합성곱 계칭 + Pooling 계층
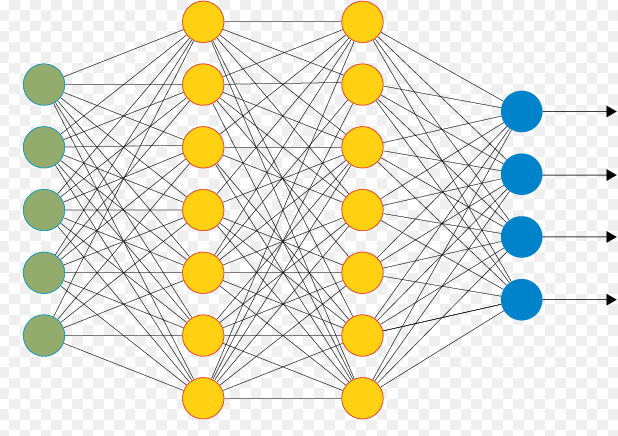
- 이전의 신경망은 인접하는 계층의 모든 뉴런과 결합되어 있습니다. 이를 완전연결(fully-connected)이라고 한다. 완전히 연결된 계층을 Affine 계층이라고 부른다.
CNN 계층은 CONV-ReLU-(Pooling)흐름으로 연결된다.
Affine - ReLU => CONV-ReLU-(Pooling) 이렇게 바뀐 것이다.
완전 연결 계층의 문제점
이전에 사용했던 완전연결 신경망에서는 완전연결 계층을 사용했다.
완전 연결 계층의 문제점은 무엇인가?
"데이터의 형상이 무시된다."예를 들어서 이미지는 통상 세로 가로 채널(색상)으로 구성된 3차원 데이터이다. 그러나 완전 연결 계층에 입력할 때는 3차원 데이터를 평평한 1차원 데이터로 편탄화해줘야 한다. 사실 지끔까지의 mnist 데이터셋을 사용한 사례에서는 형상이 (1x28x28) 1줄로 새운 784개의 데이터를 첫 Affine 계층에 입력했습니다. 이미지는 3차원 형상이며, 이 형상에는 소중한 공간적 정보가 담겨 있다. 예를 들어 공간적으로 가까운 픽셀은 값이 빗스하거나, RGB의 각 채널은 서로 밀접하게 관련되어 있거나, 거리가 먼 픽셀끼리는 별 연관이 없는등, 3차원 속에서 의미를 갖는 본질적인 패턴이 숨어 있을 것입니다 그러나 완전연결 계층은 형상을 무시하고 모든 입력 데이터를 동등한 뉴런(같은 차원의 뉴런)으로 취귑하여 형상에 담긴 정보를 살릴 수 없다.
한편, 합성곱 계층은 형상을 유지합니다. 이미지도 3차원 데이터로 입력받으며, 마찬가지로 다음 계층에도 3차원 데이터로 전달합니다. 그래서 CNN에서는 이미지처럼 형상을 가진 데이터를 제대로 이해할 것이다.
