
논문 링크:
https://arxiv.org/pdf/2209.14988.pdf
논문 소개:
이 논문은 구글에서 나왔고,
ICLR 2023에서 Outstanding paper 상을 받았습니다.
ㅤ
NeRF가 공개된 후,
NeRF의 성능을 개선시키는 연구나 NeRF를 활용해서 3d 장면을 편집하는 등
새로운 활용방안을 제시하는 후속연구들이 나왔는데,
이 논문도 그 후속연구 중 하나입니다.
ㅤ
ㅤ
이 논문은 NeRF 응용 연구분야 중에서도 Text to 3d에 속하고,
text를 3d 이미지로 바꿔주는 방법을 제안합니다.
NeRF가 나온 후, 텍스트를 기반으로 3d 이미지를 만드는데 NeRF를 활용한 첫 접근이라고 합니다.
논문 핵심 개념 요약:
텍스트를 이미지로 변환하는 diffusion 모델과 NeRF 기술을 사용해, 텍스트에 기반한 3d모델을 생성하는 새로운 방법을 제안
▷ “a raccoon astronaut holding his helmet”이라는 텍스트를 입력하면, 위와 같은 3d 모델이 생성됨.
원리:

먼저, 전체과정을 간단하게 살펴보겠습니다.
ㅤ
ㅤ
1) 랜덤한 카메라 시점을 선택하여 랜더링 한 후,
2) 랜더링 한 이미지에 노이즈를 더해, 임베딩된 텍스트와 함께 Imagen에 넣어주면,
3)Imagen은 노이즈를 예측합니다.
4) 예측된 노이즈와 실제 노이즈 사이의 차이를 구해, 그걸 gradient로 사용하게 됩니다.
ㅤ
이 부분을 좀 더 직관적으로 생각해보려 예를 만들어보았습니다.
ㅤ ㅤ
1) 랜덤하게 카메라 시점과 light 값을 샘플링해서 랜더링.
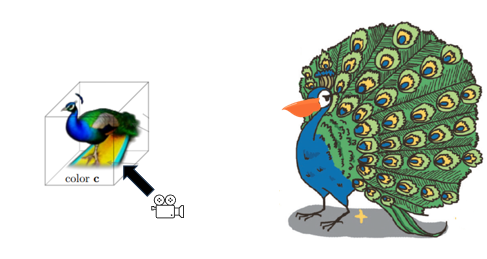
"공작이 서있다."라는 text가 들어왔을 때, 처음에는 NeRF가 학습이 제대로 되지 않은 상태일 것입니다.
극단적인 예로 공작이 펠리컨의 부리를 가지고 있는 것으로 NeRF가 잘못 학습되어있다고 가정하겠습니다.
어떤 랜덤한 카메라 뷰를 선택하고, 그 뷰에서 보이는 화면을 랜더링하면
오른쪽과 같은 사진이 나올 것입니다.
ㅤ
2) 노이즈 추가

여기다가 랜덤한 노이즈를 추가해줄 것이고,
ㅤ
3) Imagen에서 노이즈 예측
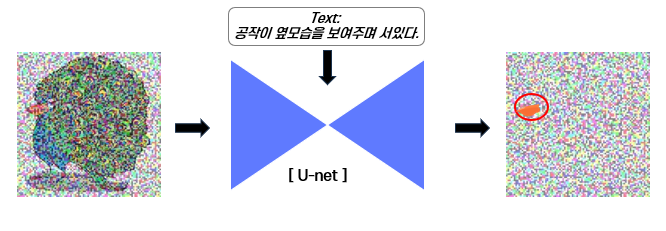
그걸 Imagen에 넣어서 노이즈를 예측해줄 것입니다.
ㅤ
여기서 Imagen의 역할은 랜더링된 사진이 사용자가 입력한 텍스트에 적합한 것인지 평가하는 역할이라고 생각했습니다.
ㅤ
여기서 공작이 옆모습을 보여주며 서있는 모습을 그려달라그랬는데,
랜더링한 사진에 있는 공작이 펠리컨 부리를 가지고 있습니다.
NeRF가 학습이 잘못된거라고 볼 수 있습니다.
ㅤ
ㅤ
이 때, Imagen에서는 부리부분에 심한 노이즈가 껴있다고 생각하고, 노이즈 예측할 때 부리 부분에 큰 값을 넣을 것입니다.
4) Loss를 구해, Backpropagation

하지만, Imagen이 예측한 노이즈와 실제 들어간 노이즈랑 차이가 많이 나겠죠.
ㅤ
그러면, 이게 일반적인 공작의 부리가 아니고 일반적으로 공작은 이런 부리를 갖는구나를 NeRF가 학습할 수 있게 될 것입니다.
ㅤ ㅤ
SDS Loss
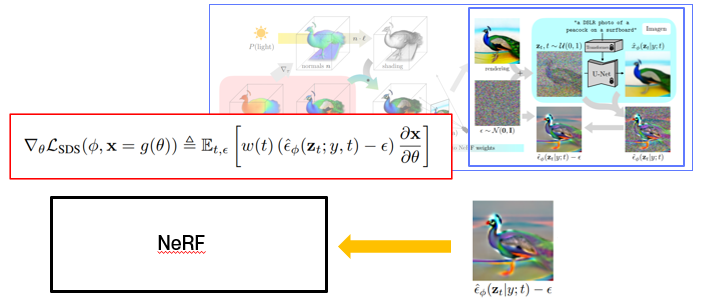
NeRF가 예측한 값과 실제 노이즈 사이의 차이를 SDS loss로 구해서,
미분한 뒤 NeRF를 재학습시킵니다.
ㅤ
성능 향상을 위한 추가 방법 - Text prompt

성능을 위한 디테일들이 있는데,
그 중 위치정보 추가에 대해 알아보겠습니다.
ㅤ
텍스트에서는 보통 일반적인 모습에 대한 묘사를 하기 때문에, 객체의 뒷모습이나 위에서 내려다 본 모습 등은 잘 샘플링을 하지 못하는 문제가 있었습니다.
ㅤ
따라서, 저자들은 카메라의 위치에 대한 디테일을 prompt에 추가해서 사용했다고 합니다.
