
논문 링크:
https://arxiv.org/pdf/2003.08934.pdf
논문 소개:
NeRF는 ECCV 2020 Best Paper Honorable Mention에 선정될 정도로 주목받았습니다.
CVPR에서 2023년 radiance라는 용어가 전년도보다 80%, NeRF는 39%나 더 사용되었다고 합니다.
타임즈는 2022년 최고의 발명품을 NVIDIA의 InstantNeRF로 선정하기도.
논문 핵심 개념 요약:
다양한 각도에서 촬영된 2D 이미지를 사용하여, 3D 장면을 모델링하고 렌더링하기 위해, NeRF라는 모델을 제안.
▷ 드럼의 여러 방향에서의 이미지를 넣어주어 학습시키면, 입력되지 않은 방향에서의 이미지를 생성해준다.
원리:
1) 모델 입출력
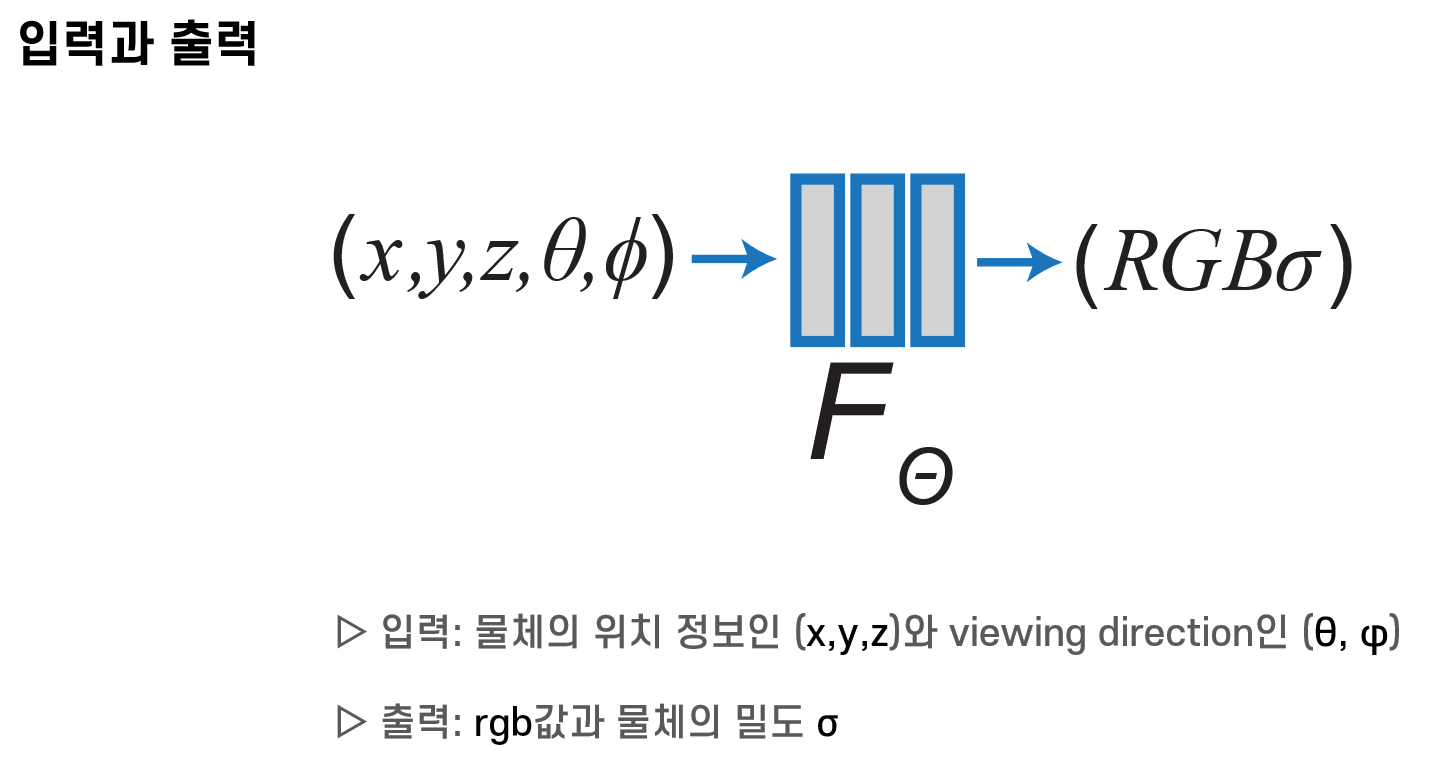
원리에 대해 좀 더 자세히 설명하겠습니다.
먼저, 모델에 들어가는 입력은 물체의 위치정보와 물체를 보는 방향입니다.
출력은 그 방향에서 봤을 때, 해당 위치에 있는 물체의 rgb값과 밀도입니다.
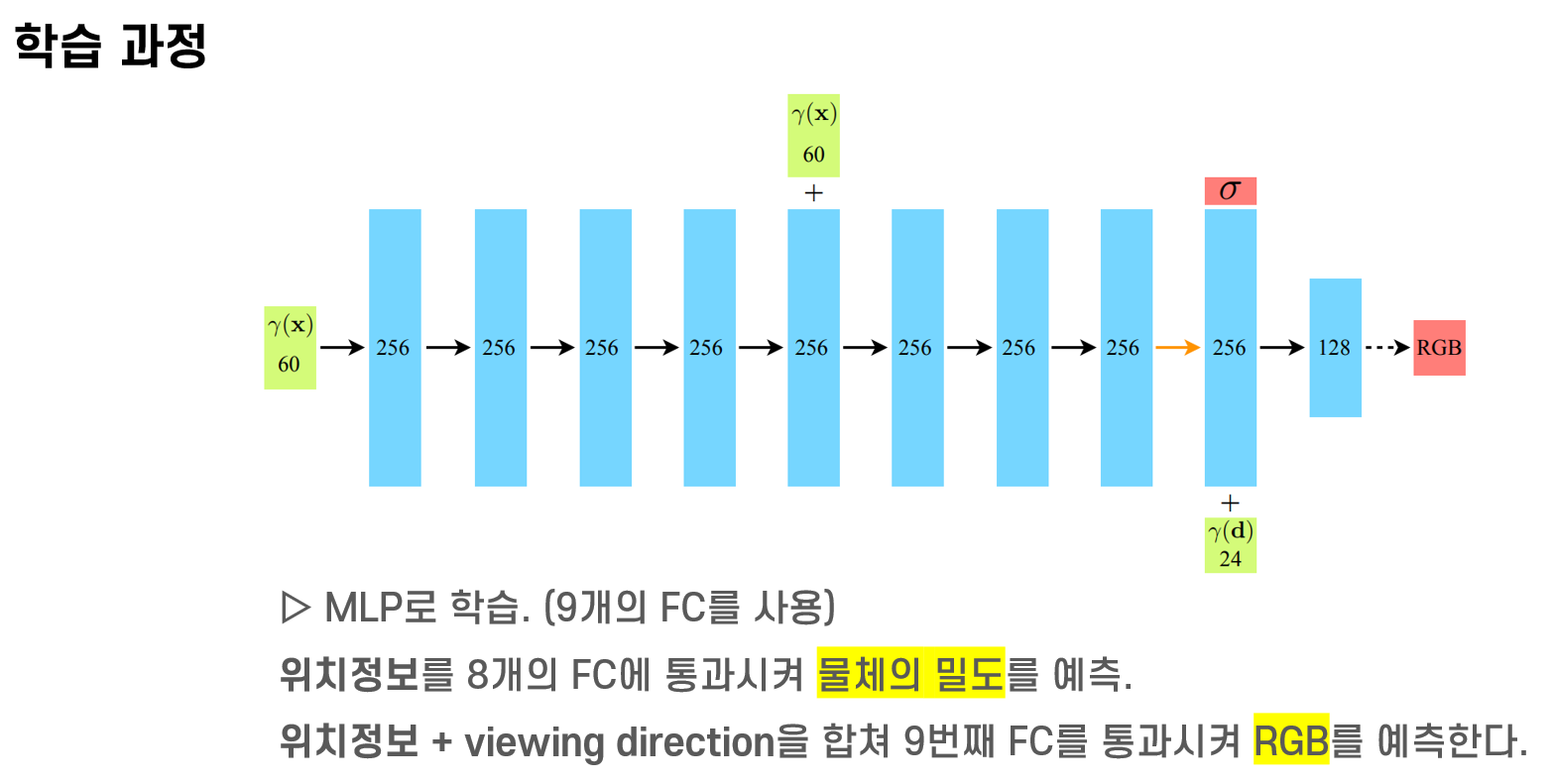
모델은 MLP로 되어있는데,
총 9개의 FC 레이어를 사용합니다.
먼저, 위치정보를 8개의 FC 레이어에 통과시켜 물체의 밀도를 예측합니다.
그 후, 물체를 보는 방향 정보를 넣어주어 9번째 FC 레이어를 통과하면 rgb를 예측합니다.
물체의 밀도는 보는 각도에 상관없이 동일해야 하기 때문에,
위치 정보만 가지고 물체의 밀도를 예측합니다.
그와는 다르게 물체의 색은 물체를 보는 방향에 따라 달라지기 때문에,
물체를 보는 방향 정보도 함께 정보로 넣어 예측하게 됩니다.
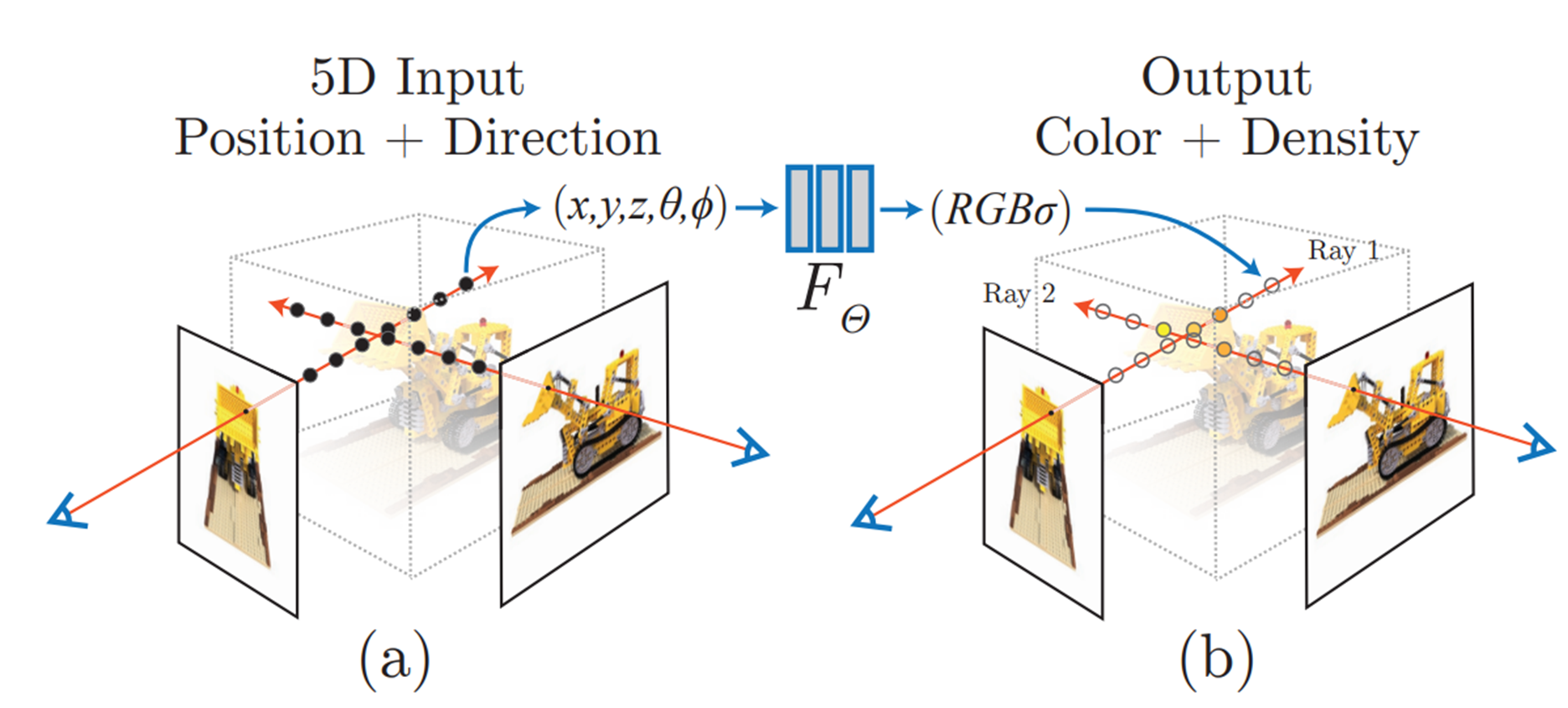
MLP를 통해서 해당 위치에 있는 물체의 rgb값과 밀도값을 얻었는데요,
학습이 끝난 후, 새로운 방향에서 보는 모습을 예측하기 위해,
즉 2d 그림으로 만들어주기 위해 하나의 픽셀로 변환할 필요가 있습니다.
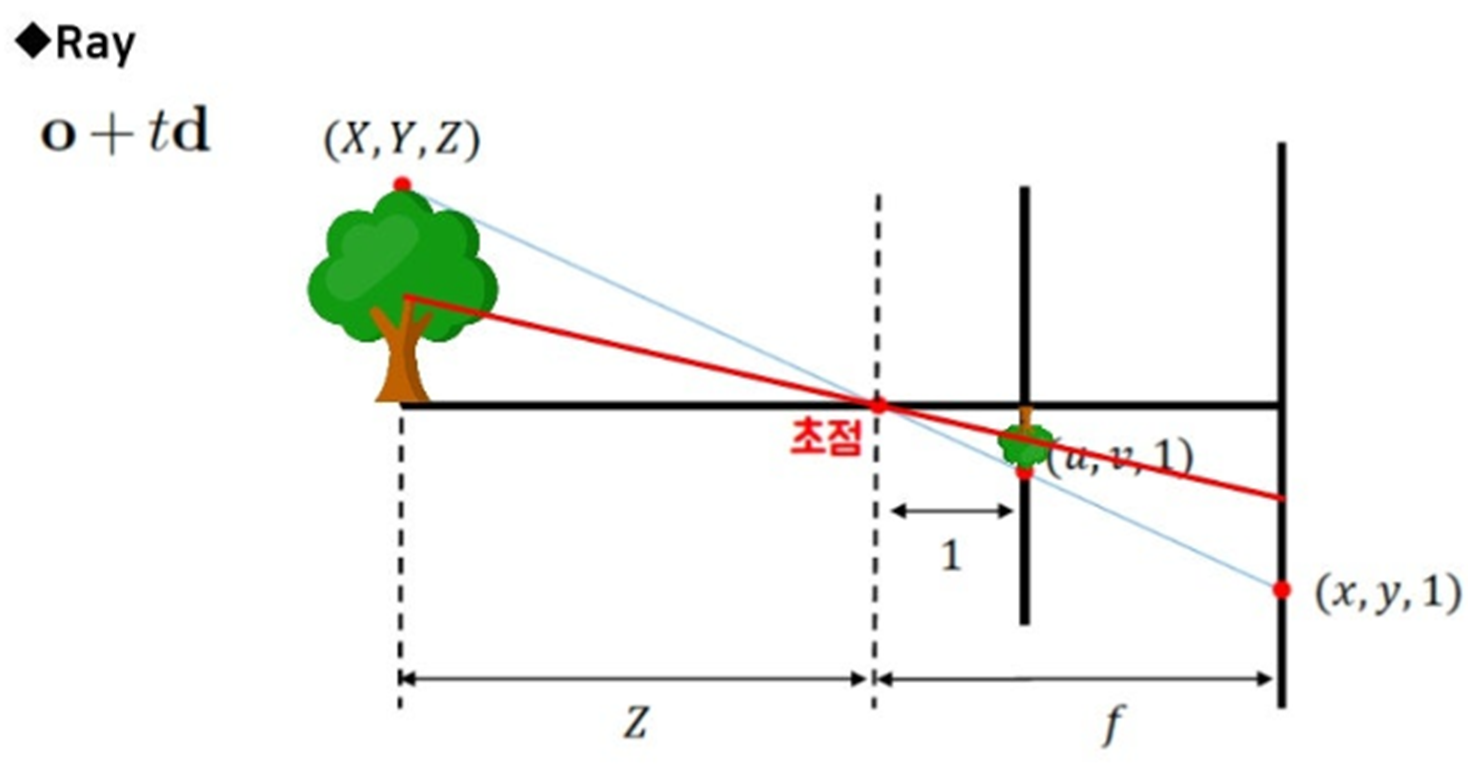
하나의 픽셀로 변환하기 위해 중요한 개념이 ray라는 개념인데,
카메라에서부터 어떤 방향으로 t 커리만큼 이동한 점들의 집합을 ray라고 합니다.
나무의 꼭대기 부분을 픽셀값으로 담고 싶다고 할 때,
카메라에서부터 나무꼭대기 부분까지 이은 직선이 바로 ray가 됩니다.
그리고 이 ray라는 직선 위의 모든 점들이 픽셀값을 만드는데 영향을 미칩니다.
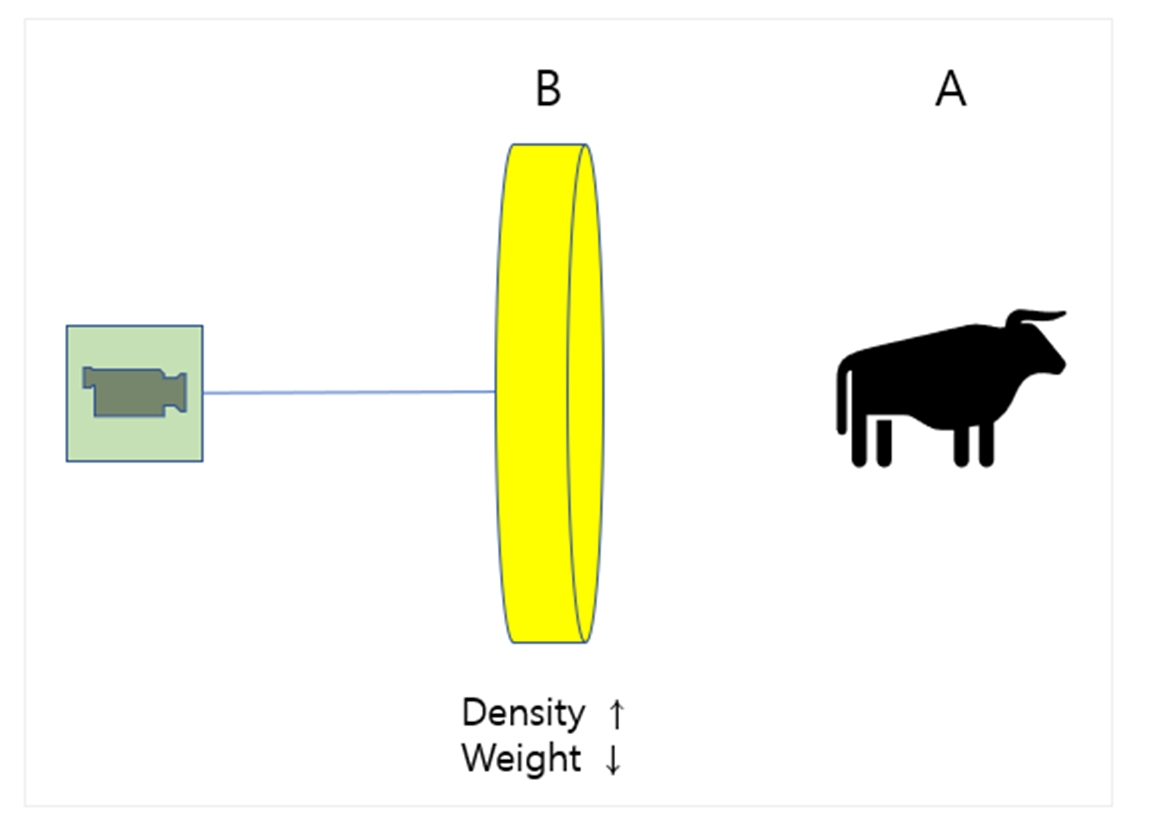
만약, 이 그림에서 A라는 물체를 카메라에 담고 싶다고 하겠습니다.
카메라가 A를 찍는데 B라는 물체가 A보다 앞에 있다고 한다면, B의 밀도가 사진에 영향을 많이 끼치겠죠
만약 B가 나무벽이라면 A는 카메라에 보이지 않을 것이고, 유리라면 A가 잘 보일 것입니다.
따라서, 어떤 물체를 찍을 때, 카메라에서 물체까지 이은 ray 위에 있는 점들의 밀도와 rgb값이,
이미지의 픽셀값에 영향을 끼친다는 것을 알 수 있습니다.

다시 돌아와서, 모델을 이용해 새로운 방향에서 보는 사진을 만들어내기 위해, 각각의 픽셀값을 예측해야 하는데,
이 픽셀값은 ray위에 있는 점들의 밀도와 rgb값에 의해 정해집니다.
따라서, 이 수식을 보시면, ray위에 있는 점들의 rgb값에 밀도값을 가중해 합하는 방식으로, 픽셀값을 결정하게 됩니다.

여기까지가 대략적인 모델의 작동 방식이고, 성능을 향상시키기 위해 논문에서는 몇 가지 방법들을 더 적용했는데요,
첫 번째가 positional encoding입니다.
모델에 인풋으로 좌표값이 들어가는데, 이 좌표값의 차원이 낮으면 모델이 고주파 성분을 잘 학습하지 못해,
성능이 낮게 나오는 문제가 있었습니다.
따라서 좌표값의 차원을 확장하자는 아이디어를 가지고 아래 수식을 만들었고,
이 수식을 x,y,z에 대해 각각 적용해, 차원수를 각 1차원에서 각 2L차원으로 확장하여 사용합니다.

positional encoding을 적용하지 않은 네 번째 사진을 보시면, 흰색 블럭같이 주변과 확 달라지는 모양을 잘 캐치하지 못했는데,
positional encoding을 적용한 두 번쨰 사진은 잘 검출해내는 것을 볼 수 있습니다.
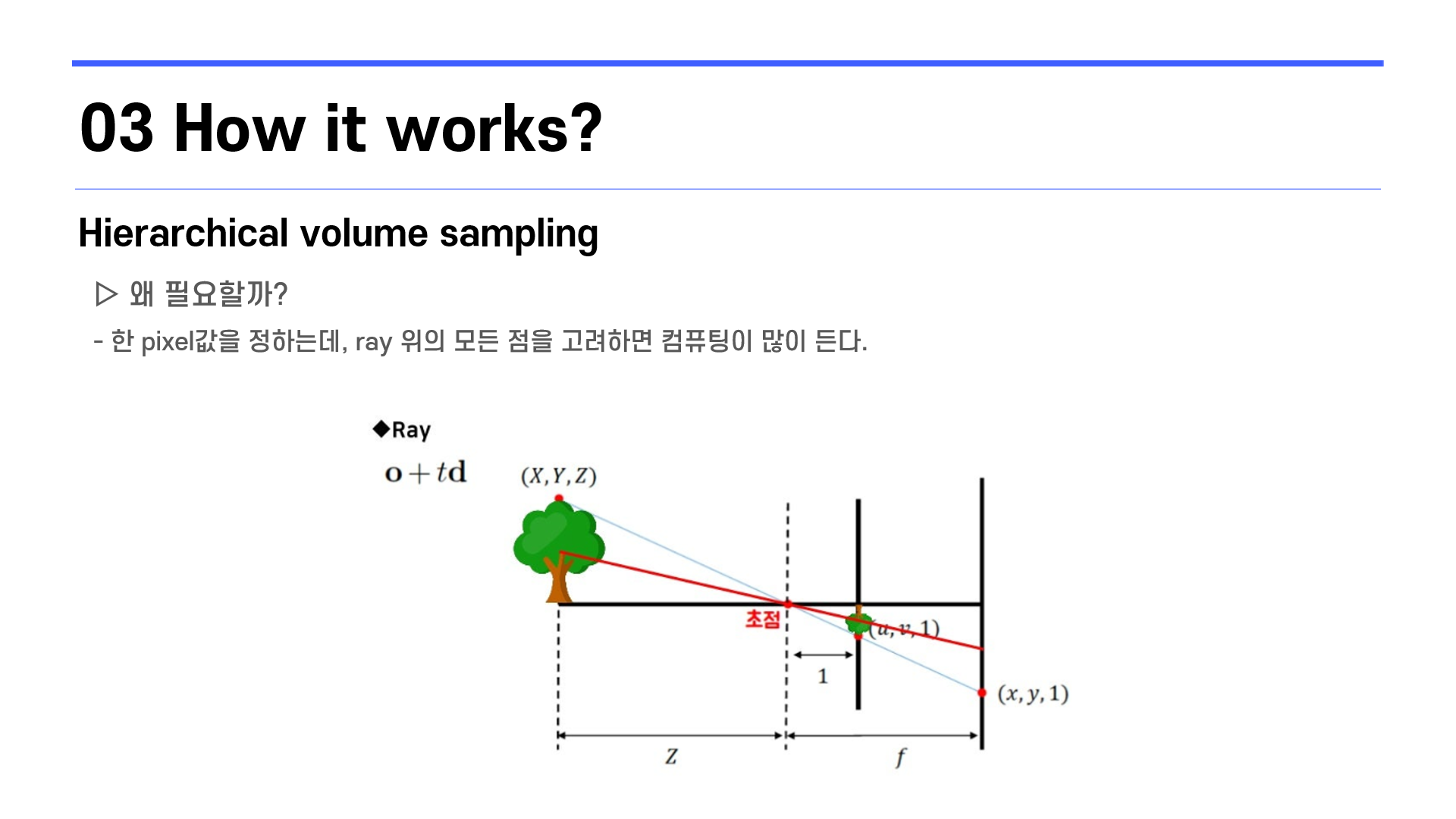
더 나은 성능을 위해 두 번째로, Hierarchical volume sampling을 적용합니다.
아까 픽셀 값 하나를 정하는데, ray 위에 있는 점들을 밀도로 가중합해서 구한다고 말씀드렸습니다.
근데 ray는 직선이고 직선위의 있는 점에 개수는 무한하기 떄문에, ray위의 점을 샘플링해서 구하도록 해주어야 합니다.
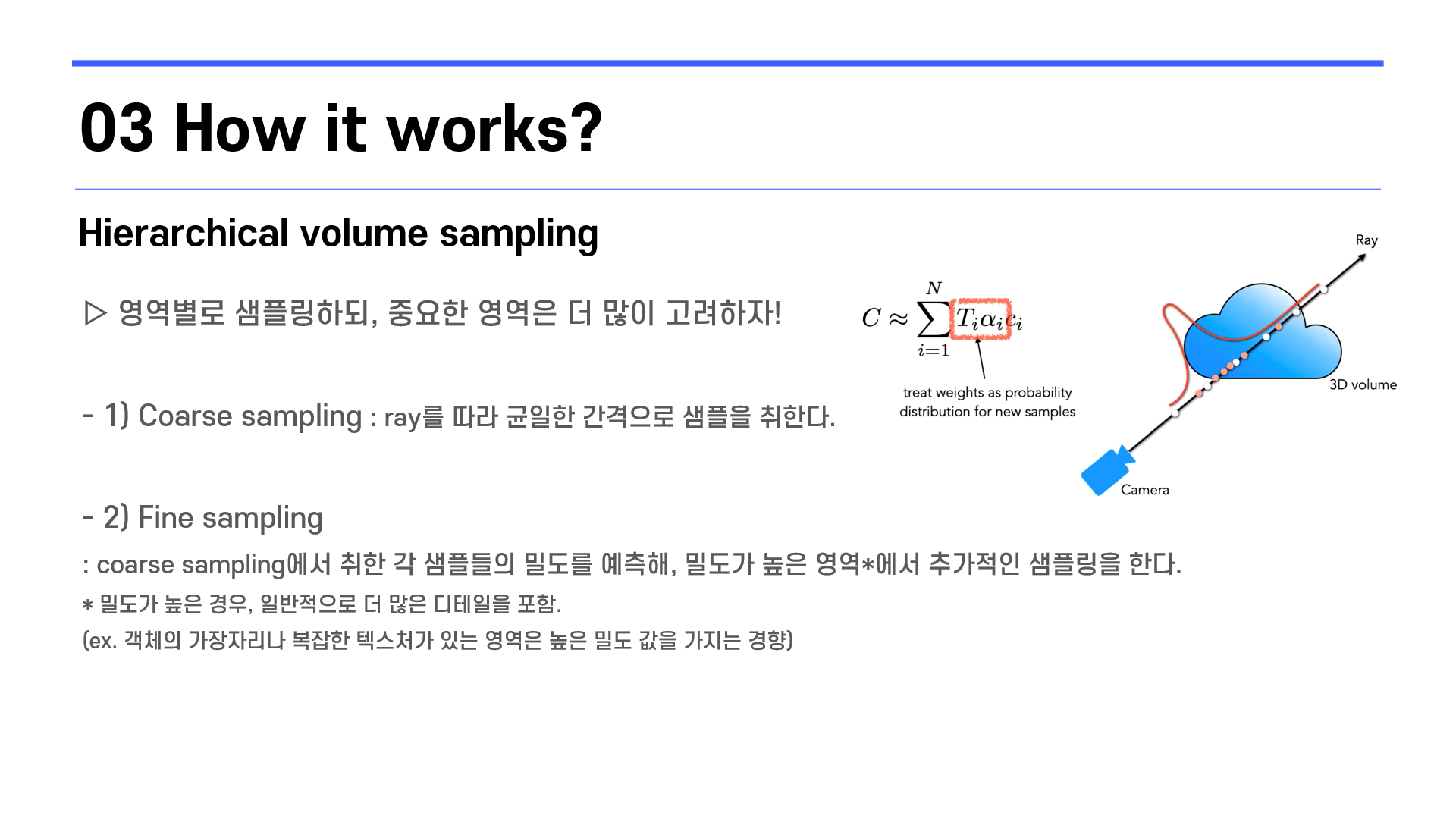
여기서는 ray 위의 어떤 점들을 이용하는지 보여주는데요,
두 개의 샘플링 방식을 함께 사용합니다.
먼저 ray 위의 점을 균일한 간격마다 샘플링합니다.
그 후, 샘플링한 점들 중에서 밀도가 높은 점이 위치한 영역에서, 추가로 샘플링을 하게 됩니다.
이러한 방식으로, 점들을 폭넓게 샘플링하되, 중요한 부분에서 더 많이 샘플링하여 사용하게 됩니다.

2번째 열이 NeRF가 예측한 결과들인데, 다른 모델에 비해 GT와 가장 유사한 텍스처도 보여주고,
선명하게 만들어내는 것을 볼 수 있습니다.
