
논문 링크:
https://arxiv.org/pdf/2211.11559.pdf
논문 소개:

CVPR 2023 Best paper상을 수상한 논문이다.
논문 핵심 개념 요약:
복잡한 Computer Vision 문제를 일반적으로 해결하기 위해, LLM을 활용한 접근 방식을 제안.
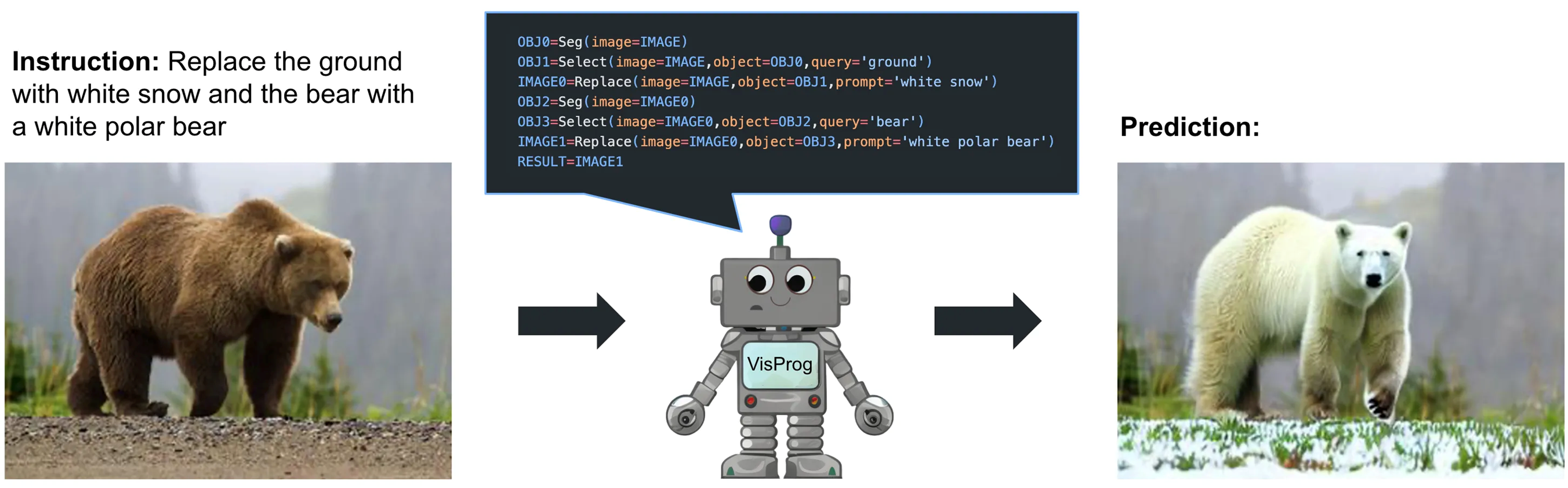 ▷ 자연어로 된 명령을 코드로 변환하고, 해당 코드를 이미지에 대해 실행하여 결과를 도출.
▷ 자연어로 된 명령을 코드로 변환하고, 해당 코드를 이미지에 대해 실행하여 결과를 도출.
-----사용 예시:
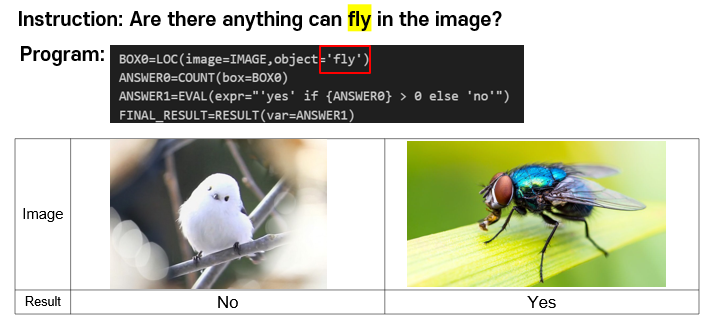
아래와 같은 명령과 이미지를 입력한다.
명령: Localize the woman and tell me the color of her dress.

모델 작동 과정:
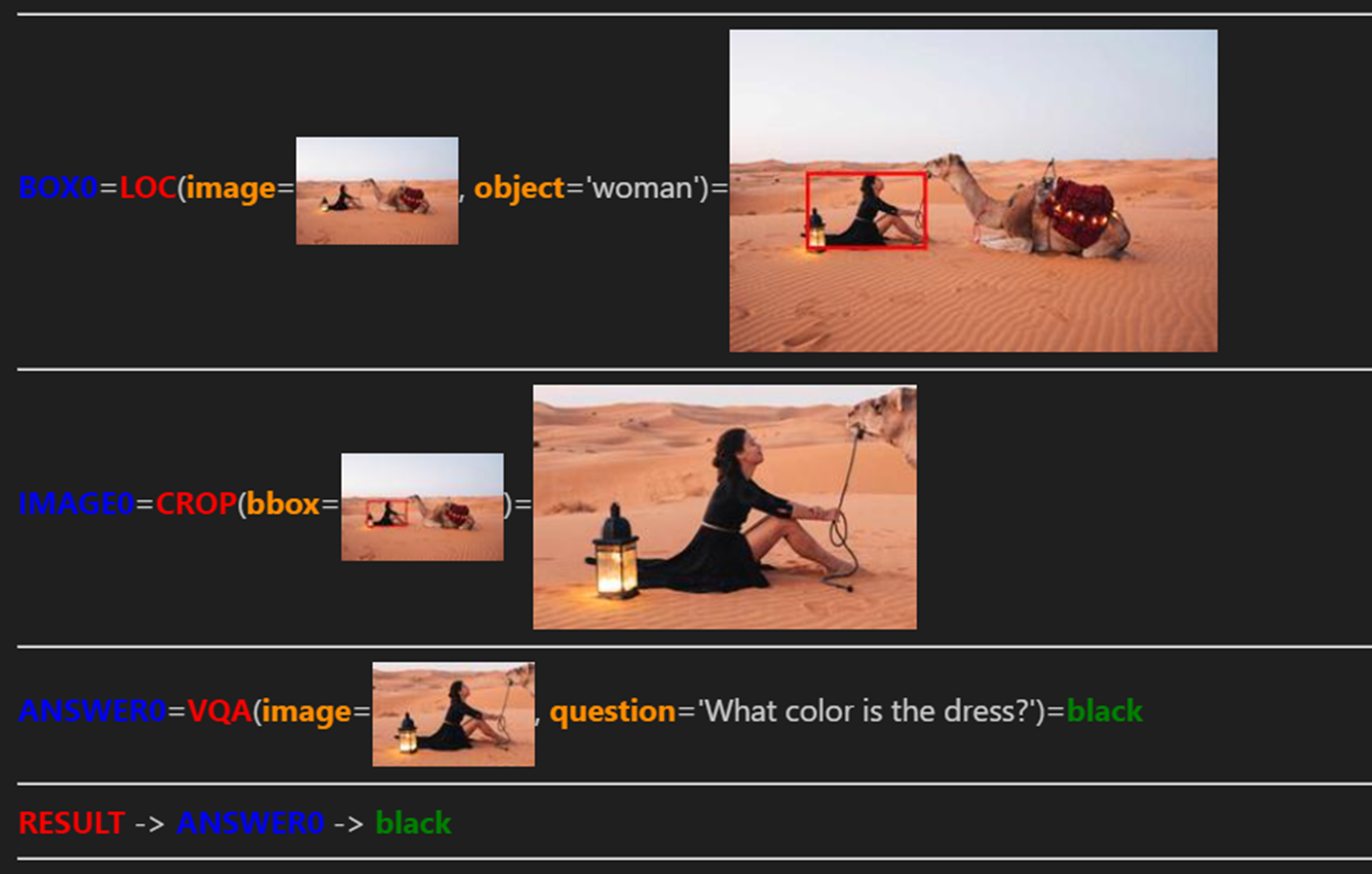
결과: black
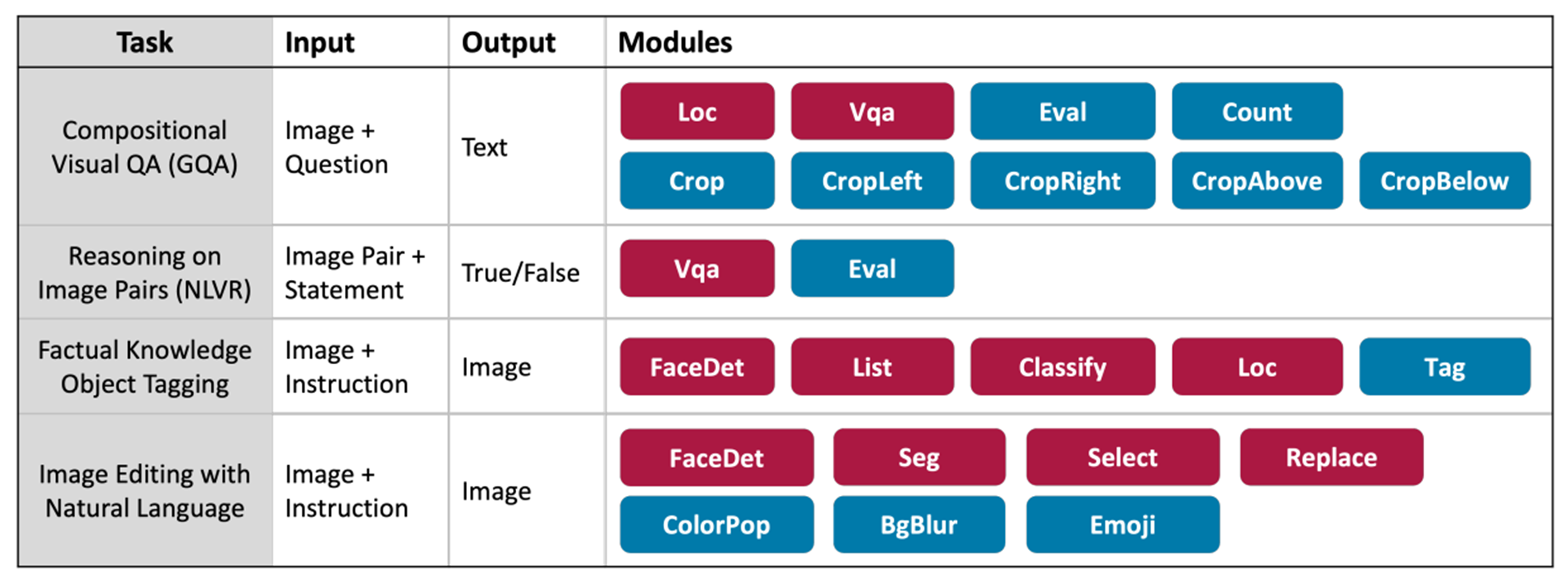
현재 가능한 task:
1) VQA

2) Natural Language Visual Reasoning

3)Factual Knowledge Object Tagging

4) Natural Language Image Editing

원리:
1) Modules
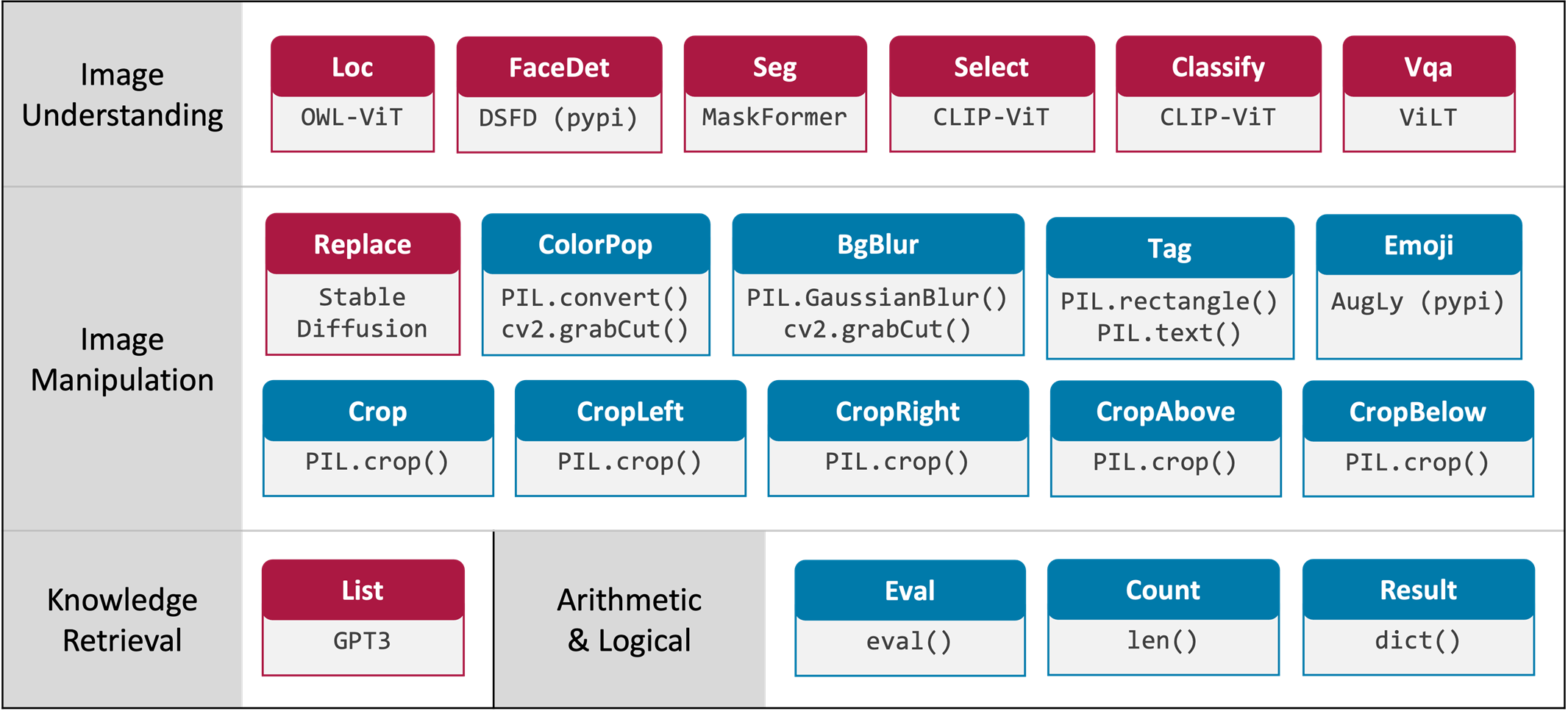
문제를 해결하는 작은 단위인 모듈들이 정의되어 있다.

2) LLM
LLM을 활용하여, 자연어로 된 명령의 의미를 파악한다.
3) Program
파악한 문제를 해결하기 위해, 모듈들을 조합해 알고리즘을 작성한다.
Related work:
1) PICa
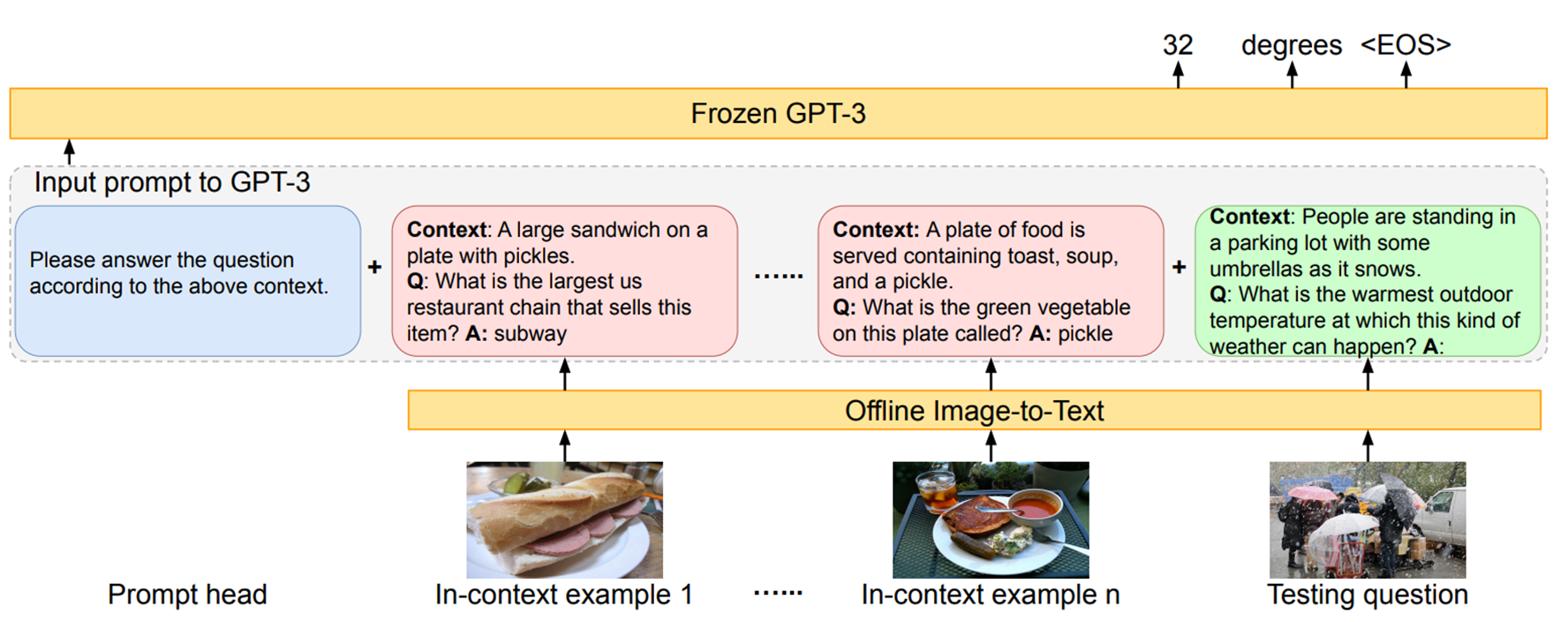
▷ VQA task에 LLM을 사용한 접근법을 제시함.
▷ 비슷한 점: Vision 문제에 LLM을 사용.
▷ 다른 점
1) 이미지를 캡션 또는 태그로 변환하여 GPT가 이해할 수 있는 텍스트로 전환.
2) VQA task에 한정됨.
2) ProgPrompt

▷ LLM을 활용해 로봇의 action plan을 생성.
▷ 비슷한 점: GPT를 활용해, 미리 만들어둔 모듈을 사용하는 알고리즘을 작성.
▷ 다른 점: VisProg의 모듈이 좀더 일반적으로 정의되어 있음.(저자들의 주장)
전통적인 방법과 비교:
1) 컴퓨터 비전 문제를 푸는 기존 접근법
▷ 대량의 데이터를 사용해, 특정 task에 pre-training된 모델을 만들어 냄.
▷ training된 특정 문제가 아닌 task에 효과적이지 못함.
2) Visprog
▷ pre-training 필요 없음.
▷ 다양한 유형의 task를 처리할 수 있음.
▷ 결과가 생성된 각 단계별로 해석 가능.
Challenges and Limitations:
1) Incorrect Program
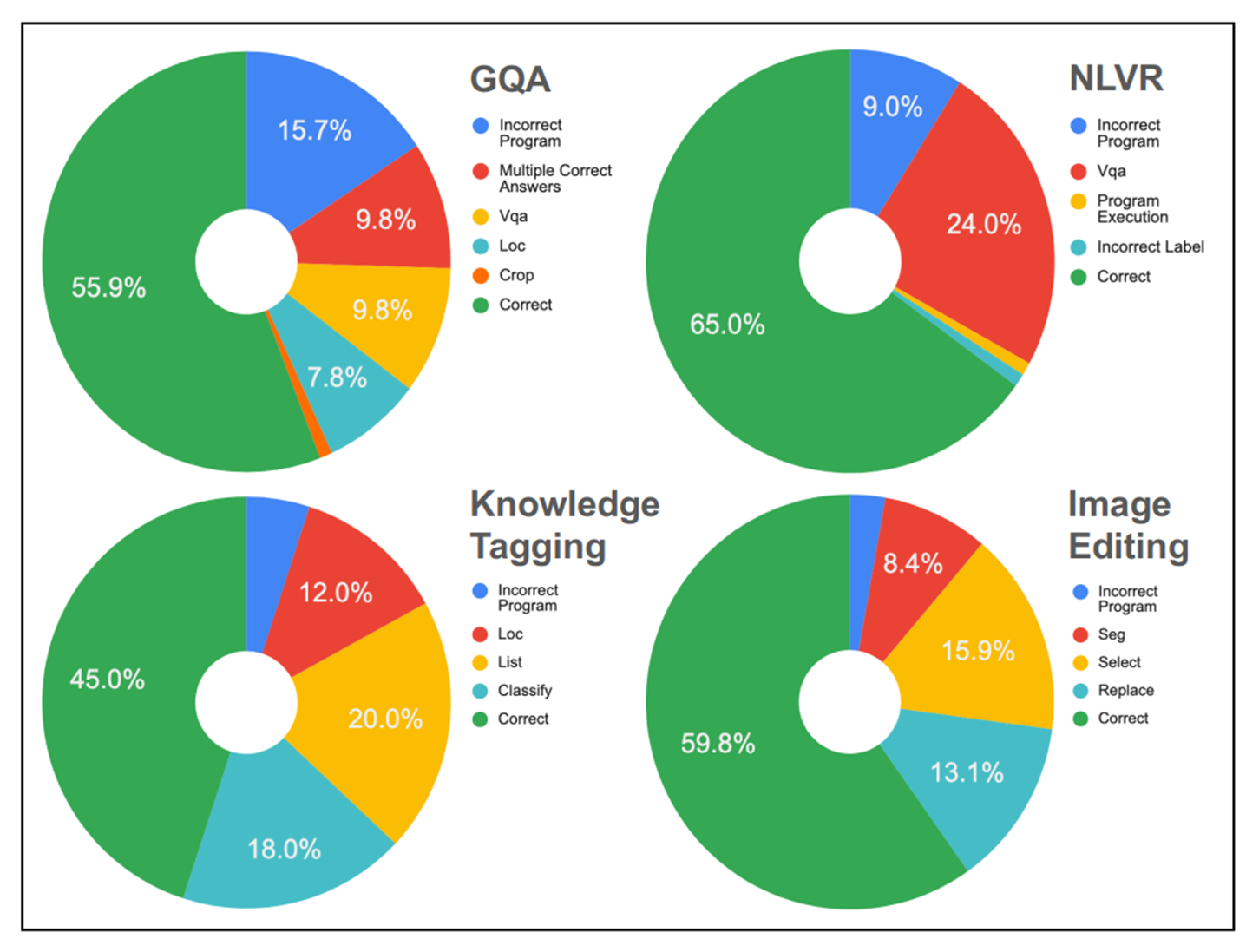 ▷ 파란색으로 칠해진 부분이, gpt가 프로그램을 잘못 작성해서 틀린 부분이다.
▷ 파란색으로 칠해진 부분이, gpt가 프로그램을 잘못 작성해서 틀린 부분이다.
▷ 직접 테스트해보면서 발생한 incorrect program 예시
2) Limited tasks and modules
3) Single-step program generation
▷ 현재는 한 번에 프로그램을 생성.
▷ 일부 행동을 수행하고 새로운 정보를 밝힌 후에는,
이 새로운 데이터를 수용하기 위해 프로그램을 업데이트하거나 확장해야 할 수 있음.
▷ 예시)
“카메라 영상에서 특정 사람을 추적해줘”
초기 프로그램: 첫 번째 카메라 영상에서 특정 사람을 식별.
사람이 다른 카메라 영역으로 이동했음을 인식.
프로그램에 다음 카메라 영상을 분석하는 단계를 추가함.
의의:
- 자연어로 된 명령과 이미지만으로 문제 해결 가능하다는 점
- General-purpose model
- 결과 해석 가능
- 오픈소스로 공개되어 있고, 모듈 생성이 쉬움.
출처:
https://arxiv.org/pdf/2211.11559.pdf
https://blog.allenai.org/visual-programming-ca58c7af51cd
Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. Progprompt: Generating situated robot task plans using large language models. ArXiv, abs/2209.11302, 2022. 3
Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Yumao Lu, Zicheng Liu, and Lijuan Wang. An empirical study of gpt-3 for few-shot knowledge-based vqa. In AAAI, 2022. 3
