CPU Scheduling
배경
한 CPU core에서는 한 번에 하나의 process만 실행할 수 있습니다. 다른 process는 대기해야 합니다. 하지만 이렇게 기다리게 되면 CPU는 아무 작업도 실행하지 못하며, 시간과 자원이 낭비됩니다.
또한 실행해야 할 process가 있지만 앞선 process의 작업이 너무 오래 걸리는 경우에도 비효율적입니다.
운영체제는 운영체제마다의 정책으로 스케쥴링을 수행해 줍니다.
어떤 process가 지금 CPU에서 실행될 것인지를 정해주는 알고리즘들을 가지고 있습니다.
CPU Scheduling
- CPU를 process들 사이에서 교환해주는 작업 실제로는 바로 앞에서 배운 thread를 이용해서 실행하므로 CPU에서 현재 실행될 thread를 골라주는 작업이라는 뜻
- CPU의 활용성(utilization)을 높이기 위해 사용 Process들은 보통 CPU 작업과 입출력 작업을 번갈아 가며 합니다. 하지만 CPU를 사용하는 시간보다 입출력 장치에서 데이터를 읽어오는 데 사용하는 시간이 훨씬 많습니다. → 그래서 process 실행 도중에 CPU를 사용하지 않는 시간이 많아지는데, 이 시간을 이용해 다른 process가 CPU를 사용할 수 있도록 하여 CPU의 활용도를 높일 수 있습니다.
- CPU 스케줄러 : CPU에서 실행될 process를 선택하여 CPU를 분배 실행 중이던 process가 CPU를 사용하지 않아 CPU가 할 일이 없어지게 되면 운영체제의 스케쥴링을 담당하고 있는 CPU 스케쥴러는 ready queue에서 대기하고 있는 여러 process 중에 지금 CPU에서 실행될 process를 선택하여 주어야 합니다. Ready queue : process 중 ready 상태에 있는 process들이 대기하는 queue
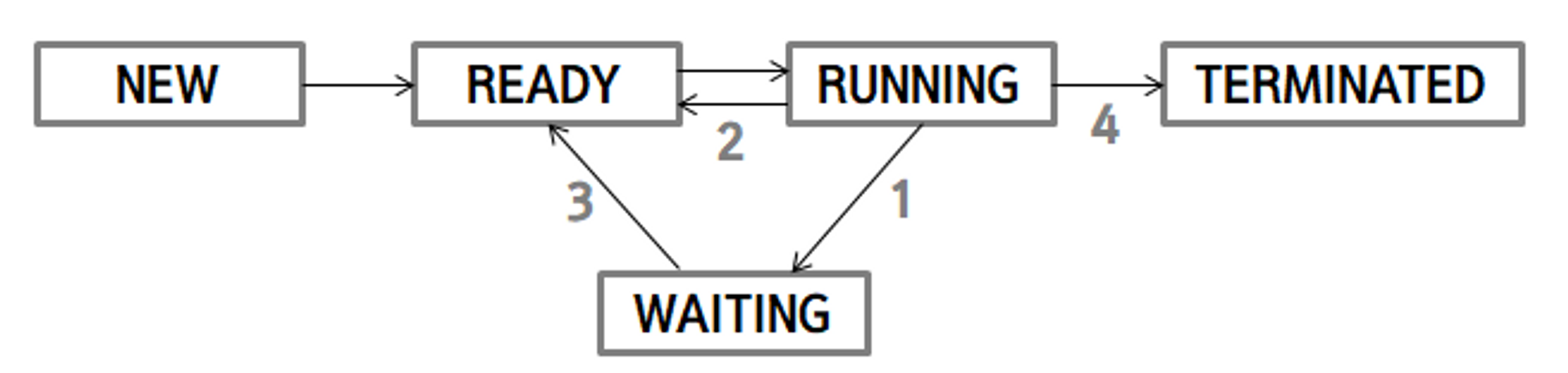
그림에서 숫자가 부여된 화살표로 process가 이동할 때 CPU 스케쥴러는 다음에 실행될 process를 선택해주는 스케쥴링을 수행하게 됩니다
-
Running --> Waiting : Process가 입출력 신호를 기다리거나 부모 process가 자식 process의 종료를 기다릴 때.
-
Running --> Ready : Interrupt가 발생했을 때.
-
Waiting --> Ready : Waiting 상태에서 ready queue로 이동해온 process의 우선순위가 현재 CPU에서 실행되고 있는 process의 우선순위보다 높을 때.
-
Running --> Terminated : Process가 종료되었을 때.
Preemptive vs. Nonpreemptive
선점 스케쥴러 (Preemptive Scheduler)
CPU에서 다른 process가 실행되고 있더라도, 우선 순위에 따라 CPU를 선점하여 뺏어올 수 있는 스케쥴러입니다. 여기서 CPU를 뺏을 때는 interrupt를 이용합니다. Process가 실행 중에 CPU를 빼앗기면, 실행 중인 프로그램은 자연스럽게 분할되어 나중에 실행되게 되겠죠? 이는 실행 시간이 긴 process들의 CPU 독점을 막아 결과적으로 프로그램의 동시성(Concurrency)을 높여줄 수 있게 됩니다.
비선점 스케쥴러 (Nonpreemptive Scheduler)
비선점 스케쥴러는 현재 실행 중인 process가 완료될 때까지 기다리는 스케쥴러입니다.
대기 중인 프로세스들 간에는 우선순위가 있지만 실행 중인 CPU를 강제로 끄지는 않습니다. 실행 중인 process가 끝나면 다음에 CPU를 사용할 process가 누구인지에 대한 우선순위를 결정합니다.
따라서 비선점 스케쥴러는 process state 중 1번째와 4번째 상황에서만 스케쥴링을 실행합니다. 즉, 프로세스가 자발적으로 CPU를 반환할 때에만 스케쥴링이 실행됩니다.
선점 스케쥴러의 약점
선점 스케쥴러는 프로그램의 동시성을 높여주지만 다음의 문제가 발생할 수 있습니다.
Race Condition (대표적인 약점)
- 정의 :둘 이상의 입력이나 조작의 순서 또는 타이밍이 결괏값에 영향을 줄 수 있는 상태
- CS에서는 대부분 공유 메모리나 공유 변수와 같은 공유 자원에 대해 여러 개의 process가 동시에 접근을 시도할 때 그 타이밍이나 순서로 인해 결괏값이 영향을 받는 상태를 말합니다. 만약 두 process들이 메모리를 공유하고 있는데, 한 process가 메모리에 새로운 데이터를 업데이트하고 있는 중에 선점을 당해 실행을 멈추게 되면, 두 process가 서로 다른 데이터를 가지게 될 수도 있다는 것입니다.
system call의 실행 중 선점
system call이 호출되었다는 말은 현재 CPU 모드가 kernel 모드로 변경되어 kernel 내부에서 작업이 수행되고 있다는 것입니다
이때 CPU를 빼앗겨 kernel 내부의 데이터 구조들이 일관성이 없어지는 상태가 생기면 더 큰 문제가 생길 수 있습니다. 그래서 system call의 호출 중에는 선점을 금지하는 등의 방법이 있지만, 완벽한 방법으로 볼 수는 없습니다.
Dispatcher
- 스케쥴러에 의해 선택된 process에게 주어지는 모듈
- context switch와, user 모드로의 전환을 담당하며, 프로그램을 다시 실행하기 위해 프로그램 내부의 적절한 위치로 이동 하는 일을 합니다.
- Process 간의 context switch는 굉장히 많은 시간이 드는 작업이기 때문에 Dispatch Latency가 최소가 되어야 합니다.
- Dispatch Latency : Dispatcher에 의해 실행 중이던 process가 실행을 멈추고 새로운 process가 CPU에서 실행을 시작하기까지 걸리는 시간
스케쥴링 기준 (Scheduling Criteria)
CPU 스케쥴링 알고리즘은 서로 다른 특성을 가지고 있고, 각각의 알고리즘은 특정한 상황에서 사용됩니다. 알고리즘을 선택하기 위해서는 각 알고리즘의 특성을 이해해야 합니다.
기준들에 따라 선택되는 알고리즘이 크게 달라질 수 있기에 여러 기준으로 알고리즘을 비교하여 선택해야 합니다.
최선의 알고리즘을 선택하기 위해 명확한 기준을 세우는 것이 중요하고 그 중 대표적인 6가지 기준을 살펴보겠습니다.
1. CPU Utilization (CPU 이용률)
CPU가 가능한 모든 시간에 일을 하기는 것이 좋습니다. 다시 말해 CPU가 작동하지 않는 시간을 최대한 줄이고자 한다는 것입니다. 실제 실행에서는 30~40% 정도의 이용률을 갖습니다.
2. Throughput (처리량)
- 처리량은 단위 시간 당 완료되는 process의 작업의 수.
3. Turnaround Time (총처리 시간)
- process가 CPU를 할당받기 위하여 제출된 시간으로부터 작업이 완료될 때 까지 시간
- CPU가 아닌 process의 입장에서 생각하면, Process의 관점에서 좋은 알고리즘은 자기 자신이 가장 빠르게 처리될 수 있는 알고리즘 입니다.
- 여기에는 메모리에 들어가기 위해 기다리는 시간, ready queue에서의 대기 시간, CPU에서 실행되는 시간, 입출력 연산을 수행하는 시간까지 모두 포함됩니다.
4. Waiting Time (대기 시간)
- ready queue에서 대기하는 시간의 총합 스케쥴링 알고리즘은 process가 CPU에서 실행되는 총 시간의 합이나, 메모리에 들어가는 시간 등에는 전혀 영향을 미치지 못합니다. 대기 시간은 스케쥴링 알고리즘이 직접적으로 영향을 미칠 수 있는 ready queue에서 대기하는 시간의 총합 만을 의미합니다.
5. Response Time (응답 시간)
- process가 제출된 시점으로부터 첫 번째 응답이 온 시점까지의 시간 Interactive system(대화식 시스템)에서는 총처리 시간보다 얼마나 빠르게 응답을 받는가가 가장 좋은 기준이 될 수 있습니다.
6. Fairness (공정성)
- 각 process들이 얼마나 공평하게 CPU를 나누어 사용하는가를 의미
Scheduling Algorithm 종류
1. FCFS Scheduling (First-Come, First-Served Scheduling (선입 선처리 스케쥴링)
- FCFS는 말그대로 들어온 순서대로 처리해주는, 먼저 오면 먼저 처리해주는 선착순 알고리즘
- 대표적인 비선점 스케쥴링 알고리즘
- 장점 : 간단하고 구현이 쉽다
- 단점 : 평균적인 대기 시간이 길다. Convoy Effect (호위 효과)가 나타난다. 도착한 순서대로 ready queue에 차곡차곡 들어가게 되고, 제일 앞의 process부터 CPU를 할당받게 됩니다. 먼저 온 process가 먼저 실행되기 때문에 먼저 온 process가 실행 시간이 정말 긴 process라면 뒤에 도착한 process들은 정말 금방 끝나는 process들이라 하더라도 먼저 온 process가 완료될 때까지 기다려야 하기 때문입니다. 라고 부르며, 평균 대기 시간을 늘리는 주범이 됩니다.
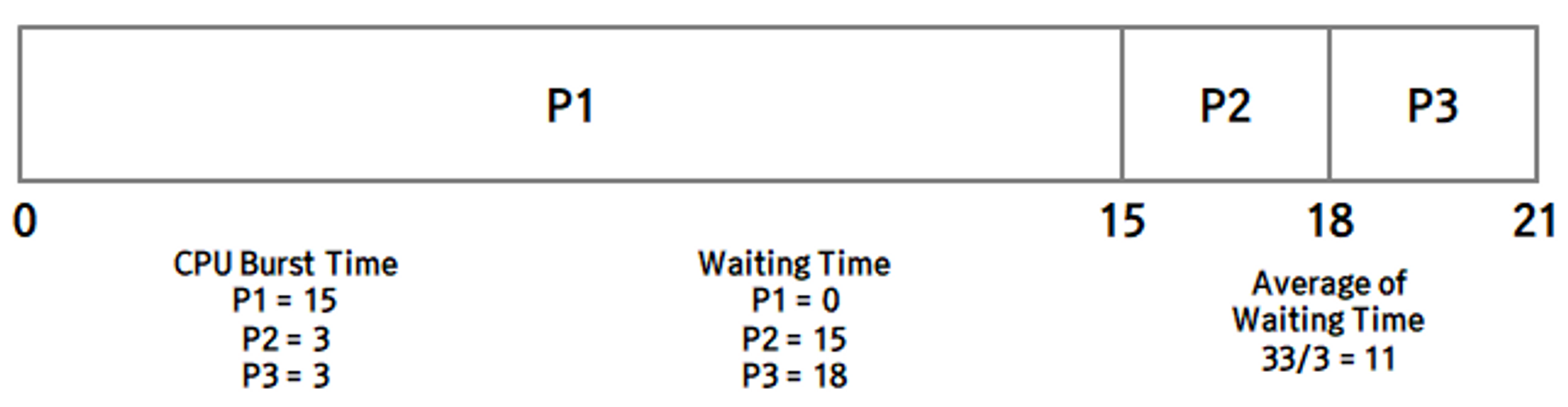
FCFS Scheduling Algorithm
2. SJF Scheduling (Shortest-Job-First Schedulinig (최단 작업 우선 스케쥴링)
- 작업 시간이 짧은 process부터 먼저 해결하는 알고리즘
- 스케쥴링 정책에 따라 선점 스케쥴링 , 비선점 스케쥴링될 수 있습니다 Ready queue에 들어온 process의 CPU 작업 시간이 현재 CPU에서 실행 중인 process의 잔여 작업 시간보다 적을 때
- 선점을 하여 CPU를 빼앗게 되면 선점 알고리즘
- 선점형일 때는 Shortest Remaining Time First Scheduling (최소 잔여 시간 우선 스케쥴링)이라고도 불린다.
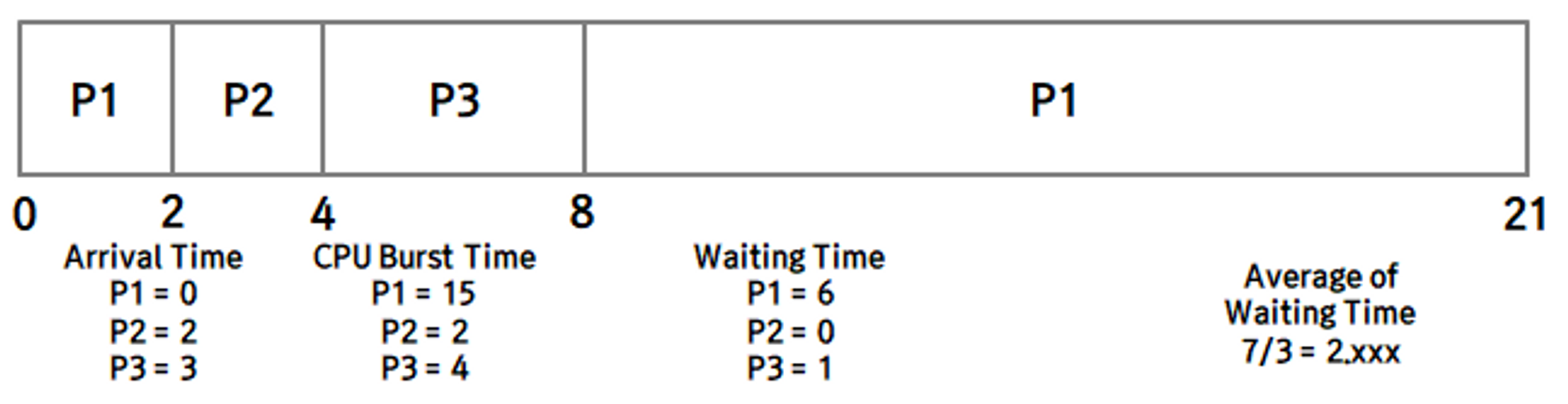
- 선점을 하지는 않고 ready queue 내에서만 우선순위에 따라 실행 순서를 정하면 비선점 알고리즘
- 선점을 하여 CPU를 빼앗게 되면 선점 알고리즘
- SJF를 통해서 FCFS에 비해 대기 시간을 비약적으로 줄일 수 있습니다
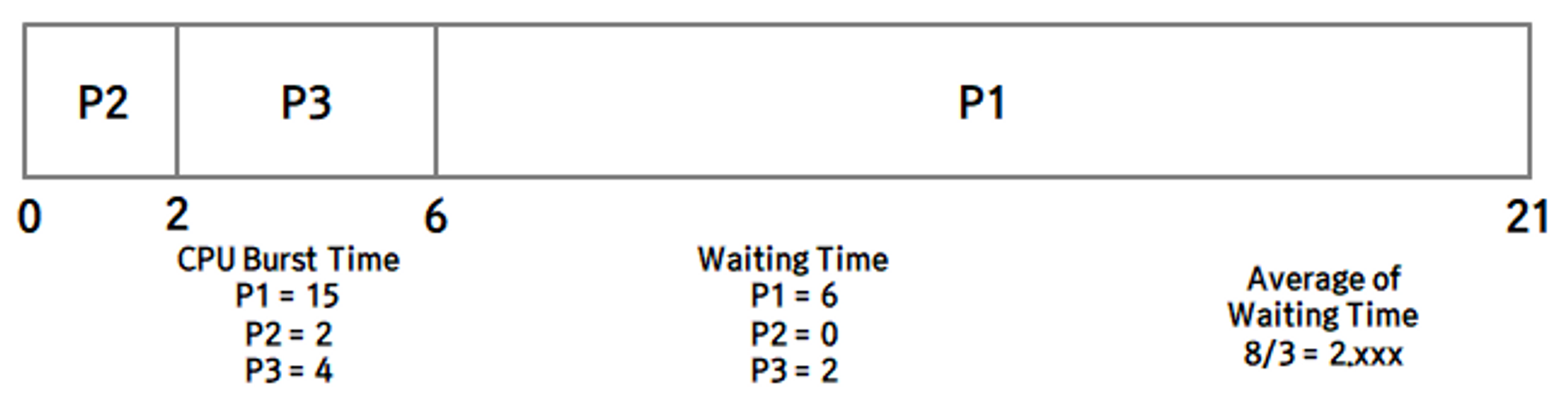
- process의 CPU 작업 시간 계산 Process의 CPU 작업 시간을 계산하는 것은 굉장히 어렵습니다 이 전의 CPU 작업 시간을 이용하여 다음 작업 시간을 예측하는 방법을 사용합니다.
최근의 작업 시간과 전체 과거의 작업 시간을 따로 계산하여, 두 값에 가중치를 부과하여 합하는 형식으로 작업 시간을 계산합니다.
3. Priority Scheduling (우선 순위 스케쥴링)
- 모든 process들에게 나름의 기준으로 우선 순위를 부여하는 스케쥴링
- 숫자가 낮을수록 높은 우선순위를 가진다.
- 내부적인 우선순위 : CPU 작동 시간이라던지, 시간제한, 열린 파일의 수 등을 기준으로
- 외부적인 우선순위 : program에 있어서 해당 process이 가지는 중요성, 컴퓨터 사용에 관한 우선순위 등을 기준으로
- 선점 스케쥴링이 될 수도 있고 비선점 스케쥴링이 될 수도 있다
- 큰 단점으로는 Starvation문제(or Indefinite Blocking (무한 봉쇄)) 를 가진다. 우선순위가 낮은 process들이 다른 높은 우선순위의 process들이 계속 들어오는 바람에 시간이 아무리 흘러도 실행될 기회를 잡지 못하는 상태 해결방법 Aging(노화) : 낮은 우선순위의 process들이 일정 시간동안 실행되지 못하면 우선순위를 조금 높여주는 방법입니다. 시간이 흐르게 되면 아무리 낮은 우선순위의 process더라도 결국에는 우선순위를 높여 실행될 수 있게 됩니다.
4. Round-Robin Scheduling (RR Scheduling)
- 시간을 할당하여 스케쥴링을 하는 방법
- FCFS와 유사하지만 선점 스케쥴링을 결합한 방식
- Time Quantum(시간 할당량)이라는 시간 단위의 개념을 정의하여 이용.
-
Ready queue는 FCFS처럼 관리되기 때문에 새로운 process가 들어오면 queue의 가장 뒤에 추가. 우선 time quantum에 해당하는 시간을 정의(1초0.1초 등)
-
ready queue의 가장 앞에 있는 process가 선택되고, CPU에서 time quantum 만큼 실행.
-
Time quantum만큼 실행된 뒤에 아직 process의 작업이 완료되지 않았다면, 작업을 멈추고 ready queue의 제일 뒤에 추가.
-
ready queue의 제일 앞에 있는 process가 다시 time quantum만큼 CPU에서 수행이 됩니다
time quantum을 너무 길게 잡으면 FCFS와 같은 형태가 될 수 있고, 너무 작게 잡으면, context switch가 자주 발생하게 되어 성능이 떨어지게 됩니다.
그래서 적절한 시간의 time quantum을 설정해 주어야 하며 당연히 context switch에 걸리는 시간보다는 time quantum이 훨씬 길어야 합니다.
일반적으로 10-100 밀리초로 설정합니다.
5. Multilevel Queue Scheduling (다단계 큐 스케쥴링)
- 다단계 큐를 활용한 스케쥴링 방법
- 다단계 큐
- 여러개의 queue를 계층적으로 이용하여 구현
- 각 queue들은 각각의 스케쥴링 알고리즘들을 가지는 독립적인 queue
- 모든 process들은 메모리 크기, process의 우선 순위, process 유형 등의 특성에 따라 한 개의 queue에 영구적으로 할당
(CPU에 할당받기 위해서는 자신이 배정된 queue에만 들어갈 수 있다). - queue들 사이에도 우선순위 스케쥴링이 되어있어 상위에 있는 queue의 process들이 우선순위가 높아 먼저 CPU를 할당받으며, 반드시 자신 보다 상위에 있는 queue가 비어있을 때에만 스케쥴링을 시작.
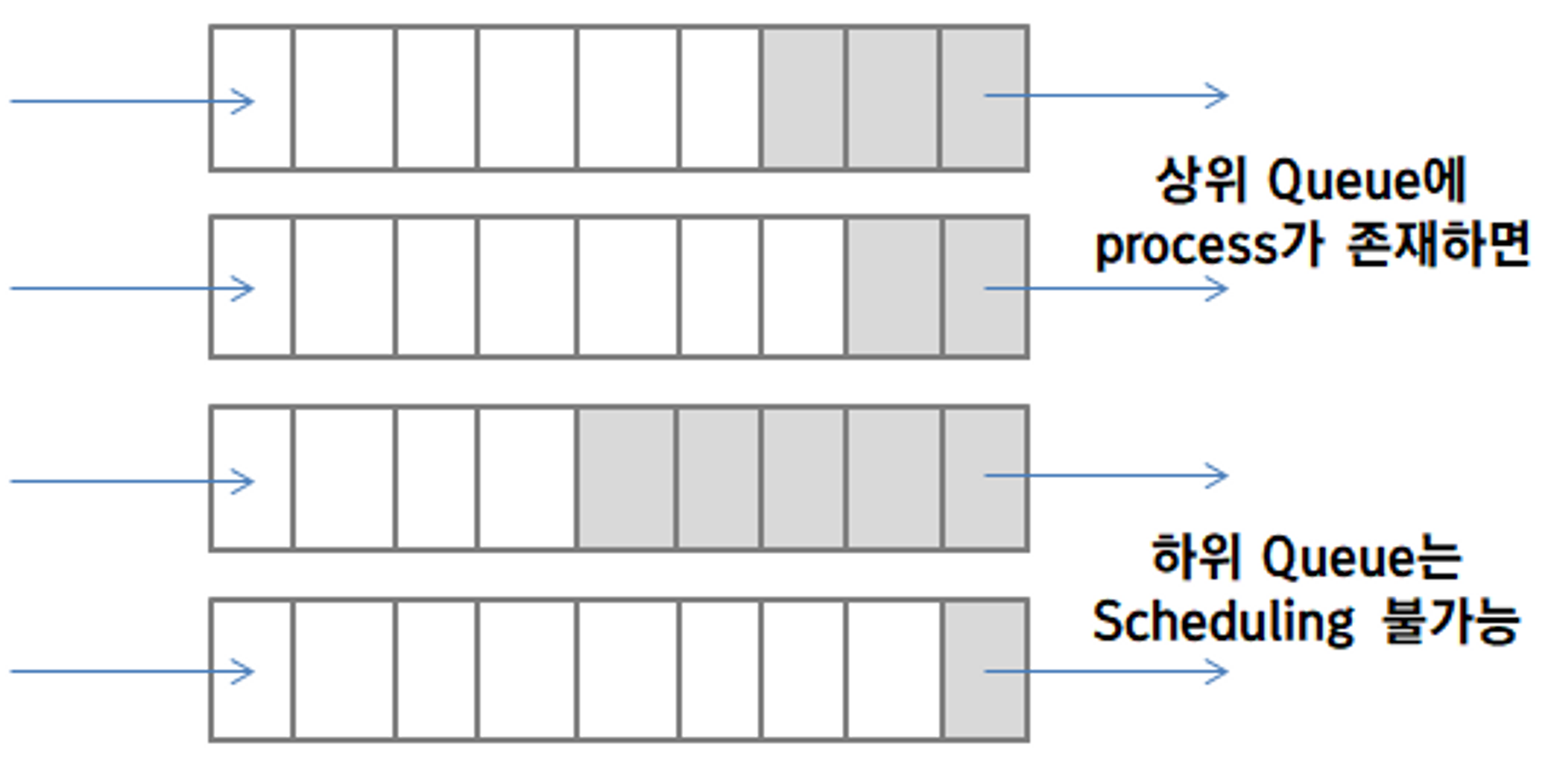
starvation 문제가 일어날 가능성이 높다. 그래서 Multilevel Feedback Queue Scheduling (MFQS / 다단계 피드백 큐 스케쥴링)을 활용.
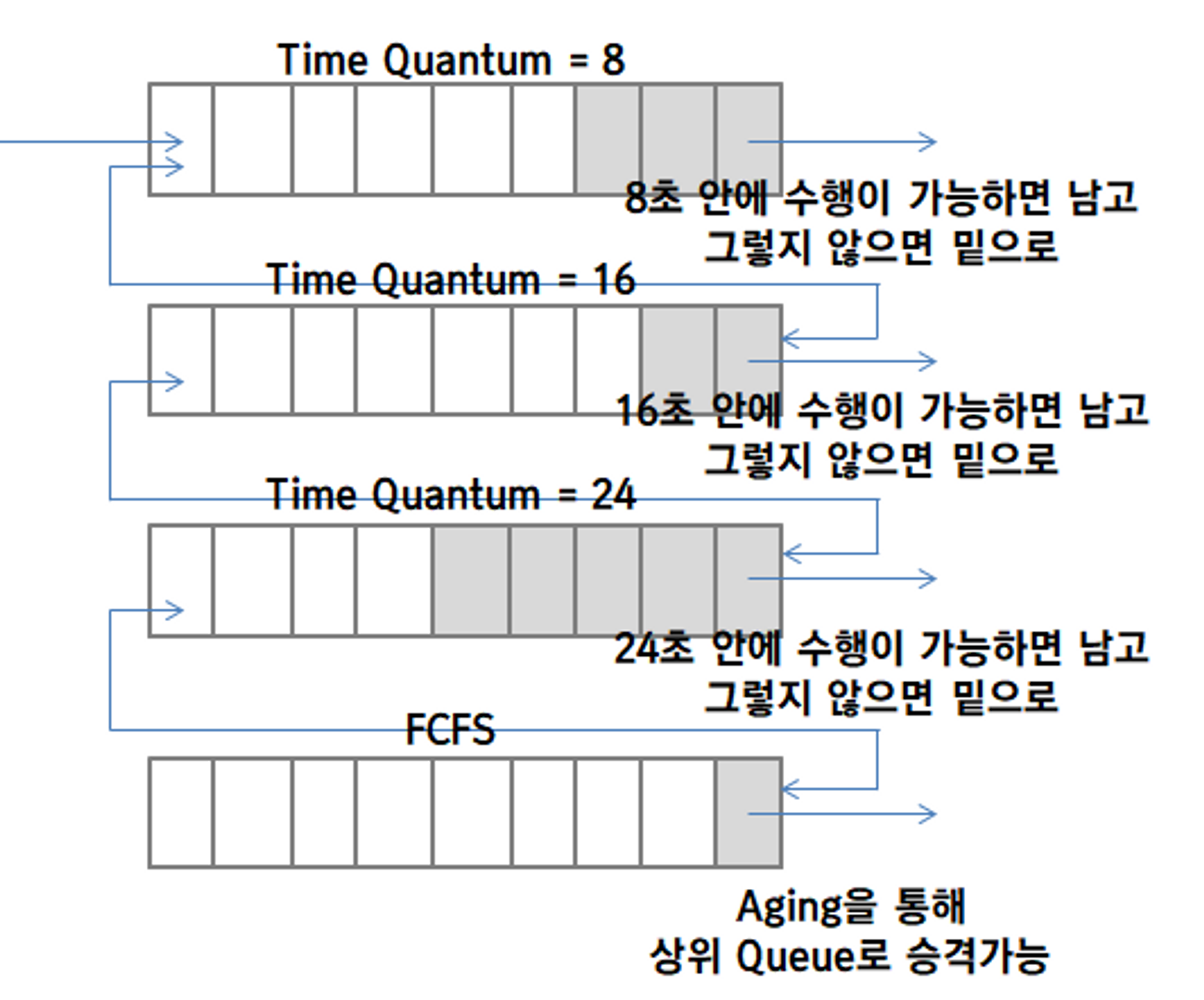
6. Multilevel Feedback Queue
Aging을 통해 queue들 사이에서의 process의 이동을 허용해서 일정 시간동안 실행이 되지 않으면 상위 레벨의 queue로 승격시켜 언젠가는 실행이 되도록 하는 구조입니다.
MFQS에서는 들어올 때는 할당된 queue가 아닌 가장 상위의 queue로 들어와서 실행 시간이 긴 process들은 아래 층으로 이동하게 됩니다. 그 외의 실행은 다단계 큐 스케쥴링과 유사합니다.
CPU가 여러 개인 경우 스케쥴링 고려사항
Homogeneous Process
- Queue에 한 줄로 세워서 각 프로세서가 알아서 꺼내가도록 할 수 있습니다.
- 반드시 특정 프로세서에서 수행되어야 하는 프로세스가 있는 경우에 문제가 복잡해집니다.
Load Sharing
- 일부 프로세서에 job이 몰리지 않도록 부하를 적절히 공유하는 메커니즘 필요
- 별개의 큐를 두는 방법 vs 공동 큐를 사용하는 방법
SMP (Symmetric Multiprocessing)
- 각 프로세서가 각자 알아서 스케쥴링 결정
Asymmetirc Multiprocessing
- 하나의 프로세서가 시스템 데이터의 접근과 고유를 책임지고 나머지 프로세서는 거기에 따름
Scheduling
Real-Time Scheduling
- 반드시 정해진 시간에 실행될 수 있도록 스케쥴링을 해주도록 하는 방법입니다.
Hard real-time systems
- 정해진 시간 안에 반드시 끝내도록 스케쥴링
Soft real-time computing
- 일반 프로세스에 비해 높은 priority를 갖도록 스케쥴링.
Thread Scheduling
Local Scheduling
- User level thread의 경우 사용자 수준의 thread library에 의해 어떤 thread를 스케줄할지 결정
- 프로세스 자체가 CPU 할당
Global Scheduling
- Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케쥴러가 어떤 thread를 스케줄할지 결정
