Thread
- 정의 : process내에서 실행되는 흐름의 단위.
- 즉, 여러 개의 thread가 있다면 여러개의 작업의 흐름을 가질 수 있는 것이죠.
- 예시 하나의 thread만 가지고 있다고 가정한다면 메세지를 주고받을 때 메세지를 보내는 작업을 수행한 뒤에 메세지를 받는 작업을 수행할 수 있고, 두 개의 thread를 이용하면 한 process 내에서 메세지를 보내는 작업과 메세지를 받기 위해 대기하는 작업을 동시에 수행할 수 있다는 것입니다.
- Lightweight process라고도 불리며, 어떤 작업을 실행할 수 있는 가장 작은 단위입니다.
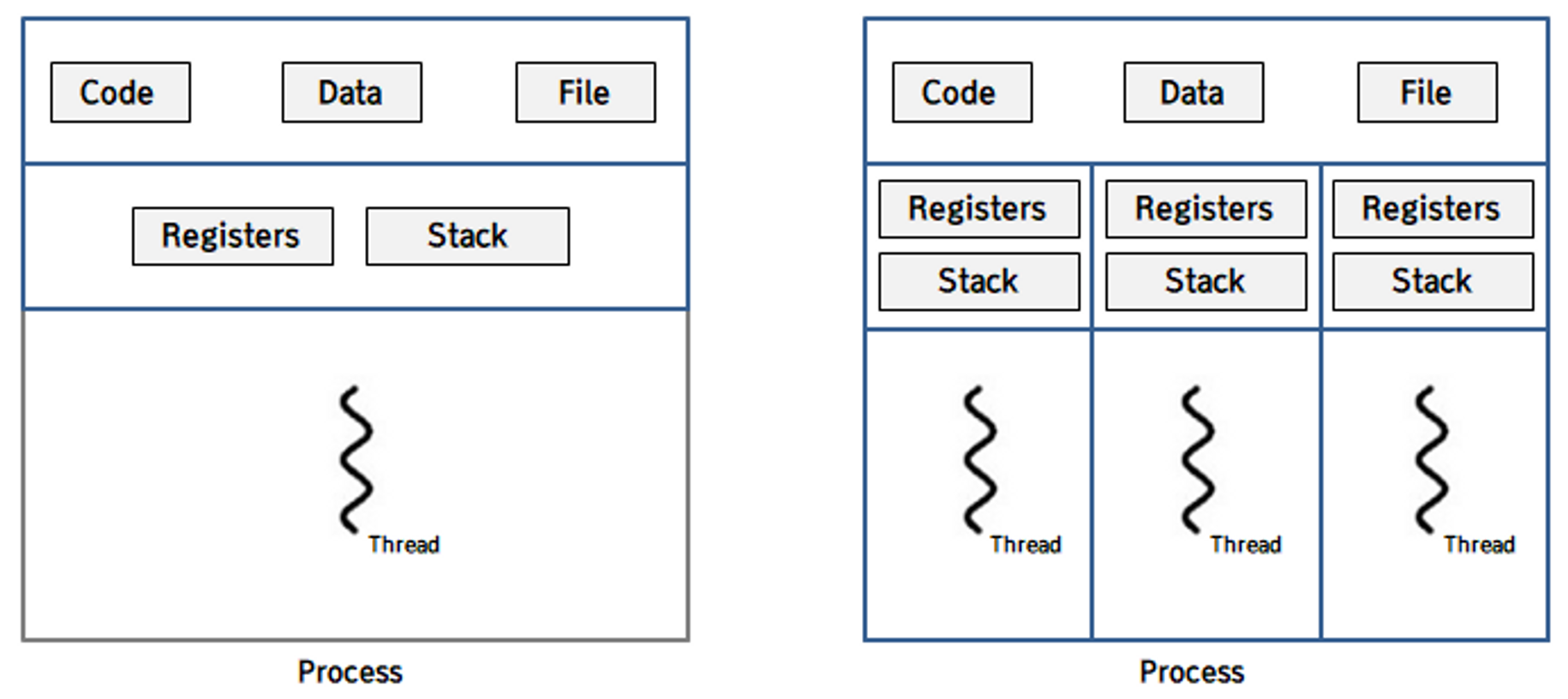
- thread id, pc, register set, 그리고 stack을 독립적으로 가집니다. 하지만 code section과 data section 등은 같은 process 내의 다른 thread들과 공유합니다. Single Thread Process 와 Multi Thread Process
Thread를 사용하는 이유
- 한 process내에서 병렬적인 작업을 수행할 수 있기 때문에 성능적으로 이득을 볼 수 있습니다.
- 한 공장 안에서 한 명이 일하는 것과 두 명, 세 명이 같이 일하는 것은 실행 속도에서 엄청난 차이가 나겠죠? 공장을 process, 직원을 thread라고 생각할 수 있다.
- thread를 새로 만드는 작업은 process를 새로 만드는 작업보다 훨씬 간단하기 때문에 생성에서 발생하는 overhead도 줄일수 있습니다.
- process를 만들려면 code, data, file, registers, stack 모두를 새로 만들어야 하는 반면, thread를 만들 때는 registers와 stack만 만들어주면 되기 때문입니다.
- 한 process 내의 thread들끼리는 소통을 위해 이런 번거로운 과정을 거칠 필요도 없습니다.
- 바로 메모리를 공유하고 있기 때문입니다. 그래서 thread들끼리 메세지를 주고받을 때 kernel의 도움을 필요로 하지 않습니다. 이것 역시 성능적으로 큰 도움이 됩니다.
정리
응답성 (Responsiveness):
- 프로그램 실행 시 어떤 작업이 오랜 시간을 필요로 하거나 또는 어떤 이유에서 block되더라도 다른 thread가 사용자에게 응답을 줄 수 있습니다.
- Thread를 하나만 사용할 때는 아무리 오래 걸리는 작업이라도 이 작업이 종료되어야 다음 작업을 통해 사용자에게 응답할 수 있습니다.
자원 공유 (Resource Sharing)
- Process 내부의 thread들 끼리는 process의 여러 resource들과 메모리를 공유합니다. Code와 data의 공유를 통해 한 프로그램이 같은 주소 공간 내에서 여러 개의 다른 작업을 하는 thread를 가질 수 있습니다.
경제성 (Economy)
- 한 process 내의 thread들 간의 context switch나 thread 생성에서 process에 비해 훨씬 적은 overhead를 가집니다. Thread를 생성하는 것은 process를 생성하는 것에 비해 30배가량 빠르며, context switch는 5배가량 빠르다고 합니다.
규모 적응성 (Scalability):
- Multiprocessor 구조에서 thread의 이점은 더욱 증가합니다. Multiprocessor 구조에서는 각각의 thread들이 다른 processor에서 병렬적으로 수행될 수 있기 때문입니다.
Thread의 구현
process는 각각의 PCB를 가지고 있어서 자신의 정보를 저장해 두고, 이와 유사하게 thread 역시 TCB (Thread Control Block)을 가집니다. 기본적인 아이디어는 원래의 PCB를 PCB와 TCB 두 파트로 나눈다는 것입니다.
- 원래 PCB가 가지고 있던 정보 중 thread들이 각각 가지는 정보들(thread ID나 thread의 상태, PC값, register 등)은 TCB에 저장
- 나머지 정보들과 자신에게 소유되는 thread들의 포인터 값만 기존의 PCB에 저장.
이렇게 만들어진 TCB는 PCB에 비해 작고 resource도 적게 사용하기 때문에 더 유용하게 사용될 수 있습니다.
Linux의 경우에는 TCB가 PCB에 비해 5배 정도 작은 크기를 가집니다.
context switch는 PCB를 활용해서 수행한다는 내용이 있지만 이렇게 TCB를 활용하는 것이 PCB를 활용하는 것보다 훨씬 쉽기 때문에 실제로는 context switch를 수행할 때 PCB가 아닌 TCB로 수행하게 됩니다.
Context switch가 수행될 때 바뀌는 TCB들이 만약 같은 process 내의 TCB들이라면 주소 공간을 아예 바꿔줄 필요가 없기 때문에 훨씬 쉽게 context switch가 가능하게 됩니다. 물론 다른 process에게 속한 thread 간에 context switch가 일어나는 경우라면 기존에 공부했던 context switch처럼 모든 정보를 교체해 주어야 합니다.
Multicore Programming
Multicore 라는 것은 CPU 칩에 여러 개의 core가 존재하는 것을 뜻합니다. 비슷한 용어로 multiprocessor가 있는데 이는 시스템 안에 여러 개의 CPU가 존재하는 것을 뜻해서 서로 뜻이 조금 다릅니다.
Multicore를 사용하면 프로그램을 더 효율적으로 병렬 수행할 수 있습니다. Core 하나가 하나의 thread의 작업을 수행할 수 있기 때문입니다. 이러한 multicore에 관한 내용에서는 Concurrency(동시성, 병행 실행)과 Parallelism(병렬성, 병렬 시행)의 차이를 잘 숙지하고 있어야 합니다.
Concurrency
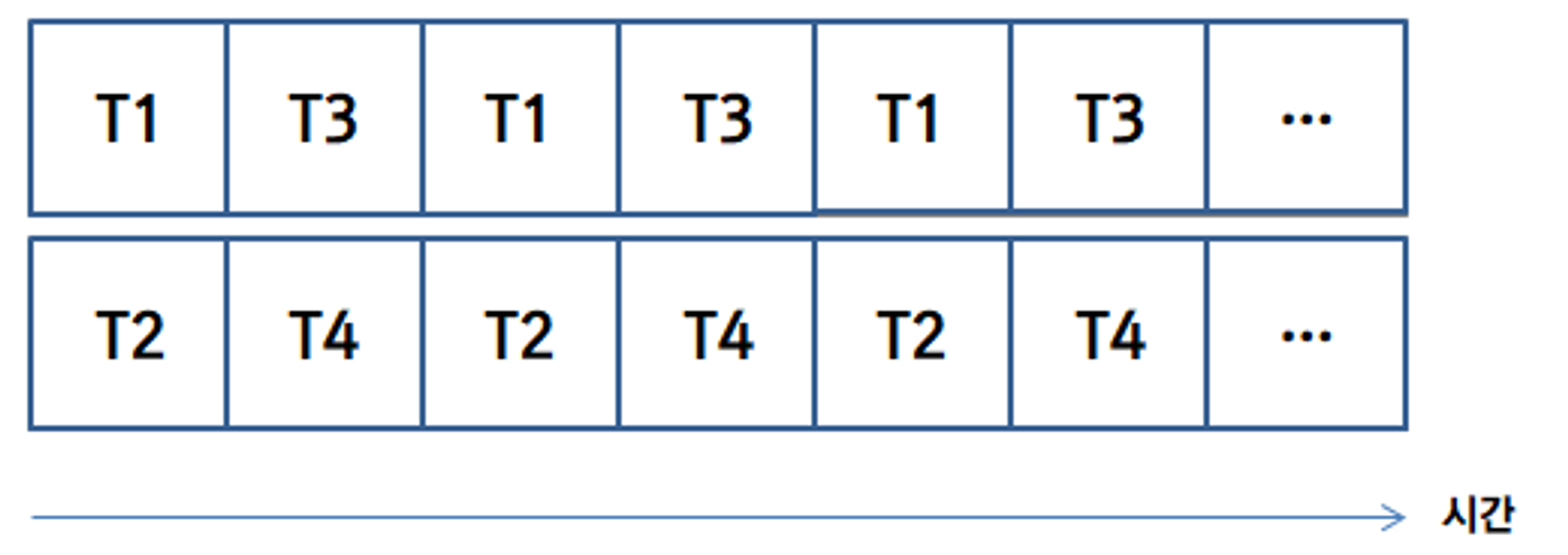
여러 개의 작업을 쪼개어 순차적으로 진행하여 마치 함께 실행되고 있는 것 같은 효과를 나타내는 것을 뜻합니다. 아래의 그림과 같이 하나의 core에서 여러 개의 작업을 쪼개어 차례로 실행하여 사용자의 입장에서는 세 개의 작업이 함께 실행되고 있는 것처럼 느끼게 됩니다.

Parallelism
말 그대로 병렬적으로 실행된다는 뜻입니다. 두 개 이상의 core를 사용하여 실제로 동시에 다수의 작업을 처리할 수 있습니다.
Parallelism에는 두 가지 타입이 존재합니다. data parallelism과 task parallelism입니다.
Data Parallelism
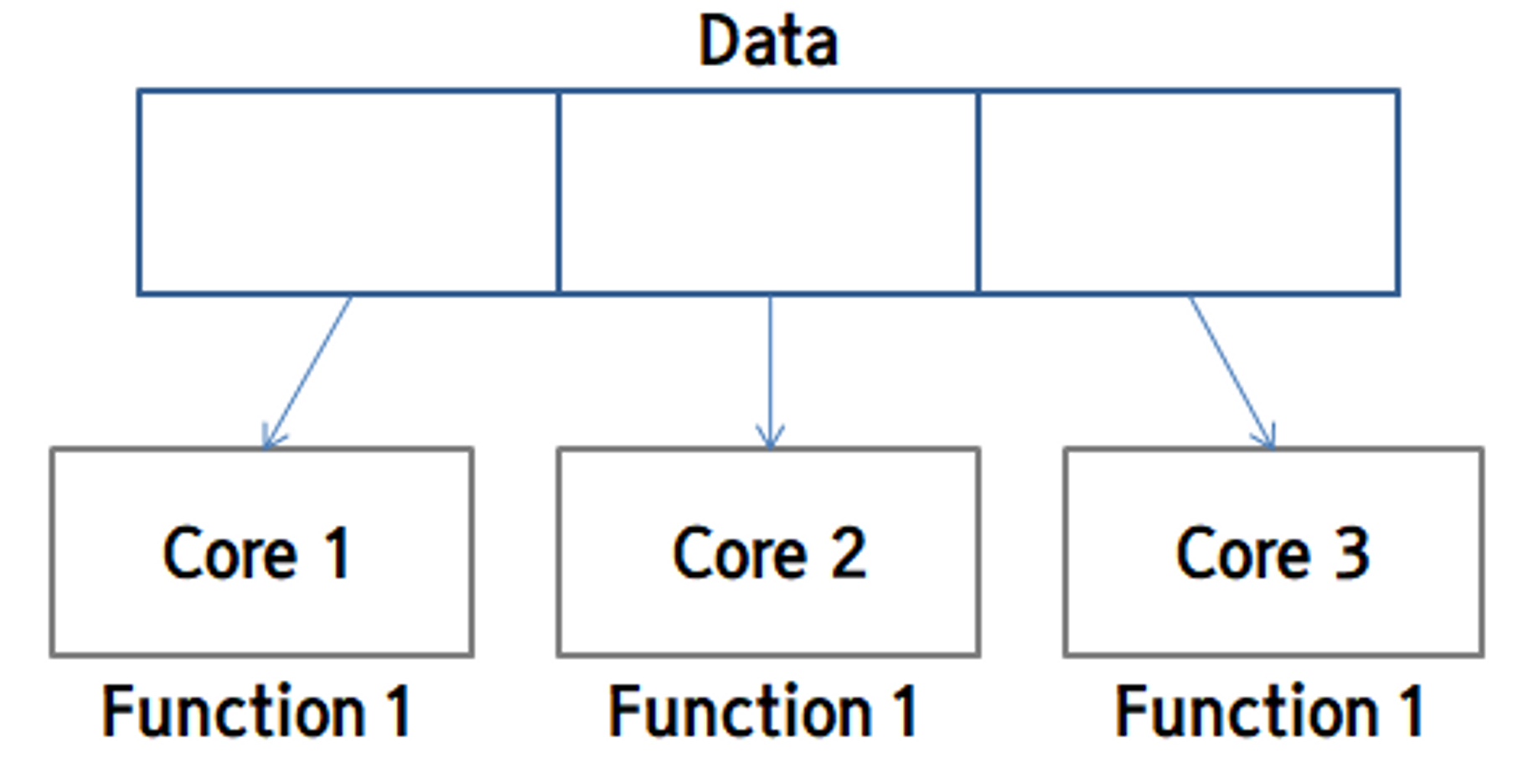
Data Parallelism은 데이터를 분할하여 같은 함수에 서로 다른 데이터들을 넣음으로써 병렬 수행을 가능하게 합니다.
예를 들면 100개의 정수가 들어있는 배열에서 0의 개수를 카운트하는 프로그램이라면 1번 core에서는 0부터 33까지의 배열에서 0의 개수를 확인하고, 2번 core에서는 34번부터 66번까지를 확인하고 3번 core에서 나머지를 확인하는 느낌입니다.
Task Parallelism
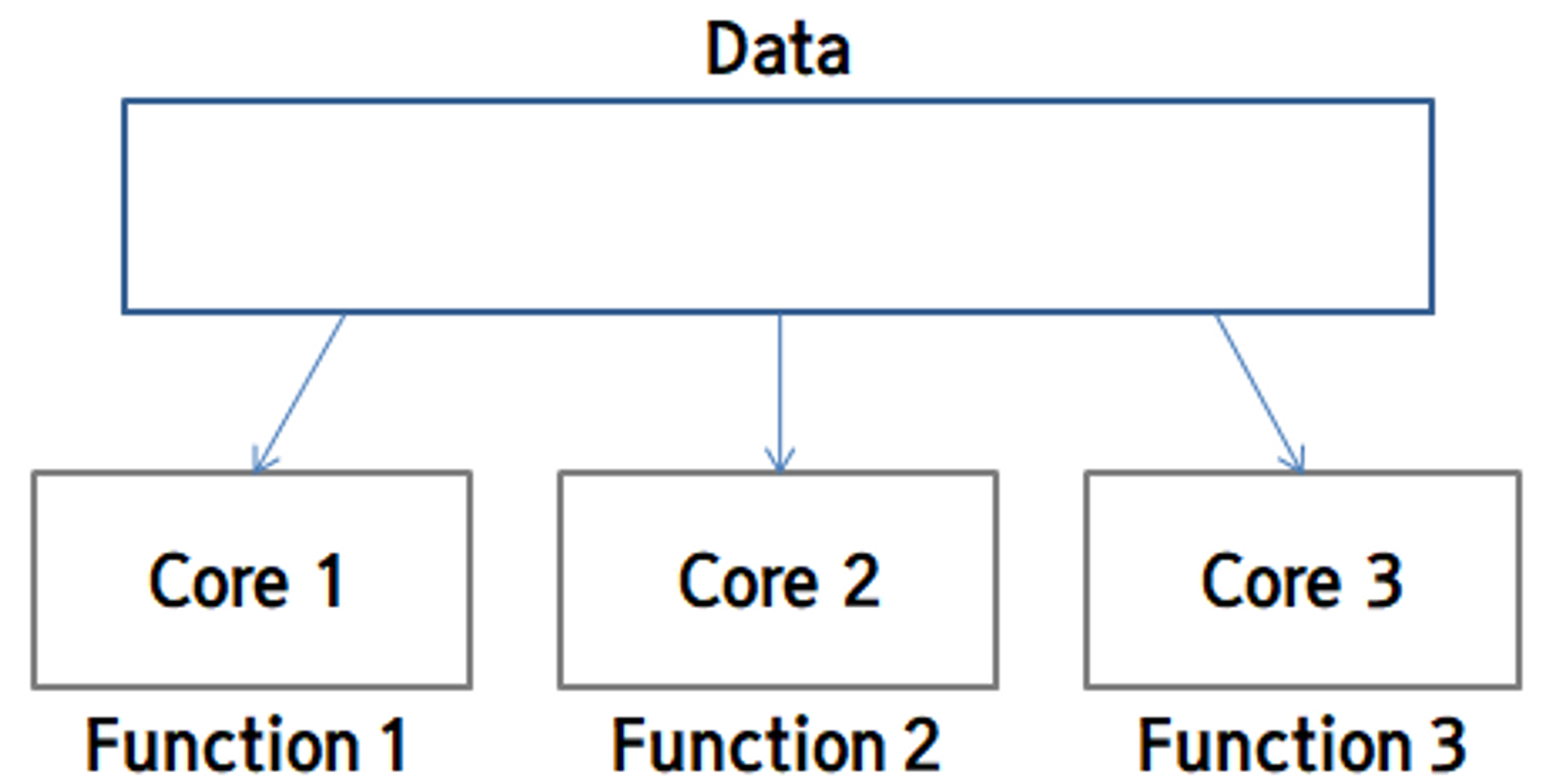
Task Parallelism은 데이터는 모두 같은 데이터를 사용하지만 core마다 서로 다른 함수를 실행시켜 병렬 수행을 가능하게 하는 방법입니다.
예를 들면 1번 core는 모든 데이터의 합을 구하고 2번 core는 모든 데이터의 곱을 구하고 3번 core는 모든 데이터의 평균을 구하는 형태가 있겠습니다.
Multicore Programming의 과제
이러한 multicore를 사용하기 위해서는 원래의 프로그램을 여러 thread를 사용할 수 있도록 수정을 해줘야하고, 이러한 multi-core 시스템에 부합하는 스케쥴링 알고리즘도 작성해야 합니다. Multicore programming에는 일반적으로 다섯 가지의 도전 과제가 존재합니다.
- Identifying tasks (테스크 인식)
- 어떤 부분을 독립적으로, 그리고 병렬적으로 실행할 지를 결정해야 한다.
- Balance (균형)
- 모든 작업이 균등하게 실행되도록 잘 배정 되었는지를 확인 해야 한다.
- Data Splitting (데이터 분리)
- 작업 뿐 아니라 데이터도 균형 있게 잘 배분 되었는지를 확인해야 한다.
- Data Dependancy (데이터 종속성)
- 한 작업을 마쳐야 시작할 수 있는 작업이 있는지(종속적인지)를 확인해야 한다.
- Testinig and debugging (시험 및 디버깅)
- 병렬적으로 실행될 경우 다양한 실행 경로가 존재할 수 있기 때문에, 테스트와 디버깅이 굉장히 어려울 수 있다.
User thread vs. Kernel thread
이전 내용에선 thread를 그냥 일반적인 의미에서의 thread로 간주했지만 사실 thread에도 두 가지 종류가 존재합니다.
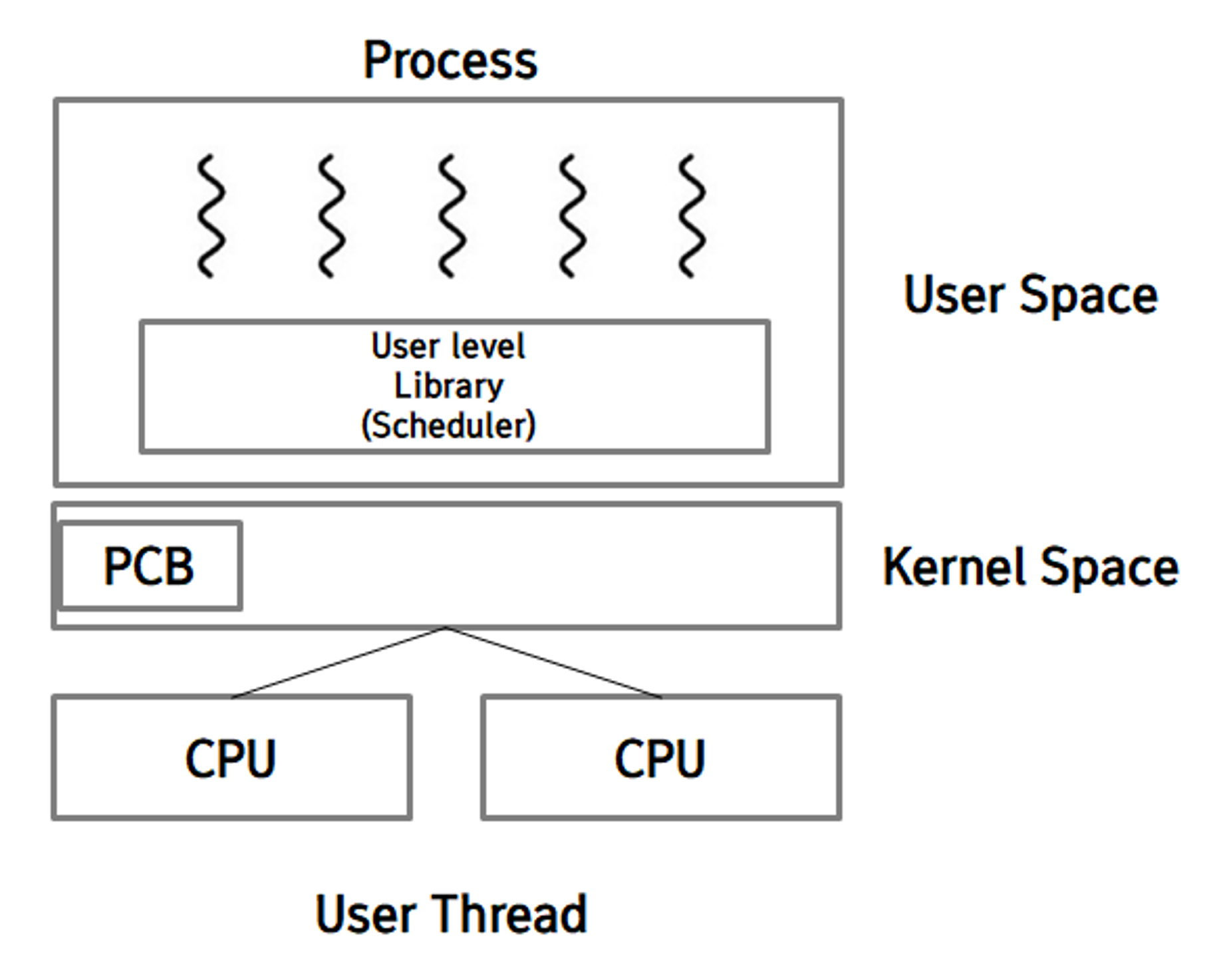
User thread
kernel과 관계없이 user library에 의해 지원이 됩니다. 즉 thread의 생성과 소멸뿐만 아니라 실행을 위한 스케쥴링, context의 저장 등이 모두 사용자 레벨에서 이루어집니다. 당연히 모든 code와 data들은 user level에 존재하고, 운영체제의 kernel은 몇 개의 user thread가 존재하는지도 알지 못합니다.
User thread는 kernel과는 아예 무관하게 동작하기 때문에 kernel thread에 비해 빠르다는 장점이 있습니다.
- 어떤 작업이든 kernel이 개입하는 순간 system call이 필수적으로 필요하기 때문에 성능적으로 큰 overhead가 발생하게 되고, 이는 속도 저하로 이어집니다.
그리고 kernel을 거치지 않기 때문에 thread들의 switching이나 스케쥴링도 비교적 간편하게 이루어질 수 있습니다.
단점 : kernel이 user thread들의 존재조차 모르고 있기 때문에 kernel과의 소통이 힘들다는 단점이 있습니다. 즉 kernel이 스케쥴링과 같은 상황에서 user 입장에서는 좋지 않은 결정을 내릴 수도 있다는 것이죠.
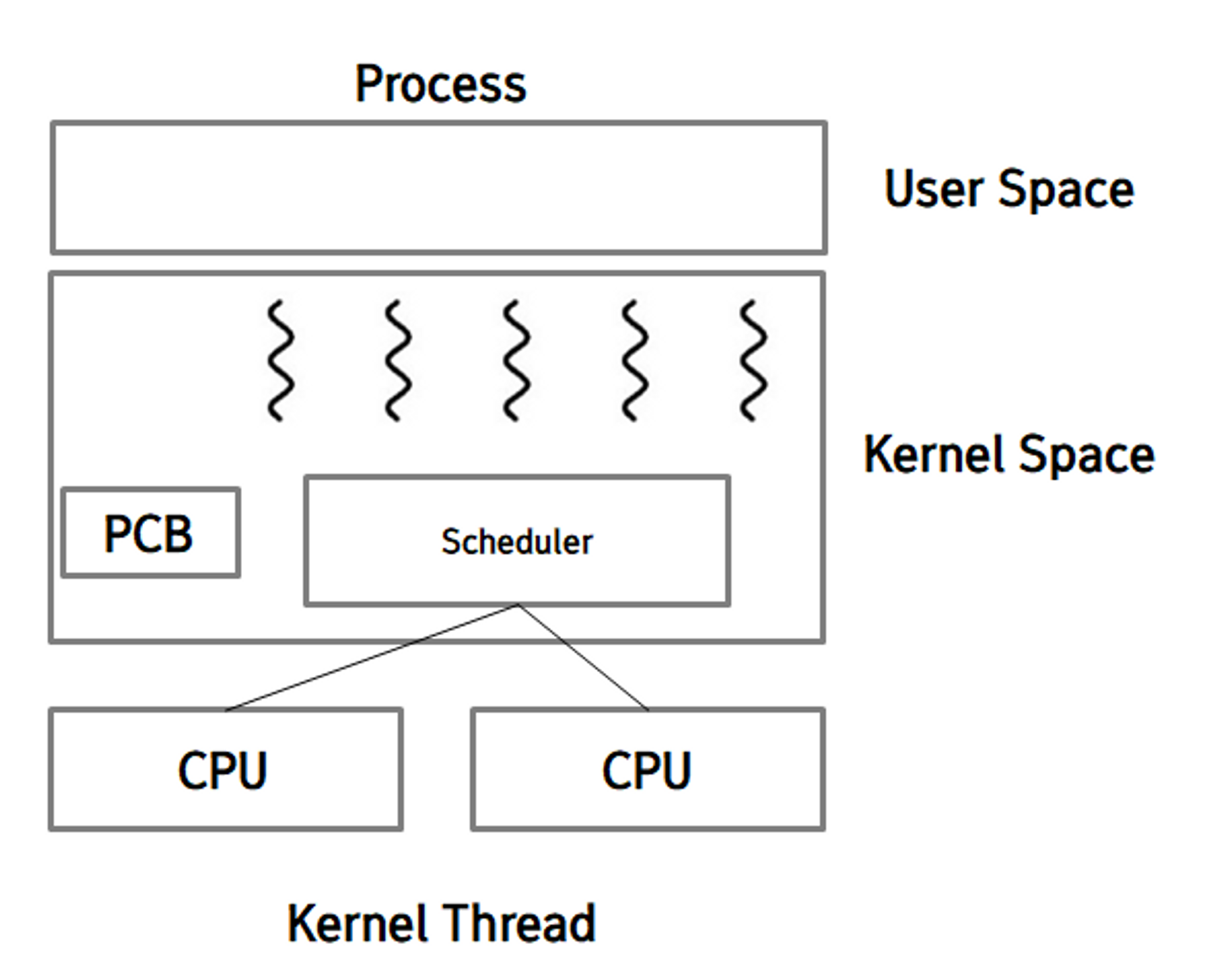
Kernel thread
운영체제에 의해 직접 지원되고 관리됩니다. 모든 code와 data들이 kernel 영역에 존재하며, thread를 만들거나 관리할 때 system call을 이용해야 합니다.
장점 : kernel이 thread에 대한 모든 것을 알고 있기 때문에 스케쥴링과 같은 어떤 결정을 내려야 하는 상황에서 user thread보다 훨씬 유용합니다.
- 즉 CPU가 스케쥴링을 할 때 thread가 많은 process에 우선순위를 주는 등의 고려가 가능한 것이죠.
단점 : 모든 thread가 kernel에 의해 관리되기 때문에 상당한 overhead가 발생하고, kernel의 복잡도가 굉장히 증가합니다. 당연하게도, user thread들에 비해 연산 속도가 느리다는 점도 단점입니다.
2. 다중 Thread 모델 (Multithreading Models)
user thread와 kernel thread 간의 관계에 따라서 다중 thread 모델의 종류가 결정됩니다.
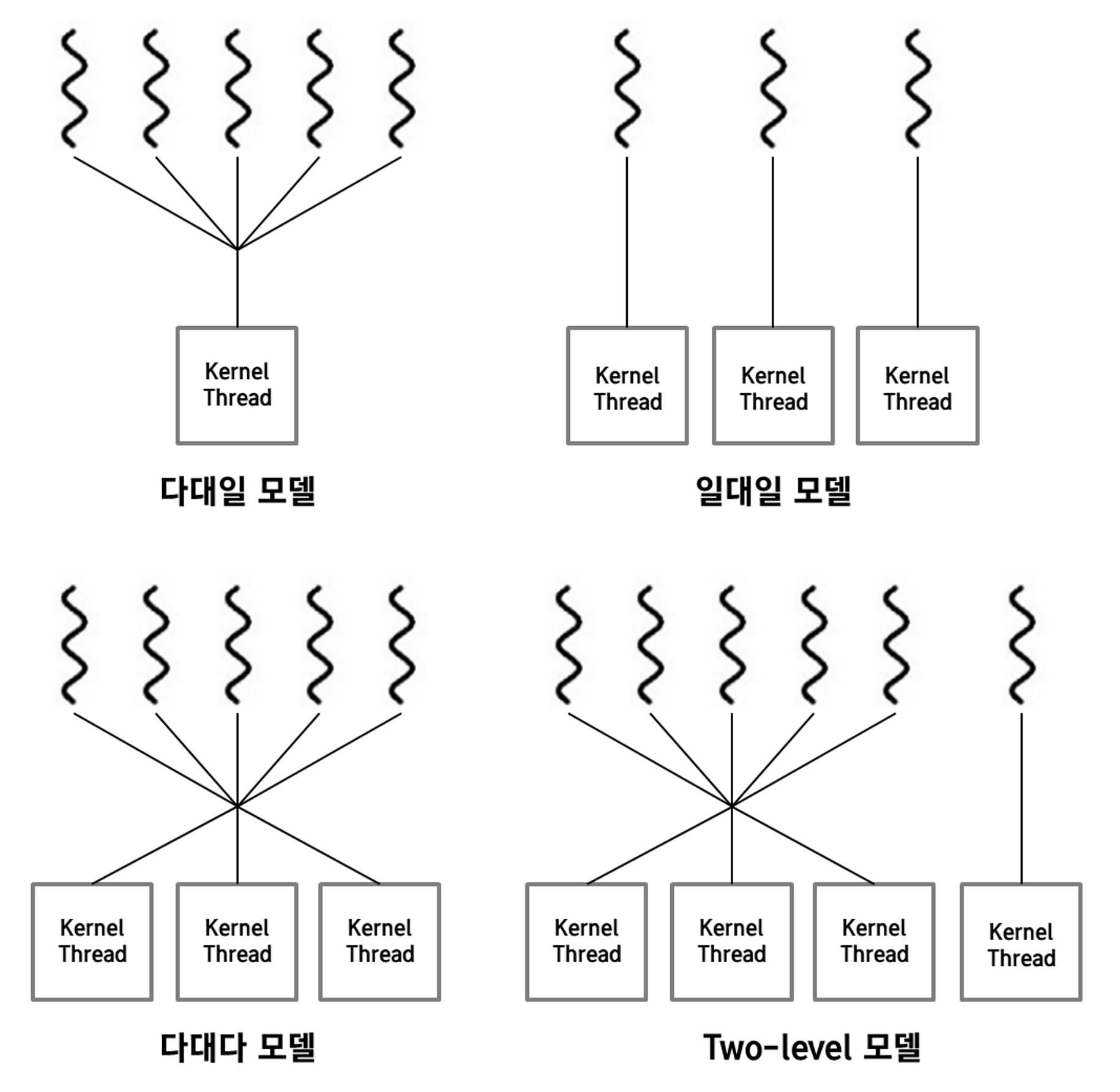
1. 다대일 모델 (Many-to-one Model) (상용X)
- 몇 개의 user thread가 한 개의 kernel thread와 연결되어 있는 형태
- 장점 : user thread가 가지는 장점과 거의 유사 다중 thread를 사용하지만, kernel 입장에서는 user level에 thread가 1개가 있는지 20개가 있는지 알지 못하기 때문에 모든 스케쥴링을 비롯한 관리들이 user level에서 이루어집니다. 당연히 속도가 빠르고 thread를 생성하고 관리하기 쉽습니다.
- 단점
- 한 개의 thread라도 system call을 수행하다가 block이 되면 모든 thread들이 block 되게 됩니다(kernel과 연결되어 있는 길이 하나뿐이기 때문에).
- 병렬적인 작업이 불가능 여러 user thread들 중 하나의 thread만이 kernel과 작업을 할 수 있기 때문에 multicore 시스템에서 한 번에 하나의 thread만이 작업에 참여할 수 있어 합니다. 이러한 이유 때문에 현재는 거의 사용하지 않는 방법입니다.
2. 일대일 모델 (One-to-one Model) (Window, Linux)
- 각각의 user thread들이 하나의 kernel thread들에 연결되어 있는 형태
- 다대일 모델과는 정반대의 특성들을 가진다
- 동시성 (Concurrency)을 보장
- user thread 하나 당 kernel thread가 하나씩 연결되어 있기 때문에 thread 하나가 block 되더라도 다른 thread들은 정상적으로 작동이 가능
- 여러 개의 multicore 시스템에서 여러 개의 thread들이 병렬적으로 실행이 가능
- 단점
- 우선 thread 생성이 힘들고, 관리도 어렵기 때문에 thread가 많아지게 되면 시스템의 성능에 큰 부담
- 시스템들은 thread의 최대 개수를 정해두어 관리하는 방법으로 overhead를 방지하곤 합니다
- 우선 thread 생성이 힘들고, 관리도 어렵기 때문에 thread가 많아지게 되면 시스템의 성능에 큰 부담
3. 다대다 모델 (Many-to-many Model)
- 여러 개의 user thread들을 그와 같은 수, 또는 조금 더 적은 수의 kernel thread와 연결하는 형태
- Kernel thread의 수는 시스템이나 하드웨어에 따라 결정되며, user thread들은 user level의 스케쥴러에 의해 kernel thread들에게 복합적으로 연결되게 됩니다.
- Kernel thread가 여러 개 존재하기 때문에 multicore 시스템에서는 당연히 병렬적인 수행이 가능합니다.
- 다대다 모델은 다대일 모델과 일대일 모델의 장점을 결합한 형태이기 때문에 많은 수의 thread들이 좀 더 손쉽게 지원됩니다.
- 단점 : 구현이 어렵습니다
Two-level 모델
- 다대다 모델에 일대일 모델을 결합한 형태
- 다대다 모델을 기본으로 하지만, 일대일 모델처럼 하나의 user thread가 하나의 kernel thread에만 연결되는 것을 허용하는 모델입니다.
Thread Library
Thread 라이브러리는 프로그래머에게 thread를 생성하고 관리하기 위한 API를 제공합니다.
Thread 라이브러리를 제공하는 방법
- kernel의 지원 없이 완전히 user level에서만 라이브러리를 제공
라이브러리의 함수를 호출하면 system call이 호출되는 것이 아닌, user level에 구현되어 있는 함수를 호출하게 됩니다.
2, kernel level의 라이브러리를 제공
라이브러리를 위한 모든 code와 자료구조는 kernel 내부에 존재하여 라이브러리를 호출하는 것은 system call이 호출되는 것과 같은 결과를 만들어 냅니다.
상용 API
- POSIX Pthread
- user level과 kernel level 모두에서 (주로 kernel level에서) 제공되며, Linux에서 보통 Pthread를 많이 사용
- Windows thread API
- kernel level의 API를 제공하며, JAVA thread는 조금 더 높은 레벨의 라이브러리로, JVM을 제공하는 모든 시스템에서 사용할 수 있기 때문에 Windows와 Linux를 포함한 대부분의 시스템에서 사용이 가능합니다.
- JAVA thread API
암묵적 Threading (Implicit Threading)
등장 배경
Thread의 사용이 점점 늘어나고, multicore system도 발전을 거듭하면서, 수백 개, 수천 개의 thread가 활용되는 응용 프로그램들이 나타나게 되자, thread를 일일이 생성시키고 관리하는 것이 어려워지고 이에 따라 프로그램의 정확도가 떨어지는 결과를 보이는 일들이 생기게 되었습니다.
Implicit Threading
프로그래머가 직접 thread들을 생성하고 관리하는 것이 아닌, 컴파일러나 런타임 라이브러리들이 대신 thread들의 생성과 관리를 수행하는 형태를 뜻합니다. 대표적인 유형 2가지 유형으로 Thread Pool, OpenMP가 있습니다
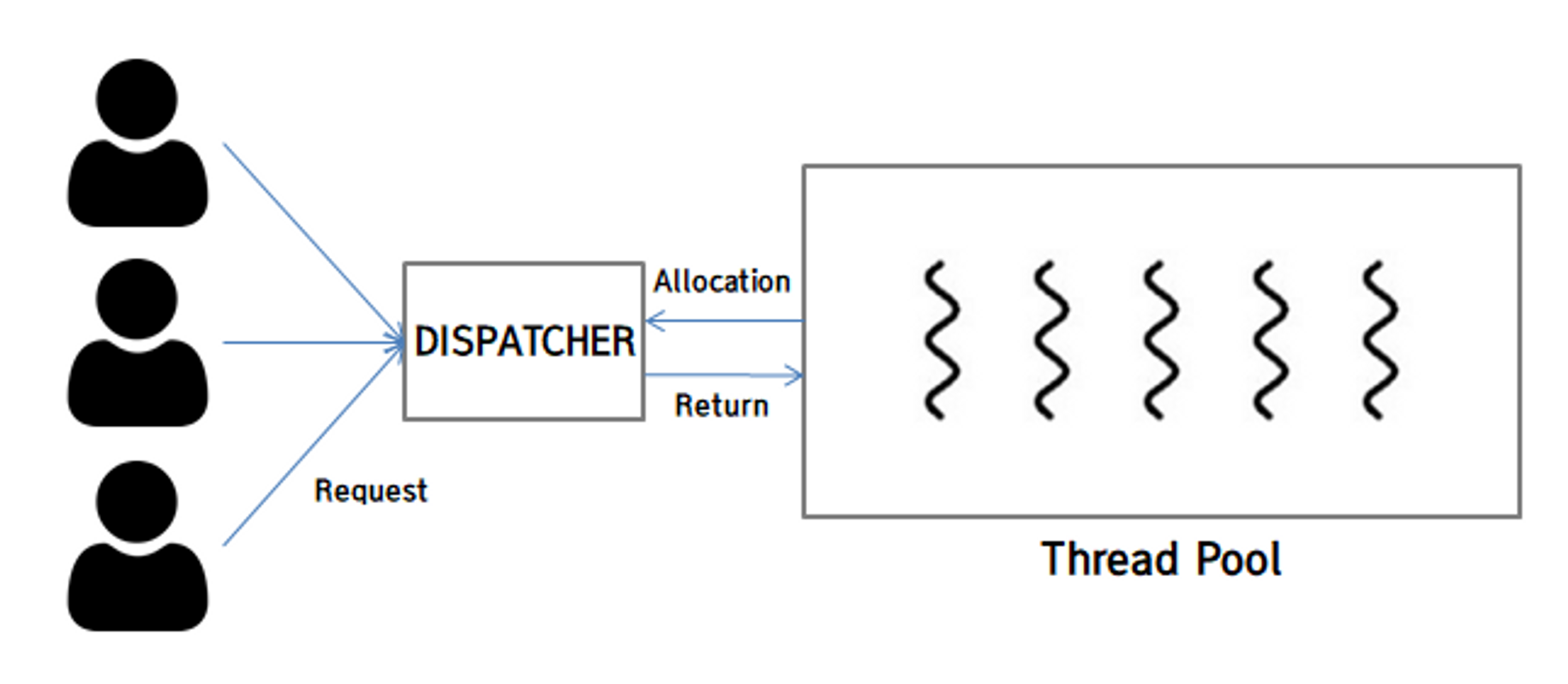
Thread Pool
- 배경 현재 까지는 thread가 필요하면 thread를 생성하고, 그리고 사용이 완료되면 thread를 소멸시키는 방법을 사용하였습니다. 하지만, thread를 생성하고 소멸시키는 것 자체가 큰 overhead가 될 수 있고, thread의 생성이 무제한적이기 때문에 너무 많은 thread가 생성되고 제대로 관리가 되고 있지 않을 시에는 시스템의 resource들을 고갈시키는 원인이 될 수 있습니다. 그래서 Thread Pool이라는 개념이 등장하게 되었습니다
- 시작할 때 특정 개수의 thread들을 thread pool에 미리 만들어두고 thread가 필요한 일이 생기면 사용 가능한 thread들을 할당시켜주는 형태
- 사용이 완료되면 thread를 소멸시키지 않고 다시 thread pool에 반납시켜 다음 요청을 기다리는 시스템을 가집니다.
- 필요할 때 마다 thread를 생성할 필요가 없고 반납된 thread를 재사용하기 때문에 생성과 소멸로 인해 발생하는 overhead를 줄일 수 있는 방법입니다.
OpenMP
- 공유 메모리 영역에서 병렬 프로그래밍을 가능하게 해주는 API와 컴파일러 디렉티브의 집합
- 쉽게 말하자면 프로그램의 code 중에 병렬적으로 실행될 수 있는 영역에
#pragma omp parallel이라는 구문을 삽입하면 시스템의 코어 개수에 맞게 thread를 생성하며#pragma omp for구문을 통해 해당 for문 안의 부분을 병렬적으로 실행하게 된다.#include <omp.h>의 선언을 통해 C와 C++에서 사용이 가능합니다.
- 쉽게 말하자면 프로그램의 code 중에 병렬적으로 실행될 수 있는 영역에
Thread와 관련된 이슈들
1. fork(), exec()
fork() system call이 호출되어 새로운 process가 생성되면, 새로운 process는 부모 process의 모든 thread를 복제해야 하는가, 아니면 하나의 thread만 복제해야 하는가?
- 상황에 맞게 사용해야 합니다.
- 예를 들어 fork() system call이 호출된 직후 exec() system call을 사용한다면 바로 다른 code들로 process가 대체되기 때문에 thread들을 모두 복제할 필요가 없어집니다.
2. Signal Handling
Unix나 Linux에서 사용하는 signal에 관한 이슈. signal이 발생했을 때 어떤 thread에 signal을 전해주어야 하는가
- signal이 발생한 thread에 전달해주어야 하는지
- 모든 thread들에 전달해 주어야 하는지
- process 내의 특정 thread에게 전해주어야 하는지
- 혹은 발생하는 signal을 모두 받는 전담 thread를 만들어서 signal을 받게 할지 등
3. Thread Cancellation
Thread가 정상적으로 종료되기 이전에 thread가 취소된다면 어떻게 해야하는가
- Asynchronous cancellation (비동기식 취소)
- 비동기식 취소는 즉시 한 thread가 target thread를 종료시키는 방법
- Deferred cancellation (지연 취소)
- 지연 취소는 target thread가 과연 지금 종료되어도 다른 문제가 발생하지 않는지 확인하고 종료시키는 방법
- 기본 값은 지연 취소로 되어있습니다.
