Interface
파일과 디렉터리 (File & Directory)
컴퓨터는 정보를 어떤 저장 매체에 저장할 수 있습니다.
파일
- 정보를 담는 논리적인 단위.
-
사용자의 관점 : 파일은 이름이 붙여져 있고 시스템이 재부팅되어도 사라지지 않는 데이터들의 집합
-
운영체제의 관점 : 데이터를 저장하고 있는 디스크 블록들의 집합체
어떠한 자료이든, 자료가 파일 안에 존재해야만 저장 장치에 기록될 수 있습니다. 그리고 파일 시스템이란 컴퓨터에서 파일이나 자료를 쉽게 발견하고 접근할 수 있도록 보관 및 조직하는 체제를 말합니다.
-
- 이름, id, 타입, 위치, 크기, 접근 권한 정보, 시간, 날짜 등을 속성으로 가집니다.
- 운영체제는 이 파일을 관리하기 위하여 생성(create), 쓰기(write), 읽기(read), 위치 재설정(reposition), 삭제(delete) 등의 시스템 콜을 제공합니다.
디렉터리
- 폴더와 같은 의미로써 파일 시스템 내에서 파일들과 다른 디렉터리들을 포함시키는 구조물을 말합니다.
- 일반적으로 컴퓨터는 수만 개, 수억 개의 파일을 가지기 때문에, 이를 체계적으로 구성하기 위해 디렉터리가 사용됩니다.
- 디렉터리에서는 파일 찾기, 파일 만들기, 파일 삭제하기, 디렉터리 나열하기, 파일 이름 변경하기, 파일 시스템 순회하기(traverse)라는 연산들을 제공합니다.
디렉토리 구조
1. 1단계 디렉터리 (Single-level Directory)
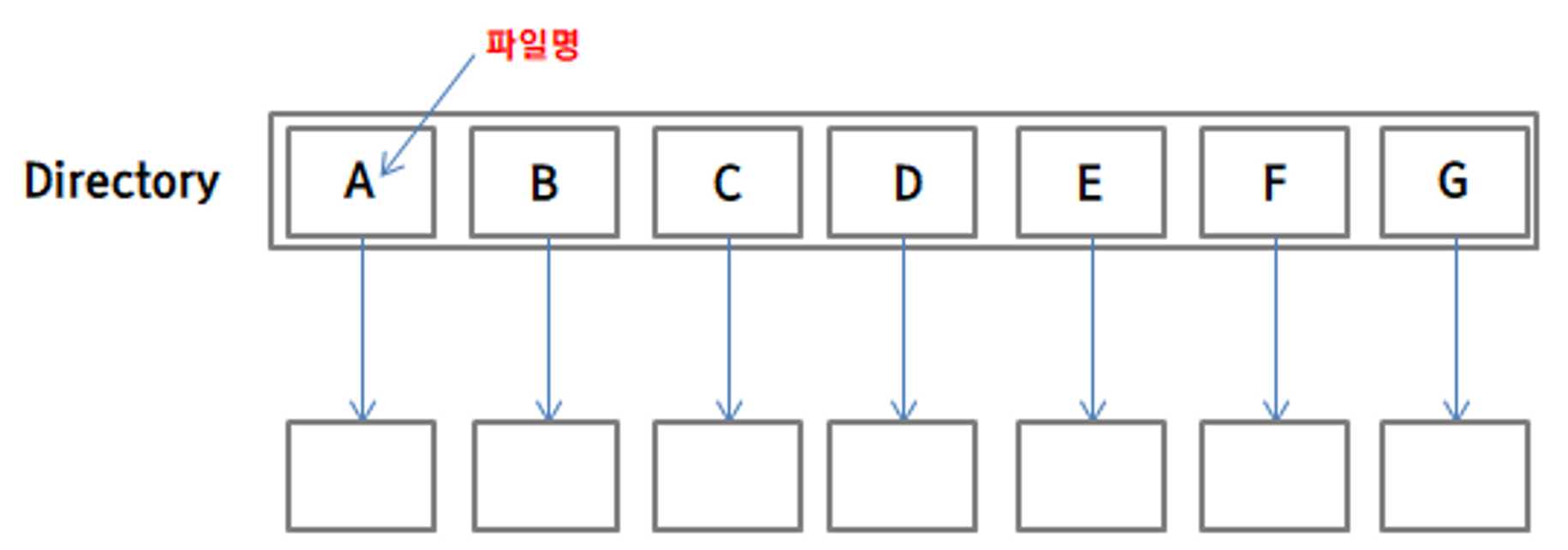
1단계 디렉터리는 가장 간단한 형태의 디렉터리로써, 컴퓨터 내의 모든 파일들이 하나의 디렉터리에 속해 있는 형태를 말합니다.
유지나 구현이 쉽다는 장점이야 있겠으나, 이러한 시스템에서는 사용자가 여러 명이더라도 모든 파일이 고유한 이름을 가져야 하고, 사용자가 한 명이더라도 파일을 사용하기 위해서는 모든 파일의 이름을 기억해야 한다는 단점이 있습니다.
2. 2단계 디렉터리 (Two-level Directory)
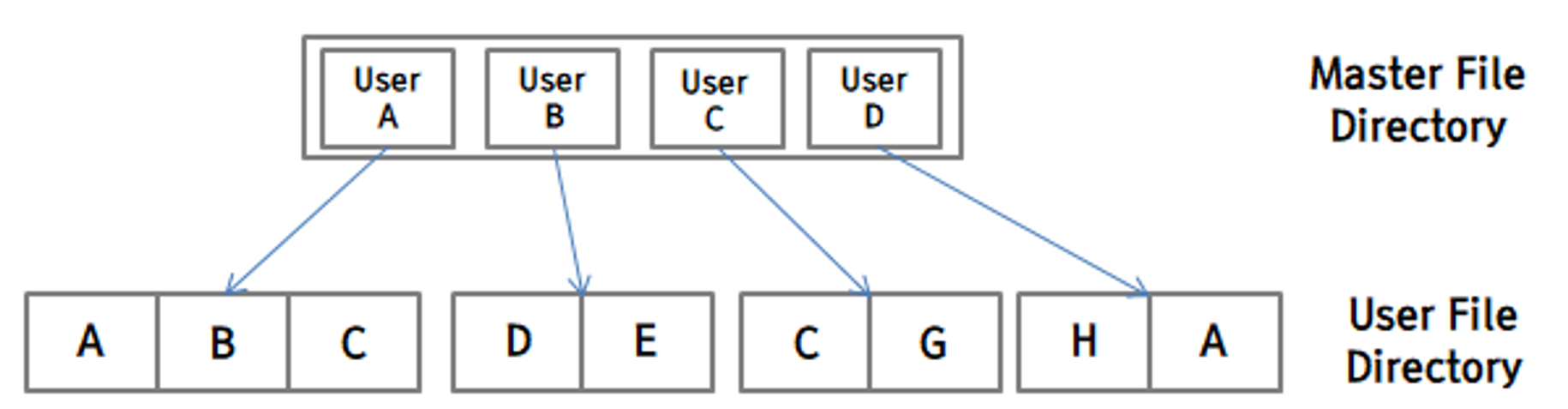
각 사용자들은 자신만의 사용자 파일 디렉터리를 가집니다.
사용자가 시스템에 접속하면 마스터 파일 디렉터리를 탐색하여 자신의 사용자 파일 디렉터리를 찾습니다. 그리고 사용자가 특정한 파일에 대한 검색을 실행하면, 자신의 사용자 파일 디렉터리에서만 검색하게 됩니다. 그렇기 때문에 파일의 이름이 다른 사용자 파일 디렉터리의 파일의 이름과는 같아도 상관이 없습니다.
이 구조에서는 한 사용자가 다른 사용자의 디렉터리에 접근할 수 없기 때문에 파일을 공유해서 사용하기 어렵다는 단점이 있습니다. 물론 서로의 사용자 파일 디렉터리에 접근을 허용한다면, 사용자 명과 파일 이름을 동시에 사용하여 파일을 공유할 수 있습니다.
3. 트리 구조 디렉터리 (Tree-Structured Directories)
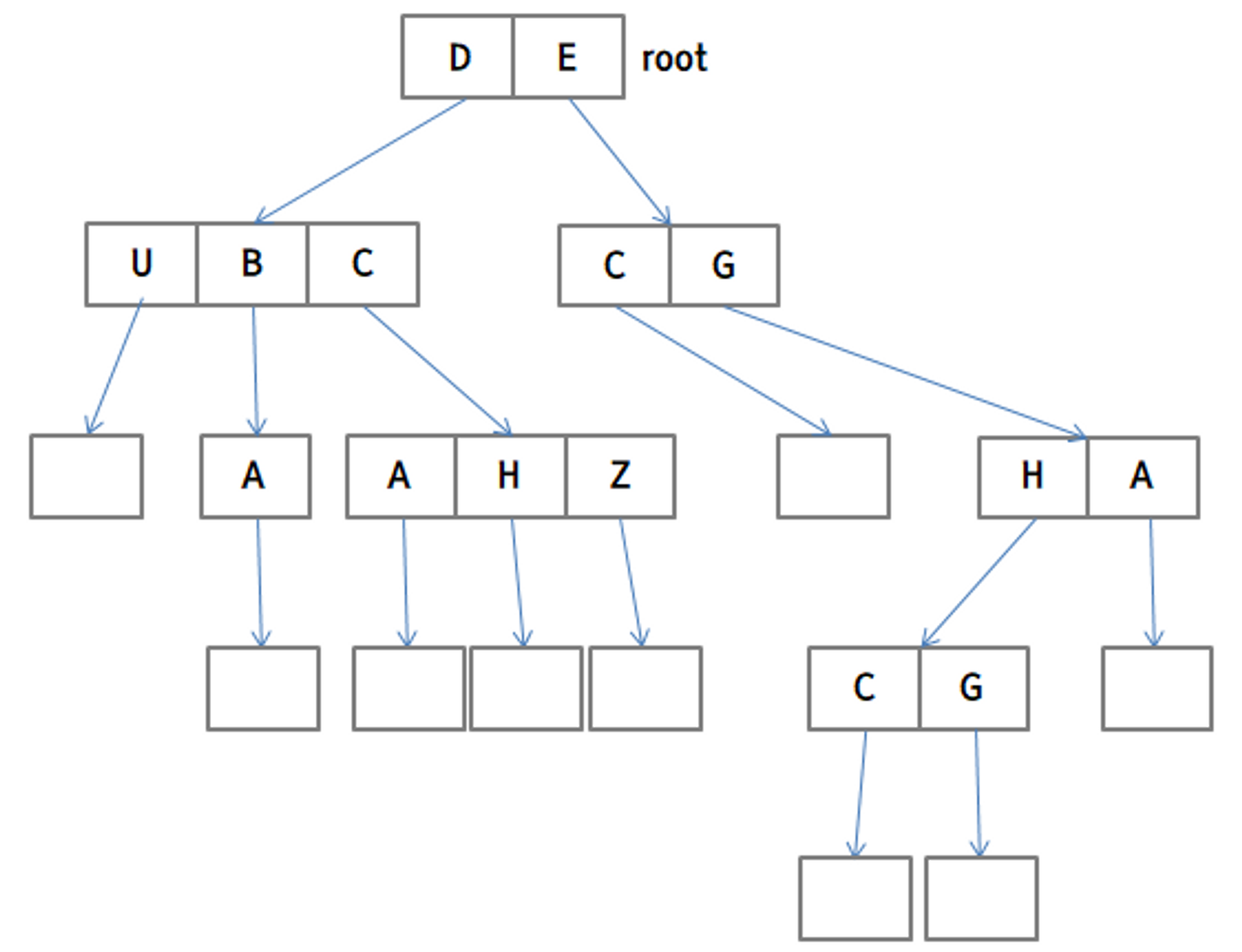
가장 흔한 형태의 디렉터리로써, 트리는 root 디렉터리를 가지고 모든 파일들은 자신 만의 경로명(path name)을 가집니다.
경로명에는 절대 경로명(Absolute path name)과 상대 경로명(Relative path name)이 존재하는데, 절대 경로명은 root로부터 해당 파일까지의 경로를 뜻하고, 상대 경로명은 현재 디렉터리에서 해당 파일까지의 경로를 뜻합니다.
디렉터리들은 자신의 밑에 다른 디렉터리나 파일을 가질 수 있고, 여기서 디렉터리는 파일들을 저장하는 파일로써의 역할을 합니다. 즉, 디렉터리는 단순히 다른 그 하위 디렉터리와 파일들의 정보를 가지는 특별한 파일과 같은 취급을 받습니다.
그리고 각각의 프로세스들은 현재 디렉토리(current directory)를 가져서 만약 파일을 탐색할 때, 현재 디렉터리에 속한 파일들을 먼저 탐색하고, 현재 디렉터리가 아닌 곳에 속한 파일을 참조하기 위해서는 탐색 경로를 사용하거나 해당 디렉터리로 옮겨가야 합니다.
4. 비순환 그래프 디렉토리 (Acyclic-Graph Directories)
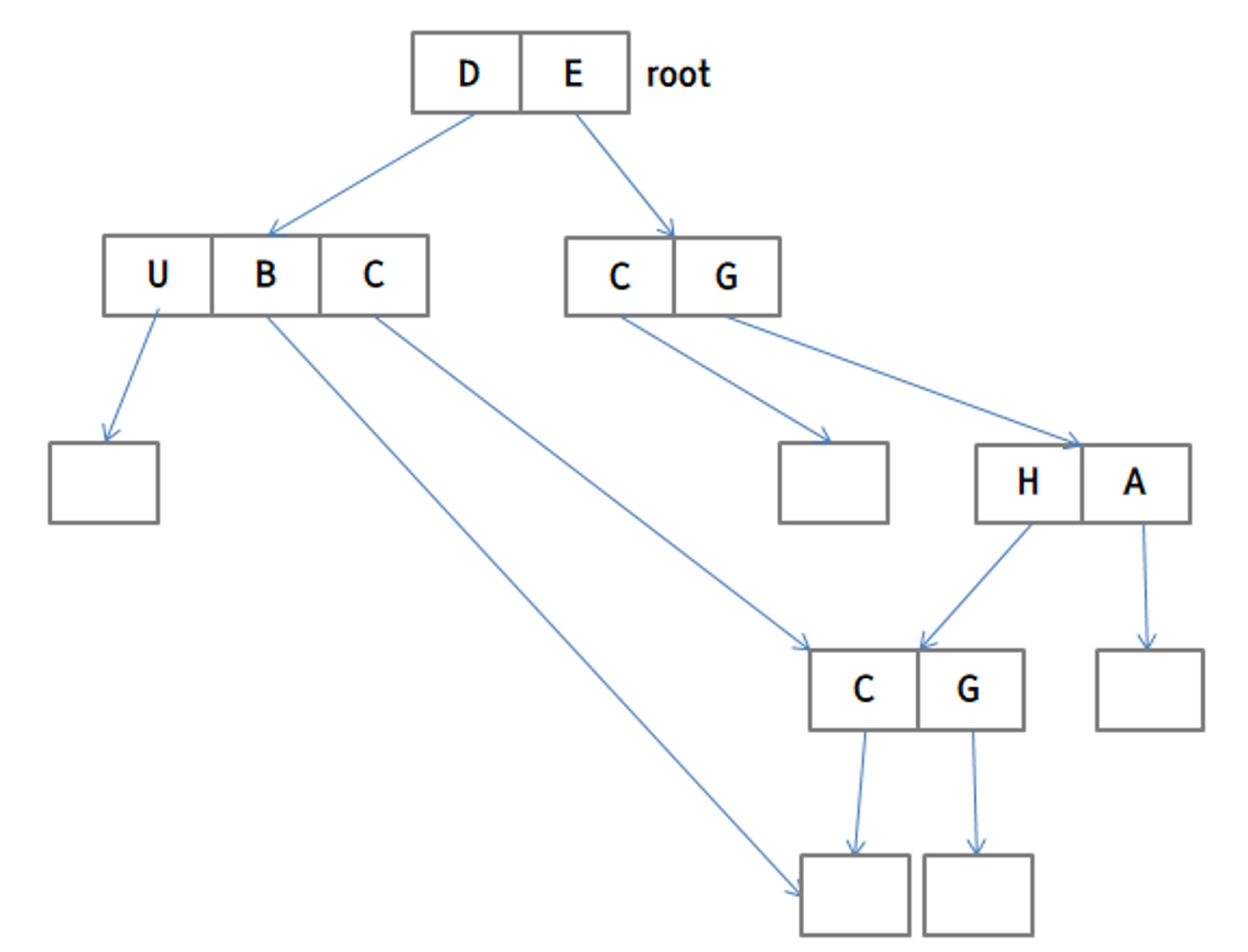
트리 구조 디렉터리에서는 파일 또는 디렉터리의 공유를 허용하지 않습니다. 즉 같은 파일이나 디렉터리에 둘 이상의 디렉터리가 연결되어 있는 것을 금지한다는 뜻입니다. 이를 허용하여 주는 것이 바로 비순환 그래프 디렉터리입니다.
비순환 그래프 디렉터리는 링크(Link)를 이용해서 이러한 공유를 허용합니다. 링크에는 하드 링크와 소프트 링크, 두 가지 종류가 존재합니다.
- 하드 링크 하드 링크(Hard Link)는 특정 파일의 복사본을 만드는 것이 아니라, 같은 파일을 가리키는 새로운 파일명을 만드는 것을 말합니다. 즉, 원본 파일과 하드 링크 파일은 동일한 inode를 가지고 있기 때문에, 원본 파일이 수정되면 하드 링크 파일도 동시에 수정됩니다. 따라서, 하드 링크 파일과 원본 파일은 서로 구분되지 않습니다. 하드 링크 파일을 삭제해도 원본 파일에는 영향을 주지 않습니다. 하지만 원본 파일을 삭제하면 하드 링크 파일도 함께 삭제됩니다. 하드 링크는 같은 파일 시스템 내에서만 생성할 수 있습니다. 다른 파일 시스템에 대해서는 소프트 링크를 사용해야 합니다.
- 소프트 링크 소프트 링크(Soft Link)는 원본 파일의 경로명을 가리키는 파일을 말합니다. 즉, 원본 파일과 별개로 새로운 파일을 생성하여, 이 파일이 원본 파일을 가리키도록 만드는 것입니다. 소프트 링크 파일은 다른 inode를 가지고 있기 때문에, 원본 파일이 수정되어도 소프트 링크 파일은 영향을 받지 않습니다. 그리고 원본 파일이 삭제되면, 소프트 링크 파일은 더 이상 원본 파일을 가리키지 않게 됩니다. 소프트 링크는 다른 파일 시스템에 대해서도 생성할 수 있으며, 원본 파일이나 소프트 링크 파일이 어느 파일 시스템에 속해있더라도 상관없이 원본 파일을 가리키게 됩니다.
비순환 그래프 디렉터리에서는 두 가지 사항을 꼭 고려해야 합니다.
-
가명 문제(Aliasing Problem)
비순환 그래프 디렉터리에서는 파일이 여러 개의 경로명을 가질 수 있기 때문에 파일을 순회하거나 할 때, 동일한 파일을 중복적으로 탐색하는 경우가 생길 수 있습니다. 만일 시스템을 백업한다거나 통계를 내기 위해 순회하는 경우라면 더 심각한 문제를 야기할 수 있습니다.
-
할당 해제에 대한 문제(Deallocation Problem)
공유 파일에 할당된 공간을 언제 반납할 것인가를 고려해야 한다는 것입니다. 해당 파일을 가리키고 있는 어떤 포인터든 하나라도 삭제되면 해당 파일을 삭제할 수도 있을 것이고, 모든 포인터가 다 사라져야 파일을 삭제할 수도 있을 것입니다. 잘못 관리하여 포인터가 남아있게 만들면, 엉뚱한 파일을 가리키게 될 수도 있습니다.
5. 일반 그래프 디렉터리 (General Graph Directory)
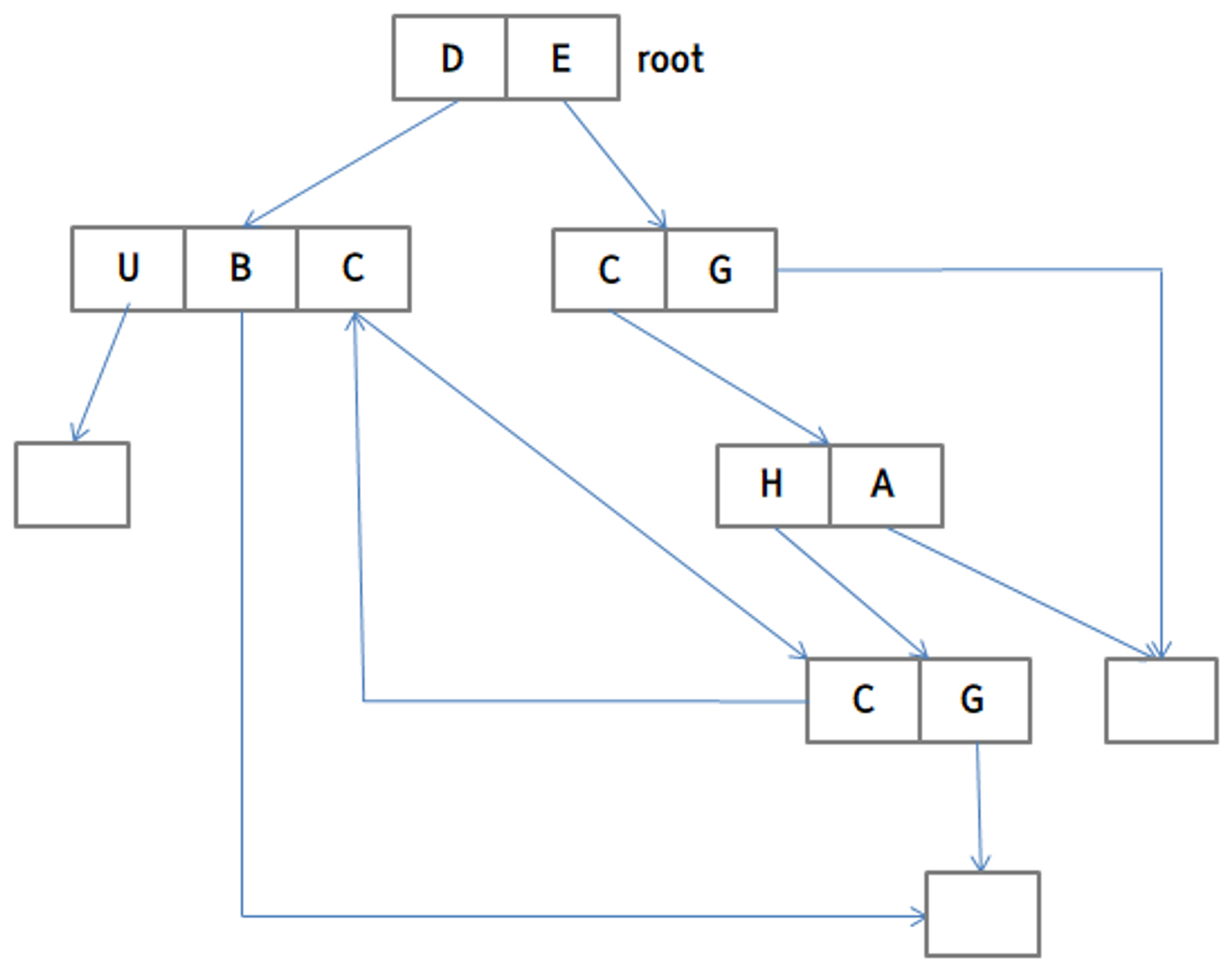
마지막으로 일반 그래프 디렉터리는 링크를 만드는데 어떠한 제약도 두지 않는 형태를 말합니다. 순환 시에 중복 탐색을 피하기 위해, 한 번의 순환에 하나의 디렉터리에 접근할 수 있는 횟수를 제한하는 counter를 이용하거나, 특정 링크들을 순환할 때 우회하는 등의 방법을 사용할 수 있습니다.
Implementation
파일 시스템은 디스크로의 효율적이고 편리한 접근을 제공합니다. 하지만 이 파일 시스템을 설계함에 있어서는 2가지 고려해야 할 사항이 존재합니다.
-
파일 시스템이 사용자에게 어떻게 보여야 할지 정의하는 것
파일의 이름이나 id와 같은 속성, 파일에 허용된 연산, 디렉터리 구조 등을 정의하는 것입니다.
-
✅ 파일들을 실제 저장 장치인 디스크에 어떻게 저장하느냐 하는 것입니다.
디스크의 어떤 블록에 해당 파일을 저장할지를 결정해주는 것입니다.
파일 시스템 자료 구조 (Data Structure for File System)
블록(block) : 정보를 담는 디스크의 한 물리적인 공간
일반적으로는 512B의 크기를 가지며 하나 이상의 섹터(sector)로 이루어져 있습니다. 디스크와 메모리 사이에 데이터 전송을 실행할 때 이 블록을 최소 단위로 사용합니다.
디스크 상의 구조(On-disk Structure)
파티션 또는 볼륨이라는 독립적인 공간들로 나누어서 사용됩니다.
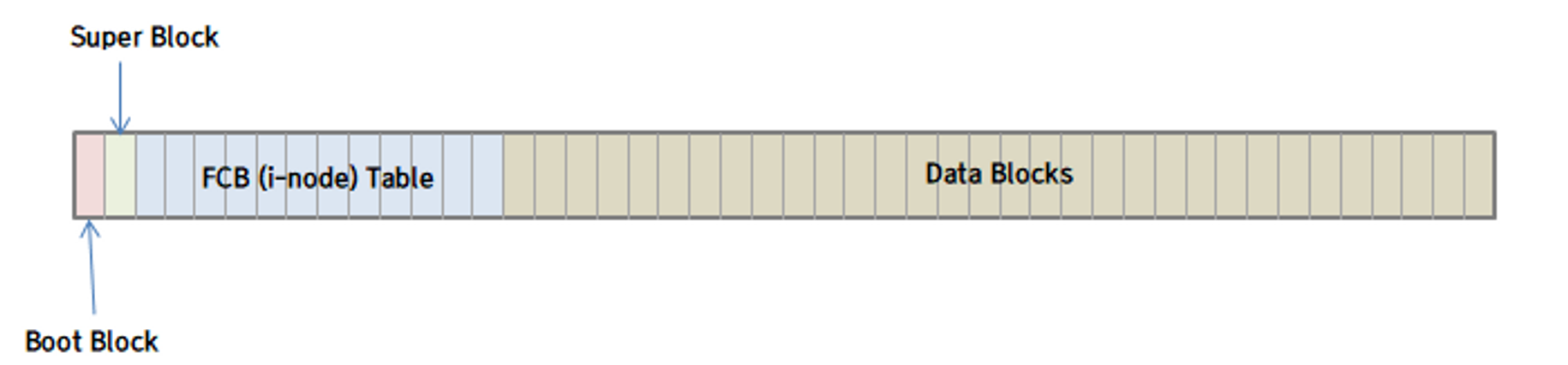
부트 제어 블록 (Boot control block): 해당 파티션의 운영체제가 시스템을 부트 시키는 데에 필요한 정보를 가지고 있습니다. 디스크가 운영체제를 가지고 있지 않다면, 당연히 부트 제어 블록은 비어있게 됩니다.
볼륨 제어 블록 (Volume control block, Super block): 파티션에 속한 블록의 수, 블록의 크기 등 파티션에 대한 정보를 저장하고 있습니다.
FCB(File Control Block): Unix와 Linux에서는 i-node라고도 불리는 FCB는 파일의 메타 데이터, 즉 파일에 대한 자세한 정보를 담고 있습니다. 파일의 타입, 소유자, 소유 그룹, 접근 허용 정보, 시간 정보, 파일의 크기 등의 정보를 가지며, 가장 중요한 데이터 블록에 대한 포인터들을 가집니다.
데이터 블록: 실제 데이터를 저장하는 역할을 합니다.
파일 생성 및 파일 열기
파일 생성
- 사용자가 creat() 함수와 같은 파일 생성 명령어를 실행시키면 운영체제는 FCB Table 중에서 비어있는 하나의 블록을 골라서 FCB(i-node)를 만들어줍니다.
- 그 FCB에 만들고자 하는 파일의 정보들을 입력해 줍니다. 그리고 파일을 저장하는 데에 필요한 만큼의 데이터 블록들을 할당받고, 할당받은 블록들에 대한 블록 번호를 FCB에 저장해줍니다.
- 운영체제가 디렉터리를 업데이트해주면 파일 생성이 완료됩니다.
파일 열기
-
우선 커널에 있는 system-wide open-file table에 원하는 파일의 FCB가 있는 지 찾아봅니다.
-
존재한다면 해당 FCB에 대한 인덱스 값을 per-process open-file table로 가져와서 추가시켜 줍니다.
System-wide open file table : 전체 시스템에서 열려있는 파일들에 대한 FCB를 저장하고 있는 테이블
per-process open-file table : 말 그대로 프로세스가 열고 있는 파일의 목록에 대한 테이블
-
만일 원하는 파일이 system-wide open file table에 없다면 디렉터리 구조에서 검색을 해야합니다. FCB 테이블에서 원하는 FCB를 찾아서 system-wide open file table과 per-process open-file table에 차례로 등록을 시켜준 뒤, 해당 인덱스를 반환해줍니다.
디스크 블록 할당 방법 (Disk Block Allocation Methods)
1. Continuous Allocation
연속적인 블록들을 할당하는 방법입니다. 무조건 이어진 순서의 블록들을 할당해 줄 수 있습니다.
시작 블록의 번호와 몇 개의 블록을 사용하는지를 이용해 블록들을 정의할 수 있으며, 블록들이 모두 바로 옆에 있기 때문에 디스크 탐색 시간이 줄어든다는 장점이 있습니다.
대신 앞에서 메모리에서 배웠던 것처럼 External fragmentation이 발생할 수 있고, 얼마나 많은 공간을 사용할지를 미리 알고 할당을 시켜줘야 합니다.
2. Linked Allocation
연결 리스트처럼 시작 블록을 지정하고 각 블록들은 다음 블록에 대한 포인터 값을 가지는 것으로 디스크 공간 할당을 진행할 수 있습니다.
블록들은 꼭 붙어 있을 필요가 없고 여기저기에 흩어져있지만 서로를 포인터로 연결하고 있는 형태입니다. 이러한 경우에는 external fagmentation이 발생할 일이 없고 굳이 처음에 얼마만큼의 공간을 사용할지 지정을 해주지 않아도 됩니다.
Sequential 한 형태의 접근에는 효과적이지만 Linked List의 단점을 그대로 가지고 있습니다. 중간에 있는 특정 블록에 접근하기 위해서는 첫 블록부터 차례로 따라가서 접근해야 하기 때문에 비효율적일 수 있습니다.
3. Indexed Allocation
Linked Allcation처럼 블록들은 여기저기 흩어져있지만 이를 연결 리스트로 연결하는 것이 아닌 모든 블록들의 주소를 하나의 블록에 저장하고 관리하는 형태입니다.
이렇게 파일의 모든 블록들의 인덱스를 저장하고 있는 블록을 index block이라고 하고 특정 블록에 접근하기 용이해집니다.
하지만 정말 작은 파일을 저장할 때도 index block을 만들어야 하기 때문에 공간을 낭비할 수 있습니다.
Free-Space Management
어떤 디스크의 공간이 비었는지를 알고 있어야 필요할 때 할당을 해 줄 수 있기 때문에 할당되지 않은 공간을 모두 알고 있어야 합니다.
bit vertor 이용
-
모든 블록들을 쭉 나열해서 쓰고 있는 블록은 1, 아직 쓰지 않는 블록은 0으로 표시하여 나타내는 방법입니다.
-
당연히 구현이 간단하고 효율적이지만 디스크 사이즈가 커지면 bit vector의 크기도 커지게 되고, 메모리에 담을 수 없을 수 있습니다.
Linked List 사용
-
비어있는 블록들 중 가장 앞에 있는 블록으로부터 시작해, 다음 비어있는 블록을 가리키는 포인터를 만들어서 연결하는 방법입니다.
-
하지만 여전히 Linked List의 단점을 가지고 있고 각각의 블록들이 포인터를 저장할 공간을 따로 가지고 있어야 합니다.
Grouping
-
비어있는 블록들 중 하나의 블록이 n개의 비어있는 블록의 포인터를 저장하고 있는 형태입니다.
-
저장된 블록들 중 마지막 블록이 다음 n개의 블록의 포인터를 저장할 블록에 대한 인덱스를 가집니다. 이 방법을 이용하면 중간에 비어있는 블록을 찾을 때 훨씬 빠르게 찾을 수 있습니다.
Counting
- Continuous Allocation에서 사용할 수 있는 방법으로 비어있는 블록들의 시작 블록의 주소만 저장하고 있는 형태입니다.
