Virtual Memory
가상 메모리는 물리 메모리로부터 사용자 관점의 논리 메모리를 분리시켜 메인 메모리를 균일한 크기의 저장 공간으로 구성된 엄청나게 큰 배열로 추상화시켜 줍니다
가상 메모리를 이용하면 프로그램이 실제 물리 메모리보다 큰 메모리 공간을 요구하더라도 사용이 가능하다는 장점이 있습니다.
명령어(instruction)는 반드시 메모리에서 실행되어야 하지만 전체 프로그램이 지금 당장 필요한 것은 아닙니다. 그리고 만일 전체 프로그램이 다 필요하다 하더라도, 이 모든 프로그램이 동시에 필요한 것 역시 아닙니다. 그래서 프로그램을 부분적으로 메모리에 적재할 수 있다면 다음과 같은 이득을 얻을 수 있습니다.
-
프로그램은 전체 물리 메모리 크기에 제약을 받을 필요가 없습니다. (조금씩 불러오면 되기 때문에)
-
동시에 더 많은 프로그램이 실행될 수 있습니다. (각각의 프로그램들이 더 작은 메모리 공간을 차지하기 때문에) 이를 통해 효율적인 자원의 이용이 가능합니다.
-
모든 프로그램을 메모리에 올리고 내리는 것보다 훨씬 빠르게 수행이 가능합니다.
이렇게 하면 사용자가 느끼기에는 정말 많은 프로그램이 메모리에 적재되어 있는 것으로 느낄 수 있습니다. 이처럼 작은 메모리로도 충분히 큰 가상 주소 공간을 프로그래머에게 제공할 수 있습니다.
- VMS(Virtual Memory System)는 4GB의 char 배열이라 볼 수 있습니다.
- VMS를 아파트 단지라 하면 페이지는 '동'이라 볼 수 있습니다.
- 그리고 우리가 사용하는 메모리는 페이지 내에 있으므로, 페이지의 '절대적 위치'를 알고 난 뒤 페이지 내의 메모리는 '상대적 위치'로 표현한다면 좀 더 간단히 접근할 수 있고 관리에 용이해집니다.
- 즉, 4GB 배열을 잘라서 하나하나를 페이지라 하고, 페이지는 보통 4KB부터 그 4MB나 그 이상까지 커지기도 하며, 페이지 내에서 메모리는 찾습니다.
- 가상주소는 (Page,Distance)로 이루어져 있고, Page는 페이지의 주소, Distance는 페이지 내의 위치입니다.
- 만약 메모리의 물리적인 주소를 묻는다면, (Frame,Distance)입니다.
요구 페이징(Demand Paging)
요구 페이징은 페이지들이 실제로 실행될 때(요구될 때) 메모리에 적재하여 사용하는 방법입니다.
앞에서 살펴봤던 바와 같이 모든 프로그램이 메모리에 적재되어 있을 필요가 없기 때문에 요구 페이징이 필요하고 가상 메모리를 구현함에 있어서 가장 중요한 개념이 바로 이 요구 페이징입니다.
페이저
요구 페이징을 수행할 때 페이지들을 관리해 주는 역할을 맡습니다.
페이저는 프로세스가 디스크에서 메모리로 올라올 때 어떤 페이지들이 필요로 되어지는 지를 파악하여 해당 페이지들만 가져옵니다.
필요한 페이지를 가져오는 방법
메모리로 올라온 페이지들과 디스크에 남아있는 페이지들을 구분을 할 수 있는 방법이 있어야하는데 테이블의 valid bit를 사용하여 Valid 하다면 현재 메모리로 적재되어 접근이 가능한 상태이고, invalid 한 상태라면 디스크에 남아있는 페이지이거나 아예 유효하지 않은 페이지라는 뜻입니다.
프로세스가 원하는 페이지가 메모리가 아닌 디스크에 존재하여 invalid한 상태일 때는 Page Fault (페이지 부재)가 발생합니다. 페이지 부재가 일어나면 아래의 그림과 같은 과정을 통해 해결을 해주게 됩니다.
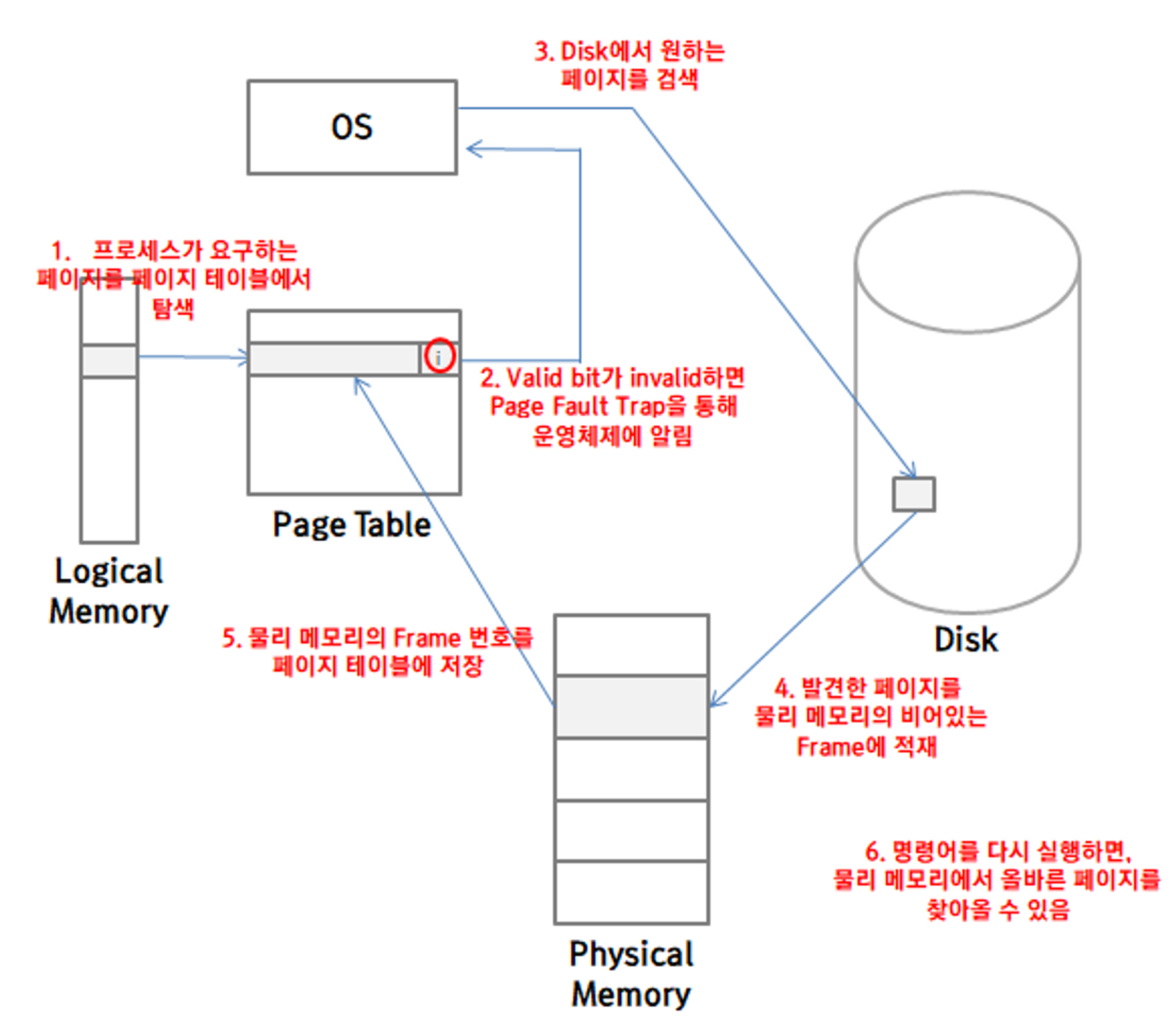
페이지 교체(Page Replacement)
다중 프로그래밍이 늘어나면서 한 번에 실행되는 프로그램이 늘어나고 그렇게 되면 결국 모든 페이지가 사용되고 있는 상태가 될 수 있습니다. 이렇게 물리 메모리에 남는 프레임이 하나도 없을 때는 페이지 교체가 일어납니다.
페이지 교체 기본 순서
-
디스크에서 요구되는 페이지의 위치를 찾는다.
-
물리 메모리에서 비어있는 프레임을 찾는다. 만약 비어있는 프레임이 있다면 그냥 사용하면 되지만 만일 하나도 없다면, 페이지 교체 알고리즘을 통해 어떤 프레임을 선택하여 해당 프레임을 디스크로 돌려보내어 빈 프레임으로 만든다.
-
이렇게 만든 빈 프레임에 원하는 페이지를 넣는다. 그리고 페이지 테이블을 최신화해준다.
이 때 물리 메모리에서 선택되어 디스크로 돌아가게 되는 프레임을 victim frame이라고 합니다
이러한 페이지 교체가 일어나면 디스크에서 프레임을 가져올 때와 선택된 프레임을 디스크로 돌려보낼 때, 두 번이나 디스크에 접근을 해야 합니다. 디스크에 접근하는 것 자체가 굉장히 많은 시간을 필요로 하기 때문에 디스크에 접근하는 횟수를 줄이는 것이 중요합니다.
페이지 접근 최소화
방법1. 변경 비트(Modify Bit, Dirty Bit)
실행 시간을 최소화 시키기 위해 우리는 페이지 테이블에 변경 비트를 추가하여 사용할 수 있습니다.
이 비트는 페이지가 프로세스에서 사용된 뒤 페이지 내에 만약 어떤 변경된 사항이 있다면 비트를 1로 바꾸어 주는 역할을 합니다. 만일 페이지 교체 시에 이 변경 비트가 0인 페이지를 선택한다면, 아직 페이지가 아무 수정이 되지 않았다는 뜻이기 때문에, 디스크와 동일한 데이터를 갖고 있고, 이 때문에 디스크에 다시 접근하여 수정을 해줄 필요가 없이 프레임을 삭제시켜버리면 됩니다.
방법2. 페이지 교체 알고리즘 사용
디스크에 접근하는 횟수를 줄이는 두 번째 방법은 바로 페이지 교체를 최대한 일어나지 않도록 하는 것입니다. 이것은 페이지 교체 알고리즘을 잘 선택하여 최대한 많이 쓰이는 페이지를 남겨두면 가능합니다.
페이지 교체 알고리즘
1. FIFO (First in, First out)
메모리에 올라온 지가 가장 오래된 페이지를 내쫓는 알고리즘으로 가장 간단한 페이지 교체 알고리즘입니다.
올라온 시간을 페이지마다 기록해도 되고, 페이지들이 올라온 순서대로 큐를 만들어서 관리해도 됩니다. 간단하긴 하지만 자주 사용하는 페이지들이 올라온 지 오래되었다는 이유만으로 디스크로 돌아간 뒤 금방 다시 올리는 알고리즘이라 최적화와는 거리가 있습니다.
2. Optimal Page Replacement (최적 페이지 교체)
FIFO의 단점을 고려해서 설걔된 최적 페이지 교체 방법은 바로 앞으로 가장 오랜 시간 동안 사용되지 않을 페이지를 찾아 교체하는 방법입니다.
가장 최적의 알고리즘이긴 하지만 미래에 대한 정보를 구하기가 어렵기 때문에 구현은 어렵습니다.
3. LRU(Least-Recently-Used)
최적의 알고리즘은 구현이 불가능하기 때문에, 조금 시각을 바꾸어 가장 오랜 기간 동안 사용이 되지 않은 페이지를 교체하는 방법입니다.
각 페이지마다 마지막 사용 시간을 저장해 두고, 이 정보를 바탕으로 가장 오랫동안 사용되지 않은 페이지가 선택됩니다. 이러한 LRU는 좋은 알고리즘으로 평가받고 있으며, LRU를 구현할 때는 Counter 또는 Stack 중 하나의 도움을 필요로 합니다.
-
Counter 활용 방법
CPU 내에 clock을 추가하여 구현합니다. 페이지를 참조할 때 마다 페이지의 사용 시간이라는 필드에 이 시간 값을 복사해주는 것입니다. 교체 시에는 당연히 시간 값이 가장 작은 페이지가 선택됩니다.
-
Stack 활용 방법
이 알고리즘은 페이지들을 스택에 저장하며 최근에 사용한 페이지들이 스택의 상단에 위치하도록 합니다. 스택의 가장 아래쪽 페이지가 교체될 때, 중간 값을 제거해야하는 경우가 있으므로 보통 이를 Doubly Linked List로 구현합니다.
4. LRU Approximation Algorithm
LRU를 위한 Counter나 Stack의 지원이 어려운 경우가 있을 수 있습니다. 이럴 때는, 페이지 테이블에 참조 비트(Reference Bit)를 사용하여 LRU 근사 페이지 교체를 수행할 수 있습니다.
참조 비트는 페이지가 참조 되면 값을 1로 바꾸어 저장하는 비트입니다. 물론 처음에는 모두 0으로 시작합니다. 이를 통해 어떤 페이지가 먼저 사용되었는지는 알기 어렵지만, 어떤 페이지가 사용되지 않았는지는 판별할 수 있습니다.
LRU Appoximation Algorithm은 이 참조 비트를 이용하여 여러 형태로 구현될 수 있습니다.
1. Additional-Reference Bits Algorithm(부가적 참조 비트 알고리즘)
페이지 별로 8 비트의 참조비트를 사용하여 누가 먼저 사용되었는지를 판별할 수 있습니다. 일정한 시간 간격마다, 이 비트들은 우측으로의 shift 연산을 수행하게 됩니다. 즉 00100000이라는 참조 비트가 있었다면, 미리 정해진 일정한 시간 후에는 00010000으로 변하게 됩니다. 그리고 해당 시간 동안에 참조가 한 번이라도 발생하면 가장 왼쪽의 비트를 1로 바꾸어 줍니다.
처음에는 00000000일 것이고 그러다가 참조가 되면 10000000이 되겠죠? 그러다가 시간이 흘러 두번의 Shift가 발생하는 동안 참조가 없으면 00100000이 될 것이고, 다시 참조가 일어나면 10100000으로 변할 것입니다. 이렇게 하면 수가 가장 클수록 최근에 많이 참조된 페이지로 판단이 가능할 것입니다.
2. Second-Chance Algorithm (2차 기회 알고리즘)
이 알고리즘은 기본적으로 FIFO 방식에 기초를 둡니다. 하지만 페이지가 선택될 때 마다 참조 비트를 확인하여 참조 비트가 0이면 바로 페이지를 교체하고, 1이면 한 번 더 기회를 주고 다음 페이지를 선택하는 알고리즘입니다. 이렇게 한 번 기회를 받게 되면 참조 비트는 다시 0으로 되돌아갑니다.
이 알고리즘을 구현하기 위해 원형 큐를 많이 사용합니다. 어떤 포인터를 통해 희생될 페이지를 가리키고 해당 페이지가 참조 비트가 0이면 바로 선택되고 0이 아니라면 해당 비트를 0으로 바꾼 뒤, 0인 페이지를 찾을 때 까지 차례로 순환하게 됩니다.
3. Enhanced Second-Chance Algorithm
2차 기회 알고리즘을 변경 비트까지 이용해서 구현을 하면 더 개선된 형태의 알고리즘을 만들 수 있습니다. 최대한 참조도 되지 않고 변경도 되지 않은 페이지를 먼저 찾아서 선택시켜 주는 것입니다. 여기서는 각각의 페이지를 다음의 4개의 등급으로 분류할 수 있고, 가장 낮은 등급의 페이지부터 선택을 해주면 됩니다.
- (0, 0): 최근에 사용되지도 변경되지도 않은 페이지 - 교체하기 가장 적합한 페이지
- (0, 1): 최근에 사용은 되지 않았지만 변경은 된 경우 - 교체를 위해 디스크에 접근을 해야함
- (1, 0): 최근에 사용은 되었지만 변경은 되지 않은 경우 - 이 페이지는 다시 사용될 확률이 높음
- (1, 1): 최근에 사용되었고 변경도 된 경우 - 최대한 선택을 미뤄야 함
