배치 서빙
머신러닝 모델을 사용하여 한 번에 대량의 데이터에 대해 예측을 수행하는 과정
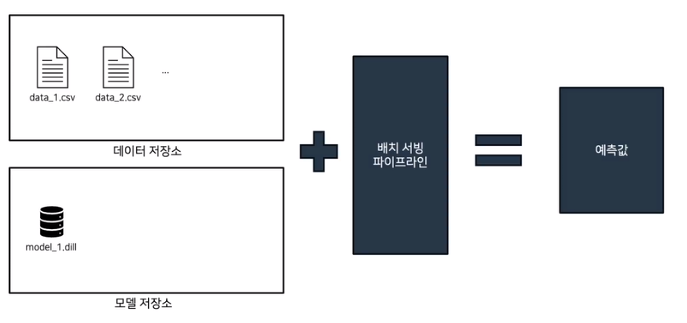
데이터,모델 저장소에서 배치 서빙 파이프라인에 넣어주고 이를 통해 예측값을 얻는다.
- 데이터 저장소의 데이터는 주로 특정 시간 단위로 모아진 데이터와 같이 같은 종류, 다른 환경에서의 데이터들의 집합이다.
배치 서빙 외에도 대표적인 세 가지 서빙 파이프라인이 있다.
서빙 종류
| Feature | 방법 | 예시 | 지연 시간 | 장점 | 단점 |
|---|---|---|---|---|---|
| Batch | 배치 프로세스에서 사전 계산 | 매일 계산된 임베딩 | 몇 시간 ~ 며칠 | 설정이 간단함 | feature가 오래되어 최신성이 떨어짐, 계산 자원 낭비 |
| NRT (Near Real Time) | 스트리밍 프로세스에서 사전 계산 | 최근 30분간의 평균 거래액 | 몇 초 | 피처가 신선하고 확장성이 좋음 | 회사들이 설정이 더 어렵다고 생각함 |
| RT (Real Time) | 예측 시점에 계산 | 거래액이 $1000을 초과하는 경우 | 1초 미만 | 설정이 간단하고 피처가 신선함 | 확장성이 떨어짐 |
기본 아키텍쳐
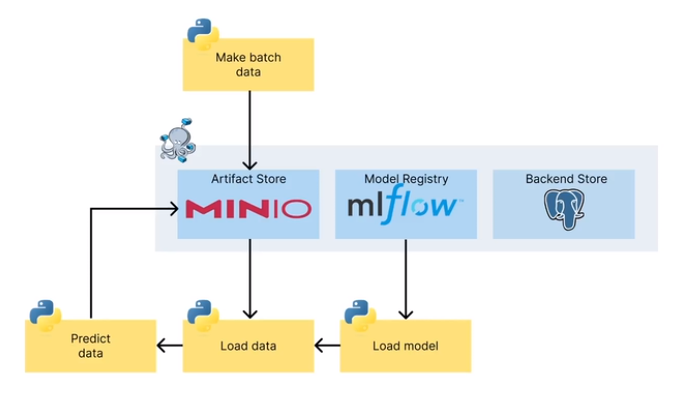
배치 서빙 코드
데이터 준비
# [make_batch_data.py]
from datetime import datetime
from sklearn.datasets import load_iris
from minio import Minio
#
# dump data
#
iris = load_iris(as_frame=True)
X = iris["data"]
X.sample(100).to_csv("batch.csv", index=None)
#
# minio client
#
url = "localhost:9000"
access_key = "minio"
secret_key = "miniostorage"
client = Minio(url, access_key=access_key, secret_key=secret_key, secure=False)
#
# upload data to minio
#
bucket_name = "not-predicted"
object_name = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
if not client.bucket_exists(bucket_name):
client.make_bucket(bucket_name)
client.fput_object(bucket_name, object_name, "batch.csv")- redis와 같은 캐시메모리를 사용하지 않고 간단하게 볼 예정이므로 버킷명(
not_predicted)구분한다. - 데이터 구분을 위해 데이터명은 생성 시간으로 구분
윈도우에선 파일명에
:가 포함될 수 없으므로 시간을 저장할 때-로 바꾸어야 한다
모델 불러오기
# [local_predict.py]
import os
import mlflow
import pandas as pd
from minio import Minio
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://localhost:9000"
os.environ["MLFLOW_TRACKING_URI"] = "http://localhost:5001"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "miniostorage"
def predict(run_id, model_name):
#
# load model: mlflow의 모델을 불러오기
#
clf = mlflow.pyfunc.load_model(f"runs:/{run_id}/{model_name}")
#
# minio client
#
url = "localhost:9000"
access_key = "minio"
secret_key = "miniostorage"
client = Minio(url, access_key=access_key, secret_key=secret_key, secure=False)
#
# get data list to predict: 예측할 데이터 불러오기
#
if "predicted" not in client.list_buckets():
# 최초 실행시 predicted bucket 생성
client.make_bucket("predicted")
# 추론이 안된 데이터 추출
predicted_set = set(objects.object_name for objects in client.list_objects(bucket_name="predicted"))
to_predict_list = [
objects.object_name
for objects in client.list_objects(bucket_name="not-predicted")
if objects.object_name not in predicted_set
]
print(to_predict_list)
#
# predict
#
for filename in to_predict_list:
print("data to predict:", filename)
# download and read data
client.fget_object(bucket_name="not-predicted", object_name=filename, file_path=filename)
data = pd.read_csv(filename)
# predict
pred = clf.predict(data)
# save to minio prediction bucket
pred_filename = f"pred_{filename}"
pred.to_csv(pred_filename, index=None)
client.fput_object(bucket_name="predicted", object_name=filename, file_path=pred_filename)
if __name__ == "__main__":
from argparse import ArgumentParser
parser = ArgumentParser() # 스크립트 실행 시 인자 받아오기
parser.add_argument("--run-id", type=str)
parser.add_argument("--model-name", type=str, default="my_model")
args = parser.parse_args()
#
# predict
#
predict(args.run_id, args.model_name)
mlflow 모델 불러오기
로컬에서 설계한 모델이 아닌 mlflow 서버에 저장된(실제로는 minio와 같은 스토리지에 저장된) 모델 불러오기
1. 모델 다운로드
import os
import mlflow
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://localhost:9000"
os.environ["MLFLOW_TRACKING_URI"] = "http://localhost:5001"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "miniostorage"
if __name__ == "__main__":
from argparse import ArgumentParser
parser = ArgumentParser() # 스크립트 실행 시 인자 받아오기
parser.add_argument("--run-id", type=str)
parser.add_argument("--model-name", type=str, default="my_model")
args = parser.parse_args()
mlflow.artifacts.download_artifacts(run_id=args.run_id, artifact_path=args.model_name, dst_path="./downloads")mlflow.artifacts.download_artifacts를 이용하여 모델을 원하는 경로로 다운로드
2. Dockerfile 작성 후 빌드
# [Dockerfile]
FROM amd64/python:3.9-slim
WORKDIR /usr/app/
#
# 모델을 불러오기 위한 패키지 다운로드
#
RUN pip install -U pip &&\
pip install mlflow==2.3.2 minio==7.1.15
#
# 모델을 실행하기 위한 패키지 다운로드 (캐싱을 위한 분리)
#
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
#
# 모델 다운로드
#
COPY downloads/ downloads/
COPY model_predict.py predict.py
#
# 도커 명령어로 파일을 실행하기 위한 요약
#
ENTRYPOINT [ "python", "predict.py", "--run-id" ][Build]
$ docker build -t <image_name> <dockerfile_path>3. 컨테이너 실행
로컬에서 mlflow, minio가 docker-compose로 실행된 상태라면 해당 docker network 포함시킨다
$ docker run --network <network-name> <image_name> <run_id>
공부!