모델 저장소: 학습이 완료된 모델을 저장하는 장소
- 실험 관리+파일: 학습 데이터, 패키지, 파라미터 등을 함께 저장
MLflow 아키텍쳐
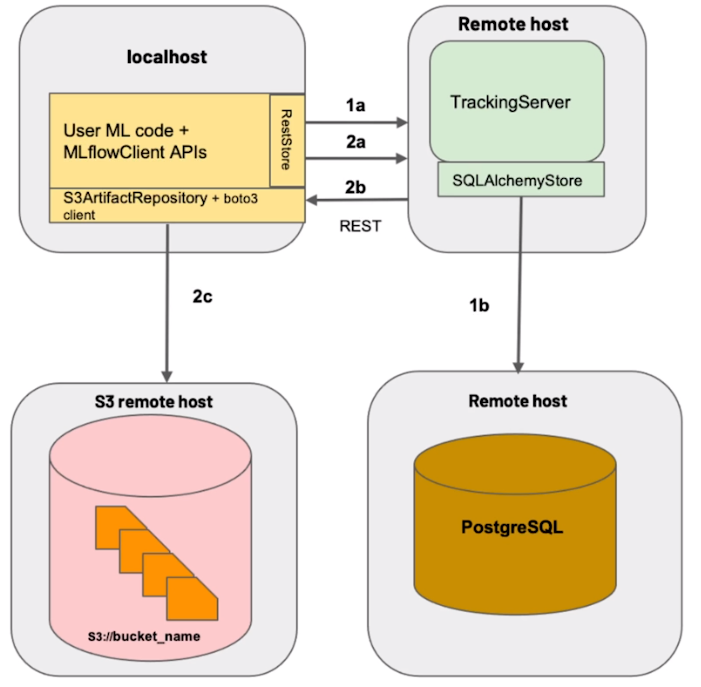
Backend Store (Remote host)
- 수치 데이터와 MLflow 서버의 정보들을 체계적으로 관리하기 위한 DB
- 저장 항목: 메타 데이터, 모델 정보, 학습 중 생기는 정보
Artifact Store(S3 remote host)
- 학습된 모델을 저장하는 Model Registry로써 이용하기 위한 스토리지 서버
- 기본적인 파일 시스템보다 체계적으로 관리할 수 있으며 외부에 있는 스토리지 서버도 사용할 수 있다는 장점이 있다.
docker-compose
version: "3"
services:
mlflow-artifact-store:
image: minio/minio # MinIO 공식 Docker 이미지
ports:
- 9000:9000
- 9001:9001
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: miniostorage
command: server /data/minio --console-address :9001 # MinIO 서버를 실행할 명령어. 데이터 저장 폴더와 콘솔 주소를 설정.
healthcheck: # 서비스의 상태를 확인하는 방법을 정의.
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s # 헬스체크 수행 간격
timeout: 20s # 헬스체크 타임아웃 시간
retries: 3 # 헬스체크 실패 시 재시도 횟수
mlflow-backend-store: # 두 번째 서비스: MLflow의 메타데이터 저장소로 사용되는 PostgreSQL 데이터베이스.
image: postgres:14.0
environment:
POSTGRES_USER: mlflowuser
POSTGRES_PASSWORD: mlflowpassword
POSTGRES_DB: mlflowdatabase
healthcheck: # PostgreSQL 서비스의 상태를 확인하는 방법을 정의.
test:
["CMD", "pg_isready", "-q", "-U", "mlflowuser", "-d", "mlflowdatabase"] # 데이터베이스의 준비 상태를 확인하는 명령어.
interval: 10s
timeout: 5s
retries: 5
mlflow-server: # 세 번째 서비스: MLflow 서버.
build:
context: .
dockerfile: Dockerfile
depends_on:
mlflow-artifact-store:
condition: service_started
mlflow-backend-store:
condition: service_healthy
ports:
- 5001:5000
environment:
AWS_ACCESS_KEY_ID: minio # AWS 스타일의 S3 저장소에 접근하기 위한 액세스 키로, 여기서는 MinIO에서 사용.
AWS_SECRET_ACCESS_KEY: miniostorage
MLFLOW_S3_ENDPOINT_URL: http://mlflow-artifact-store:9000 # MLflow에서 사용할 S3 엔드포인트의 URL
command:
- /bin/sh
- -c
- | # 여러 줄에 걸친 명령을 표시하기 위한 YAML 문법.
mc config host add mlflowminio http://mlflow-artifact-store:9000 minio miniostorage && # MinIO 클라이언트를 설정
mc mb --ignore-existing mlflowminio/mlflow # 이미 존재하지 않는 경우에만 MinIO 버킷 생성.
mlflow server \ # MLflow 서버 시작.
--backend-store-uri postgresql://mlflowuser:mlflowpassword@mlflow-backend-store/mlflowdatabase \ # PostgreSQL을 백엔드 저장소로 사용.
--default-artifact-root s3://mlflow \ # 아티팩트의 기본 저장 위치로 S3 버킷을 지정
--host 0.0.0.0 # 모든 IP에서 서버에 접근할 수 있도록 설정.코드
데이터 업로드
import pandas as pd
from sklearn.datasets import load_iris
from minio import Minio
from minio.versioningconfig import VersioningConfig, ENABLED
#
# dump data
#
iris = load_iris(as_frame=True)
X, y = iris["data"], iris["target"]
data = pd.concat([X, y], axis="columns")
data.sample(100).to_csv("iris.csv", index=None)
#
# minio client
#
url = "localhost:9000"
access_key = "minio"
secret_key = "miniostorage"
client = Minio(url, access_key=access_key, secret_key=secret_key, secure=False)
#
# upload data to minio
#
bucket_name = "raw-data"
object_name = "iris"
if not client.bucket_exists(bucket_name):
client.make_bucket(bucket_name)
config = client.set_bucket_versioning(bucket_name, VersioningConfig(ENABLED))
client.fput_object(bucket_name, object_name, "iris.csv")모델 학습 및 저장
import os
import uuid
import optuna
import mlflow
import pandas as pd
from minio import Minio
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
UNIQUE_PREFIX = str(uuid.uuid4())[:8] # 유니크한 프리픽스를 생성하여 실행별로 구분
BUCKET_NAME = "raw-data" # MinIO 버킷 이름 설정
OBJECT_NAME = "iris" # MinIO 오브젝트 이름 설정
# MinIO 접속을 위한 환경변수 설정
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://localhost:9000"
os.environ["MLFLOW_TRACKING_URI"] = "http://localhost:5001"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "miniostorage"
def download_data():
# MinIO 클라이언트 인스턴스 생성
url = "localhost:9000"
access_key = "minio"
secret_key = "miniostorage"
client = Minio(url, access_key=access_key, secret_key=secret_key, secure=False)
# 데이터 다운로드
object_stat = client.stat_object(BUCKET_NAME, OBJECT_NAME)
data_version_id = object_stat.version_id
client.fget_object(BUCKET_NAME, OBJECT_NAME, file_path="download_data.csv")
return data_version_id
def load_data():
# 다운로드된 데이터 로딩
data_version_id = download_data()
df = pd.read_csv("download_data.csv")
X, y = df.drop(columns=["target"]), df["target"]
data_dict = {"data": X, "target": y, "version_id": data_version_id}
return data_dict
def objective(trial):
# 새로운 파라미터 제안
trial.suggest_int("n_estimators", 100, 1000, step=100)
trial.suggest_int("max_depth", 3, 10)
run_name = f"{UNIQUE_PREFIX}-{trial.number}" # 실행 이름 설정
with mlflow.start_run(run_name=run_name):
# 제안된 파라미터를 로깅
mlflow.log_params(trial.params)
# 데이터 로딩
data_dict = load_data()
mlflow.log_param("bucket_name", BUCKET_NAME)
mlflow.log_param("object_name", OBJECT_NAME)
mlflow.log_param("version_id", data_dict["version_id"])
X, y = data_dict["data"], data_dict["target"]
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, random_state=2024)
# 모델 학습
clf = RandomForestClassifier(
n_estimators=trial.params["n_estimators"], max_depth=trial.params["max_depth"], random_state=2024
)
clf.fit(X_train, y_train)
# 학습된 모델 평가
y_pred = clf.predict(X_valid)
acc_score = accuracy_score(y_valid, y_pred)
# 평가 결과 로깅
mlflow.log_metric("accuracy", acc_score)
return acc_score
def train_best_model(params):
run_name = f"{UNIQUE_PREFIX}-best-model" # 최적 모델 실행 이름 설정
with mlflow.start_run(run_name=run_name):
# 파라미터 로깅
mlflow.log_params(params)
# 데이터 로딩
data_dict = load_data()
mlflow.log_param("bucket_name", BUCKET_NAME)
mlflow.log_param("object_name", OBJECT_NAME)
mlflow.log_param("version_id", data_dict["version_id"])
X, y = data_dict["data"], data_dict["target"]
# 최적의 파라미터로 모델 학습
clf = RandomForestClassifier(
n_estimators=params["n_estimators"], max_depth=params["max_depth"], random_state=2024
)
clf.fit(X, y)
# 학습된 모델 저장
mlflow.sklearn.log_model(sk_model=clf, artifact_path="my_model")
return clf
if __name__ == "__main__":
# MLflow 실험 설정
study_name = "hpo-tutorial"
mlflow.set_experiment(study_name)
# Optuna 연구 생성 및 설정
sampler = optuna.samplers.RandomSampler(seed=2024)
study = optuna.create_study(sampler=sampler, study_name=study_name, direction="maximize")
# 최적화 실행
study.optimize(objective, n_trials=5)
# 최적의 파라미터로 최적 모델 학습 및 저장
best_params = study.best_params
best_clf = train_best_model(best_params)모델 불러오기
import os
import mlflow
import pandas as pd
from minio import Minio
BUCKET_NAME = "raw-data"
OBJECT_NAME = "iris"
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://localhost:9000"
os.environ["MLFLOW_TRACKING_URI"] = "http://localhost:5001"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "miniostorage"
def download_data():
# Minio 클라이언트 객체를 생성
url = "localhost:9000"
access_key = "minio"
secret_key = "miniostorage"
client = Minio(url, access_key=access_key, secret_key=secret_key, secure=False)
# Minio 서버로부터 데이터를 다운로드
# stat_object 메소드로 객체의 메타데이터를 얻어오고 버전 ID를 획득
object_stat = client.stat_object(BUCKET_NAME, OBJECT_NAME)
data_version_id = object_stat.version_id
# fget_object 메소드로 데이터를 로컬 파일로 저장합니다.
client.fget_object(BUCKET_NAME, OBJECT_NAME, file_path="download_data.csv")
return data_version_id
def load_data():
# 데이터를 다운로드하고 pandas DataFrame으로 로드
data_version_id = download_data()
df = pd.read_csv("download_data.csv")
X, y = df.drop(columns=["target"]), df["target"]
# 데이터와 메타데이터를 포함하는 딕셔너리를 반환
data_dict = {"data": X, "target": y, "version_id": data_version_id}
return data_dict
def load_sklearn_model(run_id, model_name):
# MLflow를 사용하여 저장된 Scikit-Learn 모델을 로드
clf = mlflow.sklearn.load_model(f"runs:/{run_id}/{model_name}")
return clf
def load_pyfunc_model(run_id, model_name):
# MLflow의 PyFunc 인터페이스를 통해 모델을 로드
# Scikit-Learn 모델이라도 일관된 방식으로 사용
clf = mlflow.pyfunc.load_model(f"runs:/{run_id}/{model_name}")
return clf
if __name__ == "__main__":
from argparse import ArgumentParser
# 커맨드 라인 인자를 파싱하기 위한 ArgumentParser를 생성
parser = ArgumentParser()
parser.add_argument("--run-id", type=str)
parser.add_argument("--model-name", type=str, default="my_model")
args = parser.parse_args()
# 데이터를 로드
data_dict = load_data()
X = data_dict["data"]
# Scikit-Learn을 통해 모델을 로드하고 예측을 수행
sklearn_clf = load_sklearn_model(args.run_id, args.model_name)
sklearn_pred = sklearn_clf.predict(X)
print("sklearn")
print(sklearn_clf)
print(sklearn_pred)
# PyFunc를 통해 모델을 로드하고 예측을 수행
pyfunc_clf = load_pyfunc_model(args.run_id, args.model_name)
pyfunc_pred = pyfunc_clf.predict(X)
print("pyfunc")
print(pyfunc_clf)
print(pyfunc_pred)Custom Model
모델뿐만 아니라 모델의 전처리, 후처리 프로세스를 지난 후 결과값이 나올 때, 모든 프로세스를 묶어서 하나의 모델로 지정하는 것
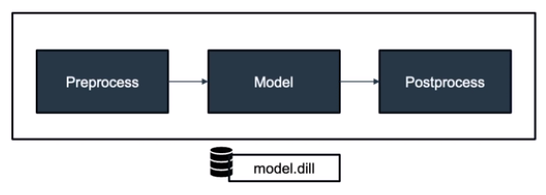
이전 코드에서 모델의 예측결과는 각 아이리스의 종류에 매핑되어 있는 숫자로 표현되어 있다.
이러한 숫자를 다시 아이리스 종류로 매핑한 결과를 post process로 설정하려면,
- 클래스로 선언 후
mlflow.pyfunc를 이용한다.
mlflow.pyfunc
MLflow 프레임워크에서 제공하는 기능 중 하나로, 다양한 머신러닝 라이브러리로 생성된 모델들을 파이썬 함수(pythonic function)처럼 다룰 수 있게 해주는 모듈이다.
- 사용자는 모델을 훨씬 쉽게 배포하고 호출할 수 있다
- MLflow 플랫폼 상에서 모델의 일관된 인터페이스를 가질 수 있다.
- PyFunc은 MLflow의 "Flavor" 중 하나로, 모델을 MLflow와 호환 가능한 형식으로 저장하고 로드하는 표준 방식을 제공한다.
mlflow.pyfunc의 주요 함수
mlflow.pyfunc.load_model()
- 저장된 PyFunc 모델을 로드하여 Python 함수로 사용.
- 설명
mlflow.pyfunc.log_model()
- 현재 MLflow 실행(run)에 PyFunc 모델을 로깅하여 MLflow 서버에 모델을 저장
- 설명
mlflow.pyfunc.save_model()
- PyFunc 모델을 파일 시스템에 저장.
- 설명
커스텀 모델 선언
커스텀 모델 클래스 선언
class MyModel:
def __init__(self, clf):
self.clf = clf
def predict(self, X):
X_pred = self.clf.predict(X)
X_pred_df = pd.Series(X_pred).map({0: "virginica", 1: "setosa", 2: "versicolor"})
return X_pred_dfmap()을 통해 후처리 과정을 붙인다.
train_best_model(params) 커스텀 - 모델 저장
def train_best_model(params):
.
.
#
# my custom model: 커스텀 모델 클래스 불러오기
#
my_model = MyModel(clf)
#
# save model
#
with open("model.dill", "wb") as f:
# 커스텀 모델을 'model.dill' 파일에 직렬화하여 저장
dill.dump(my_model, f)
# '_load_pyfunc' 함수를 정의하는 새로운 'loader.py' 스크립트 파일을 작성
# 저장된 모델을 로드하는 데 사용. textwrap.dedent로 앞부분의 공통 들여쓰기를 제거
with open("loader.py", "w") as f:
f.write(
textwrap.dedent(
"""
import os
import dill
def _load_pyfunc(path):
if os.path.isdir(path):
path = os.path.join(path, "model.dill")
with open(path, "rb") as f:
return dill.load(f)
"""
)
)
# MLflow를 사용하여 'my_model'이라는 아티팩트 경로에 모델을 로그
# 모델 데이터는 'model.dill'에 있으며, 'loader' 모듈은 모델을 로드하는 데 사용
# 'loader.py'는 로더 모듈에 필요한 의존성을 포함하는 코드 파일
mlflow.pyfunc.log_model(
artifact_path="my_model",
data_path="model.dill",
loader_module="loader",
code_path=["loader.py"],
)
return clf커스텀 모델 불러오기
이전 모델의 출력 결과물
base) (mlops-py3.9) PS C:\Users\wlsgy\Desktop\MLOps\05_model_registry> python section1_load_model.py --run-id 90beba76af604fcfa98a90a20fe47d1f
Downloading artifacts: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 156.08it/s]
pyfunc
mlflow.pyfunc.loaded_model:
artifact_path: my_model
flavor: mlflow.sklearn
run_id: 90beba76af604fcfa98a90a20fe47d1f
[0 1 1 1 1 1 1 0 0 2 1 2 0 2 0 1 0 0 0 1 0 2 1 2 0 1 2 2 2 0 0 0 1 0 2 1 1
1 2 0 2 1 0 0 1 0 2 0 2 2 1 0 0 2 0 2 2 0 1 0 0 1 2 2 1 2 2 1 0 0 0 2 1 0
1 2 1 2 2 2 2 2 1 2 2 1 2 0 2 1 0 1 0 2 1 1 0 2 2 0]커스텀 모델의 출력 결과물
(base) (mlops-py3.9) PS C:\Users\wlsgy\Desktop\MLOps\05_model_registry> python section2_load_model.py --run-id 184a78ab15094237b340403160005b1e
Downloading artifacts: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:00<00:00, 2803.99it/s]
pyfunc
mlflow.pyfunc.loaded_model:
artifact_path: my_model
flavor: loader
run_id: 184a78ab15094237b340403160005b1e
0 virginica
1 setosa
2 setosa
3 setosa
4 setosa
...
95 setosa
96 virginica
97 versicolor
98 setosa
99 virginica
Length: 100, dtype: object즉, 커스텀 모델을 관리하려면
- 클래스 선언을 통해 커스텀 모델 클래스를 생성한다.
mlflow.pyfunc와dill등을 통해 커스텀 모델을 mlflow에 로깅하도록 한다.- 모델을 불러와서 추론의 결과값을 얻는다.
의 순서로 진행한다.

공부!