
AWS의 다양한 서비스 중, S3를 간단하게 경험해 보았다.
AWS의 S3란, 아마존 클라우드 컴퓨팅 서비스의 일부이며, 무제한 용량(유료 서비스)을 제공하는 인터넷 스토리지 서비스이다.
S3의 시작은 버킬(bucket)의 생성부터 시작한다. S3는 버킷이라는 것을 생성하여, 데이터를 이 버킷에 담아서 저장하는 것이다.
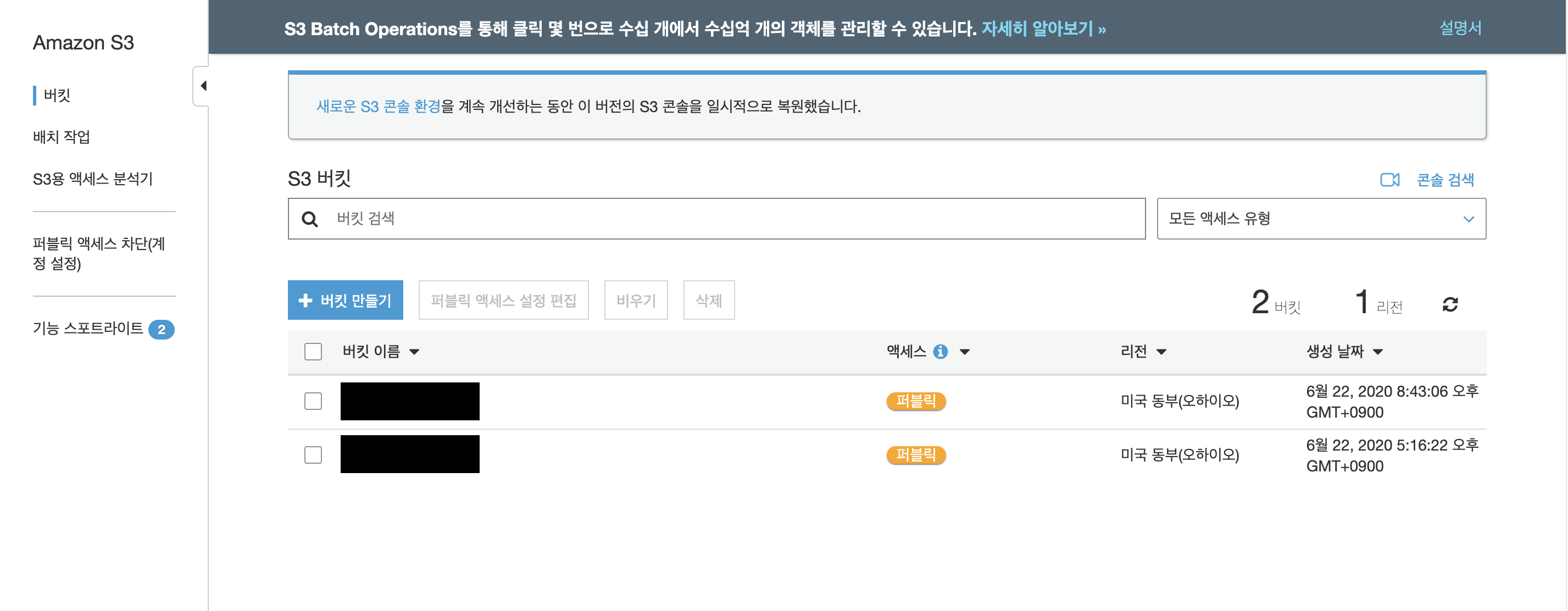
버킷 생성하기를 클릭하면, 버킷의 이름을 정하는 탬을 시작으로 다양한 옵션의 설정이 가능하다.
버킷이 생성되었으면, 버킷 리스트에 해당 버킷이 보이며, 해당 버킷을 클릭하면 또다른 상세 설정 페이지와 본격적으로 데이터를 업로드 할 수 있는 페이지가 보인다.
해당 페이지에서는 데이터의 업로드와 어떤 속성을 가진 데이터인지 설정이 가능하며, 권한과 관리를 통하여, 누가 이 버킷에 접속이 가능한지를 설정이 가능하다.
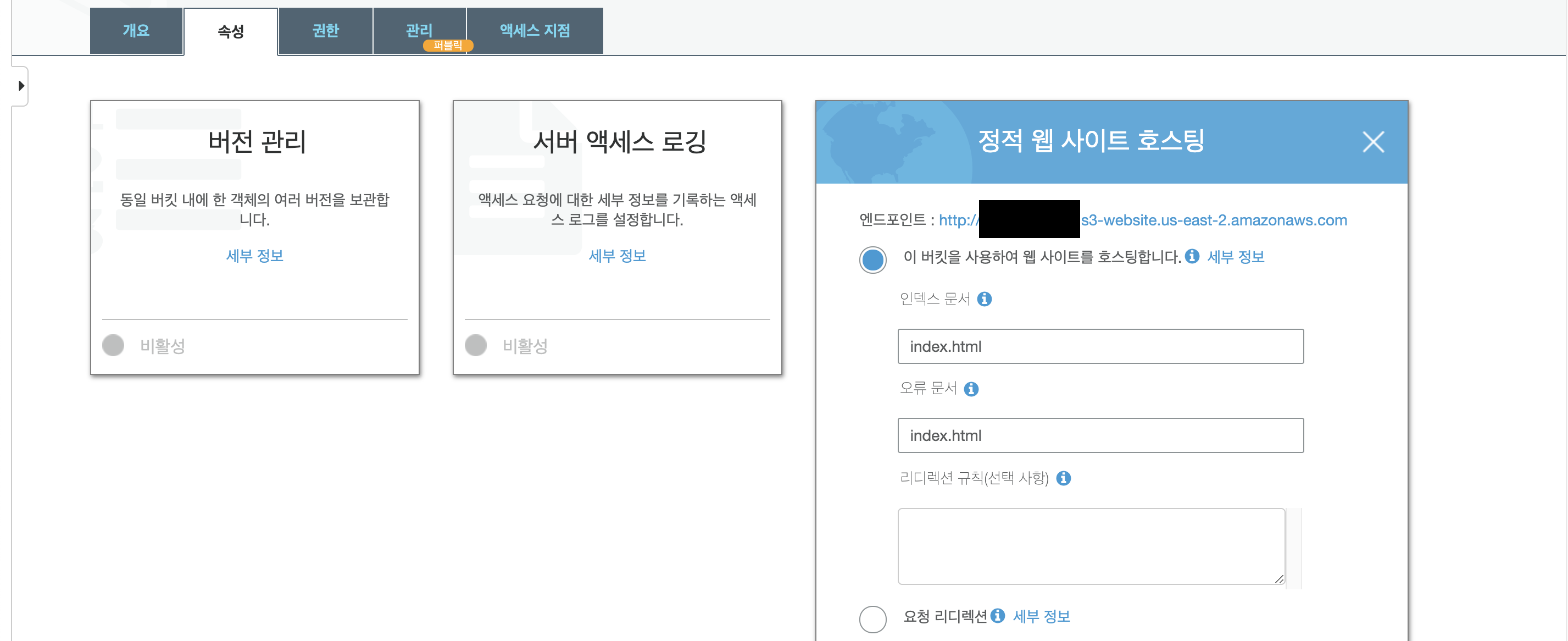
현재 스크린샷에 보이는 버킷에는 임의의 기능을 수행하는 코드의 클라이언트 부분을 REACT로 구성하여 업로드 하였다. 이 REACT는 코드의 접속 문서(웹페이지)는 index.html이므로 인덱스 문서에는 index.html을 작성하였고, 오류 문서는 현재 작성된게 없으므로, 같은 값을 입력해주었다.
상단에 보이는 엔드포인트는 우리가 잘 알고있는 웹사이트의 주소이다. REACT의 코드를 이용하여 잘 작성하고, 설정에 문제가 없다면, 브라우저를 통하여 해당 웹사이트에 접속이 가능하다.
우리가 네이버나 다음을 접속할 시, 개발자모드의 네트워크탭을 보면 이 S3가 어떤 서비스를 제공하는지 이해하기 쉽다고 생각한다. 임의의 사이트에 접속 시, 브라우저는 해당 사이트의 클라이언트 자료들을 다운로드 하며 이 자료들이 어떤 자료인지 네트워크 탭으로 확인가능하며 브라우저에 렌더링을 시킨다. 이 S3도 똑같이 해당 브라우저에 렌더링을 시킬 자료를 저장해 두었다가, 브라우저의 요청이 있으면 렌더링에 필요한 자료를 제공하고 브라우저는 해당 자료를 베이스로 렌더링을 하는 것이다.
