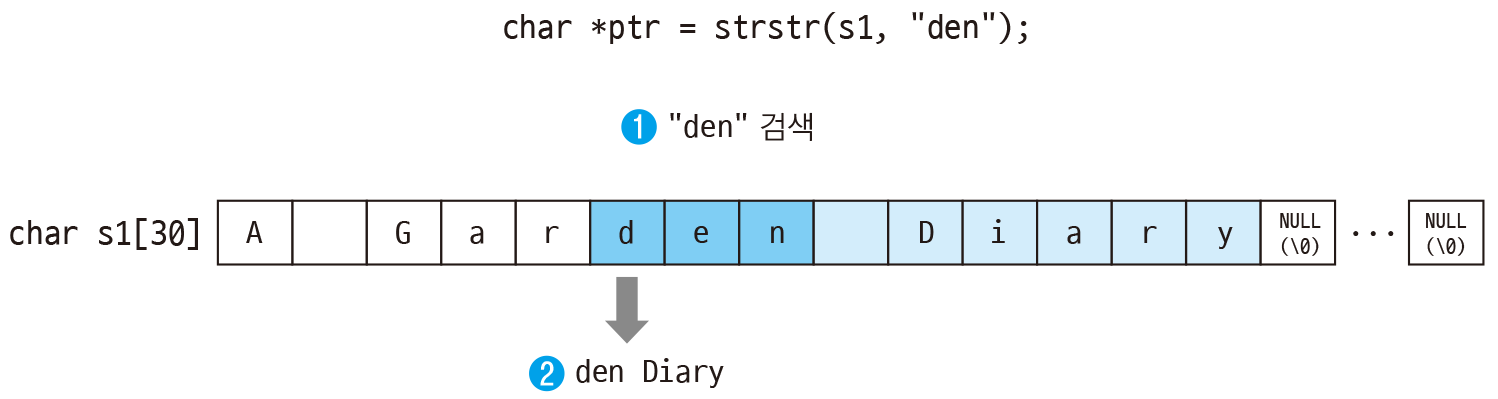
 문자열 검색이란 어떤 문자열 안에 다른 문자열이 포함되어 있는지 검사하고, 만약 포함되어 있다면 어디에 위치하는지 찾아내는 것을 의미.
문자열 검색이란 어떤 문자열 안에 다른 문자열이 포함되어 있는지 검사하고, 만약 포함되어 있다면 어디에 위치하는지 찾아내는 것을 의미.
검색되는 쪽의 문자열을 text
찾아내는 문자열을 pattern이라고 함.
Brute-Force
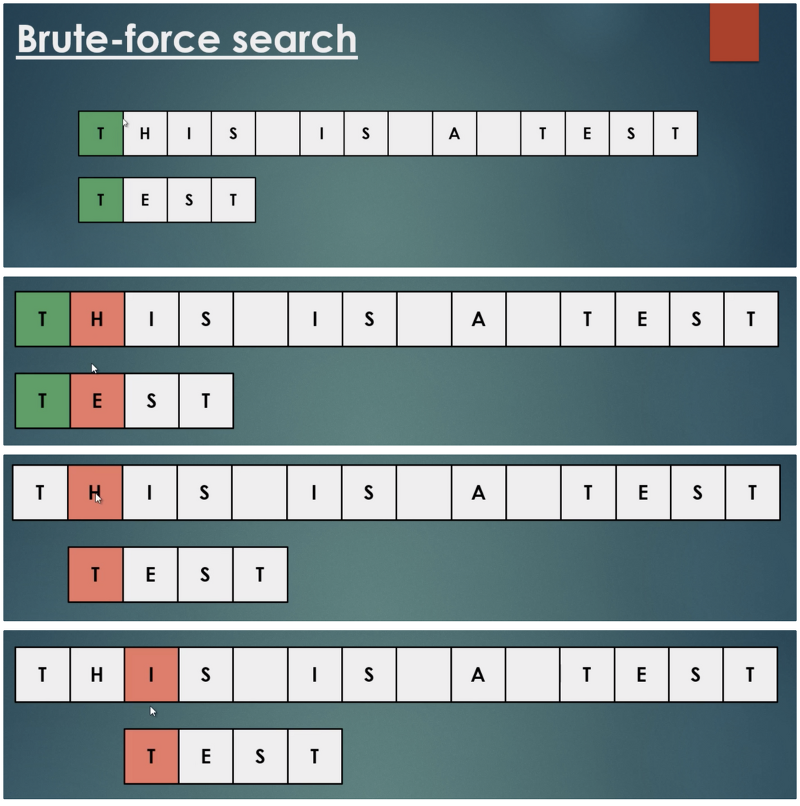 선형 검새을 단순하게 확장한 알고리즘
선형 검새을 단순하게 확장한 알고리즘
- 텍스트의 첫번째 문자에서 시작하는 문자 4개가 패턴과 일치하는 지 확인
- 일치하지 않을 경우 패턴을 오른쪽으로 한 칸 밀고, 일치할때까지 검색
- 이미 검사한 위치를 기억하지 못하고 다시 검색해야 하므로, 효율이 높지 않음.
def bf_match(txt: str, pat: str) -> int:
"""브루트 포스법으로 문자열 검색"""
pt = 0 # txt(텍스트)를 따라가는 커서
pp = 0 # pat(패턴)를 따라가는 커서
while pt != len(txt) and pp != len(pat):
if txt[pt] == pat[pp]:
pt += 1
pp += 1
else:
pt = pt - pp + 1
pp = 0
return pt - pp if pp == len(pat) else -1문자열 검색에 유용한 python 표준 라이브러리
# 포함 여부 확인
ptn in txt
ptn not in txt
# find, index 계열 함수
str.find(sub, start, end)
# 문자열 str의 start, end에 sub이 포함되면 그중에 가장 작은 인덱스 반환, or -1
str.rfind(sub, start, end)
# 문자열 str의 start, end에 sub이 포함되면 그중에 가장 큰 인덱스 반환, or -1
str.index()
#find()와 같은 기능
str.rindex()
#rfind()와 같은 기능
다만 index()계열의 method는 발견되지 않을 시에 -1이 아닌 ValueError 내보냄
#with 계열 함수
str.startswith(prefix, start, end)
# 문자열이 prefix로 시작하면 True
str.endswith(suffix, start, end))
# 문자열이 suffix로 끝나면 TrueKMP
Brute Force 방식에 비해 보다 효율적으로 검사한 결과를 사용할 수 있는 알고리즘
KMP 알고리즘
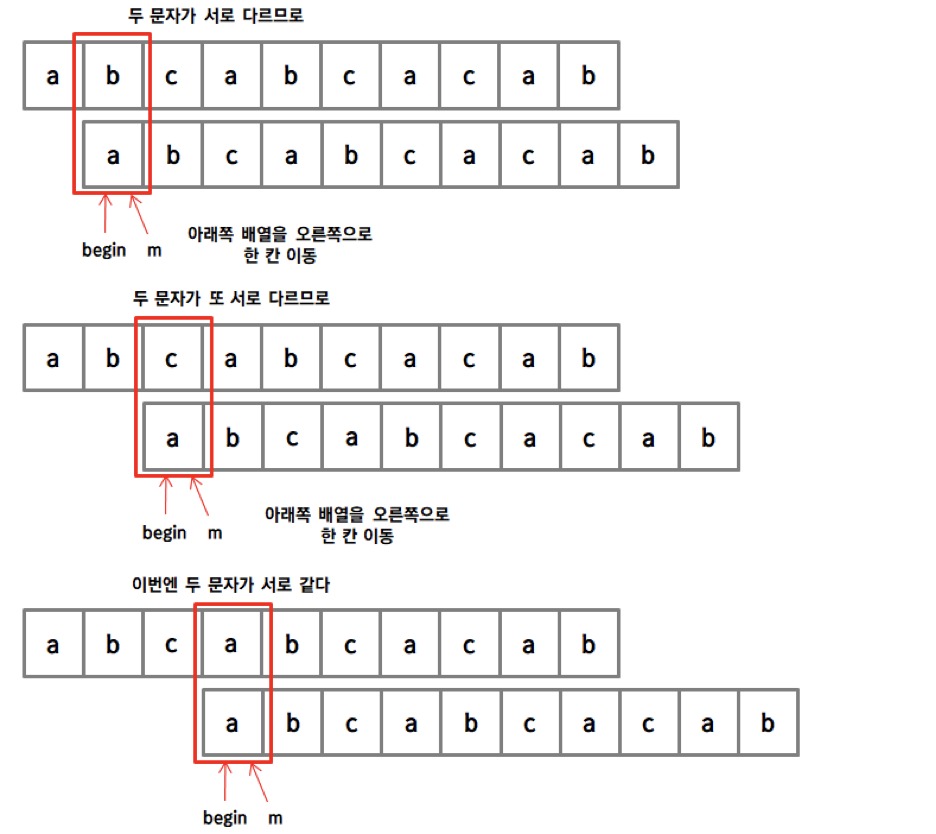
- 본문이 되는 문자열과 찾으려는 패턴은 두고, 일부가 일치하지 않는다면, 불일치한 부분을 제외한 직전까지 일치하는 패턴에서 최대 길이의 경계를 찾음
실패함수
패턴 ‘ababc’기준 
-
'a' 까지 일치하는 접두사/접미사 최대 길이 : 0 (없음)
-
'ab' 까지 일치하는 접두사/접미사 최대 길이 : 0 (없음)
-
'aba' 까지 일치하는 접두사/접미사 최대 길이 : 1 ('a')
-
'abab' 까지 일치하는 접두사/접미사 최대 길이 : 2 ('ab')
-
'ababc' 까지 일치하는 접두사/접미사 최대 길이 : 0 (없음)

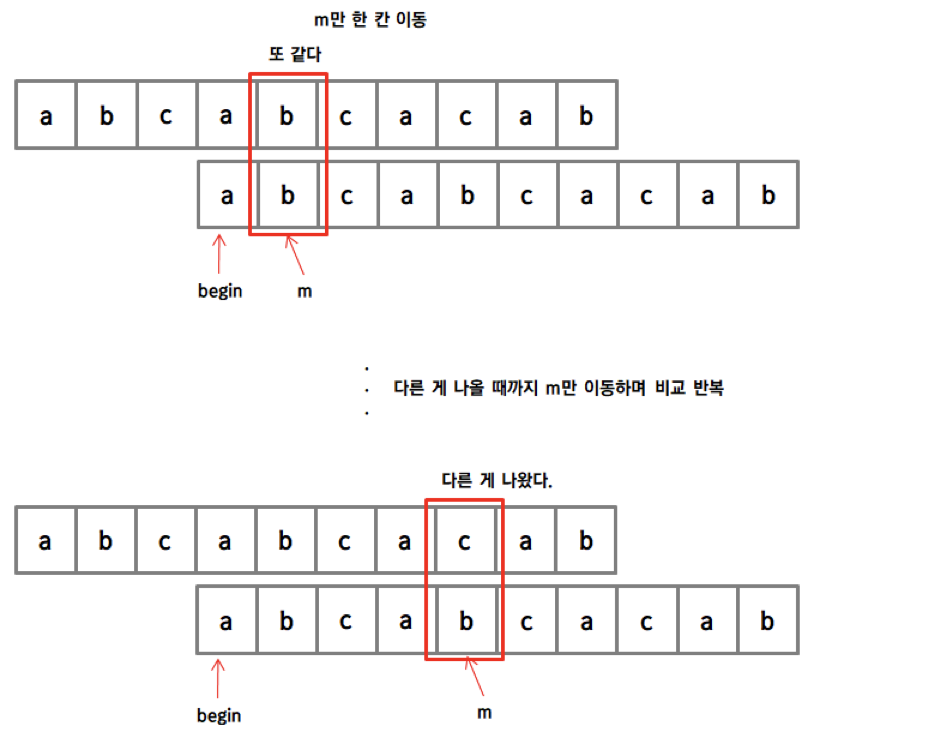
즉, 맞은 부분까지의 실패함수의 값만큼 이동!![]
def kmp_match(txt: str, pat: str) -> int:
"""KMP법에 의한 문자열 검색"""
pt = 1 # txt를 따라가는 커서
pp = 0 # pat를 따라가는 커서
skip = [0] * (len(pat) + 1) # 건너뛰기 표
# 건너뛰기 표 만들기
skip[pt] = 0
while pt != len(pat):
if pat[pt] == pat[pp]:
pt += 1
pp += 1
skip[pt] = pp
elif pp == 0:
pt += 1
skip[pt] = pp
else:
pp = skip[pp]
# 검색하기
pt = pp = 0
while pt != len(txt) and pp != len(pat):
if txt[pt] == pat[pp]:
pt += 1
pp += 1
elif pp == 0:
pt += 1
else:
pp = skip[pp]
return pt - pp if pp == len(pat) else -1보이어-무어법
Boyer-Moore algorithm(보이어-무어 알고리즘)
-
보통 상황에서 문자열은 앞부분보다는 뒷부분에서 불일치가 일어날 확률이 높다는 성질을 활용
-
불필요한 것은 건너뛰고, 검색을 빠르게!
-
패턴의 오른쪽 끝에 있는 문자와 본문을 비교하여 일치여부를 판단
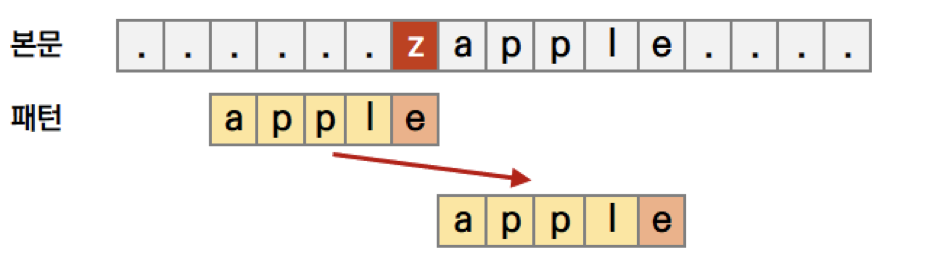
문자가 패턴에 존재하지 않는다면, 패턴의 길이만큼 이동 -
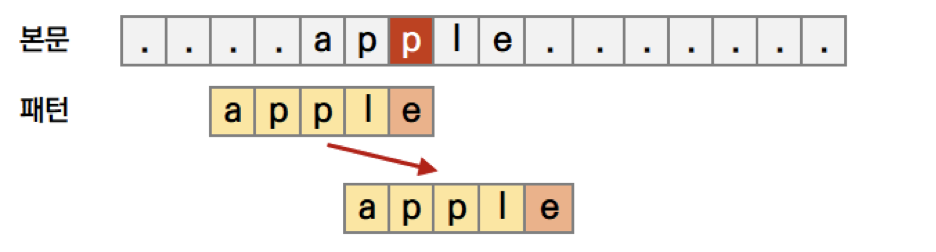 본문 문자가 패턴의 존재하지만, 중간에 불일치하는 경우, 오른쪽 끝에서 그 문자까지의 칸수를 세서 그만큼 이동
본문 문자가 패턴의 존재하지만, 중간에 불일치하는 경우, 오른쪽 끝에서 그 문자까지의 칸수를 세서 그만큼 이동
def bm_match(txt: str, pat: str) -> int:
"""보이어 무어법에 의한 문자열 검색"""
skip = [None] * 256 # 건너뛰기 표
# 건너뛰기 표 만들기
for pt in range(256):
skip[pt] = len(pat)
for pt in range(len(pat)):
skip[ord(pat[pt])] = len(pat) - pt - 1
# 검색하기
while pt < len(txt):
pp = len(pat) - 1
while txt[pt] == pat[pp]:
if pp == 0:
return pt
pt -= 1
pp -= 1
pt += skip[ord(txt[pt])] if skip[ord(txt[pt])] > len(pat) - pp \
else len(pat) - pp
return -1
Yonsei Univ. Sports Industry studies/ Computer Science / Applied Statistics