
개요
프로젝트에서 실시간 데이터 수집 파이프라인 구축할 때 참고하였던 GitHub레포지토리 내용을 바탕으로 Terraform을 이용해 Kinesis 데이터 수집 파이프라인을 구축한 내용을 담아보았습니다.
콘솔로 구축하는 과정은 지난 번 포스트를 참고해주세요.
AWS Kinesis로 API요청 정보 실시간 수집하기
이 포스팅을 통해 참고 레포지토리를 뜯어보며 자신의 상황에 적용해보는 데 있어 도움이 되었으면 좋겠습니다:)
참고 레포지토리
https://github.com/AmaraOgu/aws-data-pipelines
제가 참고했던 자료는 위의 GitHub레포지토리였습니다.
선정 이유
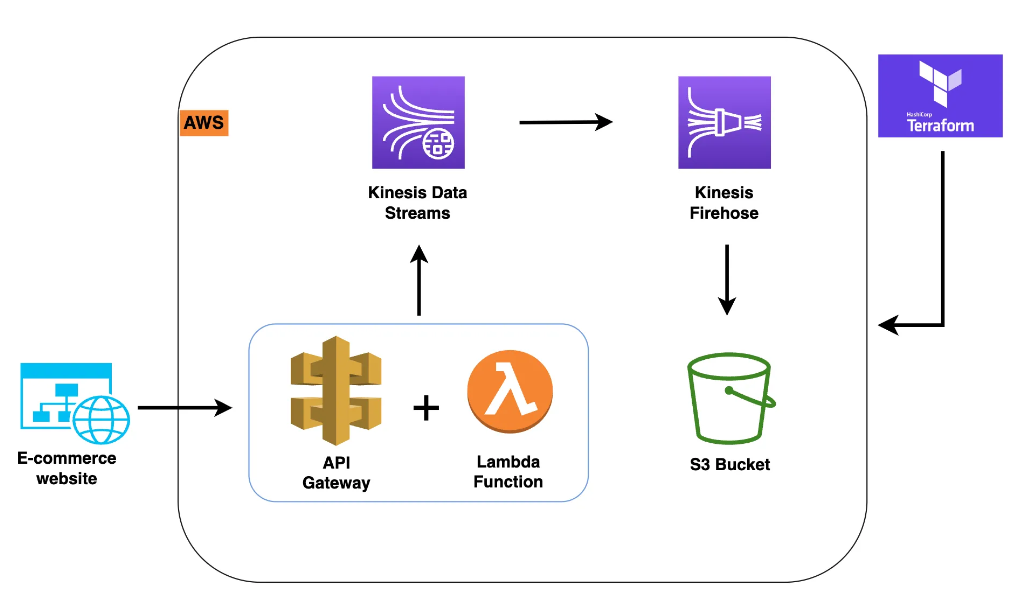
이 레포지토리에서 구축한 파이프라인의 시나리오는 웹에서 보내는 api가 API Gateway를 통하는데, 이 때 api데이터를 Kinesis로 수집하는 파이프라인이었습니다.
웹에서 보내는 api데이터를 수집하는 이 시나리오가 제가 참여중이던 프로젝트의 시나리오와 일치하여 적합하다고 판단했습니다.
시작하기
0. 프로젝트 구조
이 레포지토리에서는 Readme에 설명이 친절히 나와있습니다.
각 아키텍처에 대한 설명부터, 필요 리소스, 진행 과정에 필요한 Terraform 커맨드도 명시해주어서 README 자체로도 좋은 가이드가 되어있습니다.
그럼 프로젝트 구조부터 훑고 사전 리소스 생성, 코드 수정, 인프라 구축을 진행해봅시다.
프로젝트 구조
.
├── README.md
├── helper-resources
│ ├── process_data.py - contains Python code to be run by Lambda
│ ├── process_data.zip - contains process_data.py in a zip archive
│ └── send_to_s3.py - contains sample code to send data to s3
├── modules
│ ├── api-gateway
│ │ ├── gateway.tf - API Gateway configuration
│ │ ├── output.tf - output of the configurations
│ │ ├── permission.tf - permissions needed by the API Gateway
│ │ └── variables.tf - variables used by the API Gateway configuration
│ ├── kinesis
│ │ ├── README.MD - guide on how to use the Kinesis module
│ │ ├── kinesis_firehose.tf - Kinesis Firehose configurations
│ │ ├── kinesis_iam.tf - Kinesis Firehose IAM requirements
│ │ ├── kinesis_stream.tf - Kinesis Stream configurations
│ │ ├── output.tf - output of the configurations
│ │ └── variables.tf - variables used by the Kinesis configuration
│ ├── lambda
│ │ ├── README.MD - guide on how to use the Lambda module
│ │ ├── lambda_function.tf - Lambda function configuration
│ │ ├── lambda_iam.tf - Lambda function IAM requirements
│ │ ├── output.tf - output of the configurations
│ │ ├── permissions.tf - permissions needed by the Lambda function
│ │ └── variables.tf - variables used by the Lambda configuration
│ └── s3
│ ├── README.MD - guide on how to use the S3 module
│ ├── bucket_iam.tf - IAM configuration for the S3 bucket
│ ├── output.tf - output of the configurations
│ ├── s3_bucket.tf - S3 bucket configuration
│ └── variables.tf - variables used by the S3 configuration
└── setups
├── main.tf - configuration to build the resources
├── provider.tf - providers definition
├── terraform.tfvars - values used in building the resources
└── variables.tf - variables used by the configuration
이 파이프라인에 필요한 리소스들에 대한 내용이 modules폴더 내 각 리소스의 이름으로 구성되어있습니다.
또한 구조를 보았을 때, 필요한 모든 리소스를 통합적으로 프로비저닝할 수 있는 코드가 setups폴더 내 main.tf인 것으로 보입니다.
모듈 내 각 리소스 폴더에는 해당 리소스 설정 코드와, 다른 서비스들과의 상호작용을 위한 IAM권한 설정, 변수 등을 정의한 tf파일들이 있음을 확인할 수 있습니다.
파이프라인 구조도와, 프로젝트 구조를 통해 확인할 수 있는 프로비저닝 목록은 다음과 같이 정리할 수 있겠습니다.
- Kinesis가 쓰기를 허용하도록 구성된 S3 버킷
- Kinesis로 데이터를 보낼 수 있도록 구성된 Lambda 함수
- 데이터를 수집하도록 구성된 Kinesis 스트림
- Kinesis Stream에서 데이터를 수집하여 s3에 전달하도록 구성된 Kinesis Firehose
- Lambda 함수를 호출하도록 구성된 API Gateway
1. 필요조건 확인하기

이 레포지토리에서는 Readme를 통해 사전 필요 조건을 명시해놓을 것을 확인할 수 있습니다.
- AWS계정
- Terraform실행을 위해 미리 설치되어있어야함
- AWS 인프라 구축 시 인증을 위한 credentials설정이 되어있어야 함
위와 같이 aws인프라를 Terraform으로 프로비저닝하기 위한 기본적인 안내사항에 대해 나와있습니다.
2번의 Terraform은 저의 경우,
AWS에서 인프라 구축용이자 bastion서버로 EC2를 생성해주었습니다.
(운영체제는 default값인 Amazon Linux2)
그럼 Terraform을 이용하여 인프라 프로비저닝 작업을 완전히 EC2환경에서 끝낼 수 있기 때문입니다.
이 EC2에서 Terraform설치 및 AWS credentials설정을 해주었습니다.
Terraform 설치 가이드
AWS credentials설정 가이드
1-1. 프로젝트 코드 설치
위에서 기본적인 설정이 끝났다면, Terraform 코드 수정과 실행을 위해 레포지토리를 Clone받아옵니다.
git clone https://github.com/AmaraOgu/aws-data-pipelines.git더 살펴볼 것은?
일단 Readme에 안내되어있는 사항에 대해서는 완료했지만, 혹시 모르니 코드도 살펴봐야 합니다. (안하고 바로 코드를 돌렸다가 수많은 오류를 마주했죠)
AWS인프라는 리소스를 어느 리전에 설정할 것인지, 혹 기존 리소스와 겹치는 것은 없는 지 등을 확인하기 위해서입니다.
1-2. 메인 코드들 톺아보기
그러기 위해 Terraform apply실행 시 메인이 되는 setups폴더 내의 코드를 살펴봅시다.
1) main.tf
# Creates an S3 bucket for storing the processed data
module "data-s3-bucket" {
source = "../modules/s3"
bucket_name = var.bucket_name
}
# Creates an Amazon Kinesis data stream to send data from Lambda to S3
module "kinesis" {
source = "../modules/kinesis"
kinesis_stream_name = var.kinesis_stream_name
kinesis_firehose_name = var.kinesis_firehose_name
bucket_arn = module.data-s3-bucket.bucket_arn
depends_on = [ module.data-s3-bucket ]
}
# Deploys an lambda function that sends data to the Kinesis stream
module "lamda_function" {
source = "../modules/lambda"
function_name = var.function_name
s3_key = var.s3_key
handler = var.handler
runtime = var.runtime
timeout = var.timeout
memory_size = var.memory_size
source_bucket = var.source_bucket
kinesis_data_stream_arn = module.kinesis.kinesis_data_stream_arn
depends_on = [ module.kinesis ]
}
# deploy API Gateway
module "data_procesing" {
source = "../modules/api-gateway"
api_gateway_name = var.api_gateway_name
resource_name = var.resource_name
lambda_function_name = module.lamda_function.lambda_function_arn
lambda_function_invoke_arn = module.lamda_function.lambda_function_invoke_arn
integration_http_method = var.integration_http_method
stage_name = var.stage_name
depends_on = [ module.lamda_function ]
}이 프로젝트 코드를 통해 생성할 리소스들의 소스 코드의 위치, 리소스 이름을 정의하고 있습니다.
모듈을 통해 코드를 나눠놓았기에 main.tf에서는 하드코딩 없이 변수를 이용해서 값들을 적어놓았습니다.
main.tf는 어떤 리소스가 생성되는 지 확인만 하고 넘어가도 될 것 같습니다.
2) provider.tf
provider "aws" {
region = var.region
}
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = ">= 3.0.0"
}
}
}
provider.tf는 Terraform의 버전에 관련하여 작성한 파일인 것 같습니다.
별 내용이 없는 것처럼 보이지만, 주목할 것이 있습니다.
바로 리전입니다.
AWS는 리전별로 리소스를 생성할 수 있기 때문에, 리전 설정도 중요합니다.
여기서도 main.tf과 같이 변수를 이용하여 리전을 설정하였습니다.
그렇다면 변수가 정의된 파일을 살펴보는 것이 필요하다는 결론에 이릅니다.
3) terraform.tfvars
# Providers block
region = "us-east-1"
# Creates an S3 bucket for storing raw data
bucket_name = "product-data"
# Createing Amazon Kinesis data stream to send data from Lambda to S3
kinesis_stream_name = "demo-datastream"
kinesis_firehose_name = "demo_firehouse"
# Deploying an lambda function that sends data to the Kinesis stream
function_name = "run_data_processing"
s3_key = "process_data.zip"
handler = "process_data.lambda_handler"
runtime = "python3.8"
timeout = 60
memory_size = 128
source_bucket = "helper-bucket123"
# Deploying API Gateway
api_gateway_name = "data-processing"
resource_name = "product"
integration_http_method = "POST"
stage_name = "dev"찾고 있었던 변수들이 바로 여기에 정의되어있었습니다!
리전 설정 변경
region변수에 현재 us-east-1이라는 값이 들어가 있으니, 이 리전을 서울 리전값인 ap-northeast-2로 변경해줍니다.
# Providers block
region = "ap-northeast-2"S3 버킷 이름 수정
리전 변수 아래, 이 파이프라인에서 필요한 S3의 버킷 이름도 설정되어있습니다.
AWS S3를 몇 번 사용해보신 분은 바로 알아채시겠지만,
S3의 경우, 글로벌 범위에서 유일한 이름을 가져야하기 때문에 리전을 바꿔준다고 해도 저 이름을 그대로 쓸 수 없습니다.(이미 만들었을 것이기 때문이죠)
버킷명 위의 주석으로 이 버킷의 이름은 새로 만들어지는 버킷의 이름이니, 전 세계에서 겹치지 않을만한 이름으로 값을 수정해줍니다.
Lambda 소스용 S3버킷 설정
이제 다른 리소스들의 이름은 겹쳐도 괜찮은 것들입니다. 하지만 그 중 S3가 또 보이는 부분이 있는데요, 바로 Lambda함수 관련된 부분인 4번째 블록에서 source_bucket부분입니다.
# Deploying an lambda function that sends data to the Kinesis stream
function_name = "run_data_processing"
s3_key = "process_data.zip"
handler = "process_data.lambda_handler"
runtime = "python3.8"
timeout = 60
memory_size = 128
source_bucket = "helper-bucket123" 살펴보면, source_bucket과 s3_key라는 변수명을 통해 Lambda함수의 코드를 이 버킷의 process_data.zip에서 가져와 사용한다는 것을 유추할 수 있습니다.
그대로 사용해도 괜찮지만, 저 버킷은 이 레포지토리 작성자가 만든 버킷이기에 저 버킷에 람다 함수인 process_data.zip이 없다면 완전한 파이프라인을 구축할 수 없으니, 완전히 제가 관리할 수 있도록 새로 생성해주는 것이 좋을 것 같습니다.
1-3. 정리
이로서 필요조건은 다음과 같이 6개로 정리됩니다.
- AWS계정
- Terraform실행을 위해 미리 설치되어있어야함
- AWS 인프라 구축 시 인증을 위한 credentials설정이 되어있어야 함
- terraform.tfvars에서 region값 서울(ap-northeast-2)로 변경
- terraform.tfvars에서 S3버킷 명 유니크한 새 이름으로 설정
- terraform.tfvars에서 Lambda코드 저장용 S3버킷 생성 및 해당 이름으로 설정 필요
5번까지는 커맨드 상에서 가능했지만, Lambda 코드 저장용 S3버킷 생성은 따로 해줘야 하므로 콘솔에서 미리 생성&람다 코드 버킷에 저장 후에, 이 버킷 이름을 terraform.tfvars에 넣어줘야 합니다.
이는 다음 포스팅에서 사전 리소스 구축 및 Terraform실행, 테스트에서 이어서 다루도록 하겠습니다.
