안녕하세요 에디입니다.
최근 3-Tier 웹서비스의 인프라 구성 프로젝트를 진행하다, 실시간 랭킹 기능을 위한 실시간 데이터 수집 파이프라인을 구축할 일이 있었습니다.
AWS의 Kinesis를 이용하여 구축한 파이프라인에 대해 정리해볼 겸 Kinesis는 뭔지와, 데이터 수집 파이프라인의 구성방법에 대해 작성했습니다.
Amazon Kinesis
실시간으로 데이터 스트림을 수집, 처리, 분석해주는 AWS의 완전관리형 서비스
보통 실시간 데이터 수집 서비스라 하면 Kafka를 많이 들어보셨을 겁니다.
Kinesis도 이와 비슷하게 실시간으로 대규모의 데이터 스트림을 수집하고 처리해주는 AWS의 서비스입니다.
AWS 완전관리형 서비스이기에, Kinesis용 서버를 따로 관리할 필요 없이 서비스를 이용할 수 있습니다.
이는 대규모 데이터 수집에도 큰 이점으로 다가옵니다.
보통의 서버는 처리량이 높아지면 과부화되어 다운되는 것을 막기 위해 사용량에 따라 스펙이나 개수를 늘리는 오토스케일링을 적용하는 등의 관리가 필요합니다.
하지만 완전관리형 서비스는 이 관리를 AWS가 전담하고, 사용자는 그저 사용만 하면 되므로 관리 포인트가 줄고, 편리하고 안정적인 인프라를 구성할 수 있습니다.
이러한 Kinesis는 AWS환경에 최적화된 서비스이기에 인프라 구성과 운영 시 높은 편의성을 제공합니다.
Kinesis 종류
Kinesis는 수집, 처리, 분석을 담당하는 하위 서비스로 나뉘어있습니다.
- Data Streams - 데이터 스트림 수집 및 저장
- Data Firehose - 데이터 스트림 처리 및 전송
- Data Analytics - 스트리밍 데이터 분석 / 실시간 분석 생성 / 실시간 대시보드 제공 / 실시간 지표 생성
- Video Streams - 재생 및 분석을 위해 미디어 스트림을 캡처, 저장 및 처리
Kinesis를 쓴 이유?
왜 유명한 Kafka를 쓰지 않고 Kinesis를 쓴 이유는, 편의성의 이유가 컸습니다.
Kafka와 달리 Kinesis는 AWS완전관리형 서비스라 직접 Kinesis용 서버를 관리할 필요가 없기 때문입니다.
연동성 측면에서도, API관리를 AWS의 API Gateway를 이용하여 관리하고 있었기 때문에, 이와 연동하면 쉽게 api요청의 정보를 수집할 수 있을 것이라 판단했습니다.
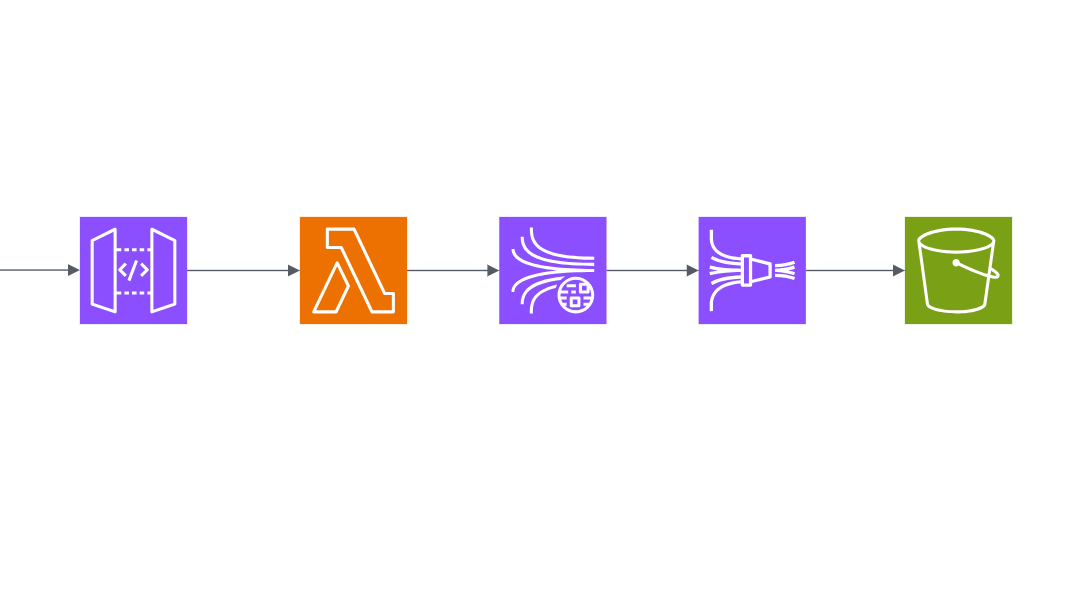
api요청을 수집하기 위한 아키텍처

구성은 간단합니다. Lambda가 API Gateway에 들어오는 요청을 트리거해서 Kinesis로 보내주면, Data stream(수집) => Firehose(처리 및 전송)를 거쳐 S3에 저장됩니다.
aws콘솔로 구축해보기(feat. API Gateway)
우선 이 구성은 서비스용 api가 미리 있다고 가정합니다! 또한 이 api는 AWS의 API Gateway에 등록되어있어야 합니다.
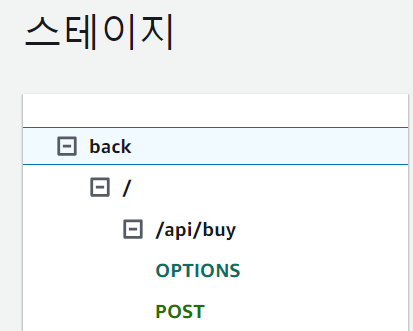
이런 식으로 배포되어 스테이지에서 확인 가능한 api가 있어야 합니다.
Kinesis Data Stream 생성
우선 데이터 수집을 위한 Kinesis Data Stream을 생성해줍시다.
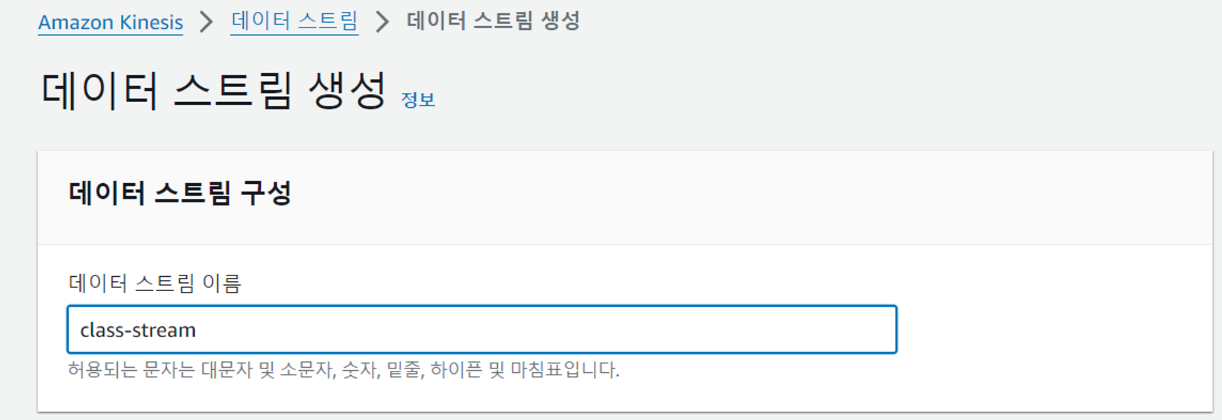
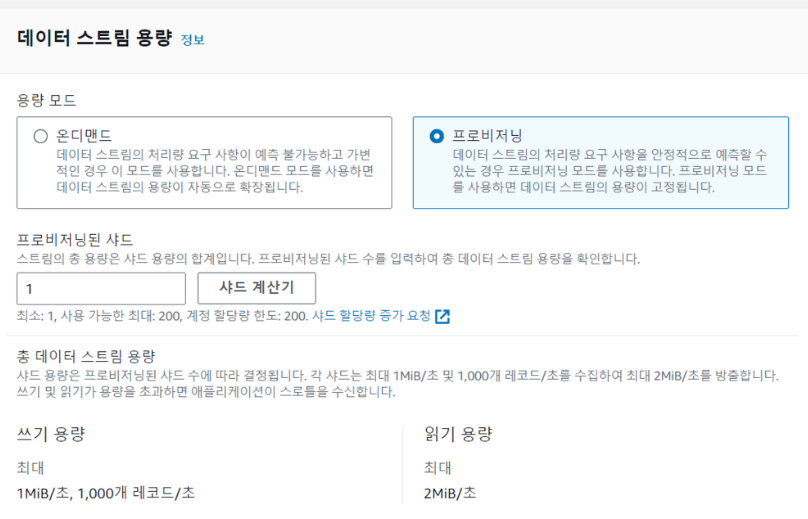
저의 경우 꾸준한 중~대규모 트래픽의 경우를 생각하여 용량 모드를 프로비저닝 모드로 했지만, 실습을 위해 잠깐의 데이터만 수집한다면 사용량에 따라 비용을 내는 온디맨드 방식을 선택해주시면 됩니다.
S3 생성
이제 데이터를 저장할 S3를 생성해줍니다.
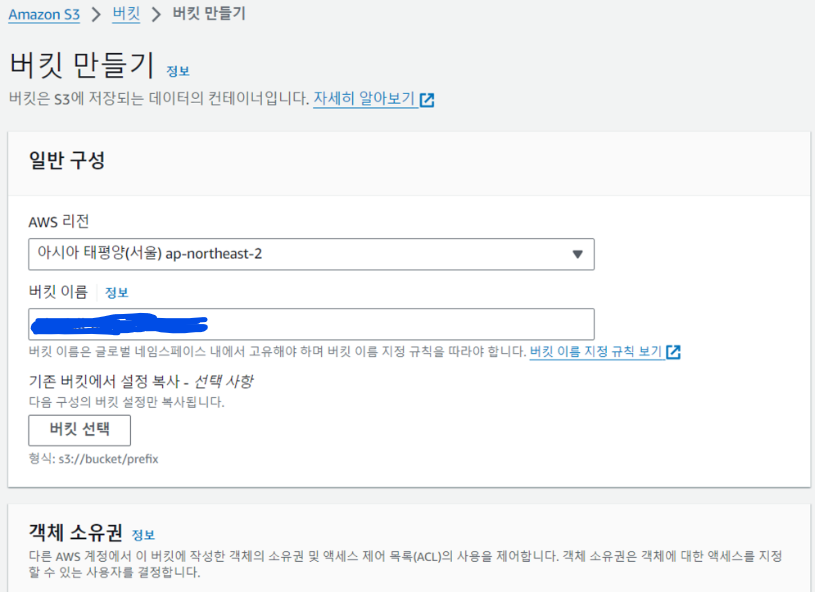
이 때 S3는 전 세계 공통으로 고유한 이름이어야 합니다. 리전 상관없이 다른 S3버킷과 이름이 겹칠 수 없습니다.
Kinesis Firehose 생성
이제 수집된 데이터를 저장소에 전송해줄 Firehose 스트림을 생성합니다.
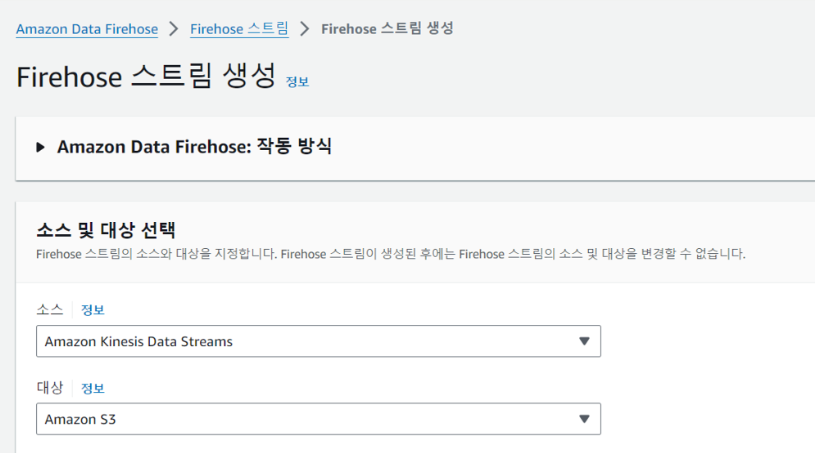
데이터의 소스는 Kinesis Data Streams으로, 데이터를 저장할 대상은 S3로 선택해줍니다.
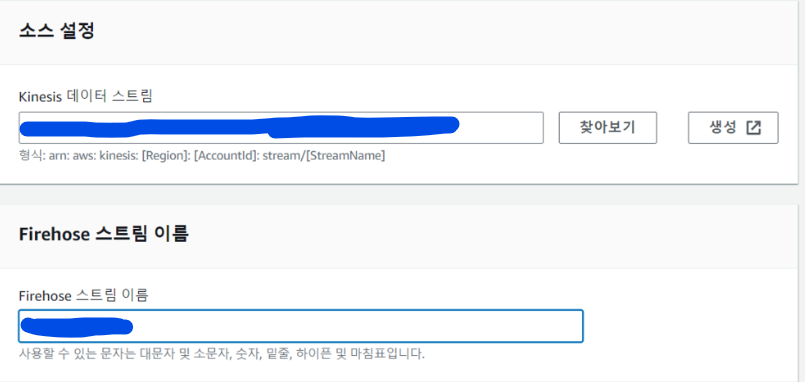
찾아보기 버튼을 눌러 위에서 생성한 kinesis data stream의 arn을 넣어줍니다.
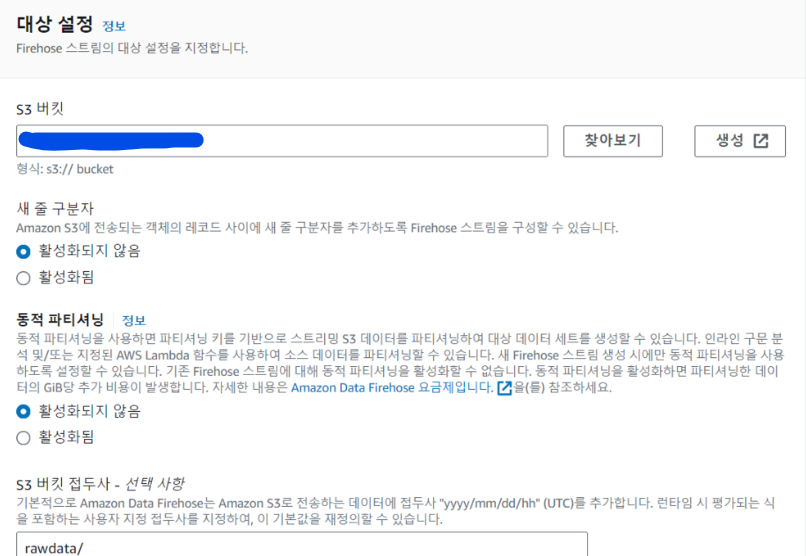
S3도 똑같이 생성했던 S3를 선택하여 arn주소를 넣어주고, api요청으로 오는 데이터를 받아볼 것이니 S3 버킷 접두사에 rawdata/로 설정해줍니다.
Lambda 생성
이제 API Gateway가 api를 요청할 때마다 Kinesis에 보내주는 Lambda를 생성해줍니다.
런타임은 Python으로 하여 람다 함수를 행성해줍니다.
import json
import boto3
def lambda_handler(event, context):
# Extract the required fields from the API Gateway event
if 'body' in event:
event = json.loads(event['body'])
else:
event = json.loads(event['Records'][0]['body'])
# Extract the required fields
# required_fields = ['id', 'title', 'price', 'category']
required_fields = ['id', 'title', 'price', 'category', 'name', 'phone', 'address', 'quantity', 'item_id', 'item_name']
processed_data = {field: event.get(field) for field in required_fields}
# Convert the processed data to JSON
processed_data_json = json.dumps(processed_data)
# Encode the data as a byte string
encoded_data = processed_data_json.encode('utf-8')
# Create a Kinesis client
kinesis_client = boto3.client('kinesis')
# Send the processed data to the Kinesis stream
response = kinesis_client.put_record(
StreamName='demo-datastream', #replace with your Kinesis stream name
Data=encoded_data,
PartitionKey='partition_key'
)
return {
'statusCode': 200,
'headers': {
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'OPTIONS,POST,GET'
},
'body': 'Processed Data sent to Kinesis stream successfully.'
}
api gateway에서 오는 데이터를 Kinesis에 보내고, Kinesis에서 오는 응답을 되돌려주는 이 코드를 함수 코드 소스에 작성해주고, Deploy해줍니다.
마지막으로 api요청을 감지하여 Lambda를 작동시킬 트리거를 생성하면 됩니다.
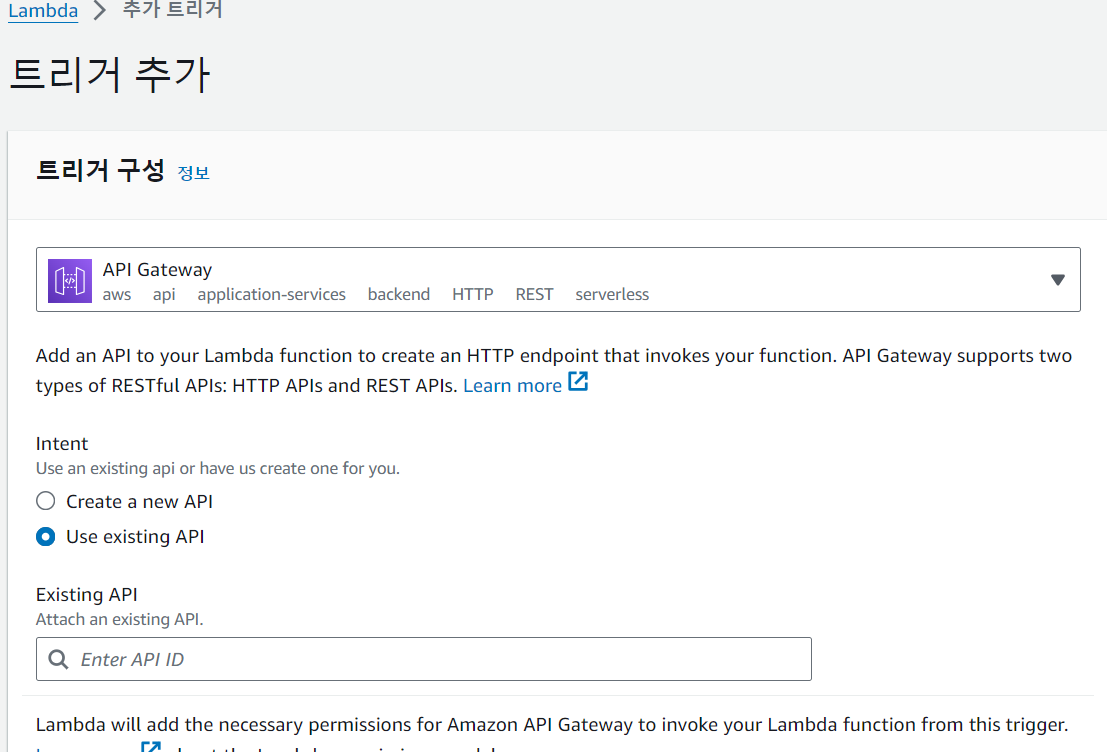
함수 개요 > 트리거 추가에서, 기존의 API를 선택해야하니
Use existing API를 선택하고, 하단의 API ID 검색창을 클릭하면 현재 API Gateway에 연결된 API 목록들이 나올겁니다.
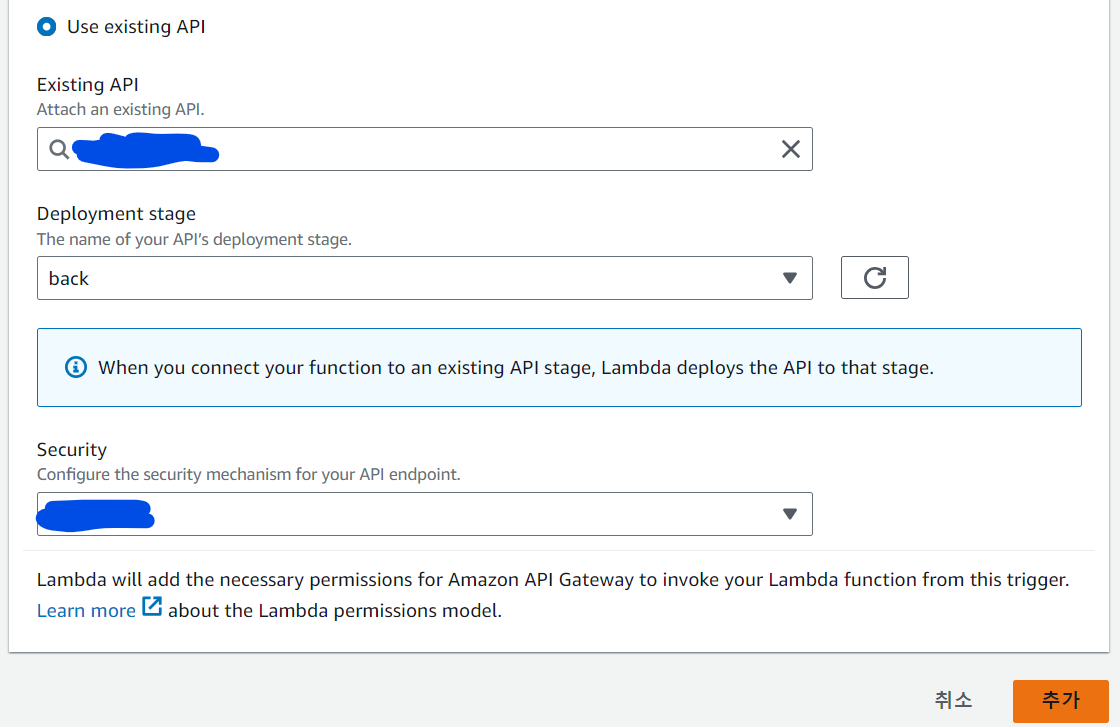
여기서 수집하고자 하는 API를 선택한 후, API배포가 이루어진 스테이지를 선택 후 Security는 Open으로 선택하여 추가를 눌러 트리거를 추가해줍니다.

트리거를 추가하면 API엔드포인트가 발급되고, 배포된 해당 스테이지 환경에도 이 엔드포인트가 추가된 것을 확인할 수 있습니다.
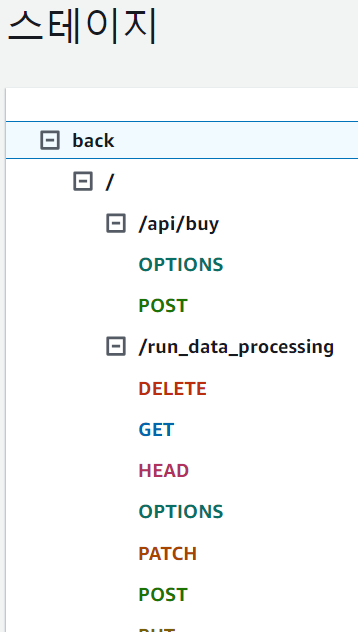
API의 스테이지에 트리거용 메서드 run_data_processing이 잘 추가되어 있습니다.
이 엔드포인트를, api를 요청하는 로직에 이 엔드포인트에도 추가해주면 파이프라인 구축 완성입니다.
저의 경우 구매에 대한 POST요청을 보내는 로직을 run_data_processing의 엔드포인만 바꿔 둘 다 보내는 방식으로 진행했습니다.
결과
구매 요청 보낸 결과
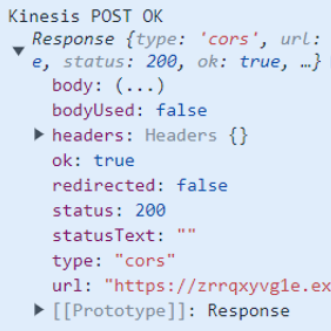
console log로 응답 데이터를 찍어보니 Lambda에서 데이터 전송 성공 시 반환하는 메세지가 뜬 것이 확인됐습니다.
데이터 저장 결과
Kinesis로 성공적으로 보내진 데이터가 S3에도 잘 도착했는지 확인해봅시다.


S3내에 데이터가 저장 되었습니다! 다운받아 파일을 열어보면 POST요청 보낼 때 담았던 데이터대로 잘 저장되는 것을 확인할 수 있습니다.
마무리
조금은 생소할 수 있는 AWS Kinesis로 간단하게 api요청의 정보를 수집하고 저장하는 파이프라인 구축에 대해 다뤄보았습니다.
이 글에서는 Kinesis를 이용한 데이터 수집까지만 다루고 있지만, 분석 서비스인 Kinesis Analytics를 이용한다면 Kinesis를 여러 방면으로도 활용해보는 것도 좋을 것입니다.
