심화 프로젝트 첫날.
학습이 선행이 되어야 프로젝트를 할 수 있는데 너무 놀았나보다.
데이터와 주제까지 주니까 플젝인지 과제인지 헷갈리더라.
분석 프로세스 중 데이터 전처리, EDA, 모델링(M/L)을 배운거고,
ML 공부했다고 프로세스를 놓치면 안된다는 걸 잊어버렸다.
<범주형 데이터 전처리 - 인코딩(Encoding)>
인코딩 : 숫자가 아닌 데이터를 숫자로 바꿈
- 레이블 인코딩(Label Encoding)
- 정의: 문자열 범주형 값을 고유한 숫자로 할당
- 1등급 → 0 / 2등급 → 1 / 3등급 → 2
- 특징
- 장점: 모델이 처리하기 쉬운 수치형으로 데이터 변환
- 단점: 실제로는 그렇지 않은데, 순서 간 크기에 의미가 부여되어 모델이 잘못 해석 할 수 있음
- 정의: 문자열 범주형 값을 고유한 숫자로 할당
- 원-핫 인코딩(One-Hot Encoding)
- 정의: 각 범주를 이진 형식으로 변환하는 기법
- 빨강 → [1,0,0]
- 파랑 → [0,1,0]
- 초록 → [0,0,1]
- 특징
- 장점: 각 범주가 독립적으로 표현되어, 순서가 중요도를 잘못 학습하는 것을 방지, 명목형 데이터에 권장
- 단점: 범주 개수가 많을 경우 차원이 크게 증가(차원의 저주) , 모델의 복잡도를 증가, 과적합 유발
- 정의: 각 범주를 이진 형식으로 변환하는 기법
<수치형 데이터 전처리 - 스케일링(Scaling)>
스케일링 : 수치형 자료에 대한 전처리
머신러닝의 학습에 사용되는 데이터들은 서로 단위 값이 다르기 때문에 이를 보정
-
표준화(Standardization)
- 각 데이터에 평균을 빼고 표준편차를 나누어 평균을 0 표준편차를 1로 조정하는 방법
- 수식
- 함수:
sklearn.preprocessing.StandardScaler - 특징
- 장점
- 이상치가 있거나 분포가 치우쳐져 있을 때 유용.
- 모든 특성의 스케일을 동일하게 맞춤. 많은 알고리즘에서 좋은 성능
- 단점
- 데이터의 최소-최대 값이 정해지지 않음.
- 장점
-
정규화(Normalization)
- 정의: 데이터를 0과 1사이 값으로 조정(최소값 0, 최대값 1)
- 수식
- 함수:
sklearn.preprocessing.MinMaxScaler - 특징
- 장점
- 모든 특성의 스케일을 동일하게 맞춤
- 최대-최소 범위가 명확
- 단점:
- 이상치에 영향을 많이 받을 수 있음(반대로 말하면 이상치가 없을 때 유용)
- 장점
-
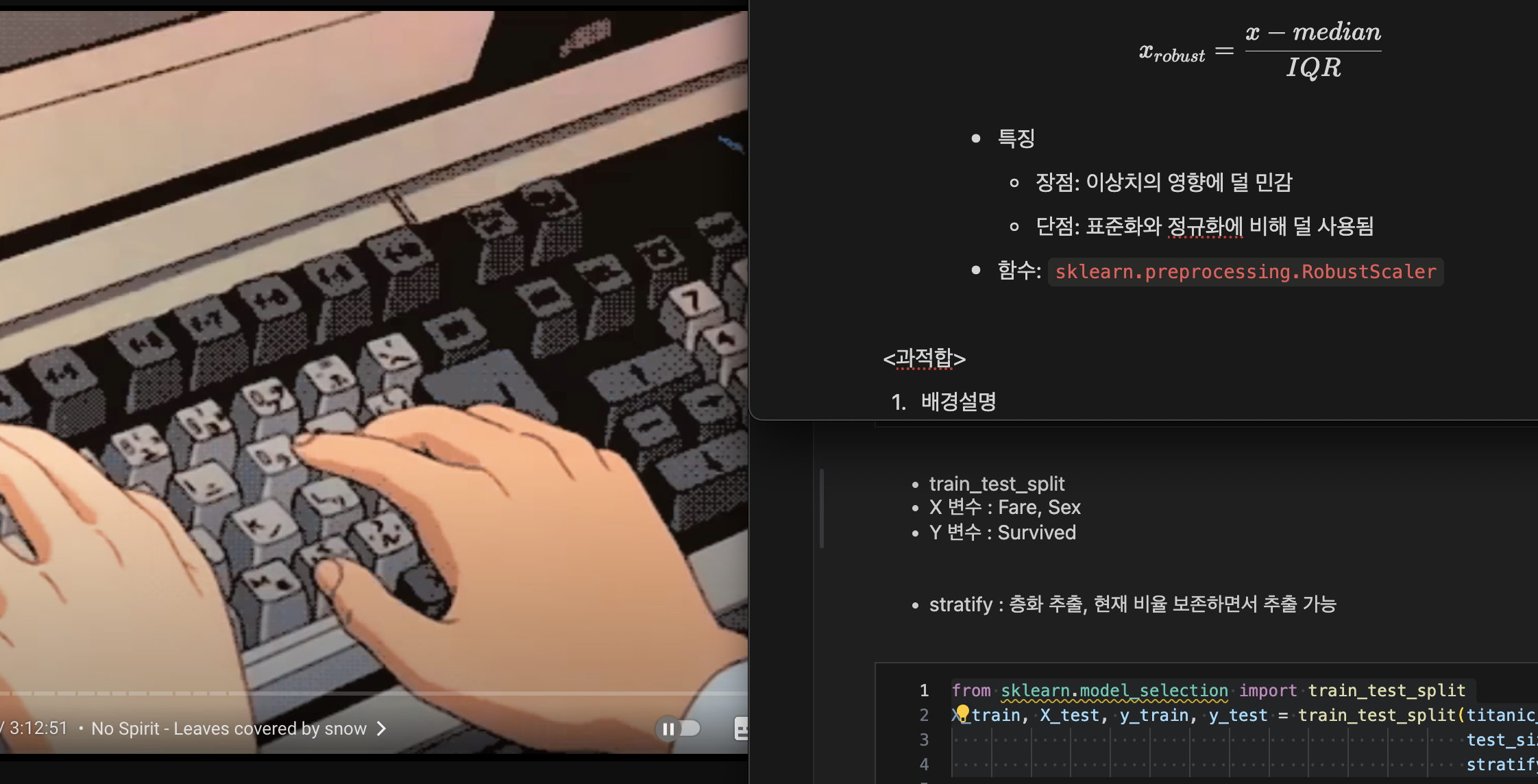
로버스트 스케일링(Robust Scaling)
- 정의: 중앙값과 IQR을 사용하여 스케일링.
- 수식
- 특징
- 장점: 이상치의 영향에 덜 민감
- 단점: 표준화와 정규화에 비해 덜 사용됨
- 함수:
sklearn.preprocessing.RobustScaler
<과적합>
- 배경설명
과대적합(Overfitting) : 데이터를 너무 과도하게 학습한 나머지 해당 문제만 잘 맞추고 새로운 데이터를 제대로 예측 혹은 분류하지 못하는 현상
- 예측 혹은 분류를 하기 위해서 모형을 복잡도를 설정
- 모형이 지나치게 복잡할 때 : 과대 적합
- 모형이 지나치게 단순할 때: 과소 적합
- 과적합의 원인
- 모델의 복잡도(상기의 예시)
- 데이터 양이 충분하지 않음
- 학습 반복이 많음(딥러닝의 경우)
- 데이터 불균형(정상환자 - 암환자의 비율이 95: 5)
과적합 해결 - 테스트 데이터의 분리
- 학습 데이터(Train Data): 모델을 학습(
fit)하기 위한 데이터 - 테스트 데이터(Test Data): 모델을 평가 하기 위한 데이터
- 함수 및 파라미터 설명
sklearn.model_selection.train_test_split- 파라미터
test_size: 테스트 데이터 세트 크기train_size: 학습 데이터 세트 크기shuffle: 데이터 분리 시 섞기(랜덤성 추가)random_state: 호출할 때마다 동일한 학습/테스트 데이터를 생성하기 위한 난수 값. 수행할 때 마다 동일한 데이터 세트로 분리하기 위해 숫자를 고정 시켜야 함
- 파라미터
- 반환 값(순서 중요)
X_train,X_test,y_train,y_test
인코딩
titanic_df.head(3)
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
le = LabelEncoder()
oe = OneHotEncoder()
le.fit(titanic_df[['Sex']])
le.classes_
titanic_df['Sex_le'] = le.transform(titanic_df[['Sex']])
titanic_df.head(3)
oe.fit(titanic_df[['Embarked']])
oe.categories_
oe.transform(titanic_df[['Embarked']])
#sparse matrix : 데이터가 희박함 (CSR)
embarked_csr = oe.transform(titanic_df[['Embarked']])
embarked_csr_df = pd.DataFrame(embarked_csr.toarray(), columns = oe.get_feature_names_out())
embarked_csr_df.head(3)
#concat으로 합치기
pd.concat([titanic_df, embarked_csr_df], axis = 1)스케일링
sns.pairplot(titanic_df[['Age', 'Fare']])
titanic_df[['Age', 'Fare']].describe()
#Age : MinMaxScaler, Fare : StandardScaler
from sklearn.preprocessing import MinMaxScaler, StandardScaler
mm_sc = MinMaxScaler()
sd_sc = StandardScaler()
titanic_df['Age_mean_mm_sc'] = mm_sc.fit_transform(titanic_df[['Age_si_mean']])
titanic_df.head(3)
titanic_df['Fare_sd_sc'] = sd_sc.fit_transform(titanic_df[['Fare']])
titanic_df.head(3)
sns.histplot(titanic_df['Age_mean_mm_sc'])
sns.histplot(titanic_df['Fare_sd_sc'])
titanic_df.head(3)데이터 분리
- train_test_split
- X 변수 : Fare, Sex
- Y 변수 : Survived
- stratify : 층화 추출, 현재 비율 보존하면서 추출 가능
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(titanic_df[['Fare', 'Sex']], titanic_df[['Survived']],
test_size=0.3, shuffle= True, random_state=42,
stratify=titanic_df[['Survived']])
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
#원자료 891개 Y값의 분포
sns.countplot(titanic_df, x = 'Survived')
sns.countplot(y_train, x = 'Survived')
sns.countplot(y_test, x = 'Survived')내일은 오전에 회의(분석 프로세스, EDA 정리)하고 심화 나머지 들어야겠다.
잘못되어간다는 건 아는데,,, 할 줄 아는 게 없어서 손 놓고 있는 찝찝함을 반복할 순 없5,,,
선택과 집중
당장 선택하기 곤란
선택 모대서 집중도 모담
집중 안하다가 오만가지 와장창
선택 햇스면 까불지 말구 집중 🥱

Data Analysis / 맨 땅에 헤딩