본격적으로 채용공고 프로젝트를 진행하기 전, Animation 데이터로 추천 알고리즘을 맛보고자 실습 진행.
손코딩을 해도 논리를 이해하지 못했으나.. 시도를 했다는 점에.. 박수...
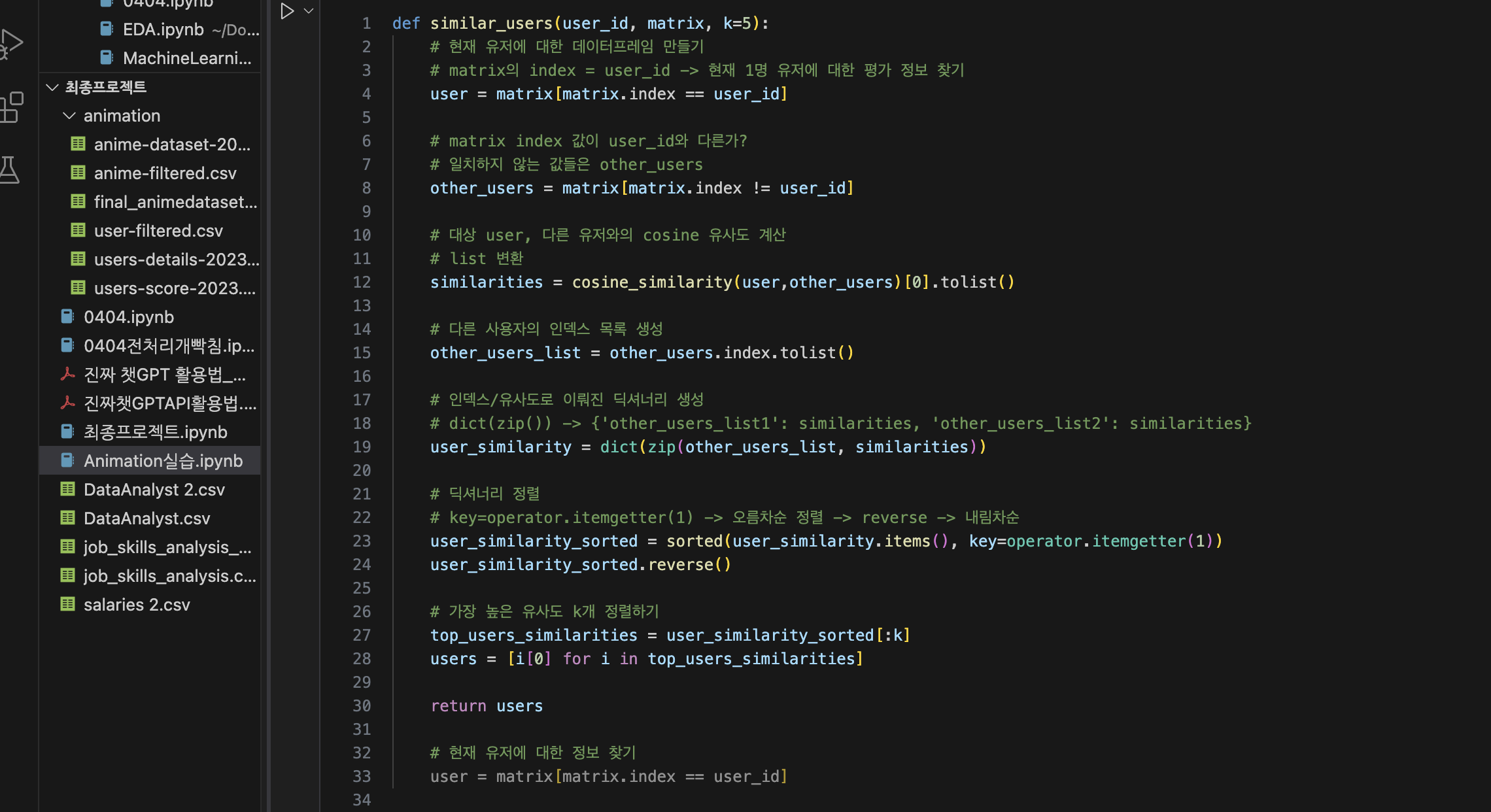
사용자 기반 협업 필터링
협업 필터링: 사람들의 행동 기록을 분석하다‘협업 필터링’이란 특정 집단에서 발생하는 ‘유사한 사용행동’을 파악하여, 비슷한 성향의 사람들에게 아이템을 추천하는 기술.
협업 필터링은 성향이 비슷하면, 선호하는 것도 비슷할 것이라는 가정을 전제로 한다.
협업 필터링은 사용자 기반 협업 필터링(User-based CF), 아이템 기반 협업 필터링(Item-based CF)으로 구분된다.
사용자 기반 협업 필터링나와 성향이 비슷한 사람들이 사용한 아이템을 추천해 주는 방식이다.
예를 들어, 사용자 A가 온라인 몰에서 선크림과 튜브, 그리고 수영복 함께 구매하고, 또 다른 사용자 B는 선크림과 튜브를 구매했다고 가정했을 때, 알고리즘은 구매 목록이 겹치는 이 두 사용자가 유사하다고 판단하여 사용자 B에게 수영복을 추천한다.
# 라이브러리 설정
import random
import pandas as pd
import statistics
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
import operator#데이터 불러오기
#animation : anime_filter / user_score : users_score
animation = pd.read_csv('/Users/yejin/Desktop/최종프로젝트/animation/anime-filtered.csv')
user_score = pd.read_csv('/Users/yejin/Desktop/최종프로젝트/animation/users-score-2023.csv')animation : anime_id, 제목, 장르, 작품 등급, 시청 타입, 에피소드 개수, 평균 평점, 시청자수 등이 기록.
user_score : user_id,해당 사용자가 평가한 anime_id, rating 점수 기록.
콘텐츠 평가 유저 수/평가된 콘텐츠 수 확인하기
#각 유저가 평가한 컨텐츠 수
# 콘텐츠를 평가한 유저 숫자
rating_per_user = user_score.groupby('user_id')['rating'].count()
statistics.mean(rating_per_user.tolist())
# 유저별 평점 개수의 분포
rating_per_user.hist(bins=20, range=(0,1000)) 각 컨텐츠가 받은 평가의 수
# 콘텐츠별 평가된 평점 등급
ratings_per_anime = user_score.groupby('anime_id')['rating'].count()
statistics.mean(ratings_per_anime.tolist())
# 콘텐츠별 평가된 빈도
ratings_per_anime.hist(bins=30, range=(0,5000))데이터 전처리 ('rating'값 확인 / 유효값 필터링)
# 'rating' 컬럼 값이 -1인 데이터를 확인합니다.
rating_minus_one = user_score[user_score['rating'] == -1]
rating_minus_one
print("Rating 컬럼의 값이 -1인 데이터 개수:", rating_minus_one.shape[0])
# 'rating' 컬럼의 값 별 개수를 확인합니다.
rating_counts = user_score['rating'].value_counts()
# 결과 출력
rating_counts
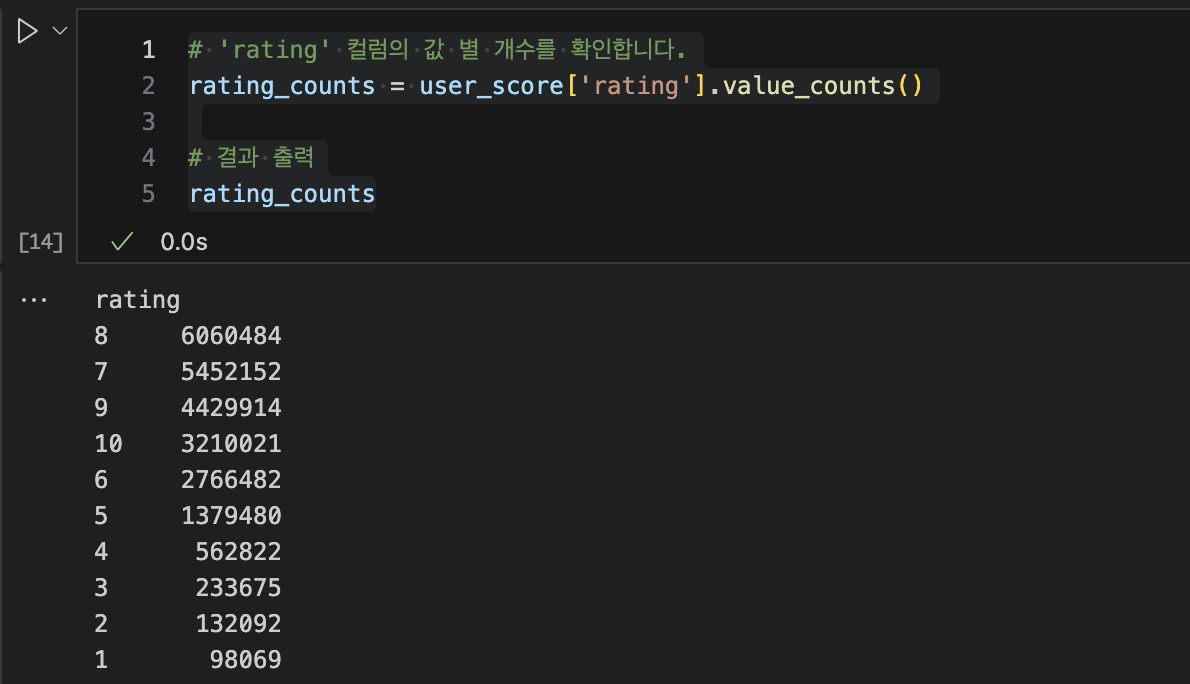
참고 블로그에서는 -1, 0 값을 바꿔주는 작업을 했지만 현재 데이터에 '-1', '0'값이 없으므로 필요 없다.
유효값 필터링
# 'anime_id' 컬럼의 고유한 값의 개수를 세어줍니다.
unique_anime_ids = user_score['anime_id'].nunique()
# 결과 출력
print("anime_id 컬럼의 고유한 값의 개수:", unique_anime_ids)# 너무 적게 평가된 콘텐츠 제거
ratings_per_anime_df = pd.DataFrame(ratings_per_anime)
# 평점 개수가 50개 이하 콘텐츠 제거
filtered_ratings_per_anime_df = ratings_per_anime_df[ratings_per_anime_df.rating >= 50]
print(filtered_ratings_per_anime_df)
# list 변환
popular_anime = filtered_ratings_per_anime_df.index.tolist()
# 남은 콘텐츠의 수 확인
num_filtered_anime = filtered_ratings_per_anime_df.shape[0]
print("평점 개수가 50개 이상인 콘텐츠 수:", num_filtered_anime)
### 기존 컨텐츠 수 : 16500 / 평점 50개 이상인 컨텐츠 수 :9239 / 약 7000개 제거# 'user_id' 컬럼의 고유한 값의 개수를 세어줍니다.
unique_user_ids = user_score['user_id'].nunique()
# 결과 출력
print("user_id 컬럼의 고유한 값의 개수:", unique_user_ids)
# 너무 적게 평가한 유저 제거
rating_per_user_df = pd.DataFrame(rating_per_user)
# 평점 데이터 30개 이하일 경우 제거
filtered_rating_per_user_df = rating_per_user_df[rating_per_user_df.rating >= 30]
rating_users = filtered_rating_per_user_df.index.tolist()
# 남은 유저의 수 확인
num_filtered_user = filtered_rating_per_user_df.shape[0]
print("평점 개수가 30개 이상인 유저 수:", num_filtered_user)
### 기존 유저 : 270033 / 평점 30개 이상인 유저 : 144459 / 약 12만 유저 제거위의 두 코드로 너무 적게 평가한 사용자(30개 미만으로 평가한 사용자)와 너무 적은 평가를 받은 작품(50개 미만의 평점을 받은 작품)을 제거하여 추천 결과의 신뢰도를 높인다.
콘텐츠 1개당 평점의 개수평균은 697.3.
평점 데이터가 적은 작품을 제거하는 이유는 유사한 user를 탐색하는데 정확도가 떨어질 수 있고,
엉뚱한 작품을 추천하는 것을 방지하기 위함이다.
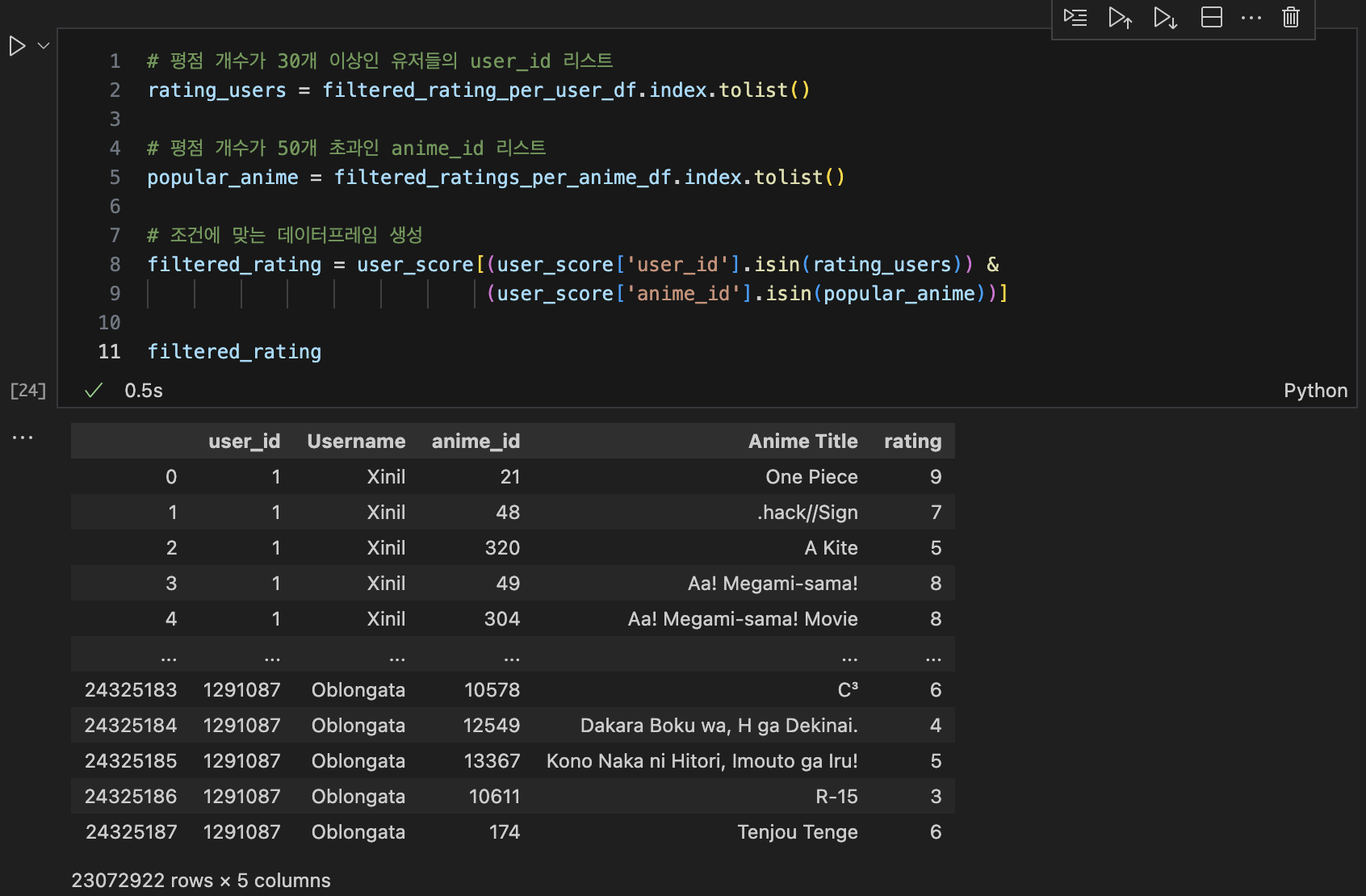
전처리 끝난 데이터들로 'filtered rating'데이터프레임 생성
피벗테이블 생성
# 피벗테이블 만들기
rating_matrix = filtered_rating.pivot_table(index='user_id', columns='anime_id', values='rating')
# 결측치 제거
rating_matrix = rating_matrix.fillna(0)
rating_matrix.shape
rating_matrix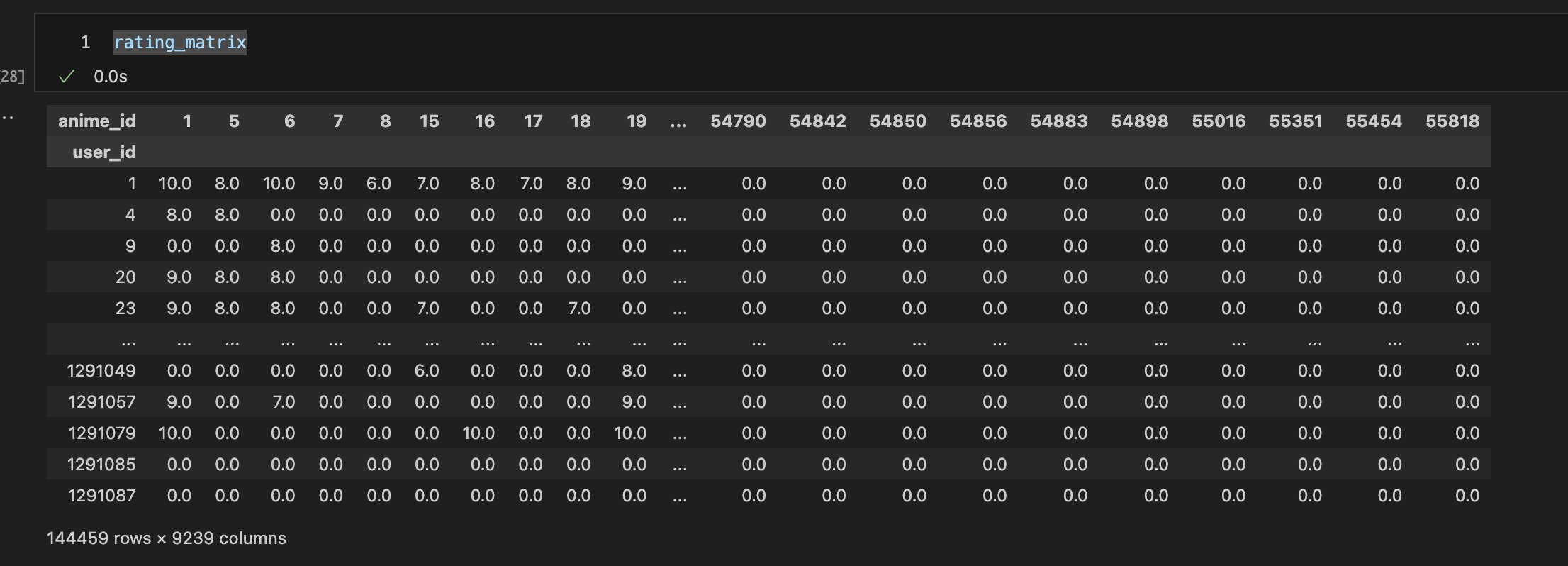
anime_id = columns
user_id = index
values = rating data
user별 콘텐츠를 평가한 평점 데이터에 대한 pivot table을 제작한다.
비슷한 성향의 유저 찾기 - 코사인 유사도
def similar_users(user_id, matrix, k=5):
# 현재 유저에 대한 데이터프레임 만들기
# matrix의 index = user_id -> 현재 1명 유저에 대한 평가 정보 찾기
user = matrix[matrix.index == user_id]
# matrix index 값이 user_id와 다른가?
# 일치하지 않는 값들은 other_users
other_users = matrix[matrix.index != user_id]
# 대상 user, 다른 유저와의 cosine 유사도 계산
# list 변환
similarities = cosine_similarity(user,other_users)[0].tolist()
# 다른 사용자의 인덱스 목록 생성
other_users_list = other_users.index.tolist()
# 인덱스/유사도로 이뤄진 딕셔너리 생성
# dict(zip()) -> {'other_users_list1': similarities, 'other_users_list2': similarities}
user_similarity = dict(zip(other_users_list, similarities))
# 딕셔너리 정렬
# key=operator.itemgetter(1) -> 오름차순 정렬 -> reverse -> 내림차순
user_similarity_sorted = sorted(user_similarity.items(), key=operator.itemgetter(1))
user_similarity_sorted.reverse()
# 가장 높은 유사도 k개 정렬하기
top_users_similarities = user_similarity_sorted[:k]
users = [i[0] for i in top_users_similarities]
return users
# 현재 유저에 대한 정보 찾기
user = matrix[matrix.index == user_id]
###### pivot tabledml index(user_id)와 불러온 user_id가 일치하는지 확인.
# matrix index 값이 user_id와 다른가?
other_users = matrix[matrix.index != user_id]
###### pivot table index와 일치하지 않는 값은 other users로 지정
# 대상 user, 다른 유저와의 cosine 유사도 계산
# list 변환
similarities = cosine_similarity(user,other_users)[0].tolist()
###### from sklearn.metrics.pairwise import cosine_similarity
###### cosine_similarity()함수로 대상유저와 다른 유저들 사이의 cosine similarity를 계산
# 다른 사용자의 인덱스 목록 생성
other_users_list = other_users.index.tolist()
# 인덱스/유사도로 이뤄진 딕셔너리 생성
# dict(zip()) -> {'other_users_list1': similarities, 'other_users_list2': similarities}
user_similarity = dict(zip(other_users_list, similarities))
###### other_users.index(대상 사용자를 제외한 모든 사용자)의 lilst 를 만들고
###### dict(zip())함수를 이용하여 dictionary에 other_user마다 similarity값 지정
###### - other_users = key 값
###### - similarity = values 값
###### dict(zip()) -> {'other_users_list1': similarities, 'other_users_list2': similarities}
# 딕셔너리 정렬
# key=operator.itemgetter(1) -> 오름차순 정렬 -> reverse -> 내림차순
user_similarity_sorted = sorted(user_similarity.items(), key=operator.itemgetter(1))
user_similarity_sorted.reverse()
# 가장 높은 유사도 k개 정렬하기
top_users_similarities = user_similarity_sorted[:k]
users = [i[0] for i in top_users_similarities]sorted(user_similarity.items(), key=operator.itemgetter(1))구문은
user_similarity.items()로 dictionary의 key, values 값을 모두 가져오고,
불러오는 기준을 value값을 기준으로 오름차순 정렬하여 가져온다.
이후 reverse 함수로 내림차순으로 정렬.
가장 높은 유사도 k(지정된 parameter)만큼 가장 높은 유사도를 추출하여 list로 변환.
for 반복문을 사용하여 top_user_similarites를 반복하고 user 리스트로 만들어 return.
컨텐츠 추천
def recommend_item(user_index, similar_user_indices, matrix, items=10):
# 유저와 비슷한 유저 가져오기
similar_users = matrix[matrix.index.isin(similar_user_indices)]
# 비슷한 유저 평균 계산 # row 계산
similar_users = similar_users.mean(axis=0)
# dataframe 변환 : 정렬/필터링 용이
similar_users_df = pd.DataFrame(similar_users, columns=['user_similarity'])
# 현재 사용자의 벡터 가져오기 : matrix = rating_matrix(pivot table)
user_df = matrix[matrix.index == user_index]
# 현재 사용자의 평가 데이터 정렬
user_df_transposed = user_df.transpose()
# 컬럼명 변경 48432 -> rating
user_df_transposed.columns = ['rating']
# 미시청 콘텐츠는 rating 0로 바꾸어 준다. remove any rows without a 0 value. Anime not watched yet
user_df_transposed = user_df_transposed[user_df_transposed['rating']==0]
# 미시청 콘텐츠 목록리스트 만들기
animes_unseen = user_df_transposed.index.tolist()
# 안본 콘텐츠 필터링
similar_users_df_filtered = similar_users_df[similar_users_df.index.isin(animes_unseen)]
# 평균값을 기준으로 내림차순 정렬
similar_users_df_ordered = similar_users_df_filtered.sort_values(by=['user_similarity'], ascending=False)
# 상위 10개 값 가져오기
# items = 10
top_n_anime = similar_users_df_ordered.head(items)
top_n_anime_indices = top_n_anime.index.tolist()
# anime dataframe에서 top10값 찾기
anime_information = animation[animation['anime_id'].isin(top_n_anime_indices)]
anime_information
return anime_information #items
#########
# 유저와 비슷한 유저 가져오기
similar_users = matrix[matrix.index.isin(similar_user_indices)]
# 비슷한 유저 평균 계산 # row 계산
similar_users = similar_users.mean(axis=0)
# dataframe 변환 : 정렬/필터링 용이
similar_users_df = pd.DataFrame(similar_users, columns=['user_similarity'])
#########
# 현재 사용자의 벡터 가져오기 : matrix = rating_matrix(pivot table)
user_df = matrix[matrix.index == user_index]
# 현재 사용자의 평가 데이터 정렬
user_df_transposed = user_df.transpose()
# 컬럼명 변경 48432 -> rating
user_df_transposed.columns = ['rating']
# 미시청 콘텐츠만 가져오기, 시청 콘텐츠 제거
user_df_transposed = user_df_transposed[user_df_transposed['rating']==0]
# 미시청 콘텐츠 목록리스트 만들기
animes_unseen = user_df_transposed.index.tolist()
# 안본 콘텐츠 필터링
similar_users_df_filtered = similar_users_df[similar_users_df.index.isin(animes_unseen)]
#########
# 평균값을 기준으로 내림차순 정렬
similar_users_df_ordered = similar_users_df_filtered.sort_values(by=['user_similarity'], ascending=False)
# 상위 10개 값 가져오기
# items = 10
top_n_anime = similar_users_df_ordered.head(items)
top_n_anime_indices = top_n_anime.index.tolist()
# anime dataframe에서 top10값 찾기
anime_information = anime[anime['anime_id'].isin(top_n_anime_indices)]
anime_information
return anime_information #items# 추천 콘텐츠 뽑아내기
random_user_id = random.choice(rating_matrix.index)
similar_user_indices = similar_users(random_user_id, rating_matrix)
recommend_content = recommend_item(random_user_id, similar_user_indices, rating_matrix)
print("-- 콘텐츠 추천 TOP 10 --")
# 모든 추천
print(recommend_content)
print("===================================")
# anime_id만 뽑기
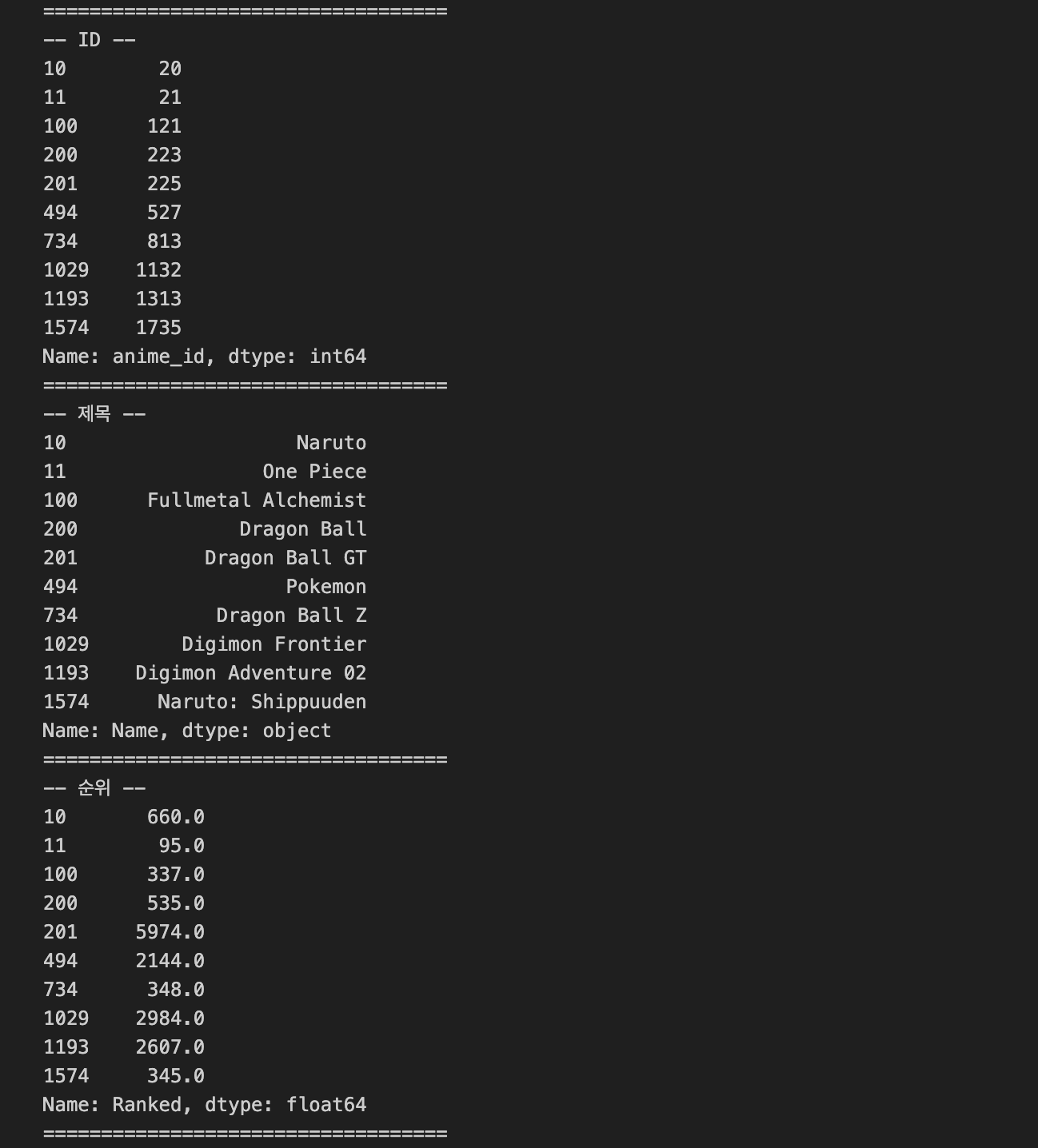
print("-- ID --")
print(recommend_content['anime_id'])
print("===================================")
# name만 뽑기
print("-- 제목 --")
print(recommend_content['Name'])
print("===================================")
# rating만 뽑기 / Unknown이 없는 anime filtered 데이터를 사용하여 사용자 랭킹인 rating이 존재하지 않음.
# anime filtered의 Rating은 작품등급 (시청가능한 연령)
# 순위로 대체 / 순위, Ranked
print("-- 순위 --")
print(recommend_content['Ranked'])
print("===================================")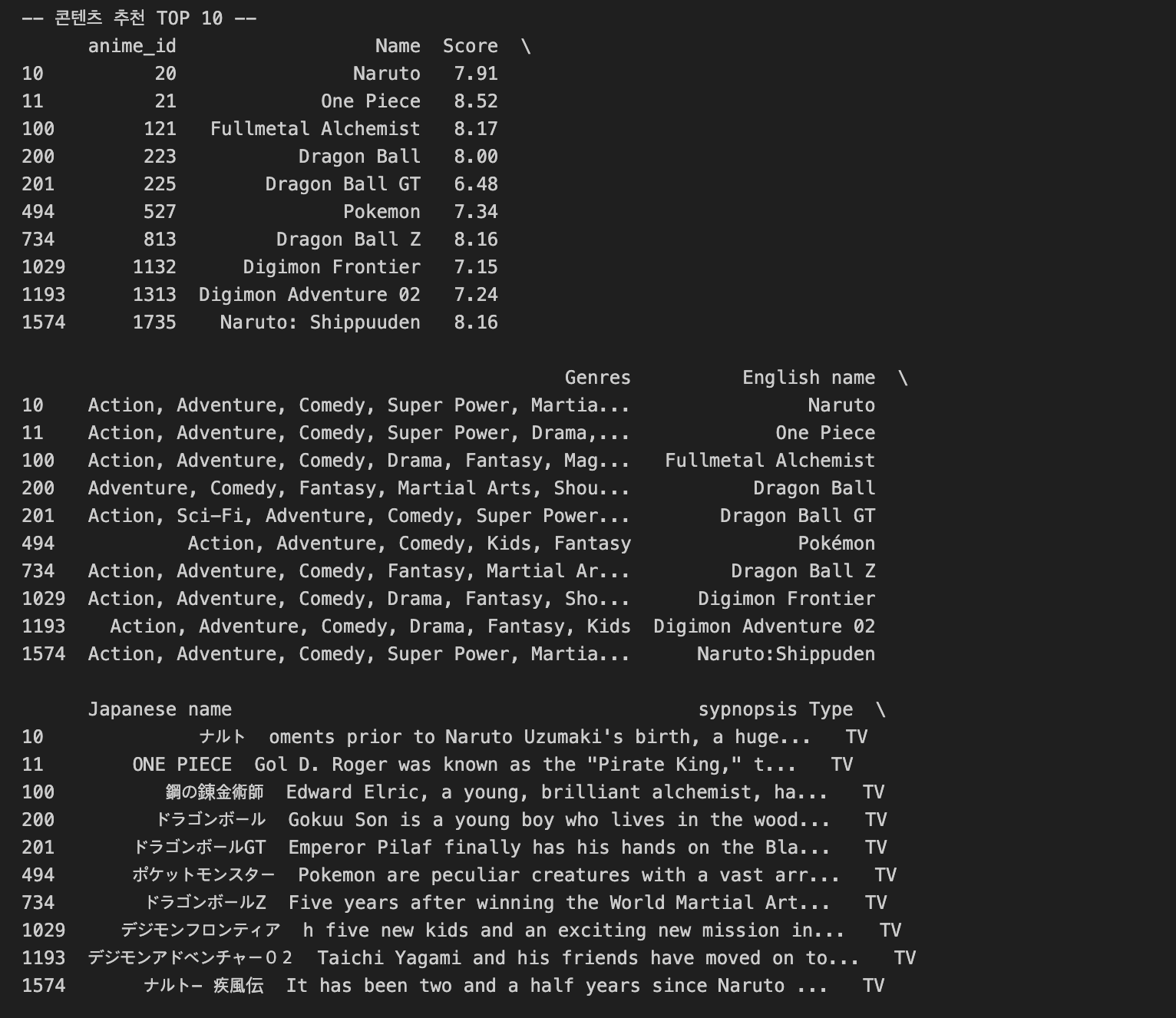
실습은 잘 됐는데...
겉핥기는 했는데...
아직도 로직이 머리에 착 들어오진 않는다.
심지어 우리는 user data가 없기 때문에 사실 사용자 기반 협업 필터링 추천 알고리즘을 사용할 수가 없다.
뭐든 해놓으면 쓸 데가 있겠지 ^ㅁ^
