실습해본 사용자 기반 협업 필터링, 고대로 쓸 순 없겠지만 코사인 유사도 측정하는 방법은 알았다.
data analyst 데이터에 적용해보기 위해 덮어두었던 텍스트 데이터 전처리를 다시 꺼냈다.
애증의 NLTK ..
import pandas as pd
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
# NLTK 데이터 다운로드
nltk.download('punkt')
nltk.download('stopwords')
# 데이터프레임에서 'Job Description' 컬럼만 추출
job_descriptions = df['Job Description']
# 불용어(stopwords) 정의
stop_words = set(stopwords.words('english'))
# 분석가에게 필요한 스킬 리스트 정의
required_skills = ['python', 'r', 'sql', 'modeling', 'statistics', 'visualization', 'big data', 'data preprocessing']
# 추가적인 스킬 리스트 정의
additional_modeling_words = ['modeling', 'machine learning', 'deep learning', 'm/l', 'd/l', 'ml', 'dl']
additional_visualization_words = ['visuali', 'dashboard', 'dashboards', 'tableau']
additional_preprocessing_words = ['preprocess']
# 스킬 라벨링을 위한 함수 정의
def label_skills(description):
tokens = word_tokenize(description.lower()) # 텍스트 토큰화 및 소문자 변환
filtered_tokens = [word for word in tokens if word.isalpha() and word not in stop_words] # 불용어 제거
# 스킬 라벨링
skill_labels = {}
for skill in required_skills:
if skill == 'python':
if any(word in filtered_tokens for word in ['python', 'pandas', 'matplotlib', 'seaborn', 'library']):
skill_labels[skill] = 1
else:
skill_labels[skill] = 0
elif skill == 'modeling':
if any(word in filtered_tokens for word in additional_modeling_words):
skill_labels[skill] = 1
else:
skill_labels[skill] = 0
elif skill == 'visualization':
if any(word in filtered_tokens for word in additional_visualization_words):
skill_labels[skill] = 1
else:
skill_labels[skill] = 0
elif skill == 'data preprocessing':
if any(word in filtered_tokens for word in additional_preprocessing_words):
skill_labels[skill] = 1
else:
skill_labels[skill] = 0
else:
if skill in filtered_tokens:
skill_labels[skill] = 1
else:
skill_labels[skill] = 0
return skill_labels
# 각 채용공고의 스킬 라벨링된 데이터프레임 생성
skills_df = job_descriptions.apply(label_skills).apply(pd.Series)
# 새로운 컬럼 추가
df_with_skills = pd.concat([df, skills_df], axis=1)
# 결과 출력
print(df_with_skills.head())
# CSV 파일로 저장
df_with_skills.to_csv('job_skills_analysis_updated.csv', index=False)Data Analyst 채용공고 데이터 안에 Job Description 컬럼의 텍스트를 분석해
분석가에게 필요한 스킬 리스트를 만들고 해당 스킬이 있으면 1, 없으면 0으로 라벨링하는 작업.
반복문을 작성하기 전에 내가 생각한 조건들인데,,,
아무래도 제대로 작동을 안한 것 같다..ㅠㅎ
-
스킬 리스트는 'sql', 'r', 'python', 'modeling', 'statistics', 'visualization', 'big data', 'data preprocessing' 이다. 기본적으로 Job Description 안에 각 단어를 포함하고 있으면 해당 컬럼에 1, 단어가 없으면 0으로 표기.
-
‘Python’, 'SQL', 'R': Python, python, sql, SQL 등 대소문자를 구분하지 않고 이 단어를 포함한다면 포함하면 각 칼럼에 1로 라벨링. 단, R은 대소문자 구분없이 독립적으로 알파벳 한 개 'R'이어야 함.
-
‘visualization’ : 꼭 ‘visualization’이라고 정확히 언급하지 않더라도, ‘visuali’를 포함하는 단어, dashboard, dashboards, Tableau, Visualization 중 한 단어라도 포함한다면 1로 라벨링.
-
data preprocessing : ‘data preprocessing’이라고 언급하지 않더라도 ‘preprocess’ 를 포함하는 단어가 있다면 1로 라벨링
-
‘modeling’ : ‘modeling’, ‘machine learning’, ‘deep learning’, ‘M/L’, ‘D/L’, ‘ML’, ‘DL’ 7개의 단어 중 한 단어라도 포함한다면 1로 라벨링
-
'statistics ' : 대소문자 구분하지 않고 이단어를 포함하면 statistics에 1로 라벨링. 'stati' 까지만 포함해도 1로 라벨링.
7.' big data' : 대소문자 구분하지 않고 big과 data 가 한 단어로 묶여있을 경우 1로 라벨링. Big-data 등 하이픈으로 엮여있어도 1로 라벨링.
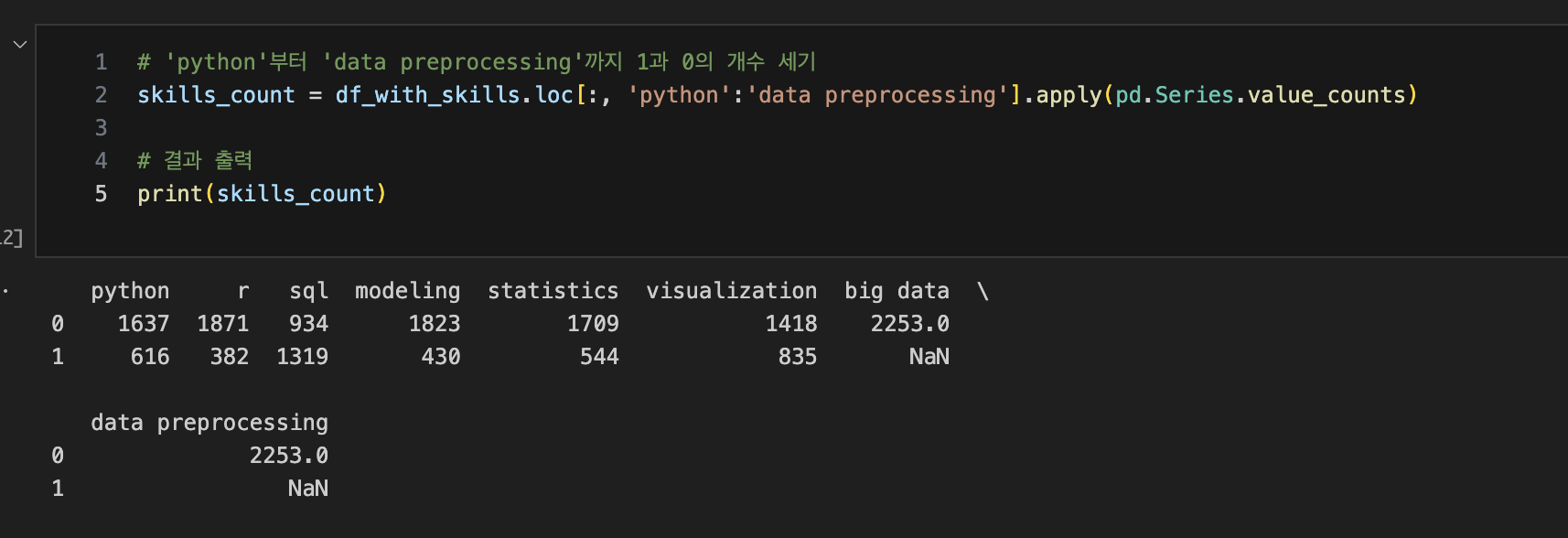
위의 코드를 실행했을 때, 데이터 프레임 생성은 잘 되었으나 뭔가 이상하다는 느낌,,
SQL은 그렇다 치고 big data 언급이 하나도 없다는 점, python이 616 밖에 안되나 싶은 마음에
pandas로 직접 단어 하나하나 숫자를 세는 노가다를 해보기로 함.
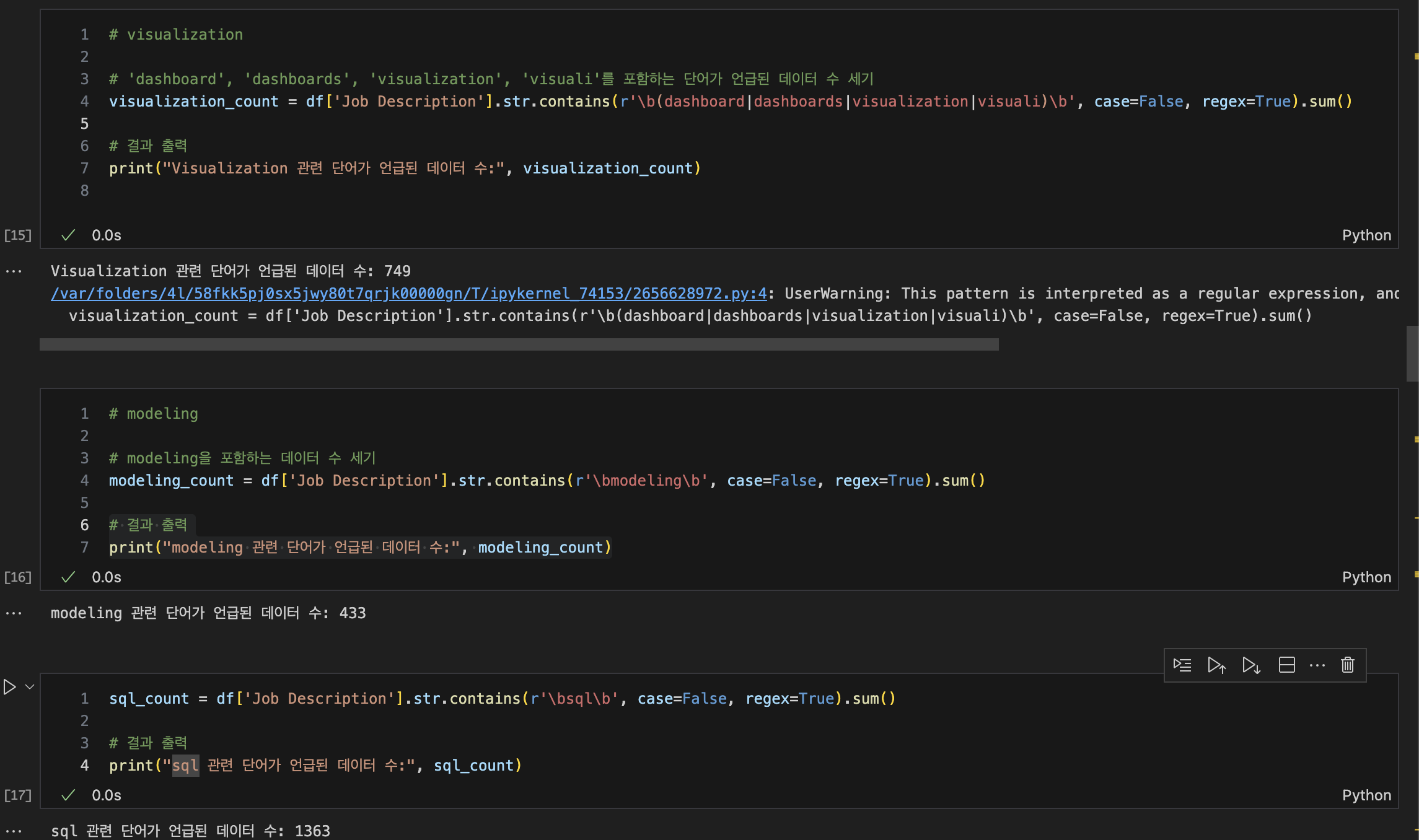
코딩 역량 부족으로 그나마 작성하기 쉬운 코드로 확인해보았는데,
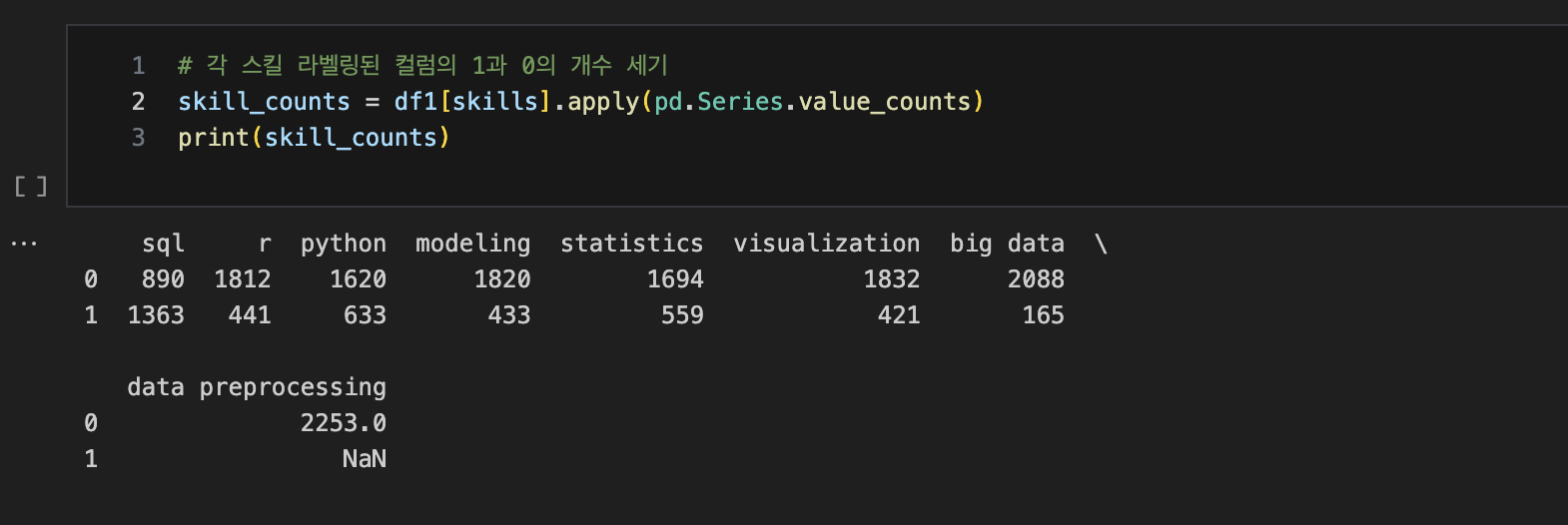
NLTK와 비교해보았을 때 modeling : 430/433, SQL : 1319/1363, Python : 616/633
미묘하게 Pandas 노가다가 개수가 많이 나오는 것을 알 수 있다.
혹시 몰라서 중복으로 세는지 찾아본 결과, 해당 단어의 존재 여부만 판단하기 때문에 중복 가능성도 없다.
ChatGPT와 씨름 끝에 NLTK로 몇 번의 시도를 해보았으나 최상의 결과를 만들진 못했다.
import pandas as pd
# 원본 데이터프레임 df 복사
df1 = df.copy()
# 스킬 리스트 정의
skills = ['sql', 'r', 'python', 'modeling', 'statistics', 'visualization', 'big data', 'data preprocessing']
# 각 스킬에 대해 라벨링하여 데이터프레임에 추가
for skill in skills:
df1[skill] = df1['Job Description'].str.contains(rf'\b{skill}\b', case=False, regex=True).astype(int)
# 결과 확인
df1.head(5)결국 Pandas로 별다른 조건을 제외하고, 단순히 단어의 존재 여부만 체크해서 숫자를 세어보니,
Visualization을 제외하고는 얘가 더 성능이 좋더라...
분류 모델은 시도도 못해보고 전처리만 하다가 하루가 끝났다.
데이터도 이 데이터를 쓸 게 아니라 OpenAPI로 따올 거고, 전처리도 LLM을 쓸 걸 생각하면,
지금 해야할 건 NLTK가 아니라 다른 자료조사가 먼저여야 한다.
하지만 텍스트 마이닝 기초도 모르고 LLM부터 덤비면 안될 것 같아서 시도한건데
요까짓 코딩 실력 갖고 반복문도 못 쓰는걸 보면 아무래도 괜히 했나 싶다.
어떻게든,, 되겠지,, Azaza...
