Introduction
- MLC task를 풀기 위해선, 보통 problem transformation -> algorithm adapation 방법을 사용.
problem transformation : BR, LP, CC
BR : multilabel problem -> a set of independent binary problems.
LP : each unique set of labels as class identifier
CC : BR + label correlation task - MLC의 주요 어려움은 imbalanced nature of the MLD(dataset) -> 이러한 특성 때문에 1번의 방법이 not effective.
- imablanced class distribution은 resampling methods 와 같은 방법들로 single-label classification의 맥락에서 연구되어옴. => 하지만, label과 label-sets들 사이의 imbalance 때문에 이 방법은 MLC에 바로 적용 불가능.
- In this paper, a literature survey was performed in order to identify a broad range of approaches for addressing the imbalanced problem in MLC.
Contributions
1) first survey paper focused on the role of imbalance techniques in an MLC task.
2) comprarative analysis of existing approaches and investigates the pros and cons of each approaches
3) provide guidance for chooisng appropriate techiques and developingg better approaches for handling an imbalanced MLC in futher studies.
Characteristics of imbalanced multi-label datasets
-
The imbalance problem in an MLD can be viewed from three perspectives: imbalance within labels, imbalance between labels, and imbalance among the label-sets.
within label : positive 가 너무 작고, negative가 대다수
between labels : 라벨끼리 데이터 개수 차이
among label-sets : some of the label-sets may be considered majority and the remaining label-sets may be considered minority cases at the same time. -
Four measures to assess label imablance
1) Imbalance ratio per label(IRLbl)
2) Mean imbalance ratio (MeanIR)
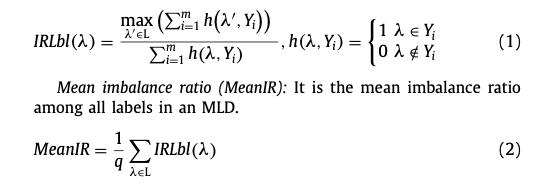
3) Maximum imbalance ratio(MaxIR)
4) Coefficient of variation of IRLbl (CVIR)

5) SCUMBLE -
Approch for MLC
- Resampling : under-sampling, over-sampling (random, heuristic)
- Multi-label random resampling : LP-ROS, LP-RUS ( 이것 둘다 MeanIR 기준 으로 복제나 삭제 )
=> limitation : some of the minority samples selected by ML-ROS may contain the most frequent
=> REMEDIAL method tackles the imbalanced prob- lem by decoupling the majority and minority labels, of which the imbalance level is assessed by SCUMBLE. REMEDIAL could be ei- ther a standalone sampling method or can be combined with other resampling techniques. - Multi-label heuristic resampling : 2)의 방법은 데이터 손실이나, 오버피팅의 문제가 발생할 수 있음. 그래서 복제나 삭제할 데이터를 선별적으로 고르는 방법임.
ex) MLeNN : ENN rule로 설계되었고, MeanIR, IRLBl로 imbalance를 평가함. ( Tomek Link algorithm )
ex) MLSMOTE
ex) MLSOL : rather than the imbalance, local characteristics of minority samples. - Classifier adaptation : loss cost of postivie and negative samples을 다이나믹하게하는 방법
ex) IMIMLRBF : multi-instance and multi-label classification algorithm based on radial basis neural networks. => label freq에 따라서 히든 레이어 수와 아웃풋과 히든레이어 사이의 웨이트를 조정. - Ensemble Method : 여러가지 모델을 합치는 방법. (BR-IRUS)
- Cost-sensitive approaches : use different cost metrics to describe the costs of any particular misclassified sample, aiming to minimize the total cost.
- Datasets and software tools : MULAN repository, MEKA repository, mldr package in R, multilearn in Python
- Model evaluation and performance metrics : Example-based, Label-based, Ranking-based Measures


Result summary
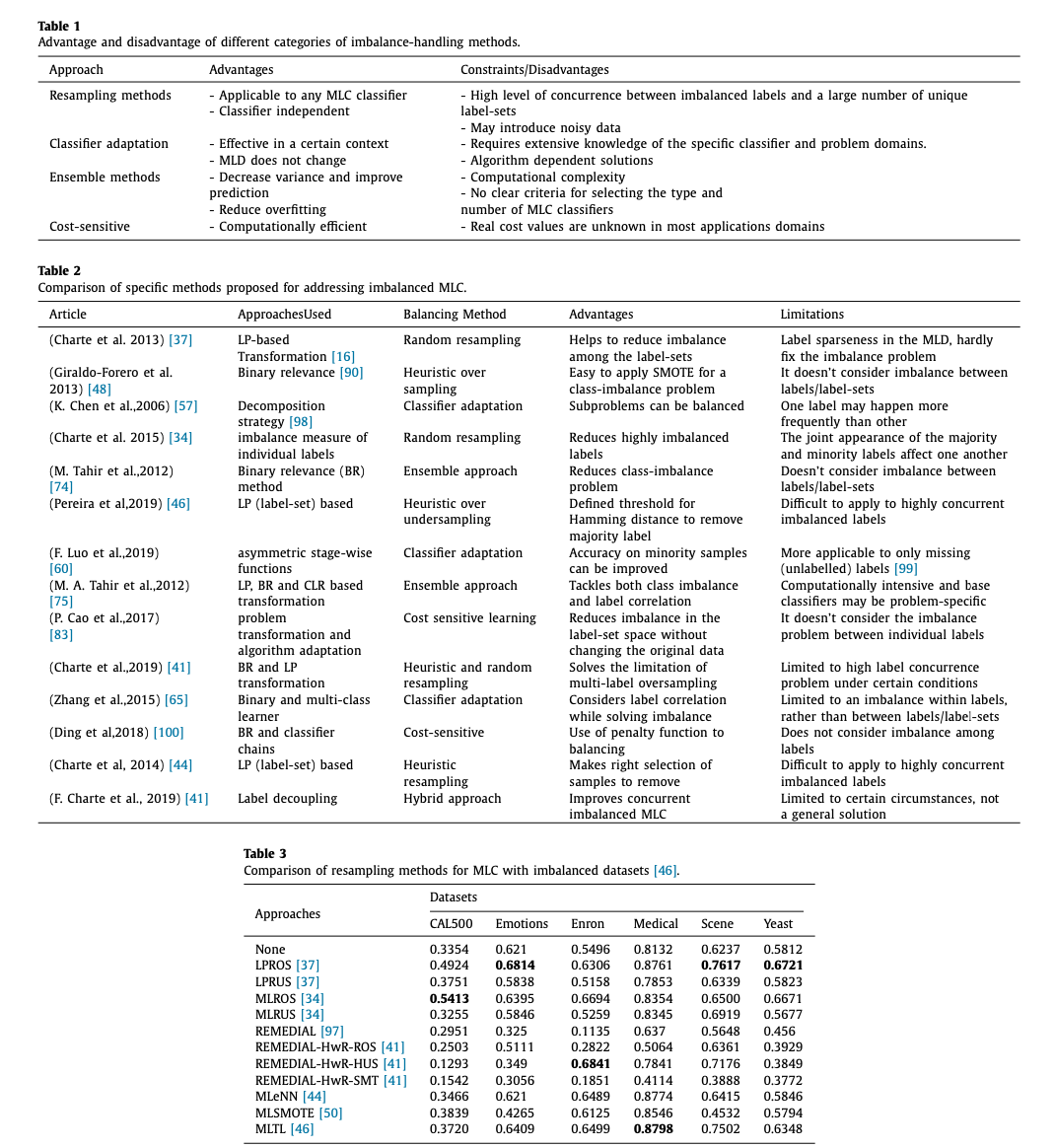
- This paper is first survey of approaches to the class imbalance problem in MLC : the characteristics of the data, problem descriptions, solutions and limitations of the approaces for solving imbalanced problems. (2006~2019)
