수치형 데이터, 범주형 데이터, 타겟 값이 함께 있는 데이터프레임 세팅
Heart Failure Prediction (Kaggle)
0. EDA 후 데이터 분포와 특징을 파악
1. 수치형, 범주형, 타겟 구분
X_num = df[['age', 'creatinine_phosphokinase','ejection_fraction', 'platelets','serum_creatinine', 'serum_sodium']]
X_cat = df[['anaemia', 'diabetes', 'high_blood_pressure', 'sex', 'smoking']]
y = df['DEATH_EVENT']2. 수치형 데이터 전처리 (Standard Scaler)
scaler = StandardScaler()
X_num_scaled = scaler.fit_transform(X_num)# fit_transform(): fit() 와 transform() 의 결합3. 데이터 통합해 y 없는 데이터프레임 구축
X_num_scaled_df = pd.DataFrame(X_num_scaled, index = X_num.index, columns = X_num.columns)
X = pd.concat([X_num_scaled_df, X_cat], axis = 1)# pd.DataFrame(data, index = , columns = )으로 array to dataframe 변환4. trainset과 testset 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)# train_test_split(독립변수 X, 종속변수 y, test size 비율, seed값 고정)5. Classification model 학습하기
from sklearn.linear_model import LogisticRegression
model_lr = LogisticRegression(max_iter=1000)
model_lr.fit(X_train, y_train)# sklearn(Scikit-learn, 사이킷런)에서 모델 불러오기
# fit(trainset의 X, trainset의 y)로 학습6. 학습 결과 평가하기
from sklearn.metrics import classification_report
pred = model_lr.predict(X_test)
print(classification_report(y_test, pred)) precision recall f1-score support
0 0.78 0.92 0.84 64
1 0.64 0.35 0.45 26
accuracy 0.76 90
macro avg 0.71 0.63 0.65 90
weighted avg 0.74 0.76 0.73 90
# classification_report(test의 y, 예측치)7. 특징 중요도(feature importance) 확인하기
plt.bar(X.columns, model_xgb.feature_importances_)
plt.xticks(rotation=90)# Logistic Regression에는 '.feature_importances_' 메서드 없음
# 5~6 과정 xgb로 학습 및 평가 후 확인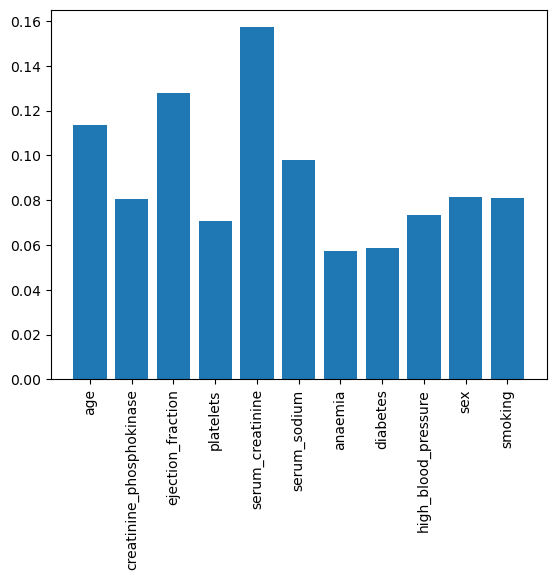
(1) get_dummies()로 범주형 데이터 전처리
X = pd.get_dummies(df, columns = [])