Video Game Sales with Ratings (Kaggle)
0. EDA 후 데이터 분포와 특징을 파악
1. 결측치 존재하는지 확인 후 제거
df.isna().sum()
df.dropna(inplace=True)2. 범주형 데이터 중 너무 적은 경우 'others'로 대체
df['Publisher'] = df['Publisher'].apply(lambda s: s if s not in pb[20:] else 'others')
df['Developer'] = df['Developer'].apply(lambda s: s if s not in dev[20:] else 'others')3. 범주형 데이터 전처리 (get_dummies)
X_cat = df[['Platform', 'Genre', 'Publisher']]
X_cat = pd.get_dummies(X_cat, drop_first=True)4. 수치형 데이터 전처리 후 데이터프레임 병합 & X, y 분리
X_num = df[['Year_of_Release', 'Critic_Score', 'Critic_Count']]
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_num)
X_scaled = pd.DataFrame(X_scaled, index=X_num.index, columns=X_num.columns)
X = pd.concat([X_scaled, X_cat], axis=1)
y = df['Global_Sales']5. XGBoost/Linear Regression 생성 및 학습
from xgboost import XGBRegressor
model_xgb = XGBRegressor()
model_xgb.fit(X_train, y_train)
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
model_lr.fit(X_train, y_train)6. 모델 학습 결과 평가
from sklearn.metrics import mean_absolute_error, mean_squared_error
from math import sqrt
pred_xgb = model_xgb.predict(X_test)
pred_lr = model_lr.predict(X_test)
print('XGB MAE:', mean_absolute_error(y_test, pred_xgb))
print('XGB RMSE:', sqrt(mean_squared_error(y_test, pred_xgb)))
print('LR MAE:', mean_absolute_error(y_test, pred_lr))
print('LR RMSE:', sqrt(mean_squared_error(y_test, pred_lr)))XGB MAE: 0.39659319130408194
XGB RMSE: 0.6821165671897874
LR MAE: 0.4435623723861831
LR RMSE: 0.70332403966428757. Feature Importance
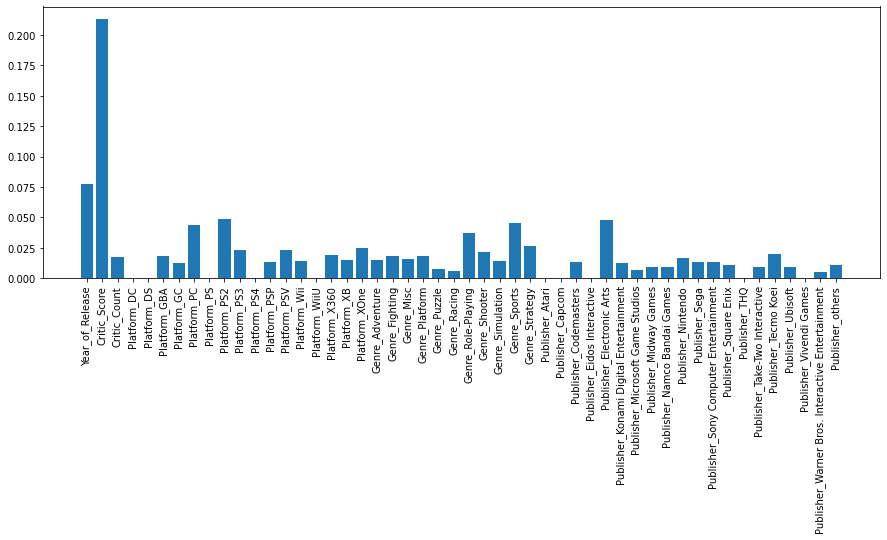
fig = plt.figure(figsize=(15,5))
plt.bar(X.columns, model_xgb.feature_importances_)
plt.xticks(rotation=90)
plt.show()